この記事では、ECCV2022 に採択された浙江大学チームの研究結果、LPCG: Lidar Point Cloud Guided Monocular 3D Object Detection を推奨します。

LPCG: レーザー点群を使用して単眼 3D オブジェクト検出をガイドするレーザー点群を使用して単眼 3D オブジェクト検出をガイドすると、どのような効果がありますか?  https://mp.weixin.qq.com/s?__biz=MzUyMDc5OTU5NA==&mid=2247500597&idx=1&sn=8f2b62adc81e09afaa5c9f0f314b7035&chksm=f9e65730ce91de26820692da915cb13a102e5 2f5f9cb5c3fbf471674943d996784aaf319c3e9&token=212338627&lang=zh_CN #rd 01 概要
https://mp.weixin.qq.com/s?__biz=MzUyMDc5OTU5NA==&mid=2247500597&idx=1&sn=8f2b62adc81e09afaa5c9f0f314b7035&chksm=f9e65730ce91de26820692da915cb13a102e5 2f5f9cb5c3fbf471674943d996784aaf319c3e9&token=212338627&lang=zh_CN #rd 01 概要
単眼の 3D 物体検出は、自動運転やコンピュータ ビジョンの分野において非常に困難なタスクです。以前の作業のほとんどは 3D ラベル ボックスに手動でラベル付けされており、ラベル付けのコストが非常に高かったです。
著者のチームは、研究の中で直観に反する興味深い発見をしました。単眼 3D 検出では、正確で注意深く注釈が付けられたラベルは必要ない可能性があります。摂動された粗いラベルを使用する検出器は、グラウンド トゥルース ラベルを使用する検出器と比較して、非常に近い精度を達成します。著者のチームはこの現象を詳しく調査し、3D 位置部分のラベル付けが残りのラベル付けと比較して非常に重要であることを経験的に発見しました。
上記の結論に触発され、LiDAR 3D 測定の精度を考慮して、著者のチームは、LiDAR 点群誘導単眼 3D 物体検出 (LPCG) と呼ばれるシンプルで効果的なフレームワークを提案します。このフレームワークは、追加のアノテーション コストを導入することなく、アノテーション コストを削減したり、検出精度を大幅に向上したりできます。
具体的には、ラベルのない LiDAR 点群から擬似ラベルを生成します。3D 位置情報は正確であるため、このような擬似ラベルは、単眼 3D 検出器のトレーニングにおいて手動で注釈が付けられたラベルを置き換えることができます。LPCG は任意の単眼 3D 検出器に適用でき、自動運転システムで大量のラベルなしデータを最大限に活用できます。
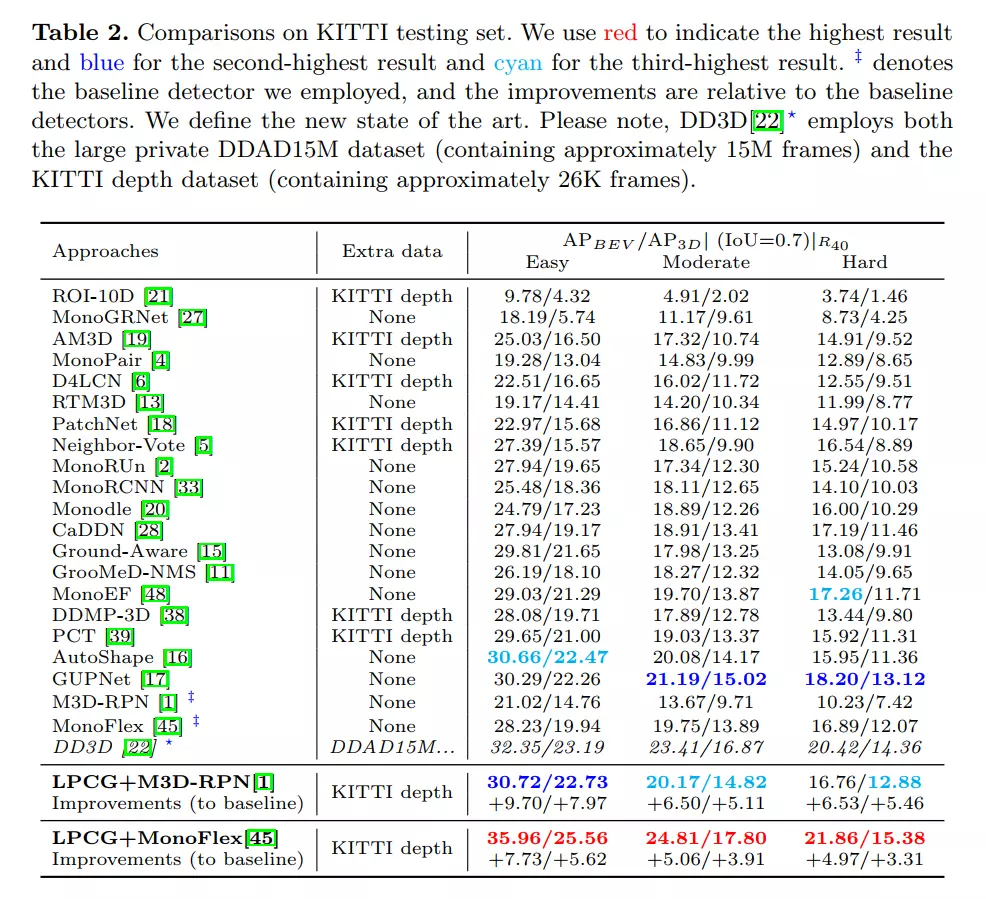
KITTI ベンチマークでは、LPCG フレームワークが単眼 3D 検出と BEV (鳥瞰図) 検出の両方で 1 位を達成し、大きな利点をもたらしました。Waymo ベンチマークでは、10% ラベル付きデータを使用した著者チームの方法は、100% ラベル付きデータを使用したベースライン検出器と同等の精度を達成しました。

02 モデル紹介
まず、図に示すように、単眼 3D 検出には手動で注釈を付けた完全なラベルは必要ありません。乱れたラベルの精度 (5%) は、完全なラベルの精度に匹敵します。大きな干渉 (10% および 20%) を実装すると、場所 (場所) がパフォーマンスを支配していることがわかります (AP は、干渉場所が大きくなる場合にのみ大幅に低下します)。これは、正確な位置を持つ粗い擬似 3D ボックス ラベルが、完全な注釈付き 3D ボックス ラベルを置き換えることができることを示しています。

LiDAR 点群が貴重な 3D 位置情報を提供できることがわかります。より具体的には、シーン内では、LiDAR 点群によって正確な深度測定が提供され、周囲の正確な深度情報によってより正確なオブジェクトの位置が提供されます。これは 3D オブジェクト検出にとって重要です。さらに、LiDAR 点群は LiDAR デバイスによって簡単に取得できるため、人件費をかけずに大規模な LiDAR 点群をオフラインで収集できます。
上記の分析に基づいて、著者のチームは LiDAR 点群を使用して 3D 立体擬似ラベルを生成します。新しく生成されたラベルを使用して、単眼 3D 検出器をトレーニングできます。このシンプルで効果的なアプローチにより、単眼 3D 検出器がラベルのないデータに対する注釈コストを削減しながら、目的のオブジェクトを学習できるようになります。一般的なフレームワークを図 1 に示します。この方法は、3D 注釈ボックスへの依存性に応じて 2 つのモードで動作します。著者のチームが以前のように少数の 3D ボックス アノテーションを使用する場合、この方法が高いパフォーマンスにつながるため、著者のチームはそれを高精度モード (高精度モード) と呼んでいます。対照的に、3D 直方体の注釈が使用されない場合、著者のチームはこれを低コスト モードと呼びます。
2.1 高精度モード
図 1 に示すように、利用可能な 3D ボックス アノテーションを活用するために、私たちのチームはまず、LiDAR 点群と関連する 3D ボックス アノテーションを使用して、LiDAR ベースの 3D 検出器を最初からトレーニングします。次に、事前トレーニングされた LIDAR ベースの 3D 検出器を利用して、他のラベルのない LIDAR 点群上の 3D ボックスを推論します。このような結果は、単眼 3D 検出器をトレーニングするための擬似ラベルとして使用されます。元の論文のセクション 5.5 では、著者のチームは疑似ラベルと手動で注釈が付けられた完全なラベルを比較しました。正確な 3D 位置測定により、LiDAR ベースの 3D 検出器によって予測された擬似ラベルは非常に正確であり、単眼 3D 検出器のトレーニングに直接使用できます。
アルゴリズム 1 の概要は次のとおりです。

興味深いことに、LiDAR ベースの 3D 検出器にさまざまなトレーニング設定を使用することで、私たちのチームは、生成された擬似ラベルからトレーニングされた単眼 3D 検出器が近いパフォーマンスを示すことを経験的に発見しました。これは、単眼法が実際に LiDAR 点群のガイダンスの恩恵を受けることができ、単眼法を駆動して高いパフォーマンスを達成するには少数の 3D アノテーション ボックスだけで十分であることを示しています。この方法では、高精度パターンの手動アノテーションのコストが以前の方法よりもはるかに低くなります。詳細な実験については、原文のセクション 5.6 を参照してください。ラベル付け要件と 3D ロケーションの観察が LPCG の中心的な動機であることに注意してください。LPCG が適切に動作するための前提条件は、LiDAR ポイントが豊富で正確な 3D 測定情報を提供し、それによって正確な 3D 位置が提供されることです。
2.2 低コストモード
このセクションでは、著者チームが、LiDAR 点群を使用して手動の 3D ボリューム ラベルへの依存を取り除く方法を紹介します。
まず、既製の 2D インスタンス セグメンテーション モデルを使用して RGB イメージをセグメント化し、2D ボックスとマスクの推定値を取得します。次に、これらの推定値を使用してカメラ錐台を構築し、各オブジェクトに関連する LiDAR RoI ポイントを選択します。内部に LiDAR ポイントがないボックスは無視されます。
ただし、同じ錐台内にある LIDAR ポイントは、オブジェクト ポイントと混合背景または遮蔽されたポイントで構成されます。無関係な点を排除するために、著者チームは DBSCAN を利用して、密度に応じて RoI 点群を異なるグループに分割しました。3D 空間内で近い点がクラスターに集められます。次に、著者らのチームは、最も多くの点を含むクラスターを、オブジェクトに対応するターゲットとみなしました。最後に、著者のチームは、すべてのオブジェクト ポイントをカバーする最小の 3D 境界ボックスを探します。
3D バウンディング ボックスを解く問題を単純化するために、作成者チームはオブジェクトの高さ (h) と y 座標 (カメラ座標系) が簡単に取得できるため、鳥瞰図に点を投影してパラメータを削減しました。したがって、著者チームは次のことを行います。
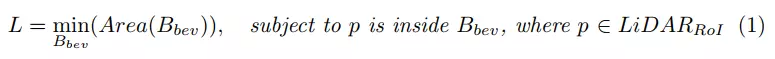
ここで、は Bird's Eye View (BEV) ボックスを指します。著者のチームは、オブジェクト ポイントの凸包を使用し、次に回転キャリパーを使用して立方体を取得することで、この問題を解決しました。さらに、高さ h は、点の y 軸に沿った最大空間オフセットによって表すことができ、中心座標 y は、点の y 座標を平均することによって計算されます。著者のチームは、オブジェクトの次元を制限する単純なルールを使用して外れ値を削除しました。
アルゴリズム 2 は、単眼法の全体的なトレーニング パイプラインを示しています。

03 実世界の自動運転システムへの応用
このセクションでは、著者チームが実際の自動運転システムへの LPCG の応用について説明します。

まず、著者チームはデータ収集戦略を図 3 に示しました。ほとんどの自動運転システムは、大量のラベルなしの LiDAR 点群データと RGB 画像を同時に簡単に収集できます。このデータは複数のシーケンスで構成されており、各シーケンスは通常、特定のシーンを指し、複数の連続したフレームが含まれています。現実世界では時間とリソースが限られているため、Waymo などのネットワークをトレーニングするためのアノテーションには一部のシーケンスのみが選択されます。さらに、高い注釈コストを削減するために、KITTI など、選択されたシーケンス内の一部のキーフレームのみに注釈が付けられます。したがって、実際のアプリケーションにはラベルのないデータが依然として大量に存在します。
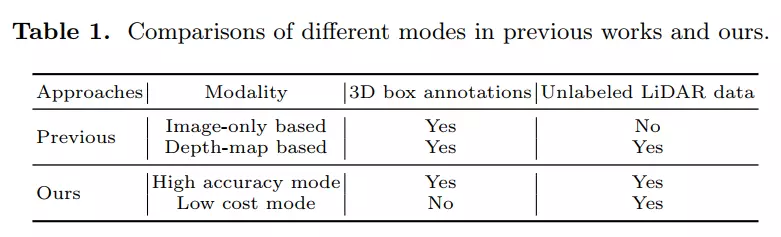
LPCG がラベルなしデータを最大限に活用できることを考えると、現実世界の自動運転システムで LPCG を使用するのは自然なことです。具体的には、高精度モードでは、少量のラベル付きデータのみが必要になります。その後、著者のチームは、単眼 3D 検出器の残りのラベルなしデータから高品質のトレーニング データを生成して、精度を向上させることができました。著者チームは実験で、生成された 3D ボックス擬似ラベルが単眼 3D 検出器に適していることを定量的および定性的に示しました。さらに、低コスト モデルは 3D 注釈ボックスを必要とせず、依然として正確な 3D ボックス擬似ラベルを提供できます。データ要件に関して、著者のチームは表 1 で LPCG を以前の方法と比較しました。

04 まとめ
この論文では、まず単眼 3D 検出の標識要件を分析します。実験では、摂動ラベルと完全ラベルが単眼 3D 検出器に非常に近い性能を達成できることを示しています。さらに調査を進めた結果、著者チームは 3D 位置が 3D ボックス ラベルの最も重要な部分であることを経験的に発見しました。さらに、自動運転システムは、正確な 3D 測定を使用して、ラベルのない大規模な LIDAR 点群を生成できます。したがって、著者チームは、単眼 3D 検出器のトレーニング セットを拡張するために、ラベルのない LiDAR 点群上に擬似 3D ボックス ラベルを生成するフレームワーク (LCPG) を提案します。さまざまなデータセットに対する広範な実験により、LCPG の有効性が検証されています。ただし、LCPG の主な制限は、トレーニング サンプルの増加によりトレーニング時間が長くなることです。