
10 億レベルの検索エンジンを構築して維持するのは簡単ではなく、唯一の最適な管理方法もありません。この記事は、継続的な学習と実際の要約の結果であり、数千万から数億の製品をサポートし、総クエリ QPS の数百から数千の増加を実現できる検索システムを構築する方法を紹介します。合計 QPS レベル 100 からレベル 10,000 まで増加するプロセス。その中で、ES リソースの拡張は不可欠ですが、この記事ではさらに、拡張では解決できないいくつかの ES パフォーマンスの問題にも焦点を当てます。この記事を通じて、より多くのデータや ES 利用シーンの参考にしていただければ幸いです。紙面の都合上、安定性ガバナンスに関する部分は次回の記事で紹介します。
事業紹介
プラットフォーム投資管理システムは、Douyin 電子商取引プラットフォーム活動のマルチエンティティ投資シナリオに対応し、投資プラットフォームを通じて製品を収集および選択し、さまざまな C エンド システムに製品を配布します。投資を誘致する主体も、生放送室、製品投資、クーポン投資など多岐にわたりますが、その中でも製品投資が当社最大の投資主体です。

投資プラットフォームのサービス体系
データセンター
データセンターは、構成可能でスケーラブルなユニバーサルなデータ取得およびオーケストレーション サービスを提供する ES ベースの検索サービスであり、投資プラットフォームでのデータ クエリをサポートするユニバーサル サービスです。
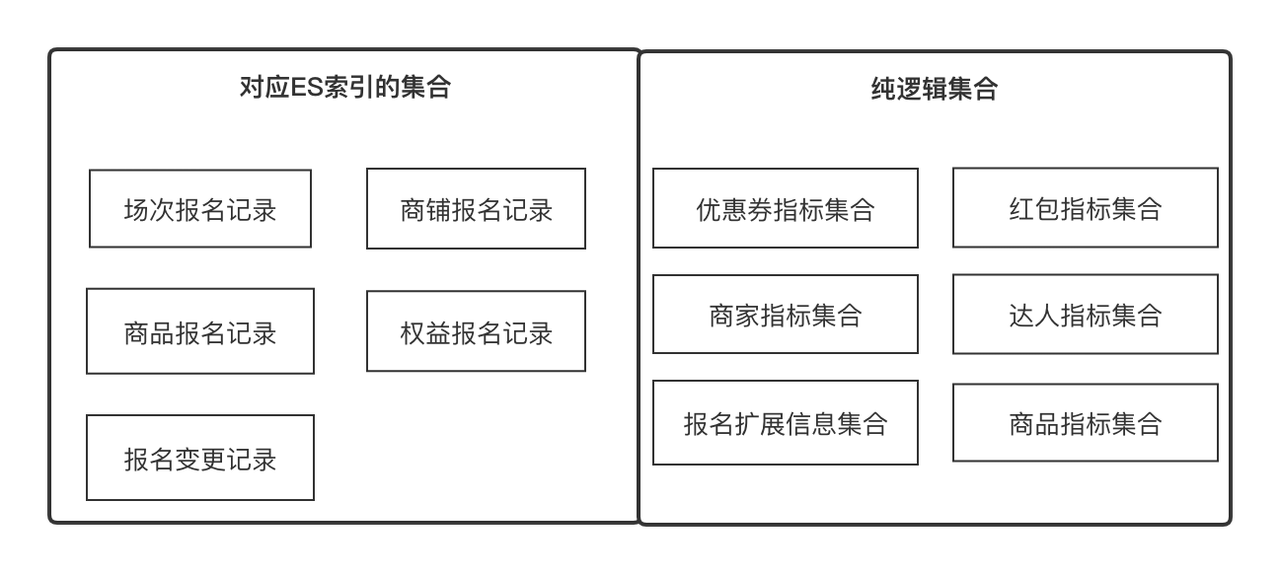
理解すべき重要な概念:
-
インジケーター : インジケーターは、製品名、店舗体験スコア、専門家レベル、登録レコード ID などのエンティティまたはオブジェクトの属性を記述するために使用されるメタデータであると同時に、最小限の更新と取得でもあります。製品の価格比較情報などのオブジェクト。すべてのフィールドを明確なセマンティクスでインジケーターとして定義できます 。
-
Set : 商品 ID と店舗 ID からそれぞれ取得できる商品属性セットと店舗属性セットなど、何らかの共通性によって収束できる集合を表します。また、 によって取得できる商品登録レコードの集合であることもあります。登録レコード ID です。ビジネス用語では、関連する指標のセットを表し、指標は 1 対多の関係にあります。
-
ソリューション : データ取得ソリューション。インジケーターとコレクションの 2 つの概念を抽象化し、データを最小単位で取得し、さまざまなコレクションの下でインジケーターを取得する方法を抽象化します。
-
カスタム ヘッダー : カスタム ヘッダーは、2 次元の行データ リストに表示されるタイトルを指し、インジケーターと 1 対多の関係があります。
-
フィルター項目 : フィルター項目は、2 次元の行データ リストで使用する必要があるフィルター項目を指します。1 対 1 の関係を示すことができます。
-
監査ビュー : 監査ビューは、監査ビジネス シナリオでカスタム ヘッダーのセットとフィルター項目のセットから動的にレンダリングできる監査ページを指します。
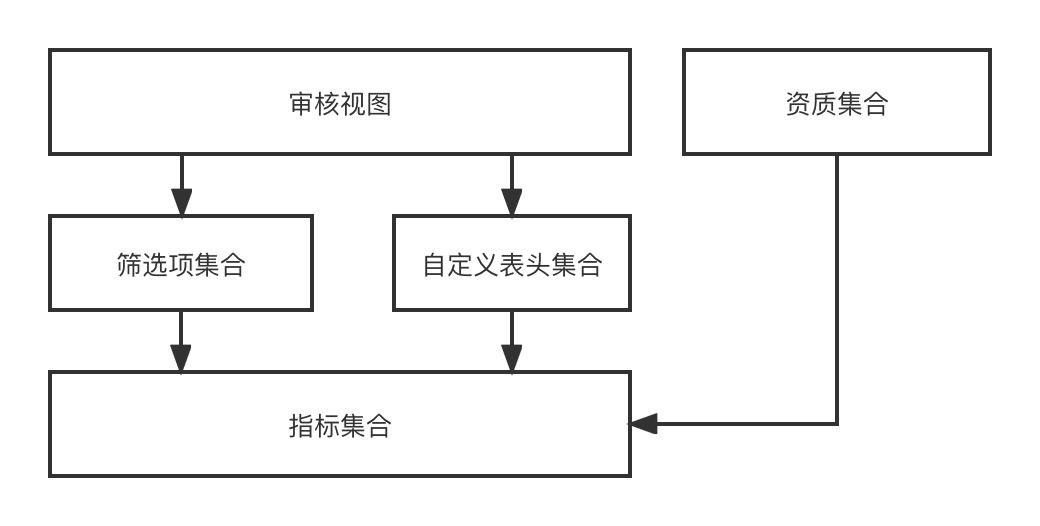
機能設計では、インジケーター -> [フィルター項目、カスタム ヘッダー] -> 監査ビュー -> 最終的に監査ページを動的にレンダリングするプロセスを経て、複数のエンティティと複数のシナリオ、異なるエンティティで投資を募集しています。さまざまなシナリオが必要となるため、私たちが設計したこの一連の機能は、必要な監査ビューの効果を動的に組み合わせることができます。
データ センターは、データ同期やデータ クエリなどの一般的なデータ取得機能を上位層のビジネスに提供します。現在、外部 RPC インターフェイスと登録レコード ES という 2 つのデータ ソースがあり、データ センターには 2 つのデータ取得ソリューションが統合されています。これらは外部の世界をまったく認識しません。つまり、どのデータ インジケーターを取得する必要があるかだけです。コレクション。
ES構築の目的は、投資登録記録の審査・統計機能をサポートし、上位ビジネスに必要なデータ内容を出力することです。
ES クラスターを 0 から 1 まで構築する
基本的なビジネスニーズを満たすシステムを0から1に構築するためには、次の2点をサポートする安定性が必要です。
-
基本的な災害復旧メカニズムとは、基本コンポーネントや読み取り/書き込みトラフィックの変更によりシステムのパフォーマンスが影響を受けた場合に、ビジネスが時間内に調整できることを意味します。
-
データの最終整合性とは、登録記録DB→ESマルチ機械室データが完成したことを意味します。
番組研究
ES クラスターの容量評価
ES クラスターの容量評価は、クラスターが構築された後、一定期間安定したサービスを提供できることを確認するために、主に次の問題を解決できる必要があります。
-
各インデックスに設定するシャードの数、その後のデータの増加量、読み取りおよび書き込みトラフィックの見積もり。
-
1 つのクラスター内にいくつのデータ インスタンスを設定する必要があるか、および 1 つのデータ インスタンスにどのような仕様を使用する必要があるか。
-
垂直方向の拡張と水平方向の拡張の違い、データ量が予想外に急増した場合やトラフィックが予想外に急増した場合の対応戦略は何か、ES クラスターの災害復旧をどのように設計すべきかを理解します。
主要なソリューション:
-
ES インデックス シャードの数は一度設定すると変更できないため、通常は負荷分散を確保するためにシャードの数を ES インスタンスの整数倍にすることが重要です。
-
単一シャードのサイズは 10 ~ 30G の間が比較的妥当であり、過剰なインデックス作成はクエリのパフォーマンスに影響します。
-
トラフィックの急増は容量の拡張によって解決でき、データの急増は古いデータを削除するかシャードの数を増やすことで解決できます。また、相互に影響しないように、複数のマシン ルームのディザスタ リカバリ展開計画に従って展開する必要があります。災害に強い機械室です。
データ同期リンクの選択
主に、DB 登録レコードを ES に同期する方法、その他の関連インジケーターを ES に書き込む方法、およびデータの整合性を更新して保証する方法を解決します。
-
DB -> ES は準リアルタイムのデータ ストリームである必要があり、登録レコードの変更やその他の情報が準リアルタイムで検索可能である必要があります。
-
登録レコードは独自のフィールドに加え、登録商品、店舗、専門家などの属性フィールドも補完する必要があり、ESにも書き込まれるため、 部分更新にも対応できる ため、ESの書き込み方法はUpsert方式のみとなります。 ;
-
個々の登録レコードの更新は順序どおりに行う必要があり、競合してはなりません。
ESインデックス基本構成調査
重要な ES の基礎と構成を理解します。
-
{"dynamic": false} は、es マッピングの自動拡張や予期しないインデックス タイプの追加を回避します。
-
index.translog.durability=async、トランスログを非同期的に更新すると、書き込みパフォーマンスの向上に役立ちますが、データ損失のリスクがあります。
-
ES のデフォルトのリフレッシュ間隔は 1 秒です。これは、書き込みが成功してから 1 秒以内にデータが見つかることを意味します。
データ同期ソリューション
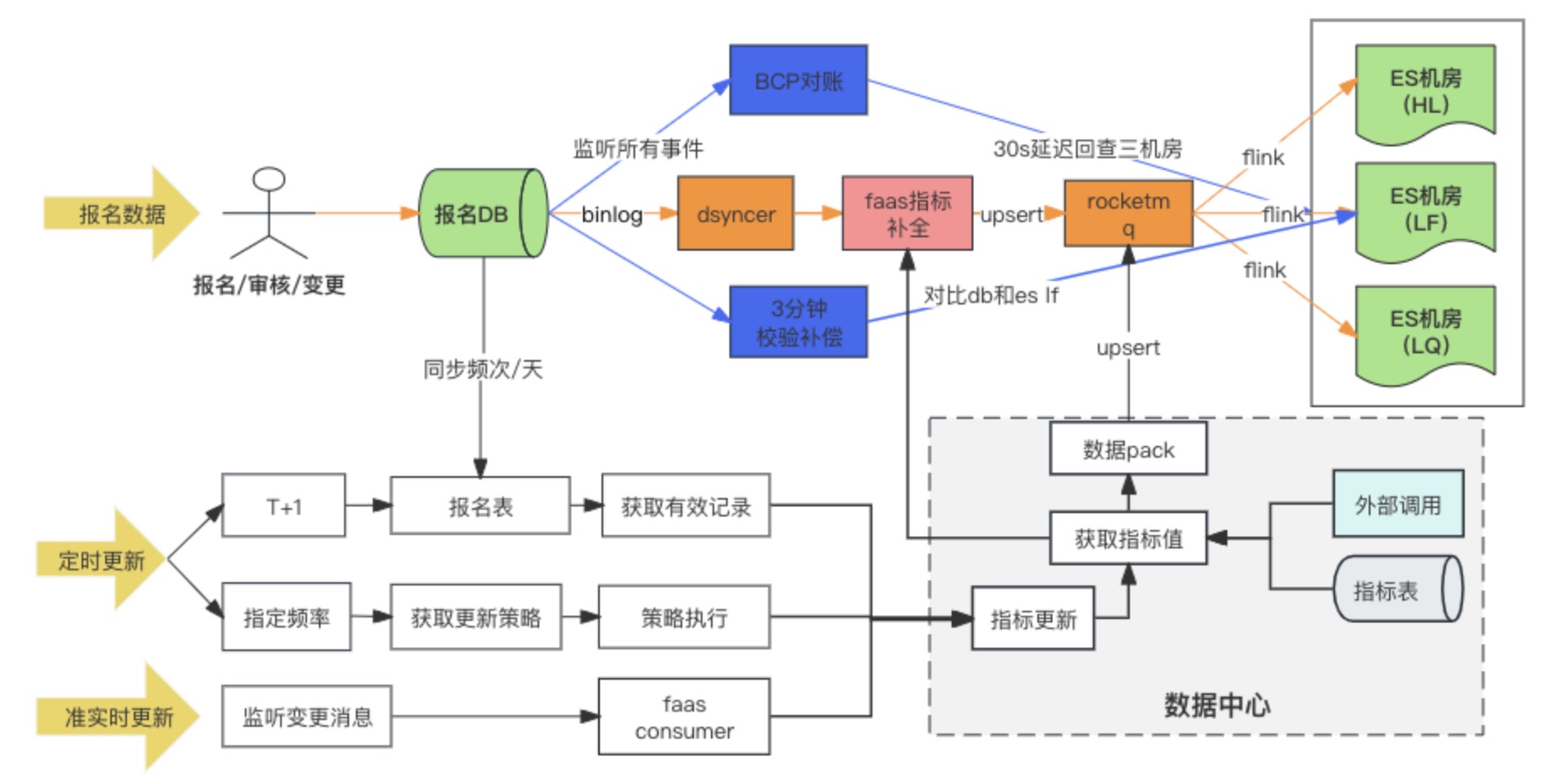
データ同期リンク図
DB --> ES データ同期ソリューションは、最終的に、マルチマシン ルームで使用するために、異種データを RocketMQ + Flink に同期書き込みする方法を採用します。同時に、登録レコードが初めて書き込まれるときに、拡張インジケーターが埋められます。 Faas カスタム変換スクリプトを介して、拡張インジケーターの更新依存関係は、メッセージ リスニングとスケジュールされたタスクの 2 つの方法を変更します。調査中に、実際には DB -> ES マルチコンピュータ ルームのオプションが 3 つあり、最終的に 3 番目のオプションを選択しました。ここでは、3 つのオプションの違いを比較します。
解決策 1:異種データ同期 (Dsyncer) を通じて ES マルチマシン ルームに直接書き込む

欠点:
-
直接書き込みは、複数のコンピューター ルームに同時に書き込みが成功することを保証できないため、複数のコンピューター ルームを同時に展開するという ES の要件を満たすには不利になります。複数の異種データを展開し、それらを別々に書き込んでも問題ありません。はい、つまり、ワークロードは 3 倍になり、約 12 個のインデックスになります。
-
直接書き込み Bulk の書き込み能力は比較的弱く、トラフィックが変動すると書き込みスパイクがより顕著になり、ES の書き込みパフォーマンスには好ましくありません。
-
ES に複数の更新エントリがある場合、直接書き込みでは 1 つの登録レコードが正しく更新されることを保証できません。グローバル バージョンを増やすことはできますか?はい、でも重すぎます。
利点:
依存関係のパスが最短で、書き込み遅延が短く、システム リスクが最小限に抑えられます。トラフィックが少ないビジネスや、単純な同期シナリオを使用するビジネスではまったく問題ありません。
オプション 2: RocketMQ を介して ES 単一コンピューター ルームを書き込む
DB が RocketMQ を通じて ES の単一コンピューター ルームに書き込んだ後、データは、ES が提供するクラスター間レプリケーション機能を通じて他のコンピューター ルームに同期されます。
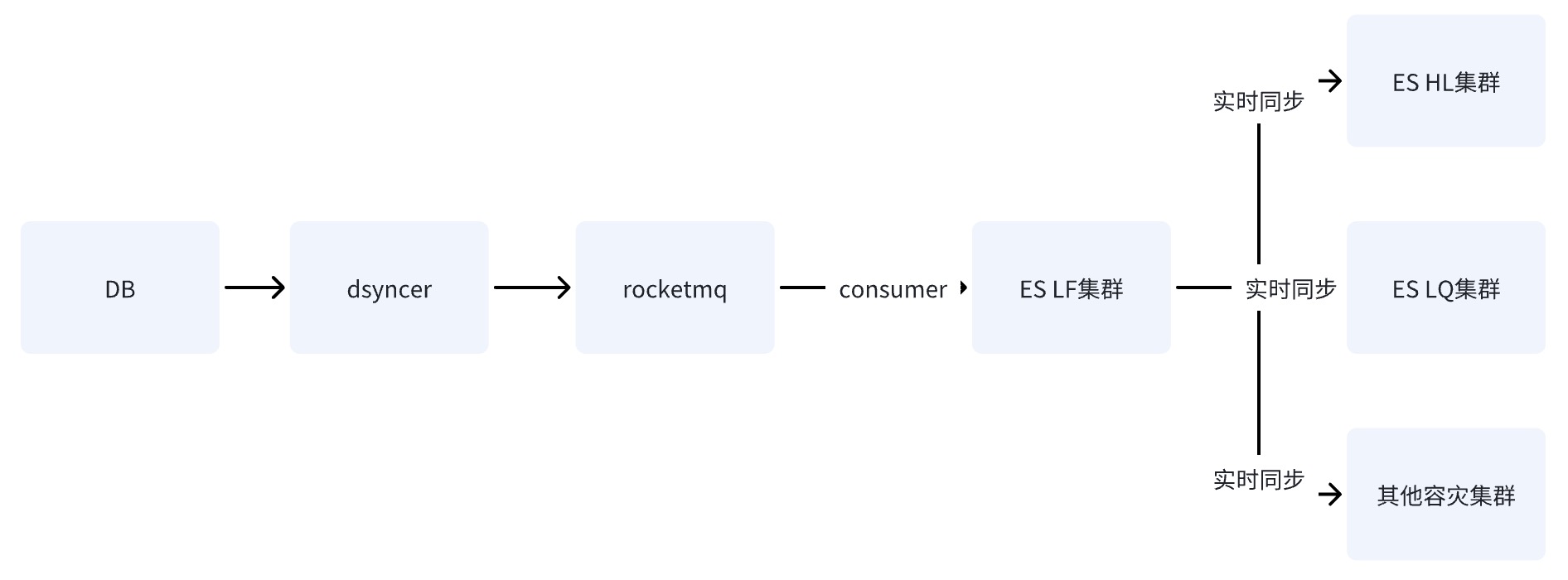
オプション 3: RocketMQ + Flink を介してESマルチマシン ルームを書き込む✅
DB が RocketMQ を通じて ES クラスターに書き込むと、複数の独立した Consumer Group タスクが開始され、Flink 分散システムを使用して複数のコンピューター ルームにデータを書き込むことができます。
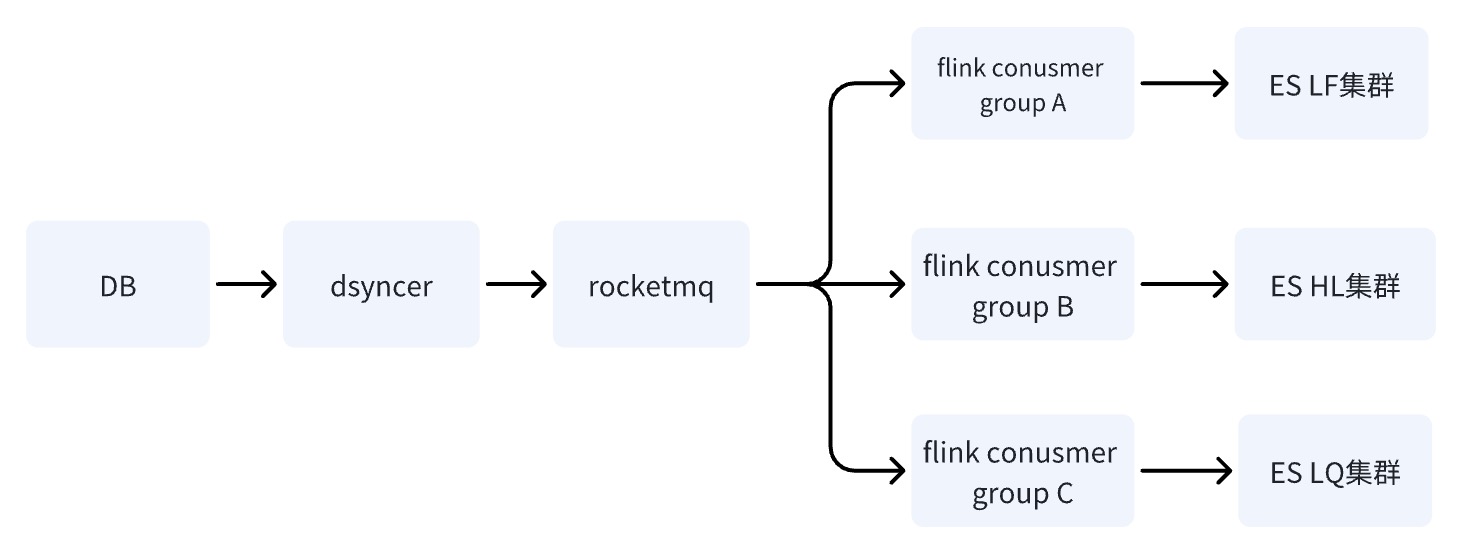
スキーム 2 とスキーム 3 の違いは 1 つだけです。スキーム 2 では、複数のコンピューター ルームに書き込む方法が異なります。一方、スキーム 2 では、1 つのコンピューター ルームにデータを書き込み、そのデータを他のコンピューター ルームに準リアルタイムで同期します。 3 つ目は、複数の独立したコンシューマを個別に記述することです。
オプション 2 と 3 の欠点は同じです。依存関係パスが最も長く、書き込み遅延が基本コンポーネントのジッターの影響を受けやすいという点です。ただし、オプション 2 の致命的な欠点は、単一
点のリスク
があることです。データが LF を介して HL と LQ に同期されていると仮定すると、LF がハングアップするとシステムは使用できなくなります 。
オプション 3 の利点は、オプション 2 と比較して、複数のコンピューター ルームの書き込みリンクが相互に独立しているため、リンクに問題があった場合でも、RocketMQ は単一のキーの順次更新の問題を簡単に解決できることです。これは、
オプション 1 の理由からも望ましくありません
。
RocketMQ を介して記述すると、なぜ順序の乱れや競合の問題が解決できるのでしょうか?
-
まず、ES の書き込みは、バージョン番号に基づいた楽観的ロックによって制御されます。同じレコードが同時に更新された場合、同時に取得されるバージョンは同じになります (1 と仮定すると、全員が同じになります)。書き込むためにバージョンを 2 に更新すると、競合が発生し、常に更新が失われる問題が発生します。
-
一般的なビジネス シナリオでは、キーとパーティションの順序に基づいて順序どおりに消費する必要があります。順序どおりに消費するには、メッセージが保存されるとき、メッセージが消費されるときの送信順序と一致している必要があります。それらはそこに保存されます。
したがって、ビジネスがメッセージを秩序ある方法で消費したい場合は、同じキーで送信されたメッセージが同じパーティションに送信されること、および消費されたメッセージが同じキーを持つメッセージが常にパーティションで消費されることを保証する必要があります。同じ消費者です。ただし、実際には、上記の 2 つの必要な条件が完全に保証されない場合があります。たとえば、特定の Broker インスタンスの書き込みが失敗し続ける場合です。その理由と解決策を以下に示します。
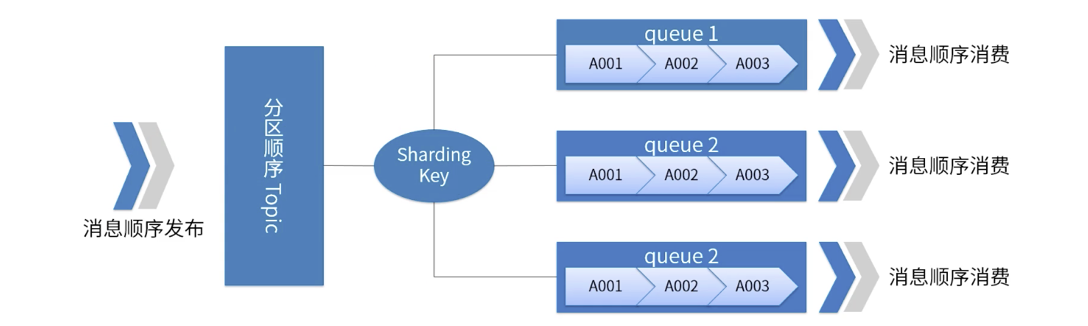
RocketMQ のパーティション順序を示す図
-
指定されたトピックについて、すべてのメッセージはシャーディング キーに従って複数 (キュー) に分割されます。
-
同じキュー内のメッセージは、厳密な FIFO 順序で発行および消費されます。
-
シャーディング キーは、連続メッセージ内の異なるパーティションを区別するために使用されるキー フィールドであり、通常のメッセージのキーとはまったく異なる概念です。
-
適用可能なシナリオ: 高パフォーマンスの要件: メッセージ内のシャーディング キーに基づいて、メッセージがどのキューに送信されるかを決定します。
ここで注意する必要があるのは、 RocketMQ は、ビジネスにおける順序異常の問題の 99% の解決には役立っているかもしれませんが、100% ではないという
こと
です。極端な場合には、メッセージに順序異常の消費問題が依然として存在する可能性があります。 ABA 現象として、Partiton が失敗した場合など、メッセージが他の Partition キューに繰り返し送信されるため、一貫性の調整が不可欠です。
多層調整メカニズム
調整メカニズムは、DB->ES のデータ一貫性の問題を解決します。DB --> ES は準リアルタイムのデータ フローであり、さまざまな状態での対応する監視が必要です。最終的なデータの一貫性を確保するための調整および補償戦略。
ここでは、分単位の調整とオフラインの調整を実現するために 3 層の調整を実行しました。以下では、複数層の調整が必要な理由を 1 つずつ説明します。

DB同期 ESリンク障害解析図
ビジネス検証プラットフォーム ( BCP ) の第 2 レベルの調整
上の図を参照すると、DB --> ES の同期が多くの依存コンポーネントに依存していることがわかります。この場合、 同期リンクの問題を発見するには、
グローバルな観点からの調整
、つまり BCP リアルタイム調整が必要です。
BCP 調整は、Binlog を監視し、ES マルチマシン ルーム調整を直接チェックする単一ストリーム調整です。Binlog ストリームのみに依存しており、注意深い学生であれば、中間リンクのデータ同期の遅延や障害を迅速に発見できます。 Binlog が切断され、BCP 調整が修正できない場合、この状況を解決する方法については後で説明しますが、少なくとも DB->DBus を除き、BCP 調整でほとんどの同期遅延を検出できることがわかります。問題。なぜ複数のストリームではなく単一のストリームなのか?
-
マルチストリーム調整のための長いデータ フロー リンクによって引き起こされ、検証精度が低下する、制御不能な遅延問題を回避します。
-
マルチストリームを使用する場合、マルチコンピュータルーム調整のために複数の BCP 調整を維持する必要があり、メンテナンスのためにより基本的なコンポーネントに依存するため、BCP 調整のメンテナンスコストが大幅に削減されます。
BCP 調整 DB の書き込みは常に ES Get リクエストをトリガーし、ES 上の特定のクエリ リソースを消費しますが、Get リクエストは非常に優れたパフォーマンスを持つクエリ メソッドであり、たとえば、1000 QPS 以内の書き込みには問題ありません。
Get リクエストでは、パラメータ Realtime に注意する必要があります。リクエスト時に False に設定する必要があります。そうしないと、リクエストされるたびに Refresh 操作がトリガーされ、システムの書き込みパフォーマンスに影響します。
mgetReq := EsClient.MultiGet()。
リアルタイム(偽)
分単位の調整
前節で述べたように、BCP (Business Verification Platform) の調整でカバーできないパスは DB->DBus であり、Binlog が切断される状況です。通常、Binlog の中断はより重大な事故を意味するかもしれませんが、私たちがしなければならないのは、可能な限りのことを行うことです。
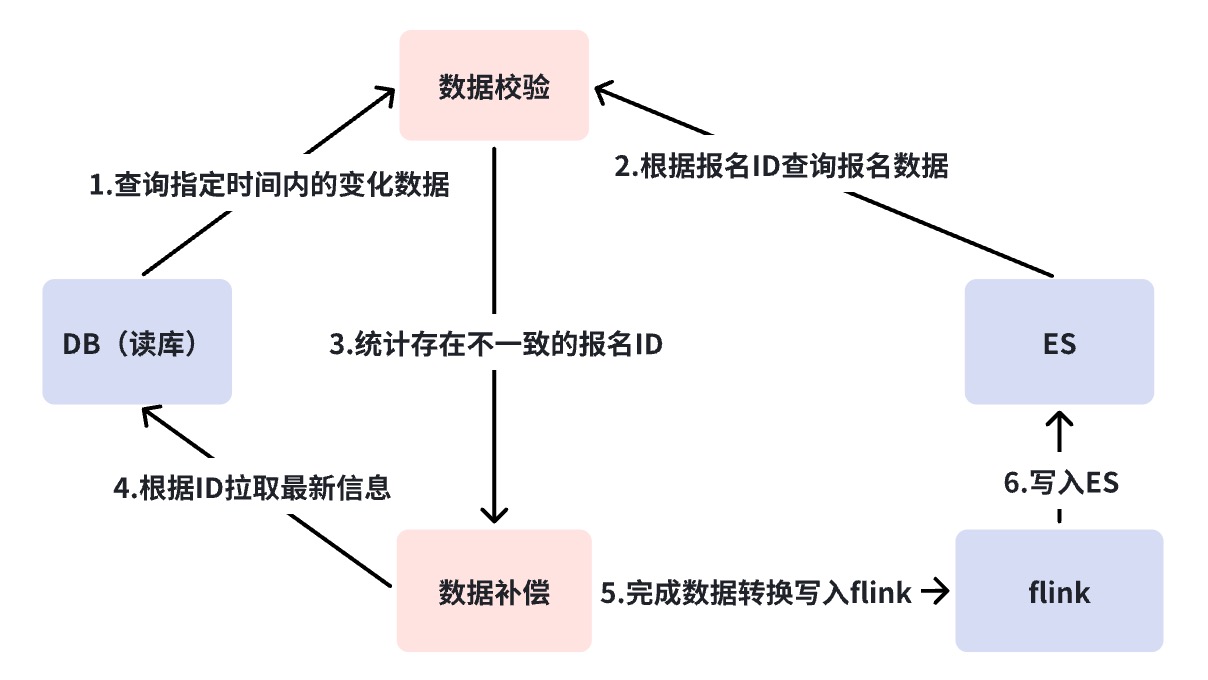
分単位のリコンシリエーションでは、コンポーネントに依存せずに DB と ES に直接クエリを実行し、不整合が発生した場合は自動補正が実行されます。一方で、分単位の調整は BCP 調整の欠点を補うものであり、第 2 の点は補償メカニズムを追加することです。 BCP が補償しない理由は、BCP は主に問題の検出を目的としており、軽量かつ高速である必要があるためです。また、この種の補償では依然としてすべての異常なシナリオをカバーすることはできません。
デフォルトでは、コンポーネントの機能は 3 分ごとの調整に対して正常であると見なされますが、ノードでの短い遅延により補償が発生する場合、リンクに何が問題であるかをさらに分析する必要があります。このとき、シナリオではリンクを 2 つに分割し、RocketMQ の以前のリンクに問題があるのか、RocketMQ 以降の消費リンクに問題があるのかを確認します。障害分析図を通じて、Binlog の中断、異種データ同期プラットフォームのコンポーネントのハングなど、RocketMQ の前にリンクに問題があった場合、補償データは RocketMQ に直接書き込まれ、複数のコンピューター ルームで消費されます。読み取りトラフィックはストリームを遮断する必要がなく、複数のコンピューター室でデータの一貫性を確保できます。ただし、RocketMQ がハングアップすると、ES に直接書き込みます。現時点では、複数のコンピューター ルームに同時に正常に書き込むことができるかどうかは保証できないため、単一のコンピューター ルームにのみ書き込み、すべてのトラフィックを 1 つのコンピューター ルームに切り替えることにしました。一人のコンピューター室。
RocketMQ のハングアップは非常に悪い信号であり、ここでの状況はさらに複雑です。 ES への直接書き込みのため、書き込みトラフィックが多い場合、この時点でシステムは電流制限保護を失い、単一のコンピューター ルームではすべての読み取りトラフィックに耐えられない可能性があります。同時に、書き込み競合が頻繁に発生する場合は、ビジネス書き込みポートをダウングレードする必要があります。したがって、RocketMQ がハングアップした場合、書き込みリンクの中央システムが麻痺していることがわかります。
これは最も避けたいことであり、RocketMQ の SLA がビジネスのベースラインとなります。
T+1オフライン調整
オフライン調整では、DB と ES のデータを毎日同期し、最終的な整合性を確認します。これにより、同期リンクのデータの一貫性が確保されます。データは遅くとも +1 補正が成功する必要があります。
要約する
以上で、構築の第 1 フェーズ、災害復旧展開、整合性調整、および基本的なシステム例外対応戦略が完了しました。現時点では、ES は数千万の製品インデックスの読み取りおよび書き込みリクエストをサポートできます。1 つのコンピューター室のトラフィックは 500 ~ 100 QPS の間で変動し、書き込みトラフィックは基本的に約 500 QPS に維持されます。
ただし、ビジネスの発展に伴い、ES クラスターでは CPU の急増が何度も発生し、1 つ以上のコンピューター ルームが同時にいっぱいになり、クエリの遅延が突然増加しましたが、読み取りおよび書き込みトラフィックはあまり変動しないか、変動しています。このリスクは、ES クラスターで発生するパフォーマンスの問題とビジネスの使用状況に起因します。この部分の内容については、次回のES検索エンジンの安定性管理について引き続き紹介していきます。
記事の出典 | ByteDance ビジネス プラットフォーム 王丹
仲間のニワトリがDeepin-IDE を
「オープンソース」化し、ついにブートストラップを達成しました。
いい奴だ、Tencent は本当に Switch を「考える学習機械」に変えた
Tencent Cloud の 4 月 8 日の障害レビューと状況説明
RustDesk リモート デスクトップ起動の再構築 Web クライアント
WeChat の SQLite ベースのオープンソース ターミナル データベース WCDB がメジャー アップグレードを開始
TIOBE 4 月リスト: PHPは史上最低値に落ち、
FFmpeg の父であるファブリス ベラールはオーディオ圧縮ツール TSAC をリリースし
、Google は大規模なコード モデル CodeGemma をリリースしました
。それはあなたを殺すつもりですか?オープンソースなのでとても優れています - オープンソースの画像およびポスター編集ツール
{{名前}}
{{名前}}