1.はじめに
GAN および拡散モデルに基づいて、さまざまなマルチモーダル信号から画像を合成するためのマルチモーダル ガイダンスを組み込むことで生成プロセスを調整します。マルチモーダル画像の合成と編集には事前トレーニング済みモデルを使用し、GAN 潜在的な反転を実行します。 space. 実行、ブートストラップ関数の適用、または潜在空間と拡散モデルの埋め込みの調整を行います。

2.モダリティの基礎
あらゆる情報源や形式の情報がモーダルになる可能性があります。
2.1 視覚的なガイダンス
視覚的なガイダンスは、ピクセル空間で特定の画像プロパティをエンコードし、制御を提供します。ビジョンガイド付きエンコーディングは、2D ピクセル空間内の特定のタイプの画像として表されるため、さまざまな画像エンコード戦略によって直接エンコードできます。エンコードされた特徴は画像の特徴、スプライシング、スペード、クロスアテンションと空間的に位置合わせされているため、このように、webui で画像を生成し、autoencoderKL を通じて init_latent を生成することになりますが、通常、テキストはクロスアテンション フュージョン モデルを通過しますが、入力画像は通過しません。
2.2 テキストガイダンス
Clip は、多数の画像とテキストのペアでトレーニングされた有益なテキスト埋め込みを生成し、テキスト エンコードに広く使用されています。
2.3 音声ガイダンス
テキストや視覚的なガイダンスとは異なり、音声ガイダンスは、動的または連続的な視覚コンテンツを生成するために使用できる一時的な情報を提供します。入力オーディオ クリップは、スペクトログラム、fBank、メル周波数ケプストラム係数 (MFCC)、事前トレーニング済み SoundNet モデルの隠れ層出力などの一連の特徴によって表すことができます。
2.4 その他のモダリティに関するガイダンス
3.方法
マルチモーダル画像の合成と編集は、1. GAN ベースの手法、2. 自己回帰、3. 拡散モデル、4. Nerf、5. その他の 5 つのカテゴリに大別されます。

3.1 GAN ベースのメソッド
3.1.1 条件付き GAN
CGAN は、追加情報を使用して生成プロセスを調整します。これは、ジェネレーターとディスクリミネーターのネットワークに追加の情報を追加のガイダンスとして入力することで実現され、ジェネレーターはディスクリミネーターを欺き、指定された条件情報と一致するサンプルを生成する方法を学習します。
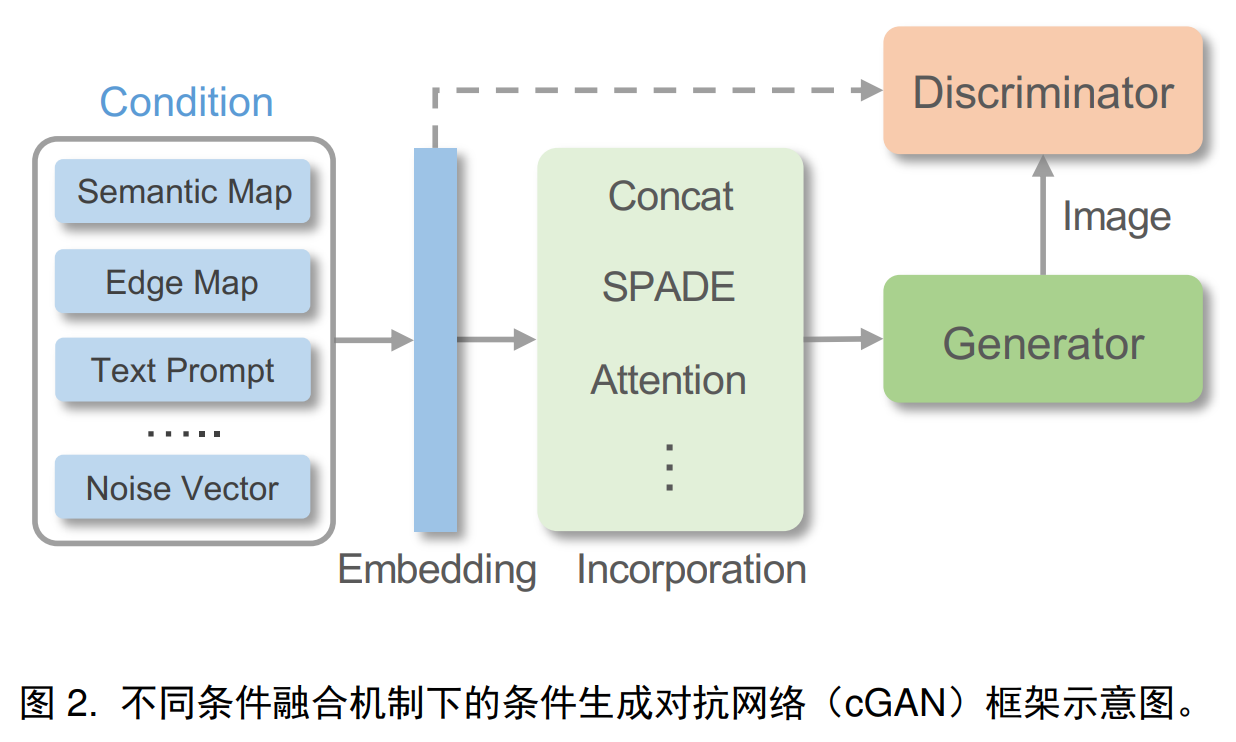
条件付きフュージョン: ターゲット イメージの空間位置合わせに関する視覚的なガイダンスとして、生成または編集のための正確な空間ガイダンスを提供する条件を 2D フィーチャに直接エンコードできます。異なる視野角や激しい変形が存在する場合、エンコードされた 2D フィーチャがキャプチャすることは困難です。実画像間の複雑なシーン構造関係については、アテンション モジュールを使用してガイダンスをターゲット画像と位置合わせすることができます。ディープ ネットワークを使用して視覚的なガイダンスをエンコードするだけでは、ガイダンス情報の一部が正規化層で失われるため、最適ではありません。SPADE、空間適応非正規化を使用して、ガイダンス機能を効果的に挿入できます。複雑な条件を中間表現にマッピングしてより正確な画像を生成することもでき、オーディオ クリップを顔のランドマークまたは 3DMM パラメータにマッピングして話し顔の生成を行うこともできます。
モデル構造:
損失関数: ガン損失、知覚損失、サイクル損失、コントラスト損失
3.1.2 無条件 GAN の反転
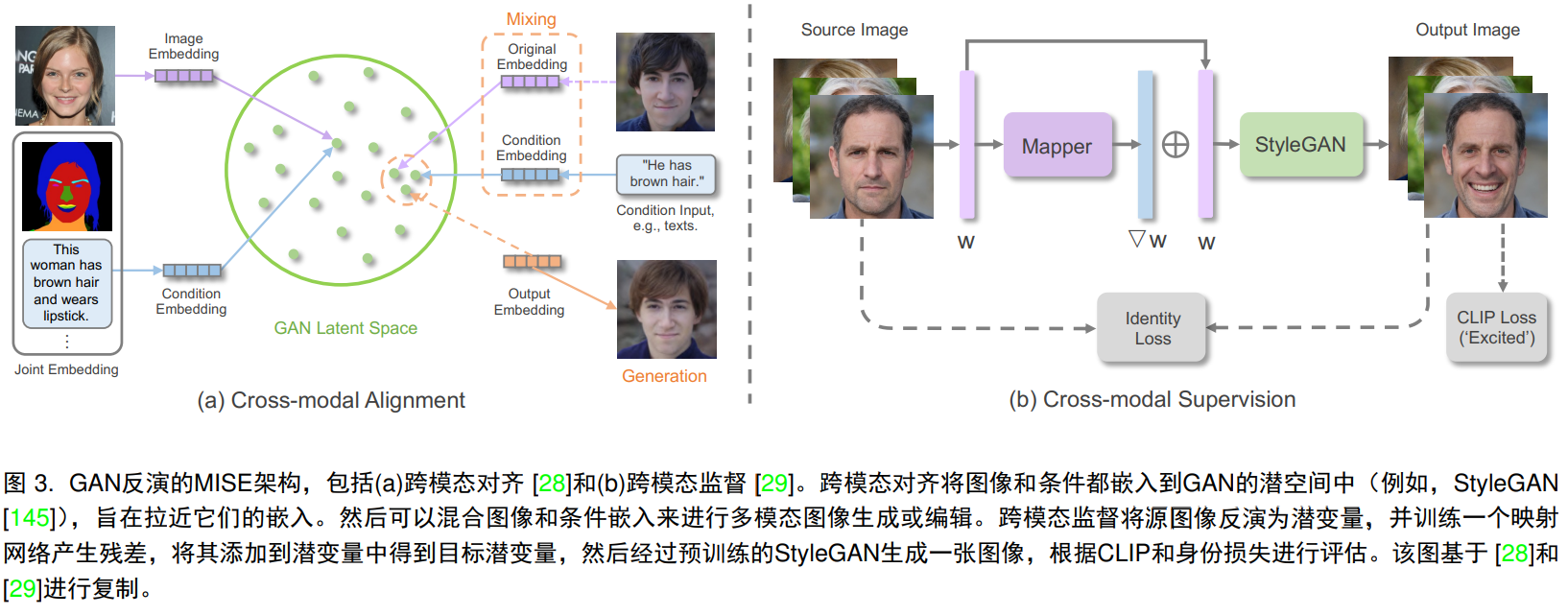
事前トレーニングされた GAN モデルを通じて、指定された画像が GAN の潜在空間に逆マッピングされます。これは GAN 逆変換と呼ばれます。具体的には、事前トレーニングされた GAN は潜在コードから実際の画像へのマッピングを学習し、GAN は画像を潜在コードに逆マッピングします。これは、潜在コードを事前トレーニングされた GAN にフィードし、最適化を通じて画像を再構成することによって実現されます。 . 再構成メトリクスは、l1、l2、知覚損失または lpips に基づいており、最適化プロセス中に顔のアイデンティティまたは潜在コードに対する特定の制約を含めることができます。潜在コードを取得することにより、元の画像を再構成でき、現実的な画像操作を実行できます。潜在空間の中で。
明示的なクロスモーダル調整:
暗黙的なクロスモーダル監視: ガイド付きモダリティを潜在空間に明示的に投影することに加えて、生成された結果とガイド付きモダリティの間の一貫性の損失を定義することで合成または編集をガイドします。styleclip は、クリップ表現間のコサイン類似性を使用して、テキストガイドによる操作を監視します。
3.2 拡散ベースの方法
3.2.1 条件付き拡散モデル
条件付き拡散モデルは、条件付き情報をノイズ除去プロセスに直接統合することで指定できます。

条件付き融合: 特定の条件付きエンコーダーを使用して、マルチモーダル条件を埋め込みベクトルに投影し、さらにモデルに組み込まれます。特定の条件付きエンコーダーは、モデルとともに学習することも、Clip などの事前トレーニング済みモデルから直接借用することもできます。LDM では、条件付きエンコーダーはクロスアテンションを介して拡散モデルの中間層にマッピングされます。
潜在空間拡散: オートエンコーダを使用して、画像空間、VQ-VAE、dalle2: クリップ潜在空間と知覚的に同等の潜在空間を学習します。
3.2.2 事前トレーニングされた拡散モデル
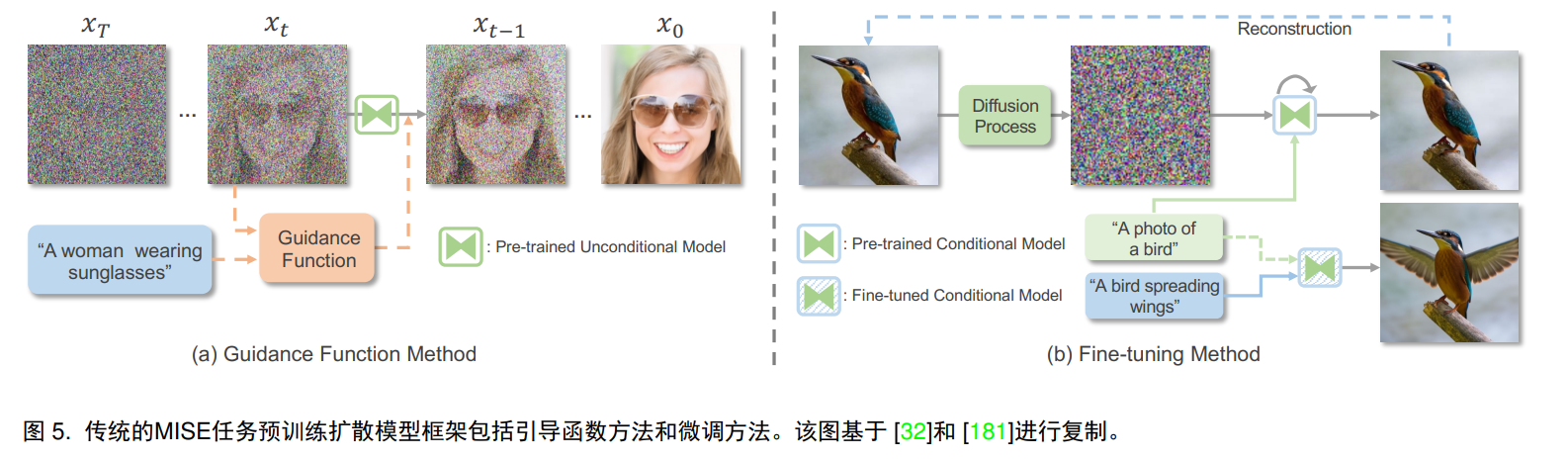
拡散モデルを再トレーニングするのとは対照的に、別の方法は、適切な単純化または微調整を通じてノイズ除去プロセスをガイドすることです。
ガイド付き関数メソッド: ガイド付き関数は、xt と y の間の一貫性を計算します。これは、ある種の類似性インデックス コサイン類似度または l2 距離によって測定できます。clip を画像エンコーダーおよびテキスト指向の条件付きエンコーダーとして使用できます。
微調整: これは、潜在エンコーディングを変更するか、事前トレーニングされた拡散モデルを調整することによって実現できます。テキスト ガイダンスに適応させるために、入力画像は最初に順拡散によって潜在空間に変換され、次に拡散モデルが変換されます。事前にトレーニングされた条件付きモデル (通常はテキスト) の画像の場合、GAN 逆変換と同様に、テキスト潜在埋め込みまたは拡散モデルを微調整して画像を再構成できます。別のアプローチは、段階的拡散サンプリングを利用して、ノイズ除去プロセスの初期段階で内容と構造を保持する部分的なガイダンスを提供することです。
3.3 自己回帰手法

平坦化された画像シーケンスを離散マーカーとして扱うことにより、自己回帰モデルを使用できます。これには、最初に統合された離散表現を生成してデータ圧縮を実現するベクトル量子化ステージ、2 番目にラスターを使用する自己回帰モデリング ステージ、格子スキャンの順序が含まれます。個別のタグ間の依存関係を確立します。
3.3.1 ベクトル量子化
すべての画像ピクセルを自己回帰用のシーケンスとして直接扱うと消費量が多すぎるため、離散的な画像圧縮が非常に重要です。VQVAE はエンコーダー、特徴量子化器、デコーダーで構成されます。画像はエンコーダーに入力されて連続表現を学習し、量子化器はそれをコードブック エントリに最も近い特徴に量子化し、デコーダは量子化された特徴から元の画像を再構築します。
損失関数: ガン損失、知覚損失、
コードブック: argmin (最も近いコードブック エントリを取得するため) を使用する一般的な VQVAE は、深刻なコードブックの崩壊の問題を引き起こします。量子化に効果的に使用されるのは少数のコードブック エントリだけです。argmin を置き換えるために Gumbel-softmax が導入され、Gumbel-softmax はパススルーを許可します。勾配推定器は、微分可能な方法で離散表現をサンプリングし、コードブックの使用率を高めます。
3.3.2 自己回帰モデリング
自己回帰はシーケンスの依存性に適応するために使用され、確率の連鎖規則に準拠します。シーケンス内の各マーカーの確率は、以前のすべての予測に条件付きです。結果として得られるシーケンスの同時分布は、条件付き確率の積です。このプロセスでは、各マーカーが順番に自己回帰予測を実行します。スライディング ウィンドウ戦略を使用すると、ローカル ウィンドウでの予測結果を活用できます。マルチモーダル画像生成タスクでは、自己回帰モデルは、以前に生成されたピクセルと与えられた条件付き情報を考慮した条件付き確率分布に基づいてピクセルごとに画像を生成します。これにより、モデルが複雑な依存関係をキャプチャし、視覚的に一貫した画像を生成できるようになります。
ネットワーク構造: PixelCNN、Parti
双方向コンテキスト: 以前に生成された結果のみに焦点を当て、この一方向戦略は順序バイアスの影響を受け、自己回帰が完了に近づく前に大量のコンテキスト情報を無視し、さまざまなスケールで大量のコンテキスト情報を無視します。ImageBart 。オクルージョン視覚マークアップ モデリング MVTM またはオクルージョン言語モデリング MLM メカニズムを伴う双方向トランスフォーマーもあります。
セルフアテンションメカニズム: NUMA
3.4 NeRF ベースの手法
ニューラル放射フィールド ニューラル フィールドを使用して 3 次元シーンの色と密度をパラメータ化することにより、完全に接続されたニューラル ネットワークが NeRF で使用され、空間位置 (x、y、z) と対応する視線方向 (θ) を入力として受け取ります。 、φ)、および対応する体積密度と放射輝度が出力として与えられます。暗黙的な 3D 表現から 2D イメージをレンダリングするには、数値積分器を介して微分可能なボリューム レンダリングを実行し、計算が困難なボリューム射影積分を近似します。
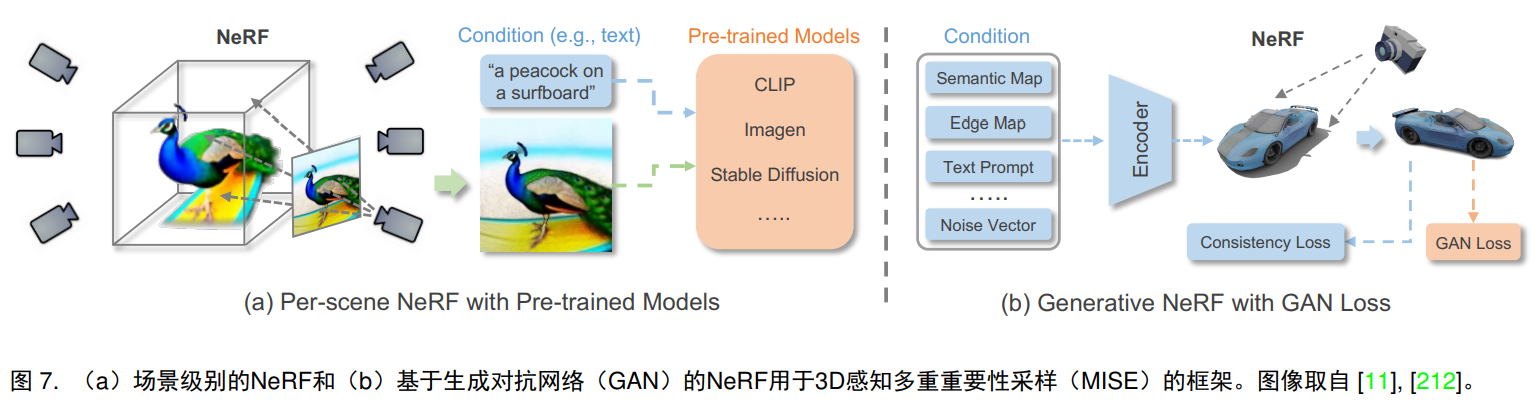
3.4.1 シーンごとの NeRF
オリジナルの NeRF モデルと一貫して、シーンごとの NeRF は、画像または特定の事前トレーニングされたモデルを通じて個々のシーンを最適化して表現するように設計されています。
画像監視: NeRF は、ペアのガイダンス情報と対応するビュー画像によって条件付きでトレーニングできます。AD-NeRF。
事前トレーニング済みモデルの監督: AvatarCIP、DreamFusion、Magic3D、Ref-NeRF
3.4.2 生成型 NeRF
シーンごとに最適化される NeRF とは異なり、生成 NeRF は、NeRF を生成モデルと統合することによって、さまざまなシナリオに一般化できます。
3.5 その他の方法
3.6 比較と議論
GAN は FID および Inception スコアで高忠実度の画像生成を実現し、推論速度は速いですが、GAN トレーニングは不安定でモード崩壊の問題が発生しやすいため、尤度ベースの拡散モデルや自己回帰モデルと比較して、GAN は忠実度に注意を払います。トレーニング データの分布の多様性を捉えるのではなく、さらに、GAN は通常、畳み込みネットワークを使用しますが、これをマルチモーダリティに一般化するのは困難です。トランスフォーマーと自己回帰モデルを使用すると、さまざまなマルチモーダル合成タスクを一般的な方法で処理できます。ただし、自己回帰モデルはラベルを予測する必要があるため、速度が遅くなり、拡散も推論速度が遅い。自己回帰モデルと拡散モデルは、安定したトレーニング目標と良好なトレーニング安定性を備えた尤度ベースの生成モデルです。Dalle2 では、拡散は自己回帰モデルよりわずかに優れています。
主に 2D 画像をターゲットにし、必要なトレーニング データが少ない上記の生成方法とは異なり、NeRF ベースの方法は 3D シーンを処理し、トレーニング データの要件が高くなります。シーンの最適化に基づく NeRF では、標準的なマルチビュー画像またはビデオが必要です。
4.実験評価
4.1 データセット
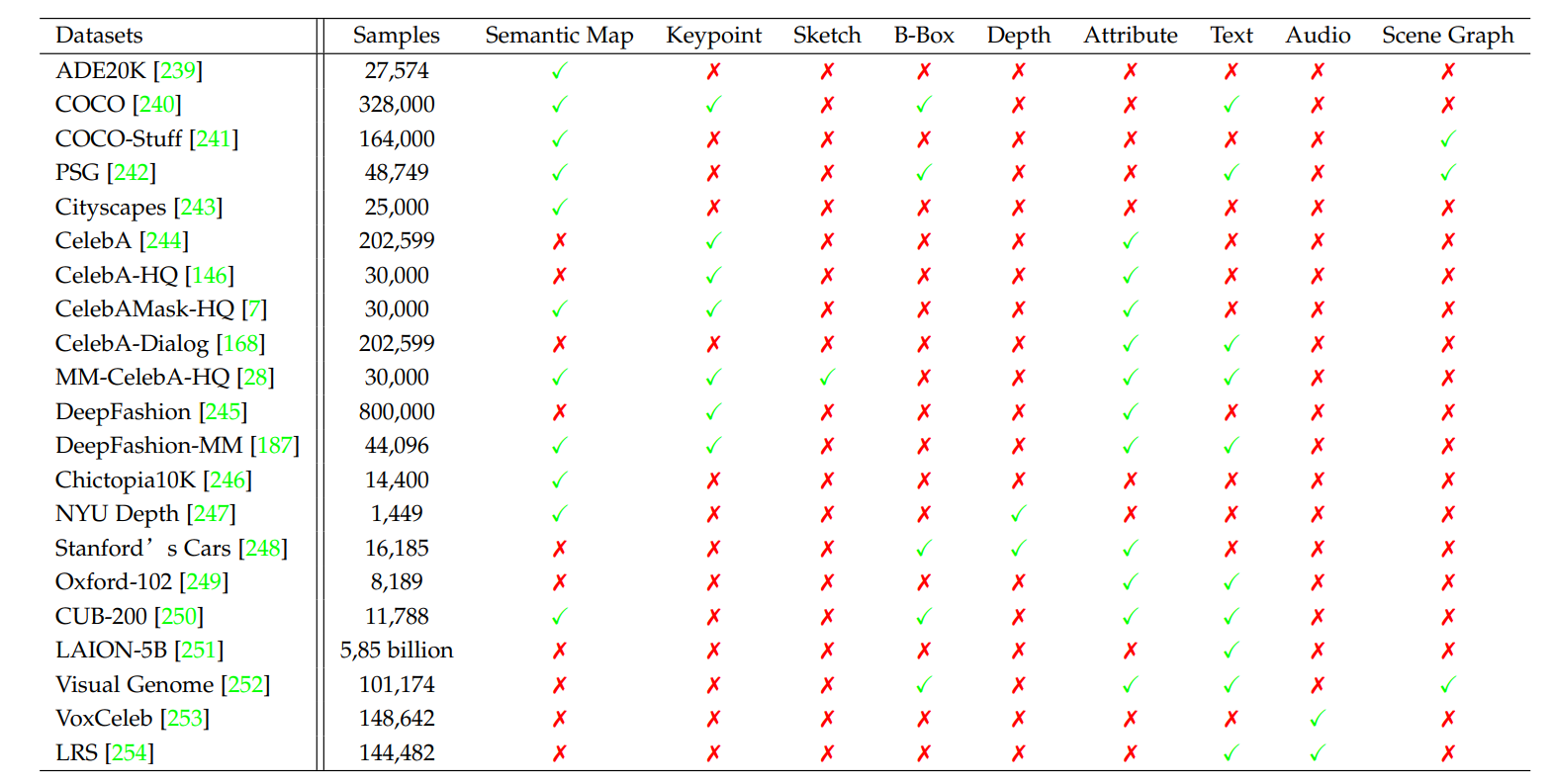
4.2 評価指標
インセプション スコアと FID は画質を評価し、LPIPS は画像の多様性を評価します。
4.3 実験結果
