著者は紹介します
ニッケルZengguang、空腹まだBDI-ビッグデータプラットフォームの開発、シニアテクニカルマネージャーは、PPTV、唯一の製品に取り組んできました。15空腹参加し、まだ、全体的なプラットフォームをオフライン、リアルタイムプラットフォーム、開発ツールやプラットフォームの運用と保守を担当するデータアーキテクチャチームを設定し、CDの製品を経験してきたことは、継続的な改善プロセスに最初から、どのような空腹データプラットフォームとなります。
一、背景
何BDI-空腹ビッグデータプラットフォームのR&Dチームは、現在約20インフラのための主な責任者、リアルタイムおよび20+部品の開発・保守を含むオフライン&プラットフォームの開発ツール、2K +サーバの運用・保守およびデータプラットフォーム周囲のデリバティブのR&D&メンテナンスの合計であります。外よりこれを共有するためのインフラオフラインのツールやプラットフォーム。
今日では、メインTELLたち空腹進化の経験プラットフォームの数の計算ではそれについて何か、リアルタイム、リアルタイムプラットフォームは、全体で、それぞれが異なる問題に直面し、位相のスクラッチ→→プラットフォームからの急速な発展を経験しています。
第二に、全体のサイズとアーキテクチャ
まず何空腹リアルタイムプラットフォームの現在の全体的なサイズに導入:
カフカクラスタ4、単一のピークカフカ100wmsg / S。
2 ELKクラスタがネットワーク全体の量をインデックス、ログの取得のために使用さ86ワット/秒。
4
ストーム
クラスタは、物理的に、SLAの操作に応じて、ネットワーク全体のピーク算出1.6キロワット/ Sを分割します。
2つのスパークストリーミングクラスタと2つのFLINKクラスタがFLINKは、いくつかのオンラインビジネスをやってみてください糸モード、です。
20以上のアクセスビジネス面、(アクティブ-アクティブ&DataPipeline事業を含む)120以上ストームタスクの合計、26 +スパークストリーミングタスク、10 +ストリーミング
SQLの
リアルタイム検索、リアルタイムのリスク管理、リアルタイム監視、リアルタイムのマーケティングプロジェクトをお勧めしますかかわるタスク。
次のように全体的な構造は次のようになります。
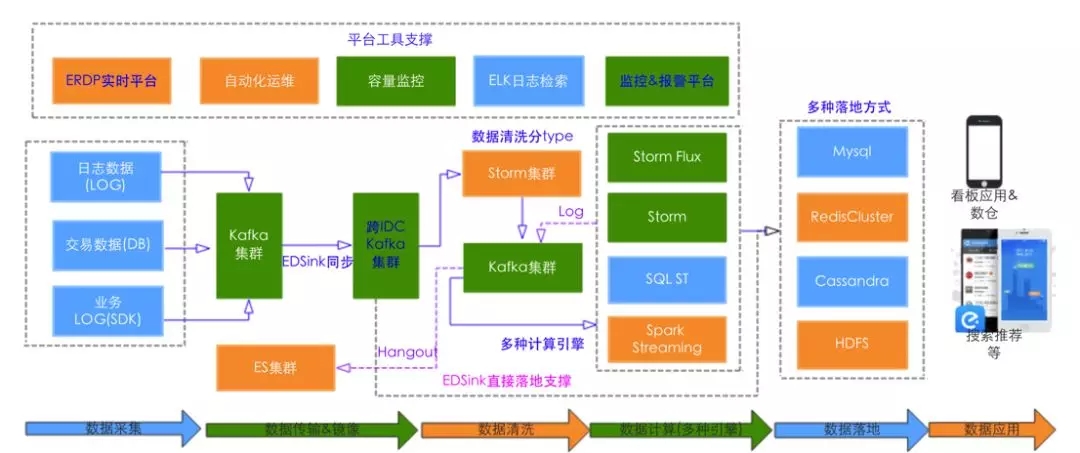
これは、データの収集、伝達、計算だけでなく、サービス階を含め、見ることができます。多成分系および圧力は、必要とされる全体のSLAより99.99%に、ビジネスクリティカル・パスの一部に直接適用しました。
第三に、進化
全体として、いくつかの段階を経験してきた:スクラッチ、迅速な開発プラットフォームから。
1、最初から
何空腹リアルタイムの問題に直面して、この段階では、5月15日からオンラインコンピューティング:
あまり需要。会社のプロモーションでリアルタイムビジネスは十分ではありません、サイトのエラー率、HTTPCode配信、QoSのデータ・ページの読み込み速度を計算するために使用される唯一のUBTドメインのQoS要件分析は、そこにあります。
単一のデータソース。唯一のデータ・ソースのユーザー行動ログ、注文、貨物運送状と他のコアDBデータの欠如。
容量が限られています。クラスタサイズが20未満で、かつ混合ユニットとオフラインの両方のリアルタイム+オフライン需要をサポートするために、リソースの競合があります。
安定性の問題。ジェスチャー、アプリケーションの各コンポーネントの多くの問題を使用して統一基準の欠如。例えば、各アプリケーションのニーズは、マシンの種類、どのようにより良いのconfigureに......と理由は、古いバージョンを使用してオープンソースコンポーネントの、いくつかの安定性のバグがあります。
データが遅延され、不完全なデータ。初期の技術的なオプションに問題があるので、頻繁に発生するデータの損失や遅延の問題が生じ、部屋を横切って、両方のトランスポートを使用して、データ収集端末に開発されたPythonプログラムを使用します。最も深刻な、リアルタイムデータの遅延に基本的に使用できない二時間以上、のピーク時。
この段階では、次の作業を行うために、主に、環境性、安定性、データ遅延やデータ損失の問題を解決するために、主に次のとおりです。
環境や標準化の問題については:
に応じて新たなモデル構成(ケース計算集約型、メモリ集約、IO集中型の、強力な混合、など)の動作特性を決定します。
環境変数、カーネルパラメータ、アプリケーションのパラメータを含む各コンポーネント配布仕様&仕様のパラメータ、設定:JVMな調整パラメータ、設定ZK /カフカの最適化を、標準的なハードウェアであって、例えば、古いカフカJBOD値下げをサポートしていません、我々は、ディスクのRAIDを持っているので、システムの可用性を向上させます。
リアルタイムおよびオフライン分割、独立した展開、リソースに対する回避の競合。
既存のコンポーネント(例えば、進化バージョンストーム1.0.1,1.0.3後ろ0.9.4-> 0.9.6など)を安定修正バグのアップグレード。
同時に、標準化と自動化の導入の環境配慮に基づい
パペット
収束環境の構成を維持するために行うには、Ansibleは、展開を自動化し、かつ迅速に維持することができる鍵管理ツールを作ったん。
安定性のために:
データ収集側において、トラフィックアプリ端消費を削減し、全体の伝送効率を高めるために、アプリの最後にマージ+ Gzipでの導入は、Luaの圧縮nginxの端にSDK後nginxのサーバーにメッセージマージ複数の送信しました仕方ACCESSLOG階に解凍。
データ送信側では、再調査のデータ伝送方式に考慮にチームを取っ
たJava
HDFSシンクに基づく技術スタックだけでなく、外部の場合、テールログの形式とシンクカフカクラスタへのデータ収集のためのデータ収集パイプラインとして水路の導入、などイベント時刻パーティション機能の開発、およびバグの同じ時間の修正バックログカフカシンクで。
データ側の地面に、状態の中間結果を格納するために、KVストレージを導入します。シングル初期使用
Redisの
背中が徐々に自己Sharding-> Redisの+ Tewmproxyの方法を使用し始めたが、メンテナンスコストが高くなっているので、再遭遇、重大なパフォーマンスの問題に設定データを格納する、と。リリースの安定したバージョンの背後にRedisClusterで徐々に会社では、この段階では、クラスタモードに移行する
のNoSQL
内部チームは絶えず自分の道を見つけているので、経験が不足してきました。
この段階リアルタイムアーキテクチャはこれです:
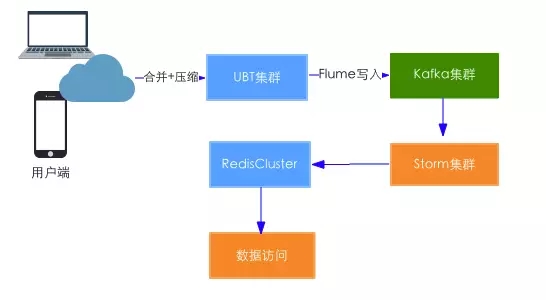
プラットフォーム全体の開発段階だけで4人、我々はリアルタイムが伸び投資するオフライン、リアルタイム、プラットフォームの開発と保守ツールの責任でなければなりませんが、また、ビジネスの発展をサポートするために、リソース不足。
虽然解决了基本的稳定性 & 数据延迟和丢失的问题,但是整体链路 SLA 还是不高,同时还存在数据源单一、应用单一的问题。
2、快速发展
16年公司业务大力发展,实时方面的需求越来越多。SLA 不高、数据源单一、应用单一的问题亟待解决。
由于业务需求,需开发实时 Dashboard 来实时关注业务情况,涉及流量、订单、运单等重要数据,项目需要涉及不同的数据源(Log & DB &业务数据),同时要求 SLA 99.99%以上。
为了提高整体的 SLA,同时覆盖 DB 侧的数据源,针对整个链路做了如下调整优化:
数据源方面:
优化 UBT(Nginx AccessLog)传输效率,调整 Flume 和 Kafka 的 Batch 大小、增加 Flume Timeout send 功能(默认 Flume1.6.0只有 Batch 的控制,没有 Timeout 的控制,会导致低峰时消息 Delay 变大)。考虑到 Batch Size 越大吞吐量越高,相应延迟也越大,因此需要针对吞吐量 & 实时性要求做 Trade Off。通过线上数据的分析,最终把 Batch Size 调整到10,Timeout 调整到100ms,最终 UBT 数据链路(从采集 Server 到计算落地)延迟降低99.9%<1s;
同时为了防止异常流量导致日志收集端雪崩,引入了 Nginx 限流限速模块;
为了满足 Binlog 数据采集的需求引入 OR 做解析工具,为防止 OR 异常退出导致数据丢失问题,开发基于 ZK 存储 Offset 功能,在异常 Crash 重启后继续上次的 Offset 消费即可。
计算方面:
前面提到用户 Log 是合并发送,在 Kafka 中的表现是多条 Merge 成一条,应用如果需要使用的话,需要按照一定的规则 Split。同时每个业务关注的 Type 不一样,不同的业务需要全量消费所有 Log,同时需要自行进行 Split,计算量大,维护成本比较高。为了解决这个问题引入了双层 Kafka 结构,在第一层进行统一的 Split 和 Filter,过滤异常流量,同时分 Type 写入二层 Topic,这样每个消费方只需消费对应的数据部分即可,整体流量相关业务计算量对比之前降低了一半以上;
涉及 UV 计算的场景,初始使用 Redis Set 去重,但是内存消耗过大。由于 UV 指标允许1%以内误差,在精度和时空效率上做 Trade Off,转而使用 Redis 的 HLL 来估算。随着业务量的增大,Redis 的 QPS 成为瓶颈,同时 Redis 无法跨实例进行 HLL 的 Merge,又演化为基于内存的 HLL 估算和 Merge,同时使用 Redis 直接存储对象,节省百倍内存的同时,支持多维度的 Merge 操作;
同时考虑到多个系统共用 ZK,ZK 可能存在比较大的压力,因此通过分析 ZK 的 Transcation Log 来确定调用分布。比如通过分析发现 Storm Worker 的 Heartbeat 会频繁访问 ZK,因此通过增加 Heartbeat Commit 时间减少 ZK 的压力;
为了减少重复的代码开发,对基础组件进行了封装:包括数据消费、去重、累加、数据写入等算子,最终减少了部分任务50%的代码量,提高了整体的开发效率,让用户关注业务逻辑即可。
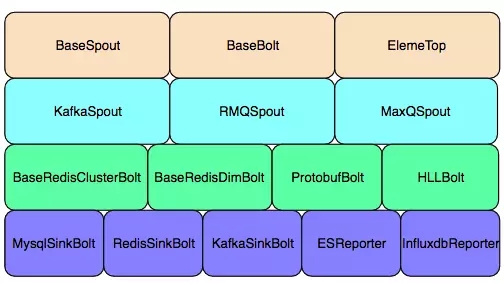
封装组件列表
运维管理方面:
为了解整体的容量情况,开发实时容量看板,通过实时获取 Zabbix Item LastValue 来监控 Storm & RedisCluster 实时压力情况;
为方便用户可以快速查看任务 Log 引入 ELK,同时在 Kafka2es 这一层引入 Hangout 替代 Flume (可支持3x以上性能提升),最终实现了 Storm Top Log->Logstash->Kafka->Hangout->ES->Kanbana 的整个 Log 链路。
整体 SLA 增强方面:
数据采集侧和计算侧均引入限速 & 反压功能,防止流量暴涨导致的雪崩效应;
从数据采集到数据最终落地使用双链路的方式,并采用多机房方式:比如数据采集端分布在异地两机房,使用本地计算+最终 Merge 或者数据双向传输+全量计算的方式;
配合 Kafka Binlog 数据的重放和 Nginx 模拟访问,对全链路进行模拟压测,配合实时监控 & 业务表现来关注各组件的性能临界点;
基于3的数据进行容量规划,同时做好资源的隔离;
完善各层面的监控和报警策略,包括模拟用户的访问来验证链路的情况,同时为了避免口径不一致导致的数据问题,开发离线&实时数据质量对比 Report,监控数据质量问题;
在业务端&后端增加降级策略,同时后端服务 Auto Failover;
完善各紧急预案 SOP,并针对性演练:比如通过切断 Active 的数据落地层来确定应用是否可以 Auto Failover;
数据层利用缓存,比如把一些 Storm 中间计算态数据写入 Redis 中;
同时为了防止应用 Crash 导致数据断层问题,开发了补数功能,在异常恢复后可以通过离线的数据补齐历史数据。
通过上述的一系列调整,最终抗住业务几倍的流量增长,保证了整体服务的稳定性。
业务监控 Dashboard 部分示例:
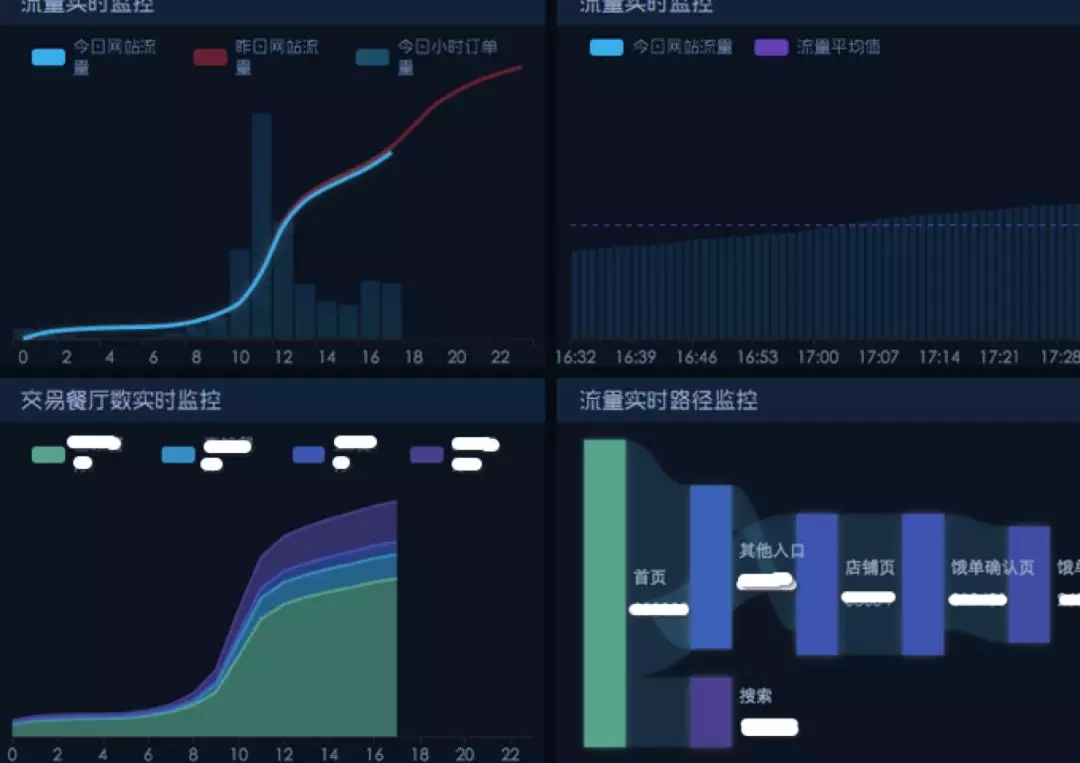
这个阶段实时平台的主要用户还是大数据自身,应用架构如下:
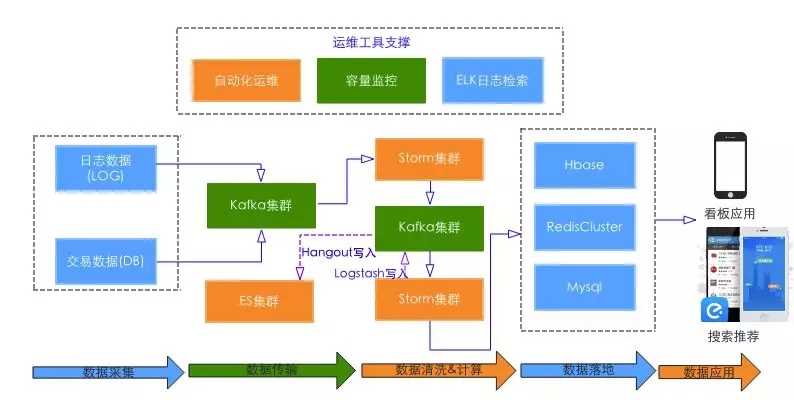
这个阶段虽然解决了数据源单一、整体 SLA 不高的问题,但是也带来了新的问题:
Storm 任务越来越多、Kafka Topic 越来越多、Topic 的 Producer 端和 Consumer 各是哪些、数据量如何,同时任务维护成本也越来越高,亟需一个平台化的工具;
用户的需求多样,一种引擎已经无法满足业务需求,需要多种引擎支持;
由于饿了么存在多语言开发场景(Go、Python、Java、
Scala 等),Storm 任务开发学习成本比较高,用户希望通过一个 SQL 即可支持部分简单场景;
业务 Log 需要通过 Nginx+Flume 方式收集,需要协调 OPS 部署 Flume,而 OPS 的同学比较排斥 Flume,亟需提供一个方便开发数据写入的标准 SDK 接入姿势;
之前业务数据落地仓库需要通过 Kafka->Flume->HDFS 方式,随着接入业务方变多,Flume 的维护成本越来越高,同时发生了多起 2HDFS 的 bug 导致数据重复的问题,亟需提供一个方便维护、支持多种数据 Sink 方式、稳定的数据流通解决方案。
3、平台化
17年初各产研逐步接入实时计算,上述问题也逐渐暴露出来,平台层面亟需一个统一的方案来解决用户的痛点。因此在年初,我们确定了“以 ERDP 实时平台为核心,打通数据采集、数据传输、数据计算、数据落地 DataPipeline 整体流程,为用户提供一个一站式的实时平台”的方向。
在此目标之上,我们做了如下的调整:
开发资源聚焦:
因为负责实时平台相关的小伙伴只有3-5人,我们开始逐步推动部分组件接入公司统一服务(比如监控 & 报警),并将部分任务移交到应用团队 team,只保留个别实时业务和平台相关部分开发;
考虑到 OR 每接入一个 DB 都需要启动 Instance,维护成本比较高,同时公司开始推动统一的 Binlog 解析工具 DRC 来做多机房间 DB 数据同步,因此我们也逐步使用 DRC 来替换 OR。
解决数据采集痛点:
通过开发统一的多语言数据接入 SDK 并接入配置中心,标准化数据接入的格式,方便用户的业务数据可以快速接入,同时为了提高可用性,在 SDK 中集成了降级 & 限速功能。
解决数据传输接入痛点:
参考 Flume Source->Channel->Sink 的思想,开发了基于 Storm 的 Data Pipeline 功能的组件 EDSink,可以支持多种数据写入方式,包括 2KAFKA、2ES、2HDFS、2DB。同时高度封装,抽象出部分配置,用户只需要通过填写一部分参数就可以实现数据的落地,大大加快了数据接入的效率,同时在数据落地层面引入了熔断功能;
在数据通过 EDSink 写入 HDFS 方面,打通了离线平台的调度系统和元数据管理使用,集成了建表和数据清洗功能,实现了一键化的数据落地。目前业务 Log 通过 EDSink 接入数据仓库已经从之前的2-3天降低到2小时以内;
为支持更细粒度的任务调度,在 EDSink 中集成基于 EventTime 分区功能,可以支持分钟粒度分区,结合 Spark 来支持半小时 ETL 链路的开发,小时整体链路从之前的40min缩短到20min左右即可完成;
同时和 Binlog 解析工具联动打通,支持用户自助申请落地 DB 数据,目前基于此方案,团队在进行 DB 数据去 Sqoop 化,预计可大大节省线上 DB Slave 服务器成本。
提供更多的计算方式:
引入 Spark Streaming 并集成到 ERDP 平台,封装基本的 Spark Streaming 算子,用户可以通过平台对 Spark Streaming 任务进行管理;
考虑到需要支持部分 SQL 的需求,在 Spark Streaming、Flink、Storm CQL 等引擎中做了对比,从团队的技术栈、引擎的成熟度、稳定性等层面综合考虑最终选择了 Spark Streaming。并基于 Spark Streaming 的 SQL 功能,为用户封装基本算子,同时支持上传 Jar 包提供 UDF 功能及 Scala 脚本支持,支持 Structured Streaming 以支持带状态的增量计算,实现用户写 SQL 即可满足实时开发的需求(目前可支持90%的业务场景)。
自动化&自助化便于任务和资源管理:
之前用户的 Storm 任务配置更改都需要重新打包,用户管理成本比较高,因此引入 Storm Flux 功能,封装基本组件并集成到实时平台。用户可以0代码生成数据 Sink,同时可以快速进行任务的开发和管理,自动生成 YML 文件降低任务的维护成本;
通过打通各个资源申请流程,支持 Kafka Topic 等资源的自助化申请和自动化创建,基于 Topic 数据完善元数据的管理,为资源的核算和实时元数据血缘做数据基础;
为了方便任务的监控,将 Storm,SparkStreaming,Kafka 层面监控统一入库 InfluxDB,并自动化模板生成功能,用户无需手动添加监控和报警,任务上线后 Metric & Dashboard 自动上报和创建,通过自动采集 API 的数据写入 InfluxDB,同时做了一个标准的 Template 用来自动生成 Grafana 的监控模板。
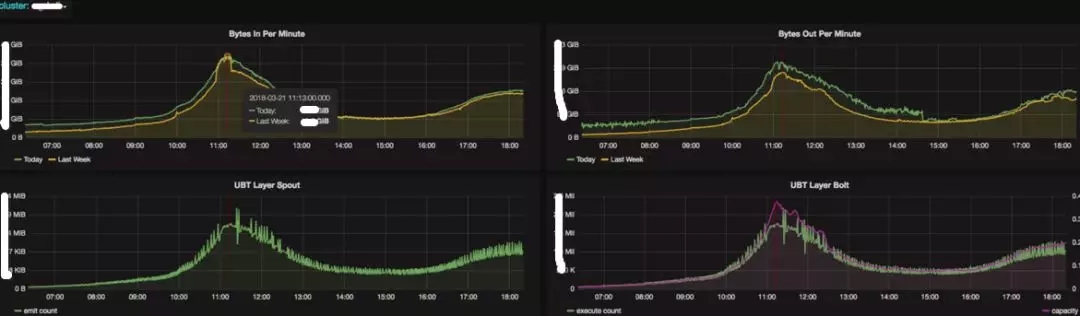
Kafka监控示例
通过上述一系列的调整,最终完善了整个平台,解决了用户开发成本高、接入成本高、管理成本高等痛点,最终的架构图就是文章开始的状况。
4、后续计划
虽然经过了一些演进,现有的平台仍然存在一些问题,比如:
SQL 方式覆盖场景有限;
用户在引擎中选择困难,没有一个引擎可以解决大部分需求;
Kafka0.8.2 版本功能有限,不支持 Excatly Once,不支持 JBOD Markdown 等;
实时和离线分离,数据重复建设,因为实现方式不同,实时和离线很难做到数据口径完全一致;
实时业务场景在公司内覆盖不够;
……
因此针对这些痛点我们也在做如下尝试:
Flink 以其性能&易用性在实时计算领域开始大行其道,我们也在做一些业务试点;
实时和离线融合 CEP 场景的试水;
Kafka 新版本的引入,包括 Qouta 限速、JBOD Markdown、Stream API、Excatly Once 等功能的支持;
实时平台集成到统一的一体化平台,用户在一个平台完成实时 & 离线开发;
发掘线上的业务场景,比如我们目前和策略部门合作的实时营销项目就是通过用户的行为数据来做一些策略,提高转化率。
四、一些心得
最后说一下关于平台化演进中的心得:
学会资源聚集(善于借助外力,must to have VS nice to have);
MVP 最小化可行性调研(产品是迭代出来的,不是一蹴而就的,先完成后完美);
偷懒思想,不重复造轮子(他山之石可以攻玉);
赋能用户,尽量自动化&自助化(提高效率,解放生产力);
数据化运营(用数据说话);
资源隔离,重点业务的 SLA 保证(降级限流策略,反压功能等);
做好监控(全链路的监控,并做必要测试);
防范墨菲定律,及时做好容量规划 & 压测,同时不断完善 SOP;
抽象思维(从一个到一类问题的抽象);
以解决实际问题为目的,而不是炫技;
关注用户体验(做完了 VS 做好了);
防火胜于救火,多想几步,不断总结并完善标准 & 规划 & 流程(上线规范/ Checklist / SOP 流程等)。