時系列予測では、機械学習と深層学習がますます使用されています。ARIMA や指数平滑法などの古典的な予測手法は、XGBoost、ガウス プロセス、ディープ ラーニングなどの機械学習回帰アルゴリズムに置き換えられています。
タイミング モデルはますます複雑になっていますが、タイミング モデルのパフォーマンスについては疑問があります。研究では、複雑なタイミング モデルが必ずしもタイミング分解モデルよりも効果的であるとは限らないことが示されています (Makridakis、2018)。
テクノロジーのアップグレード
テクノロジーは共有とコミュニケーションを学ぶ必要があり、密室で作業することはお勧めできません。
良い記事は、ファンの共有と推奨、ドライデータ、データ共有、データ、技術交流の改善と切り離せないものであり、これらはすべてコミュニケーショングループを追加することで取得できます。グループには2,000人以上の友達がいます。グループを追加する最良の方法メモは、情報源 + 興味のある方向性を備えており、同じ考えを持つ友人を簡単に見つけることができます。
方法①、WeChatアカウントの追加: dkl88191、備考: CSDNより
方法②、WeChat検索公式アカウント: Pythonの学習とデータマイニング、バックグラウンド返信: グループの追加
時系列予測はなぜ難しいのでしょうか?
時系列は時間順に並べられた値ですが、時系列の予測は非常に困難です。モデルの難易度と精度の観点から見ると、時系列モデルは従来の回帰タスクや分類タスクよりも困難です。
理由 1: シーケンスが非定常である
定常性は時系列の中核概念であり、その傾向 (平均など) が時間の経過とともに変化しない場合、時系列は定常的です。既存の手法の多くは、時系列が定常であることを前提としていますが、傾向や季節性によって定常性が崩れます。
理由 2: 外部データへの依存
時間要素に加えて、時系列には追加の依存関係があることがよくあります。一般的な例は時空間データです。このデータでは、各観測値が 2 次元で関連付けられているため、データ自体の遅れ (時間依存性) と、近くの場所の遅れ (空間依存性) が生じます。
理由 3: ノイズと欠損値
現実の世界はノイズや欠損値に悩まされており、機器の故障によってノイズや欠損値が発生する可能性があります。センサーの故障や干渉によるデータ損失により、データ ノイズが発生する可能性があります。
理由 4: サンプルサイズが限られている
時系列には少数の観測値しか含まれていないことが多く、適切なモデルを構築するのに十分なデータがない可能性があります。データ収集の頻度はサンプル サイズに影響し、データのコールド スタートの問題も発生します。
サンプルサイズとモデルの精度
時系列モデルは完全な予測を行うことができないことが多く、これは時系列データのサンプル サイズに関係している可能性があります。大きなサイズのモデルは、より大きなトレーニング セットを使用する場合、パラメーターが少ないモデルよりもパフォーマンスが向上する傾向があります。時系列の長さが 1000 未満の場合、ディープ モデルは時系列分類モデルよりも優れていないことがよくあります。
モデルの精度とサンプル数の関係を以下に比較します。ここでは、5 つの古典的な手法 (ARIMA、ETS、TBATS、Theta、Naive) と 5 つの機械学習手法 (ガウス プロセス、M5、LASSO、ランダム フォレスト、MARS) を試しています。予測タスクは、時系列の次の値を予測することです。
結果は以下の図に示されており、軸はトレーニング サンプル サイズ、つまり予測モデルの適合に使用されたデータの量を表しています。軸は、相互検証を使用して計算された、すべての時系列にわたる各モデルの平均誤差を表します。
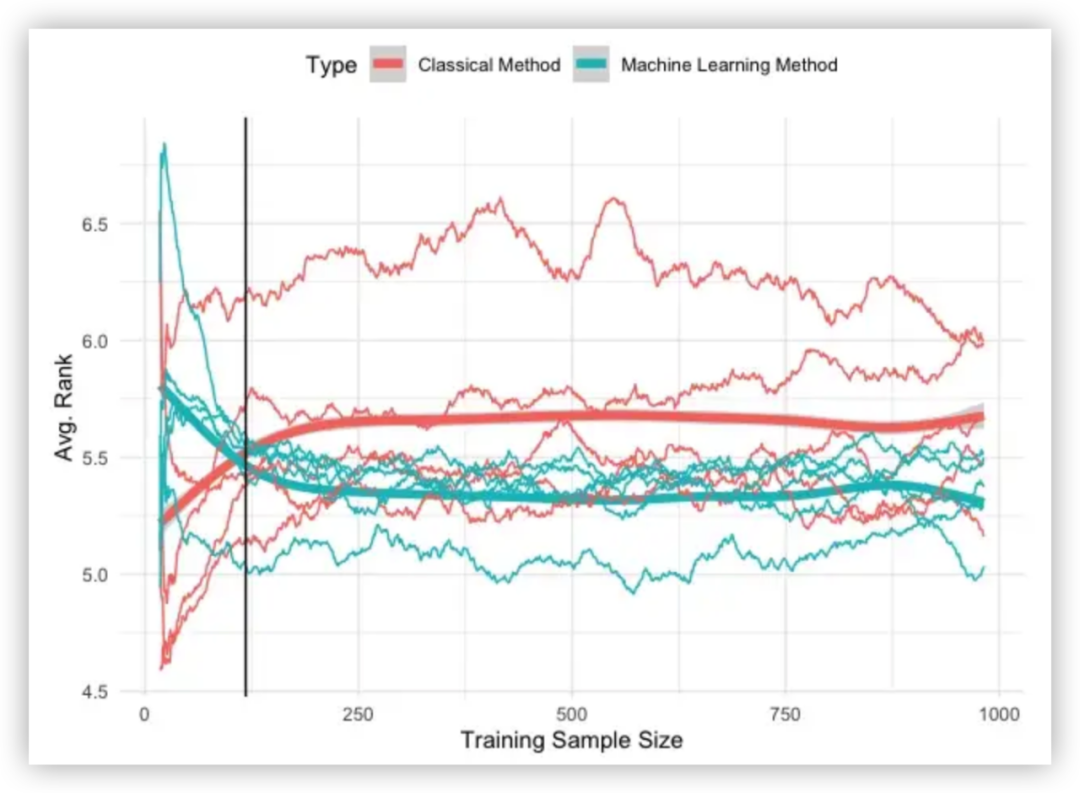
利用可能な観測値が少数である場合、基本方法の方が優れたパフォーマンスを示します。ただし、サンプルサイズが増加するにつれて、機械学習手法は従来の手法よりも優れたパフォーマンスを発揮します。
さらに次のような結論を導き出すことができます。
-
機械学習手法は、十分に大規模なトレーニング データセットがあれば、強力な予測力を備えています。
-
少数の観測値しか利用できない場合は、ARIMA や指数平滑法などの古典的な手法を優先することをお勧めします。
-
指数平滑法などの古典的な手法と機械学習を組み合わせることで、予測精度を向上させることができます。
時系列マルチステップ予測
ほとんどの予測問題はワンステップ予測として定式化され、最近のイベントに基づいて一連の次の値を予測します。時系列マルチステップ予測では、将来の複数の値を予測する必要がありますが、多くのステップを事前に予測することには重要な実用上の利点があり、マルチステップ予測は長期的な不確実性を軽減します。しかし、モデルがさらに先の将来を予測しようとすると、モデルの誤差も徐々に増加します。
方法 1: 再帰的予測
マルチステップ予測への最も単純なアプローチは再帰的形式です。この形式では、単一のモデルが単一ステップの予測を行うようにトレーニングされ、モデルとその以前の予測が後続の出力を取得するための入力として使用されます。
from sklearn.linear_model import LinearRegression
# using a linear regression for simplicity. any regression will do.
recursive = LinearRegression()
# training it to predict the next value of the series (t+1)
recursive.fit(X_tr, Y_tr['t+1'])
# setting up the prediction data structure
predictions = pd.DataFrame(np.zeros(Y_ts.shape), columns=Y_ts.columns)
# making predictions for t+1
yh = recursive.predict(X_ts)
predictions['t+1'] = yh
# iterating the model with its own predictions for multi-step forecasting
X_ts_aux = X_ts.copy()
for i in range(2, Y_tr.shape[1] + 1):
X_ts_aux.iloc[:, :-1] = X_ts_aux.iloc[:, 1:].values
X_ts_aux['t-0'] = yh
yh = recursive.predict(X_ts_aux)
predictions[f't+{
i}'] = yh
上記のコード ロジックの対応する実装は、sktime にもあります: https://www.sktime.org/en/stable/api_reference/auto_generated/sktime.forecasting.compose.RecursiveTimeSeriesRegressionForecaster.html
再帰的手法では、予測期間全体に対して 1 つのモデルのみが必要であり、予測期間を事前に決定する必要はありません。
ただし、この方法は独自の予測を入力として使用するため、誤差が徐々に蓄積され、長期予測の予測パフォーマンスが低下します。
方法 2: 多目的回帰
多目的回帰では、次のユースケースのように、予測される結果ごとにモデルを構築します。
from sklearn.multioutput import MultiOutputRegressor
direct = MultiOutputRegressor(LinearRegression())
direct.fit(X_tr, Y_tr)
direct.predict(X_ts)
scikit-learn は、MultiOutputRegressorターゲット変数ごとに学習アルゴリズムを複製します。この場合、予測方法は ですLinearRegression。
この方法では、再帰的な方法でエラーの伝播が回避されますが、多目的予測にはより多くのコンピューティング リソースが必要です。さらに、多目的予測は各点が独立していることを前提としているため、時系列データの特性に違反します。
アプローチ 3: 再帰的多目的回帰
再帰的多目的回帰は、多目的と再帰の考え方を組み合わせたものです。各点のモデルを構築します。ただし、各ステップで、前のモデルの予測に従って入力データが増加します。
from sklearn.multioutput import RegressorChain
dirrec = RegressorChain(LinearRegression())
dirrec.fit(X_tr, Y_tr)
dirrec.predict(X_ts)
このアプローチは、機械学習の文献では として知られていますchaining。scikit-learn は、RegressorChain クラスを通じてこれの実装を提供します。
参考文献
マクリダキス、スピロス、エバンゲロス・スピリオティス、ヴァシリオス・アシマコプロス。「統計的および機械学習による予測手法: 懸念事項と今後の方向性」PloS one 13.3 (2018): e0194889。