目次
オリジナル:https://blog.csdn.net/yutianzuijin/article/details/41912871
今日は、プログラムのパフォーマンスを最適化する比較的新しい方法であるHugePagesを紹介します。簡単に言うと、オペレーティングシステムのページのサイズを大きくしてページテーブルを縮小し、高速テーブルの損失を回避することです。この分野の情報は比較的貧弱であり、インターネット上のほとんどの情報はそのアプリケーションをOracleデータベースに導入しているため、このテクノロジーはOracleデータベースにしか適用できないという幻想を人々に与えます。しかし実際には、巨大なページメモリは、幅広いアプリケーションを備えた非常に一般的な最適化テクノロジと見なすことができます。さまざまなアプリケーションで、パフォーマンスが最大50%向上する可能性があり、最適化の効果は依然として非常に明白です。このブログでは、特定の例を使用して、大きなページメモリの使用を紹介します。
導入する前に、大きなページメモリにも適用範囲があることを強調する必要があります。プログラムはメモリをほとんど消費しないか、プログラムのメモリアクセスの局所性が非常に優れています。大きなページメモリのパフォーマンスを向上させることは困難です。したがって、直面しているプログラム最適化問題に上記の2つの特性がある場合は、大きなページメモリを考慮しないでください。後で、上記の2つの特性を持つプログラムの大きなページメモリが無効である理由について詳しく説明します。
1. 背景
最近、社内で音楽の聴取・認識プロジェクトの開発に携わっています。詳しくは、捜狗音声クラウドオープンプラットフォーム上にある指紋による音楽検索をご覧ください。開発プロセス中に、非常に深刻なパフォーマンスの問題が発生しました。パフォーマンスはシングルスレッドテストの要件を満たすことができますが、マルチスレッドストレステストを実行すると、アルゴリズムの最も時間のかかる部分が突然いくつかになります。何倍も遅くなります!注意深くデバッグした後、最も影響力のあるパフォーマンスはコンパイラオプション-pgであることがわかりました。これを削除すると、パフォーマンスははるかに向上しますが、シングルスレッドのパフォーマンスよりも約2倍遅くなり、実際のパフォーマンスが発生します。 -システムが1.0以上に達するまでの時間率。、応答性が大幅に低下します。
より注意深く分析したところ、システムの最も時間のかかる部分は指紋ライブラリにアクセスするプロセスであることがわかりましたが、この部分には最適化の余地がまったくなく、より高いメモリ帯域幅のマシンにしか切り替えることができません。 。より高いメモリ帯域幅のマシンに切り替えると、パフォーマンスが大幅に向上しましたが、それでも要件を満たすことができませんでした。山が使い果たされたちょうどその時、MSRAのChuntao Hong博士は、ランダム配列のアクセス問題を最適化するために大きなページメモリを使用し、非常に優れたパフォーマンスの向上を得たとMSRAがWeiboで言及しているのを偶然見ました。それから彼に助けを求めましたが、最後に、ページメモリを大きくする方法でシステムパフォーマンスがさらに向上し、リアルタイムレートは約0.4に低下しました。目標を達成しました!
2.指紋ベースの音楽検索の概要
検索プロセスは実際には検索エンジンと同じであり、音楽の指紋は検索エンジンのキーワードに相当し、指紋データベースは検索エンジンのバックグラウンドWebページライブラリに相当します。指紋データベースの構造は、転置インデックス形式を採用した検索エンジンのウェブページデータベースと同じです。以下に示すように:

図1指紋ベースの転置インデックステーブル
指紋がすべてint型の整数(図は24ビットしか占有しない)であり、情報が少なすぎるため、一致を完了するには大量の指紋を抽出する必要があります。これは1秒あたり約数千です。次の図に示すように、フィンガープリントを取得するたびに、フィンガープリントライブラリにアクセスして対応する転置リストを取得し、音楽IDに従って転送リストを作成して、一致する音楽を分析する必要があります。
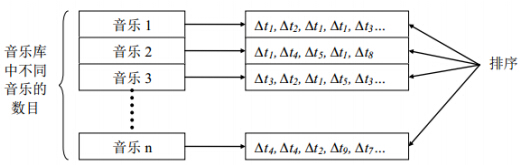
図2統計的マッチングの類似性
最終結果は、最高ランクの結果を持つ音楽です。
現在の指紋データベースは約60Gで、これは25wの曲の指紋を抽出した結果です。各フィンガープリントに対応する転置リストの長さは固定されていませんが、上限は7500です。最前列の曲の数も25wで、各曲に対応する最長の時差の数は8192です。1回の検索で約1000個(またはそれ以上)の指紋が生成されます。
上記の紹介から、指紋ベースの音楽検索(曲の聴取と音楽の認識)には、1。指紋の抽出、2。指紋ライブラリへのアクセス、3。時差の並べ替えの3つの部分があることがわかります。マルチスレッドの場合、これら3つの部分の時間のかかる比率は約1%、80%、および19%です。つまり、ほとんどの時間は指紋ライブラリの検索操作に費やされます。さらに厄介なのは、指紋ライブラリへのすべてのアクセスが順不同であり、局所性がまったくないため、キャッシュが常に欠落しており、従来の最適化方法は効果がなく、次のようにしか置き換えることができないことです。より高いメモリ帯域幅を持つサーバー。
ただし、これはまさに上記の特性によるものです。大量のメモリ消費(約100G)、順不同のメモリアクセス、メモリアクセスがボトルネックであるため、大きなページメモリは上記のパフォーマンスのボトルネックを最適化するのに特に適しています。
3.原則
大容量ページメモリの原則には、オペレーティングシステムの仮想アドレスから物理アドレスへの変換プロセスが含まれます。複数のプロセスを同時に実行するために、オペレーティングシステムは各プロセスに仮想プロセススペースを提供します.32ビットオペレーティングシステムでは、プロセススペースサイズは4G、64ビットシステムは2 ^ 64です(実際には、この値よりも小さい場合があります)。長い間、私はこれについて非常に混乱してきました。たとえば、両方のプロセスがアドレス0x00000010にアクセスする場合、これにより、複数のプロセスによるメモリアクセスで競合が発生しますか。実際、各プロセスのプロセススペースは仮想であり、物理アドレスと同じではありません。2つは同じ仮想アドレスにアクセスしますが、物理アドレスへの変換後は異なります。この変換はページテーブルを介して実現され、関連する知識はオペレーティングシステムのページングストレージ管理です。
ページングストレージ管理は、プロセスの仮想アドレス空間をいくつかのページに分割し、各ページに番号を付けます。これに対応して、物理メモリ空間もいくつかのブロックに分割され、それらにも番号が付けられます。ページとブロックのサイズは同じです。各ページのサイズが4Kであるとすると、32ビットシステムのページングアドレス構造は次のようになります。

プロセスがメモリ内の仮想ページに対応する実際の物理ブロックを確実に見つけることができるようにするには、プロセスごとにイメージテーブル、つまりページテーブルを維持する必要があります。ページテーブルには、図3に示すように、メモリ内の各仮想ページに対応する物理ブロック番号が記録されます。ページテーブルを設定した後、プロセスを実行すると、テーブルを検索することで、メモリ内の各ページの物理ブロック番号を見つけることができます。
ページテーブルレジスタはオペレーティングシステムに設定され、メモリにページテーブルの開始アドレスとページテーブルの長さを格納します。プロセスが実行されていないときは、ページテーブルの開始アドレスとページテーブルの長さがプロセスのPCBに配置されます。スケジューラがプロセスをスケジュールすると、これら2つのデータがページテーブルレジスタにロードされます。
プロセスが特定の仮想アドレスのデータにアクセスする場合、ページングアドレス変換メカニズムは、実効アドレス(相対アドレス)をページ番号とページ内のアドレスの2つの部分に自動的に分割し、ページ番号をページテーブルを取得して検索するためのインデックス操作はハードウェアによって実行されます。指定されたページ番号がページテーブルの長さを超えない場合は、ページ番号とページテーブルエントリの長さの積にページテーブルの開始アドレスを追加して、ページテーブル内のエントリの位置を取得します。次に、物理ページをブロックアドレスから取得し、物理アドレスレジスタにロードします。同時に、実効アドレスレジスタのページアドレスが物理アドレスレジスタのブロックアドレスフィールドに送信されます。これで、仮想アドレスから物理アドレスへの変換が完了します。
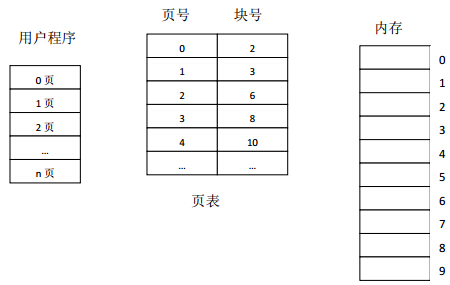
図3ページテーブルの役割
ページテーブルはメモリに格納されているため、CPUはデータにアクセスするたびに2回メモリにアクセスします。メモリ内のページテーブルに初めてアクセスすると、指定したページの物理ブロック番号が検出され、ブロック番号がページ内のオフセットとスプライスされて物理アドレスが形成されます。2回目のメモリアクセス時には、1回目に取得したアドレスから必要なデータを取得します。したがって、この方法を使用すると、コンピューターの処理速度が約1/2に低下します。
アドレス変換の速度を向上させるために、並列ルックアップ機能を備えた特別な高速キャッシュをアドレス変換メカニズム、つまり現在アクセスされているページテーブルエントリを格納するために使用される高速テーブル(TLB)に追加できます。 。高速テーブルを使用したアドレス変換メカニズムを図4に示します。コストがかかるため、高速テーブルを非常に大きくすることはできません。通常、16〜512ページのテーブルエントリのみが格納されます。
上記のアドレス変換メカニズムは、中小規模のプログラムで非常にうまく機能します。高速テーブルのヒット率は非常に高いため、パフォーマンスの低下はあまりありませんが、プログラムが大量のメモリを消費し、高速テーブルのヒット率が高くない場合は、問題が発生します。
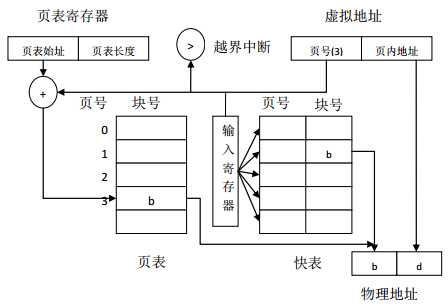
図4高速テーブルを使用したアドレス変換メカニズム
4.小さなページのジレンマ
最新のコンピュータシステムはすべて、非常に大きな仮想アドレス空間(2 ^ 32〜2 ^ 64)をサポートしています。このような環境では、ページテーブルが非常に大きくなります。たとえば、ページサイズが4Kであるとすると、40Gのメモリを占有するプログラムの場合、ページテーブルサイズは10Mであり、スペースも連続している必要があります。スペースの連続性の問題を解決するために、2レベルまたは3レベルのページテーブルを導入できます。ただし、これはパフォーマンスにさらに影響します。これは、高速テーブルが欠落している場合、ページテーブルにアクセスする回数が2回から3回または4回に変わるためです。プログラムがアクセスできるメモリスペースは非常に大きいため、プログラムのメモリアクセスの局所性が良くないと、高速テーブルが常に失われ、パフォーマンスに深刻な影響を及ぼします。
さらに、ページテーブルエントリは最大10Mであり、高速テーブルは数百ページしかキャッシュできないため、プログラムのメモリアクセスパフォーマンスが非常に優れていても、高速テーブルが欠落する可能性は非常に高くなります。大量のメモリを消費する場合。それで、不足している高速テーブルを解決するための良い方法はありますか?巨大なページメモリ!ページサイズを1Gに変更し、40Gメモリのページテーブルエントリがわずか40であり、高速テーブルがまったく失われないとします。欠落している場合でも、エントリが少ないため、第1レベルのページテーブルを使用できます。欠落していると、メモリフェッチが2回だけ発生します。これが、大きなページメモリがプログラムのパフォーマンスを最適化できる根本的な理由です。高速テーブルが失われることはほとんどありません。
最適化するプログラムがメモリをほとんど消費しない場合、またはメモリアクセスの局所性が非常に優れている場合、大きなページメモリの最適化効果は非常に重要ではないことを前述しました。ここで、その理由を理解する必要があります。プログラムがメモリをほとんど消費しない場合(数メガバイトなど)、ページテーブルエントリはほとんどなく、高速テーブルは完全にキャッシュされる可能性が高く、欠落している場合でも、第1レベルのページに置き換えることができます。テーブル。プログラムのメモリアクセスの局所性も非常に良好である場合、一定期間内に、プログラムは隣接するメモリにアクセスし、高速テーブルが欠落する可能性も非常に低くなります。したがって、上記の2つのケースでは、高速テーブルが欠落しにくいため、巨大なページメモリには利点がありません。
5.大容量ページメモリの構成と使用
大容量ページメモリを導入する場合、インターネット上の多くの情報がOracleデータベースでの使用に伴います。これにより、大容量ページメモリはOracleデータベースでのみ使用できるという幻想が生まれます。上記の分析から、実際には、大きなページメモリが非常に一般的な最適化手法であることがわかります。その最適化方法は、高速テーブルの欠落を回避することです。そのため、具体的にどのように適用するか、使用する手順を以下に詳しく説明します。
1.libhugetlbfsライブラリをインストールします
libhugetlbfsライブラリは、大きなページメモリアクセスを実装します。インストールはapt-getまたはyumコマンドで実行できます。システムにこのコマンドがない場合は、公式Webサイトからダウンロードすることもできます。
Linuxでのlibhugetlbfsの使用:https ://www.dazhuanlan.com/2019/11/22/5dd71081e318e/
2.grubスタートアップファイルを構成します
このステップは非常に重要です。割り当てる各ラージページのサイズとラージページの数を決定します。特定の操作は、図5に示すように、/ etc /grub.confファイルを編集することです。

図5grub.conf起動スクリプト
具体的には、カーネルオプションの最後にいくつかの起動パラメータを追加します:transparent_hugepage = never default_hugepagesz = 1Ghugepagesz = 1Ghugepages = 123。これらの4つのパラメーターのうち、最も重要なのは後者の2つです。hugepageszは各ページのサイズを設定するために使用されます。1Gに設定します。その他のオプション構成は4Kと2Mです(2Mがデフォルトです)。オペレーティングシステムのバージョンが低すぎると、1Gページの設定が失敗する可能性があります。設定が失敗する場合は、オペレーティングシステムのバージョンを確認してください。Hugepagesは、巨大なページメモリのページ数を設定するために使用されます。システムメモリは128Gで、現在は123Gが巨大なページを処理するために割り当てられています。ここで、割り当てられた巨大なページは従来のプログラムには見えないことに注意してください。たとえば、システムにはまだ5Gの通常のメモリが残っています。このとき、従来の方法で10Gを消費するプログラムを起動すると、失敗します。 。grub.confを変更した後、システムを再起動します。次に、コマンドcat / proc / meminfo | grep Hugeを実行して、巨大なページ設定が有効かどうかを確認します。有効な場合は、次のコンテンツが表示されます。
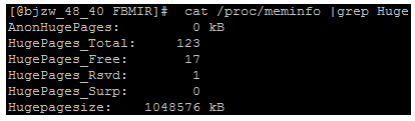
図6大きなページの現在の消費量
私たちは、HugePages_Totalがラージ・ページの現在の総数は、言った、これらの値の4に焦点を当てる必要がありますHugePages_Freeは、プログラムの起動および実行だけでなく、大規模なページの残りの数後に発現、HugePages_Rsvdは、現在のシステムのhugepages総保持の数を表し、より具体的には、ポイントはプログラムが適用されたことを示しますが、プログラムには実質的なHugePagesの読み取りおよび書き込み操作がないため、システムは実際にはHugePagesの数をプログラムに割り当てていません。Hugepagesizeは、各巨大ページのサイズを表します。ここでは1GBです。
実験で問題が見つかりました。Freeの値とRsvdの値は、文字通りの意味とは異なる場合があります。申請した大きなページではプログラムを最初から開始するのに十分でない場合、システムは次のエラーを表示します。
ibhugetlbfs:警告:0x40000000の新しいヒープセグメントマップが失敗しました:メモリを割り当てることができません
この時点で、上記の4つの値をもう一度見ると、次のような状況が見つかります:HugePages_Freeはaに等しく、HugePages_Rsvdはaに等しい。これは人々を非常に奇妙に感じさせます。明らかにまだ大きなページが残っていますが、システムは大きなページの割り当てが失敗したことを示すエラーを報告します。何度も試みた結果、Rsvdの大きなページをFreeに含める必要があると考えているため、FreeがRsvdと等しい場合、実際には大きなページはありません。無料マイナスRsvdは、再度割り当てることができる巨大なページです。たとえば、図6には、割り当てることができる16個の大きなページがあります。
いくつの大きなページを割り当てるのが適切ですか?これには複数回の試行が必要です。私たちが学んだ経験では、サブスレッドによる大きなページの使用は非常に無駄です。メインスレッドのすべてのスペースを割り当ててから割り当てるのが最善です。各サブスレッドにそれを。スレッド、これは大きなページの無駄を大幅に減らします。
3.マウント
mountを実行して、大きなページメモリを空のディレクトリにマップします。次のコマンドを実行できます。
if [ ! -d /search/music/libhugetlbfs ]; then
mkdir /search/music/libhugetlbfs
fi
mount -t hugetlbfs hugetlbfs /search/music/libhugetlbfs
4.アプリケーションを実行します
大きなページを有効にするには、通常の方法でアプリケーションを起動することはできません。次の形式で起動する必要があります。
HUGETLB_MORECORE = yes LD_PRELOAD = libhugetlbfs .so ./your_program
このメソッドは、libhugetlbfsライブラリをロードして、標準ライブラリを置き換えます。具体的な操作は、標準のmallocを大きなページのmallocに置き換えることです。この時点で、プログラムによって要求されるメモリは巨大なページメモリです。
上記の4つの手順に従って、ラージページメモリを有効にします。これにより、ラージページを簡単に有効にできます。
6.大容量ページメモリの最適化効果
アプリケーションが故障している場合、メモリアクセスが非常に深刻である場合、大きなページメモリは比較的大きなメリットをもたらします。現在、曲を聴いていて、音楽を認識することはそのようなアプリケーションであるため、最適化の効果は明らかです。以下は音楽ライブラリが25wの場合、大きなページがある場合とない場合のプログラムの実行が有効になっている場合です。
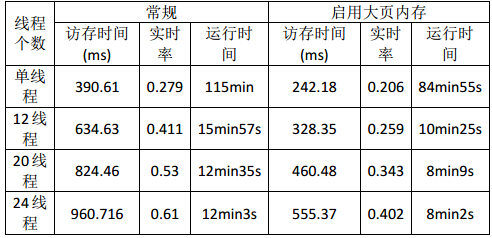
大容量ページメモリを有効にすると、プログラムのアクセス時間が大幅に短縮され、パフォーマンスが50%近く向上し、パフォーマンス要件を満たしていることがわかります。
7.大容量ページメモリの使用シナリオ
どの最適化方法にもその適用範囲があり、大きなページメモリも例外ではありません。巨大なメモリ、ランダムアクセス、およびメモリアクセスを消費する巨大なページメモリだけがプログラムのボトルネックであり、パフォーマンスが大幅に向上することを常に強調してきました。私たちのリスニングおよび認識音楽システムでは、メモリ消費量は100Gに近く、メモリアクセスはすべて順不同のアクセスであるため、パフォーマンスが大幅に向上します。オンラインの例でOracleデータベースを例として使用しているのは不合理ではありません。これは、Oracleデータベースによって消費されるメモリも膨大であり、データベースの追加、削除、および変更に局所性がないためです。データベースの背後にある追加、削除、および変更は、基本的にBツリーに対する操作であり、ツリー操作は一般に局所性を欠いています。
地域性の悪いプログラムはどのようなものですか?個人的には、ハッシュやツリー戦略を使って実装したプログラムは、メモリアクセスの局所性が低いことが多いと思います。現時点では、プログラムのパフォーマンスが良くない場合は、大きなページメモリを試すことができます。逆に、単純な配列トラバーサルやグラフ幅トラバーサルなどの操作は、メモリアクセスの局所性が高く、大きなページメモリを使用してパフォーマンスを向上させることは困難です。パフォーマンスの向上を期待して、捜狗音声認識デコーダーで大容量ページメモリを有効にしようとしましたが、効果は期待外れで、パフォーマンスは向上しません。これは、音声認識デコーダーが本質的に画像の幅広い検索であり、メモリアクセスの局所性が良好であり、メモリアクセスがパフォーマンスのボトルネックではないためです。現時点では、大きなページメモリを使用すると、他のオーバーヘッドが発生し、パフォーマンスが低下する可能性があります。
8.まとめ
このブログでは、音楽を聴いたり認識したりする例とともに、大容量ページメモリの原理と使い方を詳しく紹介しています。ビッグデータの急増により、現在のアプリケーションで処理されるデータ量が増加し、データアクセスがますます不規則になり、このような状況で大容量ページのメモリを使用できるようになっています。したがって、プログラムの実行速度が遅く、大きなページメモリの使用条件を満たす場合は、試してみてください。とにかく、それは非常に単純で、良い結果が得られる場合に備えて損失はありません。
LD_PRELOADの使用法
(英文:https://catonmat.net/simple-ld-preload-tutorial)
LD_PRELOADは、ダイナミックライブラリのロードに使用される環境変数です。ダイナミックライブラリのロードの優先度が最も高くなります。通常、ロードの順序はLD_PRELOAD> LD_LIBRARY_PATH> /etc/ld.so.cache> / lib> / usr / libです。プログラムでは、多くの場合、いくつかの外部ライブラリ関数を呼び出す必要があります。例としてmallocを取り上げます。カスタムmalloc関数がある場合は、それをダイナミックライブラリにコンパイルし、LD_PRELOADを介してロードします。malloc関数がプログラムで呼び出されると、呼び出しは実際にはカスタム関数です。例を挙げて説明しましょう。
// test.c
#include <stdio.h>
#include <stdlib.h>
int main()
{
int i = 0;
for (; i < 5; ++i) {
char *c = (char*)malloc(sizeof(char));
if (NULL == c) {
printf("malloc fails\n");
}
else {
printf("malloc ok\n");
}
}
return 0;
}コンパイルして実行すると、結果は次のようになります。
$gcc -o test test.c
$./test
malloc ok
malloc ok
malloc ok
malloc ok
malloc okプログラムの実行に問題がないことがわかります。少し変更を加えてmallocをカスタマイズします。
// preload.c
#include <stdio.h>
#include <stdlib.h>
void* malloc(size_t size)
{
printf("%s size: %lu\n", __func__, size);
return NULL;
}次に、カスタムmallocをダイナミックライブラリとしてパッケージ化します。
$gcc -shared -fpic -o libpreload.so preload.c次に、LD_PRELOADを使用してlibpreload.soをロードし、何が起こるかを確認します。
$LD_PRELOAD=./libpreload.so ./test
malloc size: 1
malloc fails
malloc size: 1
malloc fails
malloc size: 1
malloc fails
malloc size: 1
malloc fails
malloc size: 1
malloc failsご覧のとおり、mallocは5回NULLを返します(つまり、自分で定義したmallocと呼びます)。LD_PRELOADがトリックを実行していることがわからない場合は、長い理由を見つけることができない可能性があります。分析後の時間。このLD_PRELOADは両刃の剣です。上手に使えば助かります。下心があると意外な驚きがあります。
「注意してくださいのLD_PRELOADの環境変数の下でUNIX」https://blog.csdn.net/haoel/article/details/1602108