オリジナル | Wen BFT ロボット

01
まとめ
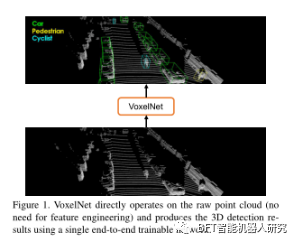
この論文では、VoxelNet と呼ばれる新しい点群ベースの 3D 検出方法を提案しています。これは、疎な点群の構造特性を利用して、疎な 3D 点を直接操作し、ボクセル グリッドの効率的な並列処理を通じてパフォーマンスの向上を実現する、エンドツーエンドのトレーニング可能な深層学習アーキテクチャです。
この方法は KITTI ベンチマーク データセットで実験され、VoxelNet が LIDAR ベースの自動車、歩行者、自転車検出タスクで最先端の結果を達成することを実証しています。実験によれば、VoxelNet は最先端の LiDAR ベースの 3D 検出方法を大幅に上回っています。
02
ボクセルネットフレームワーク
図 2 に示すように、これは一般的な 3D 検出フレームワークであり、同時に点群から識別特徴表現を学習し、エンドツーエンドの方法で正確な 3D 境界ボックスを予測します。
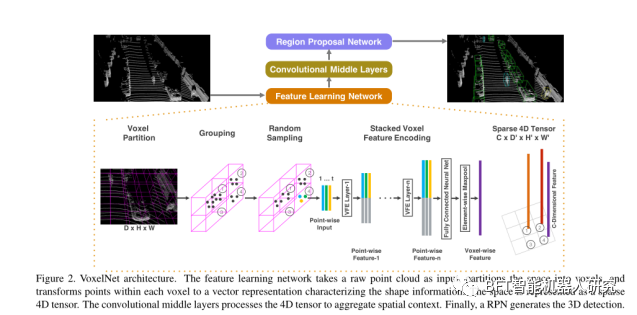
図 2 に示すように、これには主に 3 つのモジュールが含まれています。
1. 機能学習ネットワーク 機能学習ネットワーク
1.1 ボクセル分割
図 2 に示すように。点群には、それぞれ Z、Y、X 軸に沿った範囲 D、H、W を持つ 3D 空間が含まれていると仮定します。それに応じて、サイズ vD、vH、vW の各ボクセルを定義します。結果として得られる 3D ボクセル グリッドのサイズは、D' = D/vD、H' = H/vH、W' = W/vW になります。ここでは、簡単のため、D、H、W が vD、vH、vW の倍数であると仮定します。
1.2 グループ化
点群はまばらで、空間全体で点密度が非常に変化します。したがって、グループ化後、ボクセルには可変数のポイントが含まれます。図 2 に示すように、ボクセル 1 にはボクセル 2 およびボクセル 4 より多くのポイントがあり、ボクセル 3 にはポイントがありません。
1.3 ランダムサンプリング ランダムサンプリング
計算を節約するために、ボクセル間のポイントの不均衡が減少し、サンプリング バイアスが減少し、T ポイントを超えるボクセルから固定数の T ポイントをランダムにサンプリングすることで、トレーニングにさらにバリエーションが追加されます。
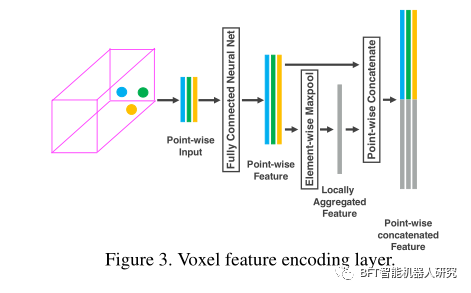
1.4 スタックされたボクセル特徴のエンコーディング スタックされたボクセル特徴のエンコーディング
図 3 は、VFE レイヤ 1 のアーキテクチャを示しています。
1.5 スパーステンソル表現
空ではないボクセルを処理することによって、ボクセル特徴のリストが取得され、それぞれが特定の空ではないボクセルの空間座標に一意に関連付けられます。結果として得られるボクセル特徴のリストは、サイズ C×D'×H'×W' の疎な 4D テンソルとして表すことができます。空ではないボクセル フィーチャをスパース テンソルとして表現すると、バックプロパゲーション中のメモリ使用量と計算コストが大幅に削減され、効率的な実装のための重要なステップとなります。
2. 畳み込み中間層
ConvMD(cin, cout, k, s, p) を使用して m 次元の畳み込み演算子を表します。ここで、cin と cout は入力チャネルと出力チャネルの数、k、s、p はそれぞれカーネル サイズ、ストライド サイズ、パディング サイズに対応する m 次元ベクトルです。
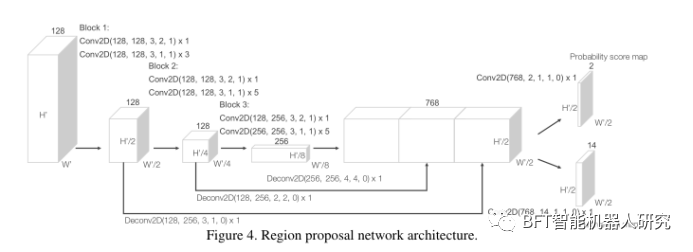
3. 地域提案ネットワーク 地域提案ネットワーク
RPN は、高性能の物体検出フレームワークの重要な部分として機能します。この研究では、著者らは RPN アーキテクチャに重要な変更を加え、それを特徴学習ネットワークおよび畳み込み中間層と組み合わせて、エンドツーエンドのトレーニング可能なパイプラインを形成しました。
RPN の入力は、畳み込み中間層によって提供される特徴マップです。ネットワークのアーキテクチャは、3 つの完全な畳み込み層ブロックで構成されています。各ブロックの最初の層は、ストライド 2 での畳み込みによって特徴マップをダウンサンプリングし、その後にストライド 1 で一連の畳み込み演算を実行します。各畳み込み層の後に、バッチ正規化 (BN) および ReLU 操作が適用されます。次に、各ブロックの出力が固定サイズにアップサンプリングされ、連結されて高解像度の特徴マップが構築されます。最後に、この特徴マップは、確率スコア マッピングや回帰マッピングなどの学習目標にマッピングされます。
03
損失関数 損失関数
これは 2 つの部分に分かれており、1 つは分類、もう 1 つは回帰です。分類にはバイナリ クロス エントロピーが使用され、回帰にはスムーズ L1 損失が使用されます。
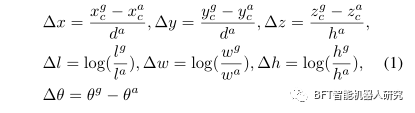
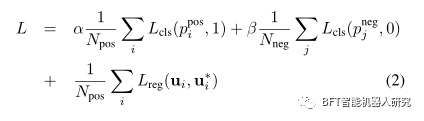
04
データ増強
点群オブジェクト検出では、ネットワークを最初からトレーニングするためのトレーニング データが 4000 個未満の点群である場合、過学習の問題に直面します。この問題を軽減するために、著者らは、ディスクに保存せずにオンザフライで生成される 3 つの異なる形式のデータ拡張を導入しました。
データ拡張の最初の形式は、各グラウンドトゥルース境界ボックスと境界ボックス内の点群に摂動を適用することです。摂動には、Z 軸を中心とした回転と XYZ 方向の並進が含まれます。不可能な結果を避けるために、衝突テストが実行され、境界ボックス間に衝突がないことが確認されます。2 番目の機能強化は、すべてのグラウンド トゥルース境界ボックスと点群全体にグローバル スケーリングを適用して、さまざまなサイズや距離のオブジェクトに対するネットワークの検出の堅牢性を向上させることです。最後に、車両の回転をシミュレートするために、すべてのグラウンド トゥルース境界ボックスと点群全体に対してグローバル回転が実行されます。
このアプローチにより、ネットワークはより多くのデータの変化から学習できるようになり、点群オブジェクト検出のパフォーマンスと堅牢性が向上します。
05
実験結果
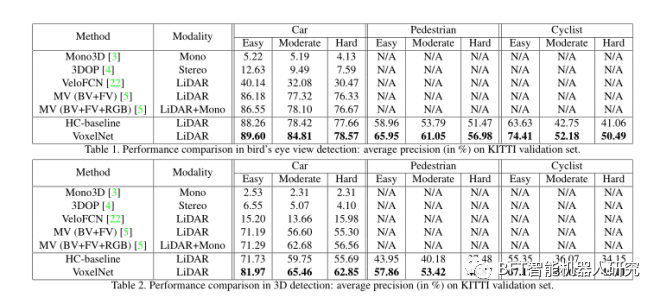
06
結論は
VoxelNet は、KITTI の自動車検出タスクにおいて、既存の LIDAR ベースの 3D 検出方法を大幅に上回ります。歩行者や自転車のより困難な 3D 検出タスクでも、VoxelNet は有望な結果を示し、より優れた 3D 表現機能を提供することを証明しました。
著者らの今後の取り組みには、検出と位置特定の精度をさらに向上させるために、ジョイント LIDAR および画像ベースのエンドツーエンド 3D 検出用に VoxelNet を拡張することが含まれます。
論文のタイトル:
VoxelNet: 点群ベースの 3D オブジェクト検出のためのエンドツーエンド学習
URL:
https://arxiv.org/pdf/1711.06396.pdf%20em%2017/12/2017.pdf
コードリファレンス:
https://github.com/ModelBunker/VoxelNet-PyTorch