河北理工大学 データマイニング実験2 データキューブとオンライン分析処理構築
1. 実験目的
(1) 基本的なデータ キューブの構築とオンライン分析および処理アルゴリズムに精通していること。
(2) 一貫性のある高品質なリレーショナルデータベースを構築します。
(3) 構築されたデータベースに基づいて、基本的なデータ キューブを構築します。
(5) 実験レポートを書きます。
2. 実験原理
1. リレーショナルデータベース
リレーショナル データベースは、リレーショナル モデルに基づいて作成されたデータベースであり、
データベース内のデータを処理するために集合代数などの数学的概念と手法を使用します。リレーショナル モデルは、リレーショナル データ構造、リレーショナル操作セット、リレーショナル
整合性制約の 3 つの部分で構成されます。
2. データキューブ
データを多次元でモデル化し、観察できるようにする多次元データ モデル。それは平和維持の事実によって定義されます。ディメンションは、ユニットが必要とする視点またはエンティティです。各ディメンションには、ディメンション テーブルと呼ばれる人物に関連付けられたテーブルを含めることができ、ディメンションをさらに説明します。たとえば、アイテム ディメンションのディメンション テーブルには、名前、時間、タイプなどの属性が含まれます。事実: 多次元データ モデルは売上などのトピックを中心に編成されており、トピックは数値基準である事実によって表されます。
3. OLAP 操作
ロールアップ: ディメンションに沿って概念を階層的に登ったり、ディメンション削減を通じてデータ キューブに集約したりする。
ドリルダウン: ロールアップの逆の操作。ディメンションの概念に沿って階層的にドリルダウンするか、追加のディメンションを導入することによって実現できます。
スライス: 指定されたデータ キューブの 1 つのディメンションを選択し、サブキューブを作成します。これは、データ キューブ内の特定のデータ層です。
切り替え: 2 つ以上の次元を選択してサブキューブを定義します。
これは、データ キューブの特定のレイヤーにある特定のデータです。
4. データウェアハウスの設計
モデル化するビジネス プロセスを選択します。発注、請求、出荷、在庫、簿記、販売、総勘定元帳などのビジネス プロセスが存在します。ビジネス処理の粒度を選択します。ビジネス処理の場合、この粒度は基本であり、単一のトランザクションや 1 日のスナップショットなど、ファクト テーブル内のデータのアトミック レベルです。各ファクト テーブル レコードに使用するディメンションを選択します。一般的なディメンションは、時間、品目、顧客、サプライヤー、倉庫、トランザクション タイプ、およびステータスです。各ファクト テーブル レコードに配置されるメジャーを選択します。一般的なメジャーは、dollars_ sold や Units_ sold などの加算数値数量です。
3. 実験内容と手順
1. 実験内容
1) VC++ プログラミング ツールを使用して、プログラムを作成し、リレーショナル データ ストレージ構造を確立し、データ キューブを作成し、実験レポートで使用される主なプロセスとメソッドを作成します。作成したデータキューブのディメンションは、商品カテゴリ、店舗番号、時間の3つです。特定の要件:
- 1019、1020、および 1021 のデータをそれぞれ保存する 3 つのストレージ テーブル (txt ファイル) を作成します。
- 各txtファイルの横方向は商品カテゴリ(商品IDの上5桁)です:10010 油、10020 小麦粉製品、10030 米・小麦粉、10088 穀物・油脂ギフト。
- 各テキストの縦方向の日付は 13 ~ 19 です。テーブルに格納されている今週の値は
合計売上です。
2) 単純な OLAP データ クエリを実行します
。具体的な要件:
- 13日の2020年の店舗における10010個の石油製品の総売上高を見つけることができます。
- 2020年の店内の10030メートルと麺類の総売上を計算できます。
- 指定された店舗における指定された種類の商品の販売数量を確認できます(追加質問)
2. 実験手順
1) データを注意深く調査およびレビューして、分析に含める必要がある属性またはディメンションを特定し、不要な
データを削除します。データの前処理後、欠損値が補完され、形式が統一されます。前処理データの商品IDと日付を読み取り、販売数量を計算します。
2) データストレージアクセスを実現し、対応する機能を実装するために適切なストレージ構造を選択します。
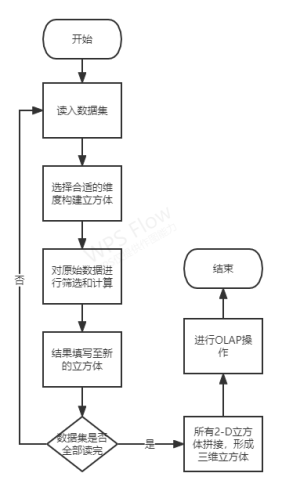
3. プログラムブロック図
4. 実験サンプル
実験 1 処理後の Data.csv
6. 実験コード
#!/usr/bin/env python
# -*- coding: utf-8 -*-
#
# Copyright (C) 2021 #
# @Time : 2022/5/30 21:27
# @Author : Yang Haoyuan
# @Email : [email protected]
# @File : Exp2.py
# @Software: PyCharm
import pandas as pd
import argparse
parser = argparse.ArgumentParser(description='Exp2')
parser.add_argument('--Shop', type=str, default="1019", choices=["1019", "1020", "1021"])
parser.add_argument('--Good', type=str, default="10010油", choices=["10010油", "10020面制品", "10030米和粉", "10088粮油类赠品"])
parser.set_defaults(augment=True)
args = parser.parse_args()
print(args)
# 读取1019,1020,1021三个商店的数据
def getData():
data = pd.read_csv("data.csv")
data_19 = data[:7693]
data_20 = data[7693:17589]
data_21 = data[17589:]
return data_19, data_20, data_21
# 构建数据立方体,数据结构采用DataFrame
def make_cuboid(data):
arr = [[ 0.0, 0.0, 0.0, 0.0],
[ 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0],
[ 0.0, 0.0, 0.0, 0.0],
[ 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0]]
dataFrame = pd.DataFrame(arr, columns=["10010油", "10020面制品", "10030米和粉", "10088粮油类赠品"],
index=["13", "14", "15", "16", "17", "18", "19"])
# 按日期进行筛选,把各日期的数据放入list中
t = [data.loc[data["Date"] == 20030413, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030414, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030415, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030416, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030417, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030418, ["Date", "GoodID", "Num", "Price"]],
data.loc[data["Date"] == 20030419, ["Date", "GoodID", "Num", "Price"]]
]
idx = 13
for df in t:
# 按照商品类别,将各类商品各日期销售总额计算出来并保存
_df = df[df["GoodID"] >= 1001000]
_df = _df[_df["GoodID"] <= 1001099]
_sum = 0
for index, row in _df.iterrows():
_sum = _sum + row["Num"] * row["Price"]
dataFrame.loc[(str(idx), "10010油")] = _sum
_sum = 0
_df = df[df["GoodID"] >= 1002000]
_df = _df[_df["GoodID"] <= 1002099]
for index, row in _df.iterrows():
_sum = _sum + row["Num"] * row["Price"]
dataFrame.loc[(str(idx), "10020面制品")] = _sum
_sum = 0
_df = df[df["GoodID"] >= 1003000]
_df = _df[_df["GoodID"] <= 1003099]
for index, row in _df.iterrows():
_sum = _sum + row["Num"] * row["Price"]
dataFrame.loc[(str(idx), "10030米和粉")] = _sum
_sum = 0
_df = df[df["GoodID"] >= 1008800]
_df = _df[_df["GoodID"] <= 1008899]
for index, row in _df.iterrows():
_sum = _sum + row["Num"] * row["Price"]
dataFrame.loc[(str(idx), "10088粮油类赠品")] = _sum
_sum = 0
idx = idx + 1
return dataFrame
if __name__ == "__main__":
data_1019, data_1020, data_1021 = getData()
# 各数据立方体按照4为小数保存到txt文件
df_1019 = make_cuboid(data_1019)
df_1019.applymap('{:.4f}'.format).to_csv("1019.txt", index=False)
df_1020 = make_cuboid(data_1020)
df_1020.applymap('{:.4f}'.format).to_csv("1020.txt", index=False)
df_1021 = make_cuboid(data_1021)
df_1021.applymap('{:.4f}'.format).to_csv("1021.txt", index=False)
# 三维数据立方体保存到txt文件中
data = pd.concat([df_1019, df_1020, df_1021], keys=["1019", "1020", "1021"], names=["Shop", "Date"])
data.to_csv("data_cubiod.csv")
# "1020商店10010油类商品13日总的销售额
print("1020商店10010油类商品13日总的销售额", format(data.loc[("1020", "13"), "10010油"], '.2f'))
# 1020商店10030米和粉总的销售额
df = data.loc["1020"]
print("1020商店10030米和粉总的销售额", format(df["10030米和粉"].sum(), '.2f'))
# 指定商店指定货物的销售总额
df = data.loc[args.Shop]
print(args.Shop + "商店" + args.Good + "的销售额", format(df[args.Good].sum(), '.2f'))
4. 実験結果
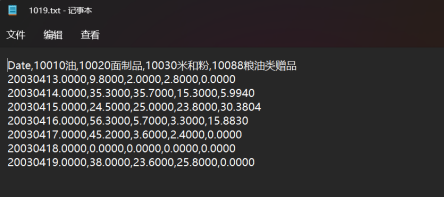
1019 データキューブ txt ファイル
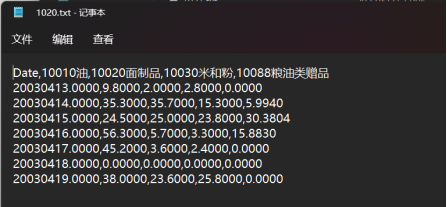
1020 データ キューブ txt ファイル
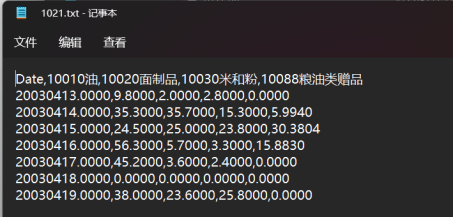
1021 データ キューブ txt ファイル
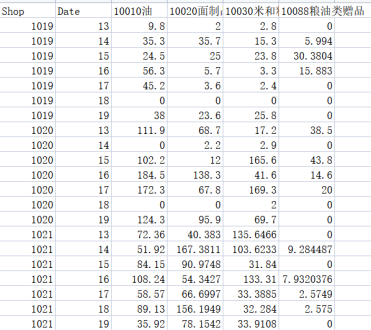
3 次元データ キューブ csv ファイル、ディメンションはショップ、日付、商品の 4 つのカテゴリです

2020 ストア 10010 13 日の石油製品の総売上高と総売上高2020 年店舗の 10030 メートルおよび粉末販売


2021 年店舗の 10088 穀物および油ギフトの売上を問い合わせる
5. 実験分析
この実験では主に、前処理されたデータのデータ キューブを構築し、対応する OLAP 操作を実行します。
pandas パッケージの DataFrame データ構造は、2 次元データ キューブを格納するために使用されます。DataFrame 構造には、データ キューブの構築と OLAP 操作の実装に適した多くの適切な操作とメソッドがあります。
DataFrame では、各データ ユニットに行インデックス (インデックス) と列インデックス (列) の 2 つのインデックスがあり、任意のインデックスに従って 1-D キューブを読み取ることも、2 つのインデックスに従って基本キューブを読み取ることもできます。pandas パッケージには 3 次元データをサポートするパネル構造もありますが、この構造は徐々に非推奨になっているため、3 次元の立方体を構築する場合は、元の 3 つの 2 次元を接続する 2 次元の DataFrame を依然として選択しています。キューブ。
OLAP 操作は、DataFrame.loc メソッドと Series.sum メソッドを使用して実装されます。