K-means クラスタリング アルゴリズム
1. 実験目的
- K 平均法クラスタリング アルゴリズムについてよく理解してください。
- トレーニング サンプル セットに対して K 平均法クラスタリングのプログラムを作成し、タスク関連データに対して K 平均法クラスタリング アルゴリズムを実行して、実験をデバッグします。
- 距離の計算方法やクラスタリングの評価基準をマスターしましょう。
- 研究室のレポートを書きます。
2. 実験原理
1. K 平均法クラスタリング
K 平均法クラスタリングは重心ベースの分割手法であり、具体的な反復計算手順は次のとおりです。
- K 個の重心座標が属性ベクトル空間にランダムに生成されます。
- データセット D 内の各データオブジェクトTi (1 ≤ i ≤ n ) T_i (1\leq i\leq n) を個別に計算します。T私は( 1≤私≤n )全てのkkへk 個の重心の距離測定 D ist ( i , j ) ( 1 ≤ i ≤ n , 1 ≤ j ≤ k ) Dist (i,j) (1\leq i\leq n, 1\leq j\leq k)Dis t ( i , _ _j ) ( 1≤私≤n 、1≤j≤k ) を実行し、データ オブジェクトT i T_iT私は最小距離メトリックを使用してクラスターに集まります。つまり、T i ∈ CJ T_i\in C_JT私は∈CJ、データ オブジェクトT i T_iを表します。T私はJJに集まったクラスターJでは、ここで、J = arg min ( D ist ( i , j ) ) J=\argmin(Dist(i,j))J=a r gmin (Dist(i, _ _ __j ) )、JJJ は次のようなものですD ist (i, j) Dist(i,j)Dis t ( i , _ _j )は最小値jjj。
- 重心の定義に従って各クラスターの重心座標を計算し、次世代kkを形成しますkの重心座標。
- 終了条件が満たされていない場合は 2) に進み反復を続行し、終了条件が満たされていない場合は終了します。
その中で、クラスターの重心はさまざまな定義を持つことができます。たとえば、クラスター内のデータ オブジェクトの属性ベクトルの平均値 (つまり、重心) にすることも、中心点にすることもできます。など; 距離の尺度にはさまざまな定義もあり、一般的に使用されるものは、ユークリッド距離、マンハッタン (または都市街区、街区) 距離、ミンコフスキー距離などです。終了条件は、オブジェクトの再割り当てができなくなった場合です。が発生すると、プログラムの繰り返しが終了します。
2. 終了条件
終了条件は次のいずれかになります。
- 別のクラスターに再割り当てされるオブジェクトはありません (または最小限のオブジェクト)。
- クラスター センターの変更はもうありません (または最小限の数)。
- 二乗誤差の合計は極小値です。
3. 実験内容と手順
1. 実験内容
- k-means クラスタリング アルゴリズムの計算手順に従って、k=3 の場合のプログラム フローチャートを描画します。
- K 平均法クラスタリング アルゴリズムは、K 平均法プログラム フローチャート プログラミングによって実装されます。
- 実験レポートに K 平均法クラスタリング プロセスの一連のスクリーンショットを表示し、各クラスターの段階的な進化を示します
。 - レポートでは、実験コードにおける初期重心の選択、終了条件の選択、
距離メトリックの選択を指摘して説明します。
2. 実験手順
プログラミングでは次の機能を実装します。
- まず、データセット D={D1,D2,D3} 内の属性ベクトルが実験データとして入力されます。
- K 平均法クラスタリング アルゴリズムは、K 平均法プログラム フローチャートによってプログラムされ、実験データを使用して実行されます。
実行プロセス中、適切な反復代数で一時停止し、クラスターの中心の位置、最近傍までの距離によるクラスター化の結果など、リアルタイムの反復の結果を表示します。
3. プログラムブロック図
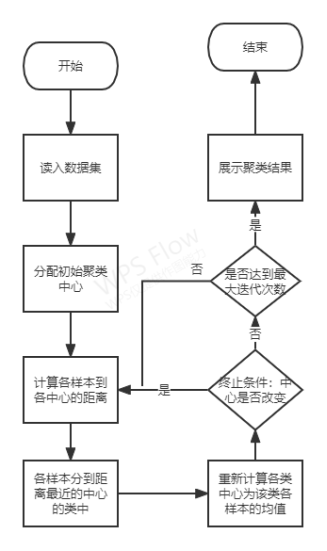
ブロック図
4. 実験サンプル
データ.txt
5. 実験コード
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# Copyright (C) 2021 #
# @Time : 2022/5/30 21:29
# @Author : Yang Haoyuan
# @Email : [email protected]
# @File : Exp5.py
# @Software: PyCharm
import math
import random
import argparse
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import calinski_harabasz_score
parser = argparse.ArgumentParser(description="Exp5")
parser.add_argument("--epochs", type=int, default=100)
parser.add_argument("--k", type=int, default=3)
parser.add_argument("--n", type=int, default=2)
parser.add_argument("--dataset", type=str, default="data.txt")
parser.set_defaults(augment=True)
args = parser.parse_args()
print(args)
# 读取数据集
def loadDataset(filename):
dataSet = []
with open(filename, 'r') as file_to_read:
while True:
lines = file_to_read.readline() # 整行读取数据
if not lines:
break
p_tmp = [str(i) for i in lines.split(sep="\t")]
p_tmp[len(p_tmp) - 1] = p_tmp[len(p_tmp) - 1].strip("\n")
for i in range(len(p_tmp)):
p_tmp[i] = float(p_tmp[i])
dataSet.append(p_tmp)
return dataSet
# 计算n维数据间的欧式距离
def euclid(p1, p2, n):
distance = 0
for i in range(n):
distance = distance + (p1[i] - p2[i]) ** 2
return math.sqrt(distance)
# 初始化聚类中心
def init_centroids(dataSet, k, n):
_min = dataSet.min(axis=0)
_max = dataSet.max(axis=0)
centre = np.empty((k, n))
for i in range(k):
for j in range(n):
centre[i][j] = random.uniform(_min[j], _max[j])
return centre
# 计算每个数据到每个中心点的欧式距离
def cal_distance(dataSet, centroids, k, n):
dis = np.empty((len(dataSet), k))
for i in range(len(dataSet)):
for j in range(k):
dis[i][j] = euclid(dataSet[i], centroids[j], n)
return dis
# K-Means聚类
def KMeans_Cluster(dataSet, k, n, epochs):
epoch = 0
# 初始化聚类中心
centroids = init_centroids(dataSet, k, n)
# 迭代最多epochs
while epoch < epochs:
# 计算欧式距离
distance = cal_distance(dataSet, centroids, k, n)
classify = []
for i in range(k):
classify.append([])
# 比较距离并分类
for i in range(len(dataSet)):
List = distance[i].tolist()
# 因为初始中心的选取完全随机,所以存在第一次分类,类的数量不足k的情况
# 这里作为异常捕获,也就是distance[i]=nan的时候,证明类的数量不足
# 则再次递归聚类,直到正常为止,返回聚类标签和中心点
try:
index = List.index(distance[i].min())
except:
labels, centroids = KMeans_Cluster(dataSet=np.array(data_set), k=args.k, n=args.n, epochs=args.epochs)
return labels, centroids
classify[index].append(i)
# 构造新的中心点
new_centroids = np.empty((k, n))
for i in range(len(classify)):
for j in range(n):
new_centroids[i][j] = np.sum(dataSet[classify[i]][:, j:j + 1]) / len(classify[i])
# 比较新的中心点和旧的中心点是否一样
if (new_centroids == centroids).all():
# 中心点一样,停止迭代
label_pred = np.empty(len(data_set))
# 返回个样本聚类结果和中心点
for i in range(k):
label_pred[classify[i]] = i
return label_pred, centroids
else:
centroids = new_centroids
epoch = epoch + 1
# 聚类结果展示
def show(label_pred, X, centroids):
x = []
for i in range(args.k):
x.append([])
for k in range(args.k):
for i in range(len(label_pred)):
_l = int(label_pred[i])
x[_l].append(X[i])
for i in range(args.k):
plt.scatter(np.array(x[i])[:, 0], np.array(x[i])[:, 1], color=plt.cm.Set1(i % 8), label='label' + str(i))
plt.scatter(x=centroids[:, 0], y=centroids[:, 1], marker='*', label='pred_center')
plt.legend(loc=3)
plt.show()
if __name__ == "__main__":
# 读取数据
data_set = loadDataset(args.dataset)
# 原始数据展示
plt.scatter(np.array(data_set)[:, :1], np.array(data_set)[:, 1:])
plt.show()
# 获取聚类结果
labels, centroids = KMeans_Cluster(dataSet=np.array(data_set), k=args.k, n=args.n, epochs=args.epochs)
print("Classes: ", labels)
print("Centers: ", centroids)
# 使用Calinski-Harabaz标准评价聚类结果
scores = calinski_harabasz_score(data_set, labels)
print("Scores: ", round(scores, 2))
# 展示聚类结果
show(X=np.array(data_set), label_pred=labels, centroids=centroids)
4. 実験結果
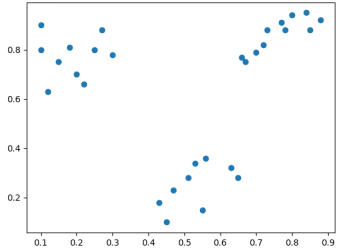
元のデータ分布散布図
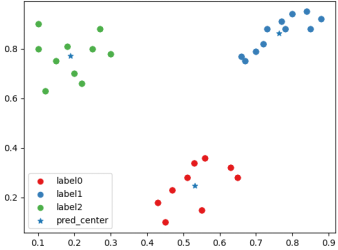
「良好な」クラスタリング後の分類とクラスタ中心の散布図。

「良好な」クラスタリング後のクラスタ ラベル、クラスタ中心および CH インデックス スコアの散布図。
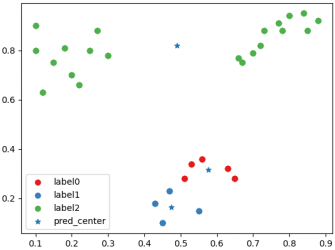
「不良」クラスタリング後の分類の散布図。およびクラスタ中心

。 「悪い」クラスタリングのポストクラスターラベル、クラスターセンター、および CH インデックススコアの状況
5. 実験分析
この実験は主に K-Means アルゴリズムの実装に関するものです。
サンプル間の距離については、ユークリッド距離メトリックを採用します。これは、古典的な K 平均法アルゴリズムで非常に効果的であることが証明されている類似性および非類似性メトリックです。
プログラムの実行時間が長すぎる原因となるいくつかの非収束状況は別にして、クラスターの中心が変更されなくなるか、反復回数が上限に達することを終了条件として設定しました。
クラスタリング センターの初期選択は完全にランダムであるため、初めてのクラスタリング クラスの数が指定された k 未満になる場合があります。この場合は、例外処理で直接再帰を実行し、クラスタリングを再開し、再帰的クラスタリングのクラス結果に戻ります。同時に、クラスター中心のランダム性により、同じパラメーターを持つ同じデータセットであっても、クラスター化結果に大きなギャップが生じる可能性があります。クラスタリングの結果が「良い」か「悪い」かを判断するには、C alinski − H arabaz ( CH ) Calinski-Harabaz(CH)を使用します。カリンスキー_ _ _ _ _ _−H a r a b a z ( C H )基準は、クラスタリングの結果を評価します。これは、クラス間およびクラス内の共分散を評価し、クラスタリングの結果を評価するために使用される古典的なアルゴリズムです。シルエットインデックスと比較して、CH インデックスの計算が高速になります。計算式は以下の通りです。
CH = BGSS k − 1 / WGSS n − k CH=\frac{BGSS}{k-1} / \frac{WGSS}{nk}CH _=k−1B G S S/n−kWGSS _ _ _
BGSS はクラス間の共分散を指し、WGSS はクラス内の共分散を指します。優れたクラスタリングでは、CH インデックスが局所的または全体的な最大値に達するように、クラス間共分散が大きく、クラス内共分散が小さくなければなりません。実験結果から、経験的に優れたクラスタリング結果はより大きな CH スコアを持つことがわかります。