Table of contents
1. Configure the virtual environment
2. Library version introduction
5. save_model (save model parameters)
6. load_model (load model parameters)
1. Experiment introduction
This experiment implements Runnerclasses for model training, evaluation, and prediction . Through this class, you can more conveniently train and evaluate the model, and obtain the changes in loss and evaluation indicators during the training process.
2. Experimental environment
This series of experiments uses the PyTorch deep learning framework. The relevant operations are as follows:
1. Configure the virtual environment
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. Library version introduction
| software package | This experimental version | The latest version currently |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
3. Experimental content
ChatGPT:
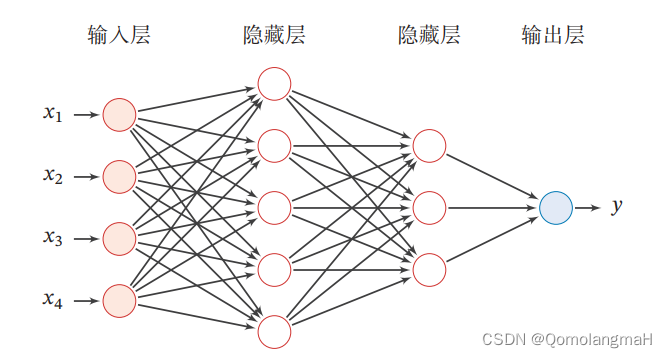
Feedforward Neural Network is a common artificial neural network model, also known as Multilayer Perceptron (MLP). It is a model based on forward propagation and is mainly used to solve classification and regression problems.
Feedforward neural network consists of multiple layers, including input layer, hidden layer and output layer. Its name "feedforward" comes from the fact that signals can only flow forward in the network, that is, from the input layer through the hidden layer and finally to the output layer, without feedback connections.
Here's how feedforward neural networks generally work:
Input layer: receives raw data or feature vectors as input to the network, and each input is represented as a neuron of the network. Each neuron weights the input and transforms it through an activation function to produce an output signal.
Hidden layer: A feedforward neural network can contain one or more hidden layers, each consisting of multiple neurons. The neurons in the hidden layer receive input from the previous layer and pass the weighted sum of the signal transformed by the activation function to the next layer.
Output layer: The output of the last hidden layer is passed to the output layer, which usually consists of one or more neurons. The neurons in the output layer use appropriate activation functions (such as Sigmoid, Softmax, etc.) according to the type of problem to be solved (classification or regression) to output the final result.
Forward propagation: The process of transmitting signals from the input layer through the hidden layer to the output layer is called forward propagation. During forward propagation, each neuron multiplies the output of the previous layer by the corresponding weight and passes the result to the next layer. Such calculations are performed layer by layer through each layer in the network until the final output is produced.
Loss function and training: The training process of a feedforward neural network usually involves defining a loss function that measures the difference between the model's predicted output and the true label. Common loss functions include Mean Squared Error and Cross-Entropy. By using backpropagation and optimization algorithms (such as gradient descent), the network adjusts parameters according to the gradient of the loss function to minimize the value of the loss function.
The advantages of feedforward neural networks include the ability to handle complex nonlinear relationships, their suitability for a variety of problem types, and their ability to automatically learn feature representations through training. However, it also has some challenges, such as easy over-fitting and difficulty in processing large-scale data and high-dimensional data. In order to cope with these challenges, some improved network structures and training techniques have been proposed, such as Convolutional Neural Networks and Recurrent Neural Networks.
This series is experimental content and does not explain theoretical knowledge in detail.
(Ahem, I actually don’t have time to sort it out. I’ll come back and fill in the gaps when I have the opportunity)
0. Import necessary toolkits
import torch
from torch import nn
import torch.nn.functional as F
# 绘画时使用的工具包
import matplotlib.pyplot as plt
# 导入鸢尾花数据集
from sklearn.datasets import load_iris
# 构建自己的数据集,继承自Dataset类
from torch.utils.data import Dataset, DataLoader1. __init__(initialization)
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
# 用于计算评价指标
self.metric = metric
# 记录训练过程中的评价指标变化
self.dev_scores = []
# 记录训练过程中的损失变化
self.train_epoch_losses = []
self.dev_losses = []
# 记录全局最优评价指标
self.best_score = 0- Five parameters:
- model: used for training, evaluation and prediction;
- Optimizer: used to update the parameters of the model;
- loss_fn (loss function): used to calculate the loss of the model;
- metric: used to evaluate the performance of the model;
- **kwargs (other optional parameters)
- This class also defines some attributes for recording indicator changes during training and the global optimal indicator:
- self.dev_scores (record changes in validation set evaluation indicators)
- self.train_epoch_losses (record changes in training set losses)
- self.dev_losses (record changes in validation set losses)
- self.best_score (records the global optimal evaluation index)
2. train(training)
Traverse the training data set to train the model and verify it in certain rounds.
train_loader: Data loader for the training dataset.dev_loader: Data loader for validation dataset (optional).**kwargs: Optional other parameters, such as the number of training rounds, log output frequency, etc.
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型设置为训练模式,此时模型的参数会被更新
self.model.train()
num_epochs = kwargs.get('num_epochs', 0)
log_steps = kwargs.get('log_steps', 100)
save_path = kwargs.get('save_path', 'best_mode.pth')
eval_steps = kwargs.get('eval_steps', 0)
# 运行的step数,不等于epoch数
global_step = 0
if eval_steps:
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
if self.metric is None:
raise RuntimeError('Error: Metric can not be None')
# 遍历训练的轮数
for epoch in range(num_epochs):
total_loss = 0
# 遍历数据集
for step, data in enumerate(train_loader):
x, y = data
logits = self.model(x.float())
loss = self.loss_fn(logits, y.long())
total_loss += loss
if log_steps and global_step % log_steps == 0:
print(f'loss:{loss.item():.5f}')
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
# 每隔一定轮次进行一次验证,由eval_steps参数控制,可以采用不同的验证判断条件
if (epoch + 1) % eval_steps == 0:
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f'[Evalute] dev score:{dev_score:.5f}, dev loss:{dev_loss:.5f}')
if dev_score > self.best_score:
self.save_model(f'model_{epoch + 1}.pth')
print(
f'[Evaluate]best accuracy performance has been updated: {self.best_score:.5f}-->{dev_score:.5f}')
self.best_score = dev_score
# 验证过程结束后,请记住将模型调回训练模式
self.model.train()
global_step += 1
# 保存当前轮次训练损失的累计值
train_loss = (total_loss / len(train_loader)).item()
self.train_epoch_losses.append((global_step, train_loss))
print('[Train] Train done')-
By
self.model.train()setting the model to training mode, this means that the parameters of the model are updated during the training process. -
Obtain some configuration information from
kwargsthe parameters, such as the number of training roundsnum_epochs, the number of log output stepslog_steps, the model saving pathsave_path, and the number of evaluation stepseval_steps. -
Initialize the global step count
global_stepto 0. -
If the number of evaluation steps is set
eval_steps, model evaluation is required.-
If no validation data set is provided
dev_loader, anRuntimeErrorexception will be thrown. -
If no evaluation metrics are set
self.metric, anRuntimeErrorexception will also be thrown.
-
-
Use a loop to iterate over the number of epochs of training
num_epochs.-
Before each round of training, the total loss is initialized
total_lossto 0. -
Use to
enumerate(train_loader)traverse the training data set to obtain the datadataand corresponding indexstep.-
dataGet input dataxand target data from ity. -
Pass the input data
xinto the modelself.modeland get the prediction results of the modellogits. -
Use a loss function to calculate the loss between
self.loss_fnthe predictionlogitsand the target data .yloss -
Accumulate the loss of each sample into the total loss
total_loss. -
If the log output step number is set
log_stepsand the current step numberglobal_stepis a multiple of the log output step number, the loss value of the current step number is printed. -
Backpropagate the loss value to calculate the gradient and update the parameters of the model.
-
Clear the gradient to prepare for the next round of training.
-
-
If the current round is a round that needs to be verified (
eval_stepscontrolled according to parameters)-
Call
self.evaluatethe function to evaluate the model and obtain the evaluation resultsdev_scoreand verification lossdev_loss. -
Print the verification results.
-
If the current validation result
dev_scoreis better than the previous best resultself.best_score, the model is saved and the best result is updatedself.best_score. -
After completing the validation, put the model back into training mode to continue training.
-
-
Update the global step count
global_step. -
Calculate the average training loss for the current epoch
train_lossand add it toself.train_epoch_lossesthe list.
-
-
After completing all training rounds, print the training completion prompt message.
3. evaluate(evaluate)
Use the validation data set to evaluate model performance and calculate evaluation metrics and loss values. (Set the model to verification mode to keep the model parameters unchanged for accurate evaluation during the verification process)
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为验证模式,此模式下,模型的参数不会更新
self.model.eval()
global_step = kwargs.get('global_step', -1)
total_loss = 0
self.metric.reset()
for batch_id, data in enumerate(dev_loader):
x, y = data
logits = self.model(x.float())
loss = self.loss_fn(logits, y.long()).item()
total_loss += loss
self.metric.update(logits, y)
dev_loss = (total_loss / len(dev_loader))
self.dev_losses.append((global_step, dev_loss))
dev_score = self.metric.accumulate()
self.dev_scores.append(dev_score)
return dev_score, dev_loss-
Use
assert self.metric is not Noneassertions to ensure that the evaluation metricself.metricis not empty. -
Set the model into validation mode by
self.model.eval()setting the model's status to validation mode. In validation mode, the model's parameters are not updated. -
kwargsGet the global step number from the parameterglobal_step, default is -1. -
Initialize the total loss
total_lossto 0. -
Call the method of the evaluation indicator
reset()to reset the internal state of the evaluation indicator. -
Use a loop to iterate over the validation data set
dev_loader.-
For each batch of data, obtain the input data
xand target datay. -
Pass the input data
xinto the modelself.modeland get the prediction results of the modellogits. -
Use a loss function to calculate the loss between
self.loss_fnthe predictionlogitsand the target data . Use the method to convert the loss value to a scalar.yloss.item() -
Add the loss value of each batch to the total loss
total_loss. -
Call the evaluation indicator
update()method and pass in the prediction resultslogitsand target datayto update the status of the evaluation indicator.
-
-
Calculate the average loss on the validation set
dev_lossas the total loss divided by the length of the validation dataset. -
Add the current global step count
global_stepand validation loss to the list for subsequent recording and analysis.dev_lossself.dev_losses -
Call the evaluation indicator
accumulate()method to calculate and return the accumulated evaluation indicator value. -
dev_scoreAdd the current evaluation indicator valueself.dev_scoresto the list for subsequent recording and analysis. -
Returns the evaluation metric value
dev_scoreand validation lossdev_loss.
4. predict
Used to make predictions on input data. Set the model to evaluation mode (self.model.eval()), and then perform forward propagation through self.model to obtain the prediction result logits.
def predict(self, x, **kwargs):
self.model.eval()
logits = self.model(x)
return logits5. save_model (save model parameters)
def save_model(self, save_path):
torch.save(self.model.state_dict(),save_path)6. load_model (load model parameters)
def load_model(self, model_path):
self.model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))7. Code integration
class Runner(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
# 用于计算评价指标
self.metric = metric
# 记录训练过程中的评价指标变化
self.dev_scores = []
# 记录训练过程中的损失变化
self.train_epoch_losses = []
self.dev_losses = []
# 记录全局最优评价指标
self.best_score = 0
# 模型训练阶段
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型设置为训练模式,此时模型的参数会被更新
self.model.train()
num_epochs = kwargs.get('num_epochs', 0)
log_steps = kwargs.get('log_steps', 100)
save_path = kwargs.get('save_path','best_mode.pth')
eval_steps = kwargs.get('eval_steps', 0)
# 运行的step数,不等于epoch数
global_step = 0
if eval_steps:
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
if self.metric is None:
raise RuntimeError('Error: Metric can not be None')
# 遍历训练的轮数
for epoch in range(num_epochs):
total_loss = 0
# 遍历数据集
for step, data in enumerate(train_loader):
x, y = data
logits = self.model(x.float())
loss = self.loss_fn(logits, y.long())
total_loss += loss
if log_steps and global_step%log_steps == 0:
print(f'loss:{loss.item():.5f}')
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
# 每隔一定轮次进行一次验证,由eval_steps参数控制,可以采用不同的验证判断条件
if (epoch+1)% eval_steps == 0:
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f'[Evalute] dev score:{dev_score:.5f}, dev loss:{dev_loss:.5f}')
if dev_score > self.best_score:
self.save_model(f'model_{epoch+1}.pth')
print(f'[Evaluate]best accuracy performance has been updated: {self.best_score:.5f}-->{dev_score:.5f}')
self.best_score = dev_score
# 验证过程结束后,请记住将模型调回训练模式
self.model.train()
global_step += 1
# 保存当前轮次训练损失的累计值
train_loss = (total_loss/len(train_loader)).item()
self.train_epoch_losses.append((global_step,train_loss))
print('[Train] Train done')
# 模型评价阶段
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为验证模式,此模式下,模型的参数不会更新
self.model.eval()
global_step = kwargs.get('global_step',-1)
total_loss = 0
self.metric.reset()
for batch_id, data in enumerate(dev_loader):
x, y = data
logits = self.model(x.float())
loss = self.loss_fn(logits, y.long()).item()
total_loss += loss
self.metric.update(logits, y)
dev_loss = (total_loss/len(dev_loader))
self.dev_losses.append((global_step, dev_loss))
dev_score = self.metric.accumulate()
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型预测阶段,
def predict(self, x, **kwargs):
self.model.eval()
logits = self.model(x)
return logits
# 保存模型的参数
def save_model(self, save_path):
torch.save(self.model.state_dict(),save_path)
# 读取模型的参数
def load_model(self, model_path):
self.model.load_state_dict(torch.load(model_path, map_location=torch.device('cpu')))