クラスタリングアルゴリズム
学習目標
- マスタークラスタリングアルゴリズムの実装プロセス
- 私たちは、理論、アルゴリズムK-手段を知っています
- 私たちは、評価モデルのクラスタリングアルゴリズムを知っています
- K-手段の長所と短所
- 道クラスタリングアルゴリズムの最適化を理解します
- アプリケーション関数kmeansクラスタリングタスクを達成

6.3クラスタリングアルゴリズムの実装工程
K-手段は、実際には2つの要素が含まれています。
K:最初の中心点の数(クラスタの平面数)
手段:の平均値からの他のデータ点の中心点を見つけます
1 k平均クラスタリングステップ
- 1、K初期クラスタ中心として特徴空間のランダムなセットポイント
- 図2は、Kは、他の中心点のそれぞれについて算出された距離、未知点は、マーカカテゴリとして、最も近いクラスタ中心を選択します
- 3、次にタグに対するクラスタ中心の後、各クラスタの中心点の再計算(平均)
- 4、次に中心点として、元の新しい中心点と計算結果(重心はもはや動く)、終了、そうでなければ再びステッププロセスであれば
図は、以下の方法により達成説明しました:
![[画像は、ソースステーションは、セキュリティチェーン機構を有していてもよく、鎖が失敗ダンプ、直接アップロード(IMG-I3UuugF3-1583251071157)(../画像/ K-手段%E8%BF%87%E7%A8%ダウン画像を保存することが推奨されます8B%E5%88%86%E6%9E%90.png)]](https://img-blog.csdnimg.cn/20200304000028196.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
Kクラスタリング図の動的効果
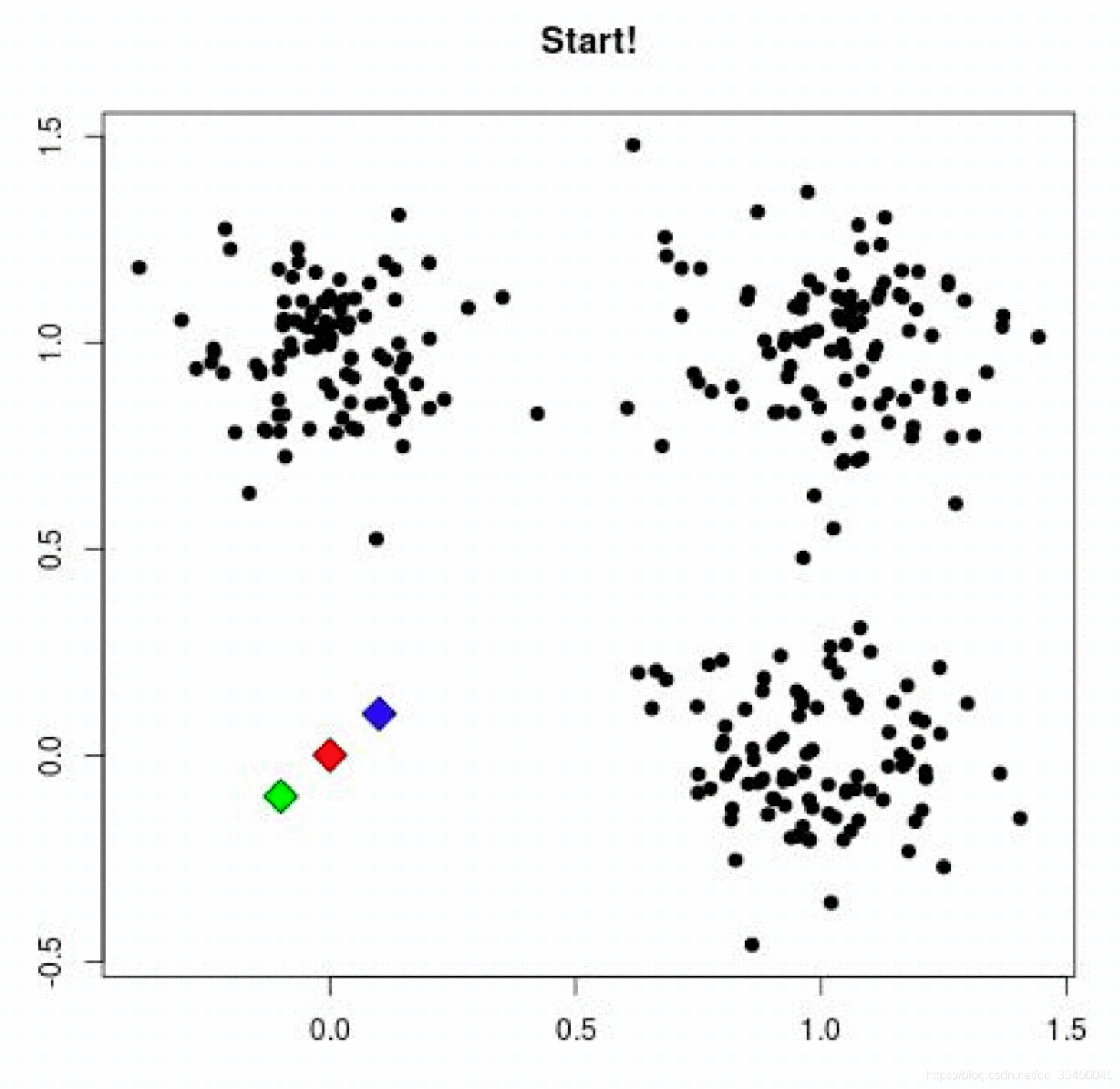
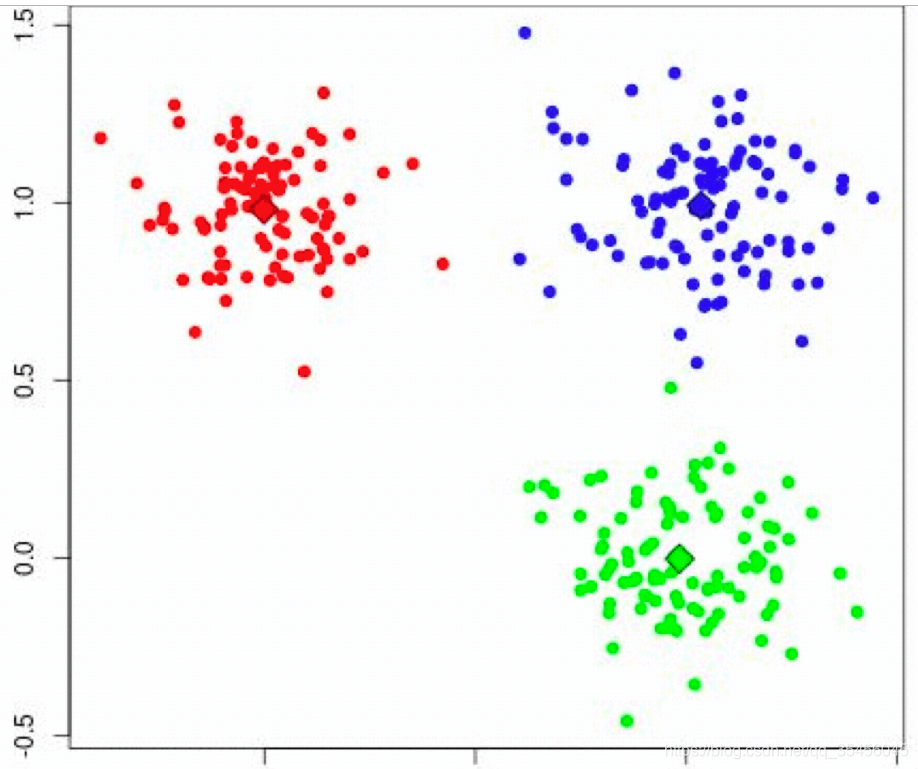
2ケース演習
- ケース:
![[画像のダンプはチェーンが失敗し、発信局は、直接アップロード(IMG-01TMWxaF-1583251071159)(../画像/ kmeans_demo1.png)ダウン画像を保存することが推奨され、セキュリティチェーン機構を有していてもよいです]](https://img-blog.csdnimg.cn/20200303235829149.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
- K初期クラスタ中心として特徴空間における1、ランダムセットポイント(この場合、P1とP2を提供)
![[画像のダンプはチェーンが失敗し、発信局は、直接アップロード(IMG-YgmP3NXH-1583251071160)(../画像/ kmeans_demo2.png)ダウン画像を保存することが推奨され、セキュリティチェーン機構を有していてもよいです]](https://img-blog.csdnimg.cn/20200303235825283.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
図2は、Kは、他の中心点のそれぞれについて算出された距離、未知点は、マーカカテゴリとして、最も近いクラスタ中心を選択します
![[画像のダンプはチェーンが失敗し、発信局は、(IMG-EKP5oNr1-1583251071160)(../画像/ kmeans_demo3.png)直接アップロードダウン画像を保存することが推奨され、セキュリティチェーン機構を有していてもよいです]](https://img-blog.csdnimg.cn/20200303235820812.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
![[画像のダンプはチェーンが失敗し、発信局は、直接アップロード(IMG-QmDvqE6m-1583251071161)(../画像/ kmeans_demo4.png)ダウン画像を保存することが推奨され、セキュリティチェーン機構を有していてもよいです]](https://img-blog.csdnimg.cn/20200303235815441.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
3、次にタグに対するクラスタ中心の後、各クラスタの中心点の再計算(平均)
![[画像のダンプはチェーンが失敗し、発信局は、直接アップロード(IMG-elAlGb9X-1583251071161)(../画像/ kmeans_demo5.png)ダウン画像を保存することが推奨され、セキュリティチェーン機構を有していてもよいです]](https://img-blog.csdnimg.cn/20200303235810907.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
[判定、反復の新しいラウンドを開始するために、上記の手順を繰り返す必要後] 4、元の中心点(重心はもはや動く)、終了として算出された新たな中心点であれば、そうでなければ再ステッププロセス
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YAbIyYrQ-1583251071162)(../images/kmeans_demo6.png)]](https://img-blog.csdnimg.cn/20200303235805817.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K1Femhd1-1583251071162)(../images/kmeans_demo7.png)]](https://img-blog.csdnimg.cn/20200303235801614.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
同じ結果が収束し、クラスタリングが完了したことを、各反復が、5、K-手段が停止され、選択プロセスに分類することができないが、質量の中心となっています。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H7VyZbqi-1583251071164)(../images/kmeans_demo8.png)]](https://img-blog.csdnimg.cn/20200303235757500.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM1NDU2MDQ1,size_16,color_FFFFFF,t_70)
3まとめ
プロセス:
- 事前に定数Kを決定し、Kはクラスタのカテゴリの定数最終的な数を意味します。
- 最初のランダム重心の初期点として選択され、各サンプルと重心(ここで、ユークリッド距離)との類似度を計算することによって、最も類似クラスに正規化サンプル点、
- 次に、再計算された各クラスタの重心(すなわち、クラスタ中心)まで、このプロセスを繰り返す重心もはや変化、
- 最終的には、各サンプルのカテゴリ属しており、各クラスの重心を決定します。
注意:
- 毎回ため試料とそれぞれの重心間の類似性の計算、その結果、K平均アルゴリズムの収束速度より遅い大規模なデータセットに。
