Große Modelle beziehen sich auf Modelle des maschinellen Lernens mit großen Parametern und komplexen Rechenstrukturen. Dieser Artikel geht von den Grundkonzepten großer Modelle aus, unterscheidet verwandte Konzepte, die im Bereich großer Modelle leicht verwechselt werden können, und bietet eine detaillierte Interpretation der Entwicklungsgeschichte, Merkmale und Klassifizierung, Verallgemeinerung und Feinabstimmung großer Modelle für jedermann Verstehen Sie das Grundwissen großer Modelle und spielen Sie dabei eine gewisse Referenzrolle.
Das Verzeichnis dieses Artikels lautet wie folgt:
· Definition eines großen Modells
· Unterscheidende Konzepte im Zusammenhang mit einem großen Modell
· Die Entwicklungsgeschichte großer Modelle
· Eigenschaften großer Modelle
· Klassifizierung großer Modelle
·Verallgemeinerung und Feinabstimmung großer Modelle
1. Definition eines großen Modells
Große Modelle beziehen sich auf Modelle des maschinellen Lernens mit großen Parametern und komplexen Rechenstrukturen. Diese Modelle basieren häufig auf tiefen neuronalen Netzen mit Milliarden oder sogar Hunderten von Milliarden Parametern. Der Entwurfszweck großer Modelle besteht darin, die Ausdrucksfähigkeit und Vorhersageleistung des Modells zu verbessern und komplexere Aufgaben und Daten bewältigen zu können. Große Modelle haben ein breites Anwendungsspektrum in verschiedenen Bereichen, einschließlich der Verarbeitung natürlicher Sprache, Computer Vision, Spracherkennung und Empfehlungssystemen. Große Modelle lernen komplexe Muster und Merkmale durch das Training riesiger Datenmengen, verfügen über stärkere Generalisierungsfähigkeiten und können genaue Vorhersagen auf unsichtbaren Daten treffen.
Die Erklärung des großen Modells durch ChatGPT ist leichter zu verstehen und spiegelt auch menschenähnliche Induktions- und Denkfähigkeiten wider: Das große Modell ist im Wesentlichen ein tiefes neuronales Netzwerkmodell, das mithilfe massiver Daten trainiert wird. Sein riesiger Daten- und Parameterumfang realisiert die Entstehung von Intelligenz und die Demonstration menschenähnlicher Intelligenz.
Was ist also der Unterschied zwischen großen Modellen und kleinen Modellen?
Kleines Modell bezieht sich normalerweise auf Modelle mit weniger Parametern und flacheren Schichten. Sie haben die Vorteile von geringem Gewicht, hoher Effizienz, einfacher Bereitstellung usw. und eignen sich für kleine Datenmengen. Szenarien mit begrenzten Rechenressourcen, wie mobile Anwendungen, eingebettete Geräte, Internet der Dinge usw.
Wenn sich die Trainingsdaten und Parameter des Modells weiter ausdehnen, bis sie einen bestimmten kritischen Maßstab erreichen, weist es einige unvorhergesehene und komplexere Fähigkeiten und Eigenschaften auf, und das Modell kann automatisch aus den ursprünglichen Trainingsdaten lernen. Und entdecken Neue, höherstufige Eigenschaften und Muster, diese Fähigkeit wird „emergente Fähigkeit“ genannt. Modelle für maschinelles Lernen mit Emergenzfähigkeiten werden im unabhängigen Sinne als große Modelle betrachtet, was auch den größten Unterschied zwischen ihnen und kleinen Modellen darstellt.
Im Vergleich zu kleinen Modellen verfügen große Modelle normalerweise über mehr Parameter, tiefere Schichten, stärkere Ausdrucksfähigkeiten und höhere Genauigkeit, erfordern jedoch auch mehr Rechenressourcen und Zeit für Training und Inferenz und eignen sich für Anwendungen mit großen Datenmengen. Großmaßstab Szenarien mit ausreichenden Rechenressourcen, wie Cloud Computing, Hochleistungsrechnen, künstliche Intelligenz usw.
2. Unterscheidende Konzepte im Zusammenhang mit großen Modellen:
Großes Modell (auch bekannt als Foundation Model) bezieht sich auf ein maschinelles Lernmodell mit einer großen Anzahl von Parametern und einer komplexen Struktur, das große Datenmengen verarbeiten und verschiedene Aufgaben erledigen kann. komplex Aufgaben wie Verarbeitung natürlicher Sprache, Computer Vision, Spracherkennung usw.
Sehr große Modelle: Sehr große Modelle sind eine Teilmenge großer Modelle und ihre Anzahl an Parametern übersteigt die von großen Modellen bei weitem.
Großes Sprachmodell: Normalerweise ein natürliches Sprachverarbeitungsmodell mit großen Parametern und Rechenleistung, wie zum Beispiel das GPT-3-Modell von OpenAI. Diese Modelle können mit großen Mengen an Daten und Parametern trainiert werden, um menschenähnlichen Text zu generieren oder Fragen in natürlicher Sprache zu beantworten. Umfangreiche Sprachmodelle werden häufig in Bereichen wie der Verarbeitung natürlicher Sprache, der Textgenerierung und dem intelligenten Dialog eingesetzt.
GPT (Generative Pre-trained Transformer): GPT und ChatGPT sind beide Sprachmodelle, die auf der Transformer-Architektur basieren, aber sie unterscheiden sich in Design und Anwendung: Das GPT-Modell ist entworfen zum Generieren von Text in natürlicher Sprache und übernimmt verschiedene Verarbeitungsaufgaben in natürlicher Sprache wie Textgenerierung, Übersetzung, Zusammenfassung usw. Es wird typischerweise im Zusammenhang mit der einseitigen Generierung verwendet, d. h. der Erzeugung einer kohärenten Ausgabe basierend auf einem gegebenen Text.
ChatGPT: ChatGPT konzentriert sich auf Konversationen und interaktive Konversationen. Es ist speziell darauf trainiert, mehrere Gesprächsrunden besser zu bewältigen und den Kontext besser zu verstehen. ChatGPT soll ein reibungsloses, kohärentes und interessantes Gesprächserlebnis bieten, das auf Benutzereingaben reagiert und entsprechende Antworten generiert.
3. Entwicklungsgeschichte großer Modelle
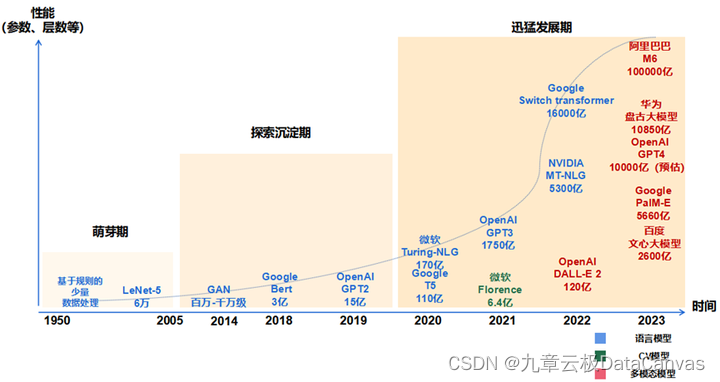
Embryonalperiode (1950–2005): Die Phase des traditionellen neuronalen Netzwerkmodells, dargestellt durch CNN
· Im Jahr 1956 entwickelte sich die KI-Entwicklung ausgehend vom Konzept der „künstlichen Intelligenz“, das vom Computerexperten John McCarthy vorgeschlagen wurde, schrittweise von einer auf kleinem Expertenwissen basierenden hin zu einer auf maschinellem Lernen basierenden Entwicklung.
· 1980 wurde CNN, der Prototyp eines Faltungs-Neuronalen Netzwerks, geboren.
· Im Jahr 1998 wurde LeNet-5, die Grundstruktur moderner Faltungs-Neuronaler Netze, geboren. Die Methode des maschinellen Lernens wandelte sich von einem frühen Modell, das auf flachem maschinellem Lernen basierte, zu einem Modell, das auf tiefem Lernen basierte, was den Weg für tiefes Lernen ebnete Forschung in Bereichen wie der Erzeugung natürlicher Sprache und Computer Vision. Sie legte den Grundstein und war von bahnbrechender Bedeutung für spätere Iterationen von Deep-Learning-Frameworks und die Entwicklung großer Modelle.
Erkundungs- und Niederschlagszeitraum (2006–2019): die neue Stufe des neuronalen Netzwerkmodells, dargestellt durch Transformer
· Im Jahr 2013 wurde das natürliche Sprachverarbeitungsmodell Word2Vec geboren und schlug erstmals das „Wortvektormodell“ vor, das Wörter in Vektoren umwandelt, damit Computer Textdaten besser verstehen und verarbeiten können.
· Im Jahr 2014 markierte die Geburt von GAN (Generative Adversarial Network), das als eines der leistungsstärksten Algorithmusmodelle des 21. Jahrhunderts bekannt ist, den Eintritt von Deep Learning in eine neue Phase der generativen Modellforschung.
· Im Jahr 2017 schlug Google bahnbrechend die Transformer-Architektur vor, eine neuronale Netzwerkstruktur, die auf dem Selbstaufmerksamkeitsmechanismus basiert und den Grundstein für die Architektur eines großen Modellalgorithmus vor dem Training legte.
· Im Jahr 2018 veröffentlichten OpenAI und Google die großen Modelle GPT-1 bzw. BERT, was bedeutet, dass vorab trainierte große Modelle im Bereich der Verarbeitung natürlicher Sprache zum Mainstream geworden sind. Während der Erkundungsphase legte die neue neuronale Netzwerkarchitektur, die von Transformer dargestellt wird, den Grundstein für die Algorithmusarchitektur großer Modelle und verbesserte die Leistung der Technologie großer Modelle erheblich.
Schnelle Entwicklungsphase (2020 bis heute): Große Modellphase vor dem Training, dargestellt durch GPT
· Im Jahr 2020 brachte OpenAI GPT-3 auf den Markt, dessen Modellparametergröße 175 Milliarden erreichte, was zum damals größten Sprachmodell wurde und enorme Leistungsverbesserungen bei Lernaufgaben ohne Stichproben erzielte. Anschließend tauchten weitere Strategien wie Reinforcement Learning basierend auf menschlichem Feedback (RHLF), Code-Pre-Training, Befehlsfeinabstimmung usw. auf, die zur weiteren Verbesserung der Argumentationsfähigkeiten und der Aufgabenverallgemeinerung eingesetzt wurden.
· Im November 2022 wurde ChatGPT mit GPT3.5 geboren, das mit seiner realistischen Interaktion in natürlicher Sprache und den Funktionen zur Generierung von Inhalten für mehrere Szenarien das Internet schnell zum Explodieren brachte.
· Im März 2023 verfügt das neu veröffentlichte ultragroße multimodale Pre-Training-Großmodell GPT-4 über die Fähigkeiten des multimodalen Verständnisses und der Generierung von Inhalten mehrerer Typen. In der Zeit der rasanten Entwicklung hat die perfekte Kombination aus Big Data, großer Rechenleistung und großen Algorithmen die Vortrainings- und Generierungsfähigkeiten großer Modelle sowie die multimodalen und szenarioübergreifenden Anwendungsmöglichkeiten erheblich verbessert. Der große Erfolg von ChatGPT wurde beispielsweise mit der Unterstützung der leistungsstarken Rechenleistung von Microsoft Azure und umfangreichen Daten wie Wikis sowie auf der Grundlage der Transformer-Architektur erzielt, wobei die Strategie der Feinabstimmung des GPT-Modells und des verstärkten Lernens beibehalten wurde menschliches Feedback (RLHF).
4. Eigenschaften großer Modelle
· Großer Maßstab: Große Modelle enthalten Milliarden von Parametern und Modellgrößen können Hunderte von GB oder mehr erreichen. Die enorme Modellgröße ermöglicht großen Modellen leistungsstarke Ausdrucks- und Lernfähigkeiten.
· Emergenzfähigkeit: Emergenz (englisch: Emergenz), auch bekannt als Schöpfung, Emergenz, Präsentation und Evolution, ist ein Phänomen, das aus der Interaktion vieler kleiner Einheiten resultiert. Es entsteht eine große Einheit, und diese große Einheit weist Eigenschaften auf, die die kleineren Einheiten, aus denen sie besteht, nicht besitzen. Auf die Modellebene erweitert, bezieht sich die Emergenzfähigkeit darauf, dass das Modell plötzlich mit unerwarteten und komplexen Fähigkeiten und Eigenschaften auftaucht, die im vorherigen kleinen Modell nicht verfügbar waren, und eine umfassende Analyse und tiefere Lösung ermöglicht, wenn die Trainingsdaten des Modells einen bestimmten Maßstab überschreiten Probleme, die demonstrieren, menschenähnliches Denken und Intelligenz entwickeln. Auch die Emergenzfähigkeit ist eines der wichtigsten Merkmale großer Modelle.
· Bessere Leistung und Generalisierung: Große Modelle verfügen im Allgemeinen über stärkere Lern- und Generalisierungsfähigkeiten und können bei einer Vielzahl von Aufgaben gut funktionieren, einschließlich der Verarbeitung natürlicher Sprache, Bilderkennung, Spracherkennung, usw.
· Multitasking-Lernen: Große Modelle lernen normalerweise mehrere verschiedene NLP-Aufgaben zusammen, wie maschinelle Übersetzung, Textzusammenfassung, Frage-Antwort-Systeme usw. Dadurch kann das Modell umfassendere und allgemeinere Sprachverständnisfähigkeiten erlernen.
· Big-Data-Training: Große Modelle erfordern riesige Datenmengen zum Trainieren, normalerweise Datensätze mit mehr als TB oder sogar PB-Ebenen. Nur eine große Datenmenge kann die Parameterskala großer Modelle nutzen.
· Leistungsstarke Rechenressourcen: Das Training großer Modelle erfordert normalerweise Hunderte oder sogar Tausende von GPUs und viel Zeit, normalerweise Wochen bis Monate.
· Lernen und Vortraining übertragen: Große Modelle können anhand umfangreicher Daten vorab trainiert und dann auf bestimmte Aufgaben abgestimmt werden, wodurch die Leistung des Modells verbessert wird auf neue Aufgaben. Leistung.
· Selbstüberwachtes Lernen: Große Modelle können durch selbstüberwachtes Lernen auf umfangreichen, unbeschrifteten Daten trainiert werden, wodurch die Abhängigkeit von beschrifteten Daten verringert und die Modelleffizienz verbessert wird.
· Domänenwissensfusion: Große Modelle können Wissen aus Daten in mehreren Bereichen lernen und es in verschiedenen Bereichen anwenden, um bereichsübergreifende Innovationen zu fördern.
· Automatisierung und Effizienz: Große Modelle können viele komplexe Aufgaben automatisieren und die Arbeitseffizienz verbessern, z. B. automatische Programmierung, automatische Übersetzung, automatische Zusammenfassung usw.
5. Klassifizierung großer Modelle
Je nach Eingabedatentyp lassen sich große Modelle hauptsächlich in die folgenden drei Kategorien einteilen:
·Sprachmodell (NLP): bezieht sich auf eine Art großes Modell im Bereich der Verarbeitung natürlicher Sprache (NLP), das normalerweise zur Verarbeitung von Textdaten und zum Verstehen natürlicher Sprache verwendet wird. Das Hauptmerkmal solch großer Modelle besteht darin, dass sie auf großen Korpora trainiert werden, um verschiedene grammatikalische, semantische und kontextuelle Regeln natürlicher Sprache zu lernen. Zum Beispiel: GPT-Serie (OpenAI), Bard (Google), Wen Xinyiyan (Baidu).
·Visual Large Model (CV): Bezieht sich auf ein großes Modell, das im Bereich Computer Vision (CV) verwendet wird und normalerweise für die Bildverarbeitung und -analyse verwendet wird. Diese Art von Modell kann verschiedene visuelle Aufgaben durch Training an umfangreichen Bilddaten erfüllen, wie z. B. Bildklassifizierung, Zielerkennung, Bildsegmentierung, Posenschätzung, Gesichtserkennung usw. Zum Beispiel: VIT-Serie (Google), Wenxin UFO, Huawei Pangu CV, INTERN (SenseTime).
· Multimodales großes Modell: bezieht sich auf ein großes Modell, das mehrere verschiedene Datentypen verarbeiten kann, wie z. B. Text, Bilder, Audio und andere multimodale Daten. Diese Art von Modell kombiniert die Fähigkeiten von NLP und CV, um ein umfassendes Verständnis und eine umfassende Analyse multimodaler Informationen zu erreichen und so ein umfassenderes Verständnis und eine umfassendere Verarbeitung komplexer Daten zu ermöglichen. Zum Beispiel: DingoDB-Multimodus-Vektordatenbank (Jiuzhang Yunji DataCanvas), DALL-E (OpenAI), Wukong Huahua (Huawei), midjourney.
Je nach Anwendungsbereich lassen sich große Modelle hauptsächlich in drei Ebenen einteilen: L0, L1 und L2:
· Allgemeines großes Modell L0: bezieht sich auf ein großes Modell, das universell in mehreren Bereichen und Aufgaben verwendet werden kann. Sie nutzen große Mengen an Rechenleistung, massive offene Daten und Deep-Learning-Algorithmen mit riesigen Parametern, um auf großen, unbeschrifteten Daten zu trainieren, um Merkmale zu finden und Muster zu entdecken, und bilden so leistungsstarke Generalisierungsfähigkeiten aus, die „Rückschlüsse von einer Instanz auf andere Fälle ziehen können“. .“ Es kann Multi-Szenario-Aufgaben ohne Feinabstimmung oder mit einem geringen Maß an Feinabstimmung erledigen, was dem Abschluss einer „allgemeinen Bildung“ durch KI gleichkommt.
· Großes Branchenmodell L1: bezieht sich auf die großen Modelle, die auf bestimmte Branchen oder Bereiche abzielen. Sie werden in der Regel mithilfe branchenbezogener Daten vorab trainiert oder feinabgestimmt, um die Leistung und Genauigkeit in diesem Bereich zu verbessern, was gleichbedeutend damit ist, dass KI zu einem „Branchenexperten“ wird.
·Vertikales großes Modell L2: bezieht sich auf die großen Modelle, die auf bestimmte Aufgaben oder Szenarien ausgerichtet sind. Sie werden in der Regel mithilfe aufgabenbezogener Daten vorab trainiert oder feinabgestimmt, um die Leistung und Effektivität dieser Aufgabe zu verbessern.
6. Verallgemeinerung und Feinabstimmung großer Modelle
Generalisierungsfähigkeit des Modells: Bezieht sich auf die Fähigkeit eines Modells, neue, unsichtbare Daten richtig zu verstehen und vorherzusagen, wenn es mit diesen Daten konfrontiert wird. In den Bereichen maschinelles Lernen und künstliche Intelligenz ist die Generalisierungsfähigkeit eines Modells einer der wichtigen Indikatoren zur Bewertung der Modellleistung.
Was ist Modell-Feinabstimmung?: Bei einem vorab trainierten Modell (vorab trainiertes Modell) wird eine Feinabstimmung (Feinabstimmung) basierend auf dem Modell durchgeführt. Im Vergleich zum Training eines Modells von Grund auf kann die Feinabstimmung viele Rechenressourcen und Rechenzeit einsparen, die Recheneffizienz verbessern und sogar die Genauigkeit verbessern.
Die Grundidee der Modellfeinabstimmung besteht darin, eine kleine Menge beschrifteter Daten zu verwenden, um ein vorab trainiertes Modell neu zu trainieren, um es an eine bestimmte Aufgabe anzupassen. Dabei werden die Parameter des Modells entsprechend der neuen Datenverteilung angepasst. Der Vorteil dieses Ansatzes besteht darin, dass er die Leistungsfähigkeit vorab trainierter Modelle nutzt und gleichzeitig in der Lage ist, sich an neue Datenverteilungen anzupassen. Daher kann die Feinabstimmung des Modells die Generalisierungsfähigkeit des Modells verbessern und eine Überanpassung reduzieren.
Gängige Methoden zur Modellfeinabstimmung:
· Feinabstimmung: Dies ist die am häufigsten verwendete Feinabstimmungsmethode. Durch Hinzufügen einer neuen Klassifizierungsebene zur letzten Ebene des vorab trainierten Modells und anschließende Feinabstimmung basierend auf dem neuen Datensatz.
· Feature-Erweiterung: Diese Methode verbessert die Leistung des Modells, indem sie den Daten einige künstliche Features hinzufügt. Diese Features können manuell entworfen oder durch automatische Feature-Generierungstechniken generiert werden.
· Transferlernen: Diese Methode verwendet ein an einer Aufgabe trainiertes Modell als Ausgangspunkt für eine neue Aufgabe und passt dann die Parameter des Modells an die neue Aufgabe an.
Große Modelle stellen eine wichtige Richtung und Kerntechnologie für die zukünftige Entwicklung der künstlichen Intelligenz dar. Mit der kontinuierlichen Weiterentwicklung der KI-Technologie und der kontinuierlichen Erweiterung der Anwendungsszenarien werden große Modelle in Zukunft ihr enormes Potenzial in mehr Bereichen zeigen und ein Kaleidoskop darstellen -ähnliche KI-Zukunft für die Menschheit. Erweitern Sie die Möglichkeiten.