アルゴリズムは、クラスタリングアルゴリズムに基づく分割されたクラスタは、高い類似性を有し、およびクラスタ間の類似度が低くなるように、それは、k個のクラスタにパラメータk、n個のデータ・オブジェクトであるkは、意味します。
1.基本的な考え方
K平均アルゴリズムは、クラスタkのパーティションを構築するために、n個のデータオブジェクトのセット方法与えられたデータであり、分割された各クラスタはクラスタです。唯一つのクラスタが属するn個のクラスタにデータを分割する方法は、少なくとも1つのデータオブジェクトを有する各クラスタ、および各データオブジェクトが属している必要があります。、高い類似性の同じクラスタに小さい相似の異なるクラスタ内のデータオブジェクトをデータオブジェクトを満たしつつ。各クラスタ内の類似性を用いてクラスタリングを計算オブジェクトに意味します。
次のようにK平均アルゴリズムの処理フローです。各クラスタ中心(距離)との類似度に応じて各オブジェクトの残り、それが割り当てられます。まず、ランダムに選択されたデータオブジェクトをK、各データ、すなわち、k個の初期中心は、選択、クラスタ中心を表すオブジェクトクラスターの中心に対応する最も類似したクラスタと、各クラスタ内のすべてのオブジェクト、新しいクラスタ中心の平均値を再計算します。
収束基準機能まで、上記の手順を繰り返し、つまり、クラスタ中心が劇的に変化しません。通常、距離の二乗と最も近いクラスタ中心を最小にする、すなわち各点、平均二乗誤差基準の関数として示します。
新しいクラスタ中心の平均値を算出する方法は、すなわち、それぞれが、クラスタの中心となる点をすべてのオブジェクトの各次元の値を平均化し、クラスタ内のすべてのオブジェクトに対して計算されます。例えば、3つのデータオブジェクト{(6,4,8)、(8,2,2)、(4,6,2)を}含むクラスタは、クラスタの中心点は(6 + 4 + 8(あります)/ 3、(2 + + 6 4)/ 3、(2 + 2 + 8)/ 3)=(6,4,4)。
アルゴリズムは、2つのオブジェクト間の距離データの類似度を用いて説明kは、意味します。最も一般的に使用される明スタイル、ユークリッド距離、およびグラムから馬のタイプの距離からの距離関数は、ユークリッド距離です。
基準関数または反復の最大数は終了することができるときにアルゴリズムが最適であるkは、意味します。場合ユークリッド距離、基準関数がどのクラスタの中心間距離の二乗、そのデータオブジェクトに一般的に最小限にすること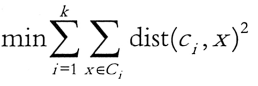 。
。
ここで、kはクラスタの数であり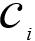 、i番目のクラスタ、DIST(の中心点である
、i番目のクラスタ、DIST(の中心点である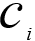 Xのに対して、X) 距離。
Xのに対して、X) 距離。
2.スパークMLlib k平均アルゴリズム
MLlib関数kmeansは、以下のパラメータを持っているスパークのアルゴリズム実装クラスをKは、意味します。
クラス関数kmeansプライベート(
プライベートするvar K:int型、
プライベートするvar maxiterations:INT、
プライベートVARラン:INT、
民間のvar initializationMode文字列
プライベートするvar initializationStep:INT、
プライベートVARイプシロン:ダブル、
プライベートするvar種:ロング)拡張:ログとシリアライズ
1)K-手段コンストラクタをMLlib
MLlibインタフェースの例として、k平均のデフォルト値で構成されています。
{K:2、maxIterations:20は、実行:1、initializationMode:KMeans.K_MEANS_PARALLEL、InitializationSteps:5、イプシロン:LE-4、シード:ランダム}。
パラメータの意味を説明しています。
| 名前 | 説明 |
|---|---|
| K | これは、クラスタの所望の数を表します。 |
| maxIterations | 単一の実行の繰り返し表現の最大数。 |
| 実行 | これは、アルゴリズムが実行された回数を表します。K平均アルゴリズムがグローバル最適なクラスタリング結果を返すことが保証されていないが、非常に多くの時間が最良のクラスタリング結果を返す支援するために設定された目標データにK-meansアルゴリズムを走りました。 |
| initializationMode | 選択方法は、現在、ランダムに選択またはK_MEANS_PARALLELモードをサポートし、デフォルトはK_MEANS_PARALLEL初期クラスタ中心を表しています。 |
| initializationsteps | K_MEANS_PARALLELは、方法のステップの数を表します。 |
| イプシロン | これは、k平均アルゴリズムの収束反復閾値を表しています。 |
| シード | これは、クラスタが初期化されたランダムシードを表します。 |
通常、アプリケーションは最初のトレーニングデータセットをクラスタ化するためKMeans.trainメソッドを呼び出しますが、このメソッドはKMeansModelクラスのインスタンスを返し、その後、新しいデータオブジェクトがKMeansModel.predictは、クラスタリング手法を所属用いて予測することができます。
2)MLlib k平均トレーニング機能
ほとんどのパラメータは、全体を説明するKMeans.train方法MLlibで多くのオーバーロードされたメソッドk平均トレーニング機能があります。KMeans.trainは次のとおりです。
DEF列(
データ:RDD [ベクター]、
K:のInt
maxIterations:INTが
実行されます。int
initializationMode:文字列、
種:ロング):KMeansModel = {
。新しい関数kmeans()setK(K) -
.setMaxIterations(maxIterations)
.setRuns(ラン)
.setInitializatinMode(initializationMode)
.setSeed(シード)
.RUN(データ)
}
)
各パラメータの方法コンストラクタと同じ意味ではここでは繰り返しません。
MLlibにおけるk-手段3)予測関数
K-means法KMeansModel.predict MLlibの予測関数は、データ入力パラメータの異なるフォーマットを受信、ベクターまたはRDDであってもよいし、入力パラメータはクラスタ索引を属し返します。次のようにAPI KMeansModel.predictの方法があります。
DEF(:ベクター点):予測intは
デフ予測(点:RDD [ベクター]):RDD [INT]
第1の予測方法は、一点のみを受信することができ、それは、クラスタ内のインデックスを返し、第2の予測方法は、点の集合、および値は、RDDのクラスタ方式として返される各ポイントを受け取ることができます。
アルゴリズムの例K-手段3 MLlibで
例:クラスタの所望の数をパラメータとしてアルゴリズムに渡されうちの2つのクラスタにクラスタリングデータのk平均アルゴリズムを使用してインポートトレーニングデータセット、その後増加することにより、クラスタ内の平均二乗誤差(WSSSE)の和を計算しますkは誤差を低減するクラスタの数です。
この例では、クラスタリングのアルゴリズムは以下のK-手段を使用するステップ。
① データをロードするには、データをテキストファイルに保存されています。
② データのクラスタリングの数を、2〜20回の繰り返しのクラスを設定し、モデルのトレーニング・データ・モデルを形成します。
③ データモデルの印刷中心点。
④ データモデルの誤差二乗和を使用して評価します。
⑤ シングルポイントデータをテストするためにモデルを使用します。
⑥ クロス評価1、結果を返し、クロス2を評価し、データを返す結果を設定します。
この例では、文書kmeans_data.txtに格納されたデータを使用して、以下のデータに示すように、空間的な位置は、6点の座標。
0.0 0.0 0.0
0.1 0.1 0.1
0.2 0.2 0.2
9.0 9.0 9.0
9.1 9.1 9.1
9.2 9.2 9.2
データの各行が1個のドットを記述し、各ドットは、3次元空間内に記載されている3つのデジタル座標値を有しています。各列は、特性指標データ、データセットのクラスター分析とみなされます。コードの実装は、以下に示します。
- インポートorg.apache.log4j。{レベル、ロガー}
- インポートorg.apache.spark。SparkConf {、} SparkContext
- 輸入org.apache.spark.mllib.clustering.KMeans
- 輸入org.apache.spark.mllib.linalg.Vectors
- 目的関数kmeans {
- DEFメイン(引数:配列[文字列]){
- //動作環境を設定します
- ヴァルCONF =新しいSparkConf()。setAppName(「関数kmeans」)。setMaster(「ローカル[4]」)
- ヴァル・SC =新しいSparkContext(CONF)
- //ロードデータセット
- ヴァル・データ= sc.textFile(「/ホーム/ Hadoopの/エクササイズ/ kmeans_data.txt」、1)
- ヴァルparsedData = data.map(S => Vectors.dense(s.split(」)。マップ(_。toDouble)))
- データモデル//クラスタリングデータ数を形成し、クラス2、20回の反復、鉄道模型に設定
- ヴァルnumClusters = 2
- 波numIterations = 20
- ヴァルモデル= KMeans.train(parsedData、numClusters、numIterations)
- //中心点のデータモデルを印刷
- 印刷(「クラスター・センター:」)
- { - (model.clustercenters C <)のために
- 印刷(「」+ c.toString)
- }
- //二乗誤差の和で評価するために、データモデルを使用して
- ヴァル・コスト= model.computeCost(parsedData)
- 印刷(「乗誤差の和集合内=「+コスト)
- //シングルポイントのデータをテストするためにモデルを使用
- 印刷(「ベクター0.2 0.2 0.2であるクラスタに属している:」。+ model.predict(Vectors.dense(「0.2 0.2 0.2」.split(」)マップ(_ toDouble))))
- 印刷(「ベクター0.25 0.25 0.25であり、クラスタに属している:」+ model.predict(Vectors.dense(「0.25 0.25 0.25」.split(」))マップ(_ toDouble))。)。)
- 印刷(「ベクター8 8 8は、クラスタに属している:」+ model.predict(Vectors.dense(「8 8 8」.split(」「).MAP(_ toDouble))))。
- 1 //クロス評価、結果のみ
- ヴァルTESTDATA = data.map(S => Vectors.dense(s.split(」)。マップ(_。toDouble)))
- ヴァル結果1 = model.predict(テストデータ)
- result1.saveAsTextFile(「/ホーム/ Hadoopの/アップロード/ class8 / result_kmeans1」)
- 2クロス評価@、および結果のデータセットを返します
- ヴァル結果2 = data.map {
- ライン=>
- ヴァルlinevectore = Vectors.dense(line.split(」)。マップ(_。toDouble))
- ヴァル予測= model.predict(linevectore)ライン+」「+予測
- } .saveAsTextFile(「/ホーム/ Hadoopの/アップロード/ class8 / result_kmeans2」)
- sc.stop()
- }
- }
コードが実行された後、ウィンドウは、モデルによって計算され、実行中のデータに見られると、2つのクラスタの中心点が識別され:(9.1、9.1、9.1)および(0.1、0.1、0.1);及びポイントをテストするためにモデルを使用します分類は、彼らは1,1,0を得ることができ、クラスタに属しています。
一方、二つの出力先/ホーム/ Hadoopの/火花/ mllib /運動ディレクトリがあります。result_kmeanslとresult_kmeans2。クロス出力クラスタに属する6 0,0,0,1,1,1点の評価、クロスクラスタ評価で設定された第2の出力データにおける各点が属します。
4.アルゴリズムの長所と短所
アルゴリズムの低い時の複雑さは、rは繰り返し数であり、kはクラスタの数であり、O(TKM)、であり、mは、クラスタリングアルゴリズムは、単純かつ効率的な、理解及び実施するのが容易である古典的なアルゴリズムであり、kは、意味しますn次元のレコードの数、およびt << MK << N。
多くの不十分があり、-kを意味するアルゴリズムを。
- 人々は、kは、より難しい問題で選択する傾向が、事前にクラスタ数を決定する必要があります。
- 設定した初期値は、初期選択のためのアルゴリズム値の結果で、非常に敏感です。
- ノイズや異常なデータに非常に敏感。外れ値は、大きな価値を持っている場合、それは真剣に、データの分布に影響を及ぼします。
- データのクラスタリングの分布の非凸形状を解決するわけではありません。
- 主に円形または球状のクラスターを同定するために、非球形クラスタを識別することができません。
- 57 協会は、データマイニング解析ルール
58 アプリオリアルゴリズムとFP-ツリー・アルゴリズム
59 の大規模なデータ精度のマーケティングに基づいて、
60 ベースのパーソナライズされた推薦システムビッグデータ
61 ビッグデータ予測
62. 他のビッグデータアプリケーション
63を。ビッグデータとは、産業界で使用可能な
64の金融業界では、大規模なアプリケーションデータ
65 インターネット業界におけるビッグデータアプリケーション
66 物流業界におけるビッグデータの応用