背景導入
GPU は現在、iQiyi 深層学習プラットフォームで広く使用されています。 GPU には数百または数千の処理コアがあり、多数の命令を並行して実行できるため、深層学習関連の計算に非常に適しています。 GPU は、CV (コンピューター ビジョン) モデルや NLP (自然言語処理) モデルで広く使用されており、通常、CPU と比較して、モデルのトレーニングと推論をより速く、より経済的に完了できます。
CTR (クリック トラフ レート) モデルは、ユーザーが広告やビデオをクリックする確率を推定するために、推奨、広告、検索、その他のシナリオで広く使用されています。 CTR モデルのトレーニング シナリオでは GPU が広範囲に使用されており、トレーニング速度が向上し、必要なサーバー コストが削減されます。
しかし、推論シナリオでは、Tensorflow サービングを通じてトレーニング済みモデルを GPU に直接デプロイすると、推論効果が理想的ではないことがわかります。に表示されます:
-
CTR タイプのモデルは通常、エンドユーザー指向であり、推論レイテンシーに非常に敏感です。
-
GPU の使用率が低く、コンピューティング能力が十分に活用されていません。
原因分析
分析ツール
-
tensorflow が公式に提供しているツールである Tensorflow Board は、計算フローグラフの各段階での所要時間を視覚的に表示し、オペレーターの総所要時間を集計することができます。
-
Nsight は、NVIDIA が CUDA 開発者向けに提供する開発ツール スイートで、CUDA プログラムの比較的低レベルの追跡、デバッグ、パフォーマンス分析を実行できます。
分析の結論
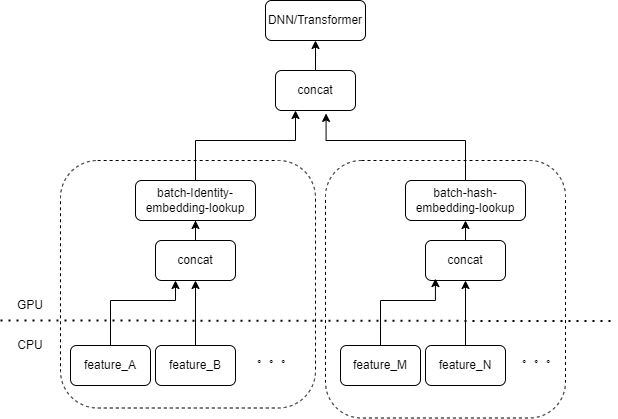
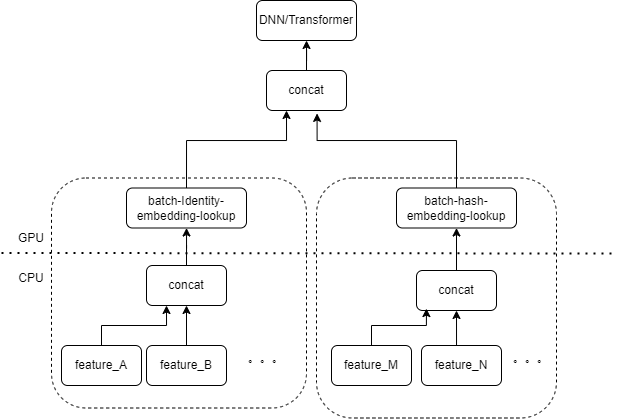
一般的な CTR モデルの入力には、多数のまばらな特徴 (デバイス ID、最近視聴したビデオ ID など) が含まれています。 Tensorflow の FeatureColumn はこれらの特徴を処理します。まず、アイデンティティ/ハッシュ操作を実行して、埋め込みテーブルのインデックスを取得します。埋め込みルックアップおよび平均化操作の後、対応する埋め込みテンソルが取得されます。複数の特徴に対応する埋め込みテンソルを結合した後、新しいテンソルが取得され、後続の DNN/Transformer およびその他の構造に入ります。
したがって、各スパース特徴により、モデルの入力層で複数の演算子がアクティブになります。各演算子は 1 つまたは複数の GPU 計算、つまり cuda カーネルに対応します。各 cuda カーネルには、cuda カーネルの起動 (カーネルの起動に必要なオーバーヘッド) とカーネル実行 (実際に cuda コア上で行列計算を実行する) の 2 つのステージが含まれています。スパース特徴 ID/ハッシュ/埋め込みルックアップに対応する演算子の計算量は少なく、カーネルの起動にはカーネルの実行時間よりも時間がかかることがよくあります。一般に、CTR モデルには数十から数百のまばらな機能が含まれており、理論的には数百の起動カーネルが存在することになりますが、これが現在の主なパフォーマンスのボトルネックとなっています。
GPU を使用して CTR モデルをトレーニングする場合、この問題は発生しませんでした。トレーニング自体はオフライン タスクであり、遅延に注意を払わないため、トレーニング中のバッチ サイズが非常に大きくなる可能性があります。起動カーネルは複数回実行されますが、カーネルの実行時に計算されるサンプルの数が十分に大きい限り、起動カーネルの各サンプルにかかる平均時間は非常に短くなります。オンライン推論シナリオの場合、計算を実行する前に Tensorflow Serving が十分な推論リクエストを受信し、バッチをマージする必要がある場合、推論のレイテンシーは非常に高くなります。
最適化
私たちの目標は、基本的にトレーニング コードやサービス フレームワークを変更せずにパフォーマンスを最適化することです。当然、起動するカーネルの数を減らす方法と、カーネルの起動速度を向上させる方法の 2 つが考えられます。
オペレーターフュージョン
基本的な操作は、複数の連続する操作または演算子を 1 つの演算子にマージすることであり、一方では cuda カーネルの起動回数を減らすことができ、他方では、計算プロセス中の一部の中間結果をレジスタに保存したり共有したりすることができます。サブセクションの最後で、計算結果がグローバル cuda メモリに書き込まれます。
-
-
自動融合
TVM/TensorRT/XLA などのさまざまな深層学習コンパイラーを試しましたが、実際のテストでは、連続 MatrixMat/ADD/Relu など、DNN の少数の演算子の融合を実現できます。 TVM/TensorRTはonnxなどの中間フォーマットをエクスポートする必要があるため、元のモデルのオンラインプロセスを変更する必要があります。そこで、 tf.ConfigProto() を使用して、tensorflow の組み込み XLA を融合用に有効にします。
ただし、自動融合は、スパース特徴に関連する演算子に対しては良好な融合効果をもたらしません。
手動オペレーターフュージョン
入力層に同じタイプの FeatureColumn の組み合わせによって処理される複数のフィーチャがある場合、複数のフィーチャの入力をオペレーターの入力として配列に結合するオペレーターを実装できると当然考えられます。オペレーターの出力はテンソルであり、このテンソルの形状は、元の特徴を個別に計算してそれらを連結することによって得られるテンソルの形状と一致します。
元の IdentityCategoricalColumn + EmbeddingColumn の組み合わせを例として、同じ計算ロジックを実現するために BatchIdentiyEmbeddingLookup 演算子を実装しました。
アルゴリズムの学習者が使いやすいように、ネイティブの FeatureLayer を置き換える新しい FusedFeatureLayer をカプセル化しました。また、Fusion オペレーターを含めるだけでなく、次のロジックも実装されています。
-
融合されたロジックは推論中に有効になり、元のロジックはトレーニング中に使用されます。
-
同じタイプのフィーチャを確実に一緒に配置できるように、フィーチャを並べ替える必要があります。
-
各特徴の入力は可変長であるため、ここでは追加のインデックス配列を生成して、入力配列の各要素がどの特徴に属するかをマークします。
ビジネスの場合、統合効果を得るために元の FeatureLayer のみを置き換える必要があります。
当初数百回テストされた起動カーネルは、手動融合後は 10 回未満に削減されました。カーネル起動のオーバーヘッドが大幅に軽減されます。
マルチストリームにより打ち上げ効率が向上
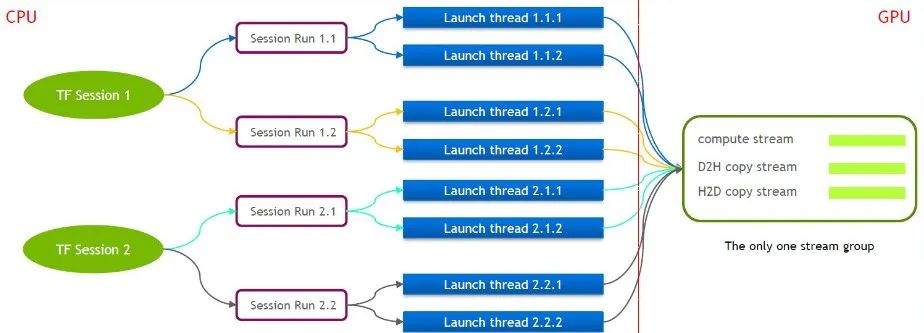
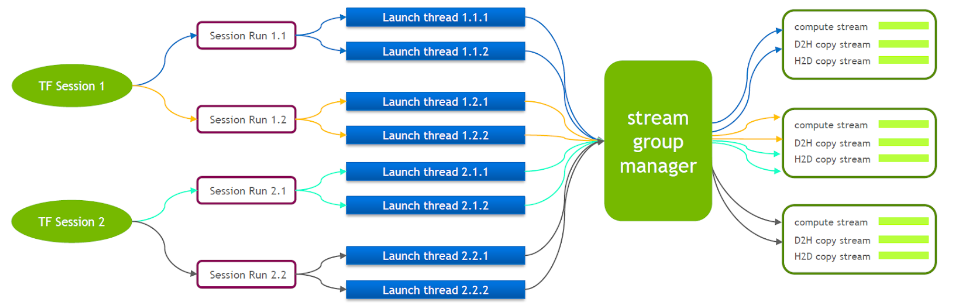
TensorFlow 自体は単一ストリーム モデルであり、Cuda Stream Group (Compute Stream、H2D Stream、D2H Stream、D2D Stream で構成される) を 1 つだけ含んでおり、複数のカーネルは同じ Compute Stream 上でしか連続的に実行できません。これは非効率です。 cuda カーネルが複数の tensorflow セッションを通じて起動された場合でも、GPU 側でキューイングが必要です。
このため、NVIDIA の技術チームは、複数の Stream Group の同時実行をサポートするために Tensorflow の独自のブランチを維持しています。これは、cuda カーネルの起動効率を向上させるために使用されます。この機能を Tensorflow Serving に移植しました。
Tensorflow Serving の実行中は、複数の CUDA コンテキスト間の相互干渉を減らすために Nvidia MPS をオンにする必要があります。
小規模データのコピーの最適化
前回の最適化に基づいて、小規模データのコピーをさらに最適化しました。 Tensorflow Serving はリクエストから各特徴の値を逆シリアル化した後、cudamemcpy を複数回呼び出して、ホストからデバイスにデータをコピーします。呼び出しの数は機能の数によって異なります。
ほとんどの CTR サービスでは、バッチサイズが小さい場合、最初にホスト側でデータを結合してから cudamemcpy を一度に呼び出す方が効率的であることが実際に測定されています。
バッチをマージする
GPU シナリオでは、バッチ マージを有効にする必要があります。デフォルトでは、Tensorflow Serving はリクエストをマージしません。 GPU の並列計算機能をより有効に活用するために、1 回の前方計算にさらに多くのサンプルを含めることができます。複数のリクエストをバッチマージするために、実行時に Tensorflow Serving のenable_batching オプションをオンにしました。同時に、次のパラメーターの構成に重点を置いたバッチ構成ファイルを提供する必要があります。以下に、私たちの経験の一部を示します。
-
max_batch_size: バッチ内で許可されるリクエストの最大数。これよりわずかに大きくなる可能性があります。
-
batch_timeout_micros: バッチのマージを待機する最大時間。バッチの数が max_batch_size に達しない場合でも、理論的には遅延要件が高くなるほど、ここでの設定は小さくなります。 5 ミリ秒未満に設定するのが最適です。
-
num_batch_threads: MPS をオンにした後、最大同時推論スレッド数を 1 ~ 4 に設定できます。それ以上に設定すると、遅延が増加します。
ここで、CTR クラス モデルに入力されるスパース特徴のほとんどは可変長特徴であることに注意してください。クライアントが特別な合意を結んでいない場合、特定の機能の長さが複数のリクエストで一致しない可能性があります。 Tensorflow Serving にはデフォルトのパディング ロジックがあり、リクエストが短い場合は対応する機能にゼロを埋め込みます。可変長機能の場合、null を表すために -1 が使用されます。デフォルトのパディング 0 は、実際には元のリクエストの意味を変更します。
たとえば、ユーザー A が最近視聴したビデオの ID は [3,5]、ユーザー B が最近視聴したビデオの ID は [7,9,10] です。デフォルトで完了すると、リクエストは [[3,5,0], [7,9,10]] になります。モデルは、A が ID 3、5、0 の 3 つのビデオを最近視聴したとみなします。
したがって、Tensorflow Serving 応答の完了ロジックを変更しました。この場合、完了ロジックは [[3,5,-1], [7,9,10]] になります。最初の行の意味は、やはりビデオ 3 と 5 が視聴されたということです。
最終効果
前述のさまざまな最適化の後、レイテンシーとスループットはニーズを満たし、推奨されるパーソナライズされたプッシュおよびウォーターフォール ストリーミング サービスに実装されました。業績は以下の通りです。
-
スループットは、ネイティブ Tensorflow GPU コンテナーと比較して 6 倍以上増加します。
-
レイテンシは基本的にCPUと同じで、ビジネスニーズに対応
-
同じ QPS をサポートする場合、コストは 40% 以上削減されます
この記事は、WeChat パブリック アカウント - iQIYI テクノロジー製品チーム (iQIYI-TP) から共有されたものです。
侵害がある場合は、削除について [email protected] までご連絡ください。
この記事は「OSC ソース作成計画」に参加していますので、読んでいる方もぜひ参加して共有してください。