
01
戻るシーンそして現状
1. 広告分野におけるデータの特徴
広告分野のデータは、連続値の特徴と離散値の特徴に分類できます。AI画像、ビデオ、音声などの分野とは異なり、広告分野、ユーザーID、広告ID、ユーザーとインタラクションする広告IDシーケンスなどのIDの形式で提示されることがほとんどです。規模が大きく、広告フィールドを形成する高次元のスパースデータの特徴。
-
静的特性 (ユーザーの年齢など) と、ユーザーの行動に基づく動的特性 (ユーザーが特定の業界の広告をクリックした回数など)の両方があります -
利点は汎化能力が高いことです。 業界に対するユーザーの好みは、その業界の同じ統計的特徴を持つ他のユーザーにも一般化できます。 -
欠点は、記憶力の欠如により識別力が低下することです。 たとえば、同じ統計的特性を持つ 2 人のユーザーの行動に大きな違いがある可能性があります。 さらに、連続値特徴量では、多くの手動特徴量エンジニアリングも必要になります。
-
離散値の特徴は、きめの細かい特徴です。 数え切れないもの(ユーザーの性別、業界IDなど)もあれば、高次元のもの(ユーザーID、広告IDなど)もあります。 -
記憶力が強く、識別力が高いのが利点です。 離散値の特徴を組み合わせて、横断的および協調的な情報を学習することもできます。 -
欠点は汎化能力が比較的弱いことです。
-
ワンホットエンコーディング -
特徴の埋め込み (エンベディング)
-
機能の競合: 語彙サイズの設定が大きすぎると、トレーニング効率が急激に低下し、メモリ OOM が原因でトレーニングが失敗します。 したがって、10 億レベルのユーザー ID 離散値特徴量であっても、100,000 レベルの ID ハッシュ空間しか設定されません。ハッシュの競合率が高く、特徴量情報が破損し、オフライン評価による利点はありません。 -
非効率な IO: ユーザー ID や広告 ID などの特徴は高次元で疎であるため、つまり、トレーニング中に更新されるパラメーターは全体のごく一部にすぎないため、TensorFlow の独自の静的埋め込みメカニズムでは、モデルへのアクセスを処理する必要があります。高密度 Tensor 全体は膨大な IO オーバーヘッドをもたらし、疎な大規模モデルのトレーニングをサポートできません。
02
広告がまばらな大規模モデルの実践
-
TFRA API は Tensorflow エコシステムと互換性があり (オリジナルのオプティマイザーとイニシャライザーを再利用し、API は同じ名前と一貫した動作を持ちます)、TensorFlow がよりネイティブな方法で ID タイプの疎な大規模モデルのトレーニングと推論をサポートできるようにします。 学習と使用のコストは低く、アルゴリズム エンジニアのモデリング習慣を変えることはありません。 -
動的なメモリの拡張と縮小により、トレーニング中のリソースが節約され、 ハッシュの競合が効果的に回避され、特徴情報のロスレスが保証されます。
-
静的埋め込みは動的埋め込みにアップグレードされます。 離散値特徴の人工ハッシュ ロジックの場合、TFRA 動的埋め込みはパラメーターの保存、アクセス、更新に使用されます。これにより、すべての離散値特徴の埋め込みがアルゴリズム フレームワーク内で競合しないことが保証され、すべての離散値を保証する 特徴のロスレス学習。 -
高次元スパース ID 機能の使用: 前述したように、TensorFlow の静的 Embedding 機能を使用する場合、ユーザー ID と広告 ID 機能は、ハッシュの競合によりオフライン評価では利益がありません。 アルゴリズム フレームワークがアップグレードされた後、ユーザー ID と広告 ID の機能が再導入され、オフラインとオンラインの両方でプラスのメリットが得られます。 -
高次元のスパース結合 ID 機能の使用: ユーザー ID と業界 ID およびアプリ パッケージ名とのそれぞれの組み合わせなど、ユーザー ID と広告の粗粒 ID の結合離散値機能を導入します。 同時に、機能アクセス機能と組み合わせて、よりスパースなユーザー ID と広告 ID の組み合わせを使用する個別の機能が導入されます。

2. モデルのアップデート
-
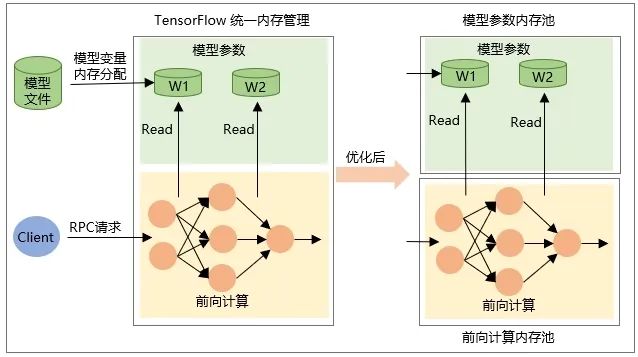
モデルが復元されるときの Tensor 変数自体の割り当て。つまり、モデルがロードされるときにメモリが割り当てられ、モデルがアンロードされるときにメモリが解放されます。 -
中間出力 Tensor のメモリは、RPC リクエスト中のネットワーク転送計算中に割り当てられ、リクエスト処理の完了後に解放されます。
03
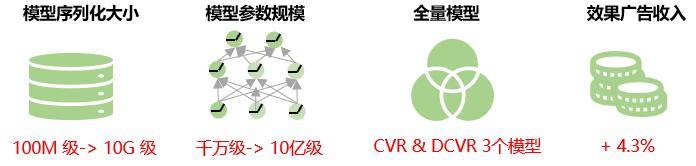
全体的な利益
04
今後の展望
現在、大規模な広告スパース モデル内の同じ特徴のすべての特徴値には、同じ埋め込みディメンションが与えられます。実際のビジネスでは、高次元特徴のデータ分布は非常に不均一であり、非常に少数の高頻度特徴が非常に高い割合を占め、すべての特徴値に対して固定の埋め込み次元を使用すると、ロングテール現象が深刻になります。埋め込み表現の学習能力が低下します。つまり、低周波の特徴の場合、埋め込み次元が大きすぎるため、モデルは過剰適合の危険にさらされます。高周波の特徴の場合は、表現して学習する必要がある情報が豊富にあるため、埋め込みの次元が大きすぎます。寸法が小さすぎるため、モデルがアンダーフィッティングになる危険性があります。したがって、将来的には、モデル予測の精度をさらに向上させるために、特徴の埋め込み次元を適応的に学習する方法を検討します。
同時に、モデルの増分エクスポートのソリューションを検討します。つまり、増分トレーニング中に変更されるパラメーターのみを TensorFlow Serving にロードすることで、モデル更新中のネットワーク送信とロード時間を削減し、分単位の更新を実現します。疎な大規模モデルの構築と、モデルのリアルタイム性の向上。

この記事は、WeChat パブリック アカウント - iQIYI テクノロジー製品チーム (iQIYI-TP) から共有されたものです。
侵害がある場合は、削除について [email protected] までご連絡ください。
この記事は「OSC ソース作成計画」に参加していますので、読んでいる方もぜひ参加して共有してください。
{{名前}}
{{名前}}