[MATLAB Issue 68] 将来の予測を含む MATLAB の LSTM 長短期記憶ネットワークに基づく多変数時系列データのマルチステップ予測 (シングルステップ予測ではない)
入力前25回、出力後5回
1. データ変換
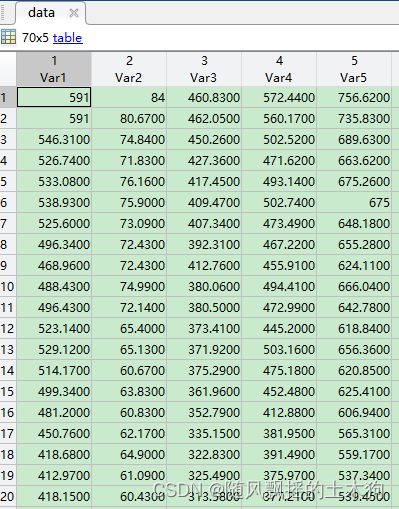
1.オリジナルデータ
5列の時系列データ、70行のサンプル、
70×5のデータ行列構造
2. データ変換
合計データを 14 のセルに分割し、
各行は 14 行のデータのうちの 5 つの変数の 5 日分のデータを表します。
マルチステップ予測: 最初の 25 日間のデータに基づいて次の 5 日間のデータを予測します。
つまり、5 1cell は 1 1cellを予測します。
例: 行 1 ~ 5 のセルは 6 行目を予測します (1 ~ 25 日、26 ~ 30 日を予測)
行 2 ~ 6 のセルは 7 行目を予測します (6 ~ 30 日、31 ~ 35 日を予測)
...
行 9 ~ 13 のセルは行 14 を予測します (41 ~ 65 日、予測 66 ~ 70 日)
次に、data_y を 5 25 に変更します。これは、data_x シーケンスの長さと一致します。
data_add(n,1) ={zeros(5,20)};、ゼロ値を追加します。つまり、
data_y を 5 5 から5* に変換します。 25
2. パラメータの設定
%% LSTM网络训练
inputsize =5;
outputsize =5;
layers=[sequenceInputLayer(inputsize);
bilstmLayer(200);
dropoutLayer(0.2);
fullyConnectedLayer(outputsize);
regressionLayer();
];
opts = trainingOptions('adam', ...
'MaxEpochs',2000, ...
'GradientThreshold',1,...
'ExecutionEnvironment','cpu',...
'InitialLearnRate',0.005, ...
'LearnRateSchedule','piecewise', ...
'LearnRateDropPeriod',125, ... %2个epoch后学习率更新
'LearnRateDropFactor',0.2, ...
'Shuffle','once',... % 时间序列长度
'L2Regularization',0.005,...%正则项系数初始值。建议一开始将正则项系数λ设置为0,先确定一个比较好的learning rate。然后固定该learning rate,给λ一个值(比如1.0),然后根据validation accuracy,将λ增大或者减小10倍(增减10倍是粗调节,当你确定了λ的合适的数量级后,比如λ = 0.01,再进一步地细调节,比如调节为0.02,0.03,0.009之类。
'SequenceLength',25,...
'MiniBatchSize',10,...%比如mini-batch size设为100,则权重更新的规则为:%也就是将100个样本的梯度求均值,替代online learning方法中单个样本的梯度值
'Verbose',1,...
'Plots','training-progress');
3. 予測
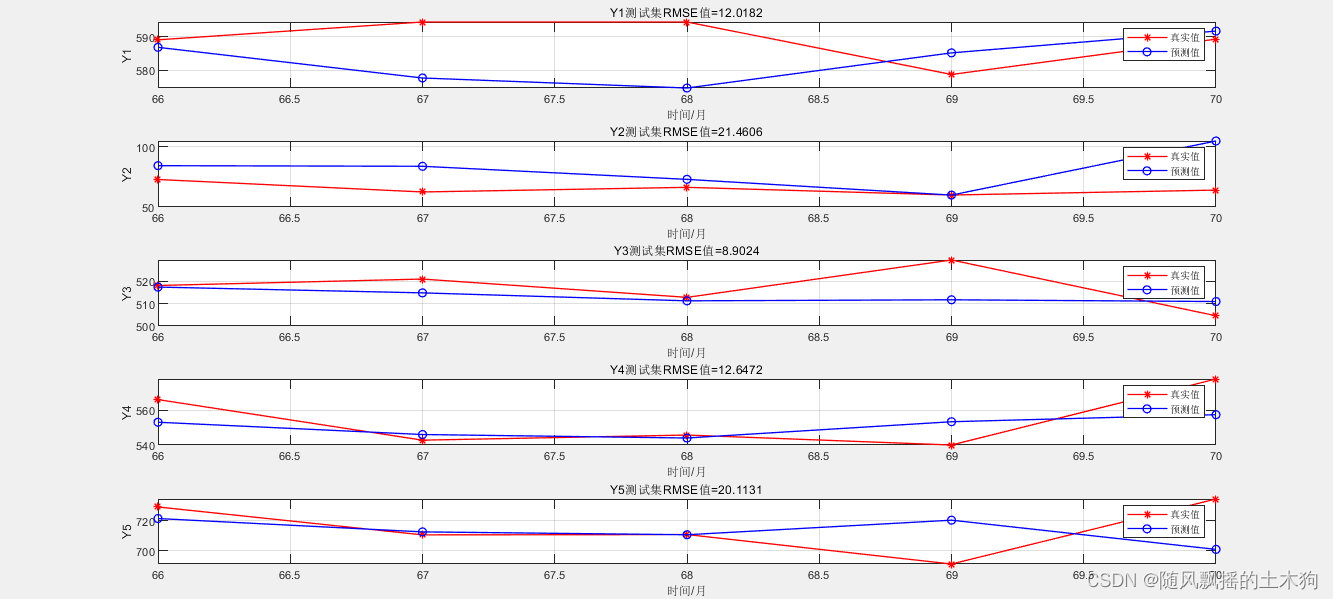
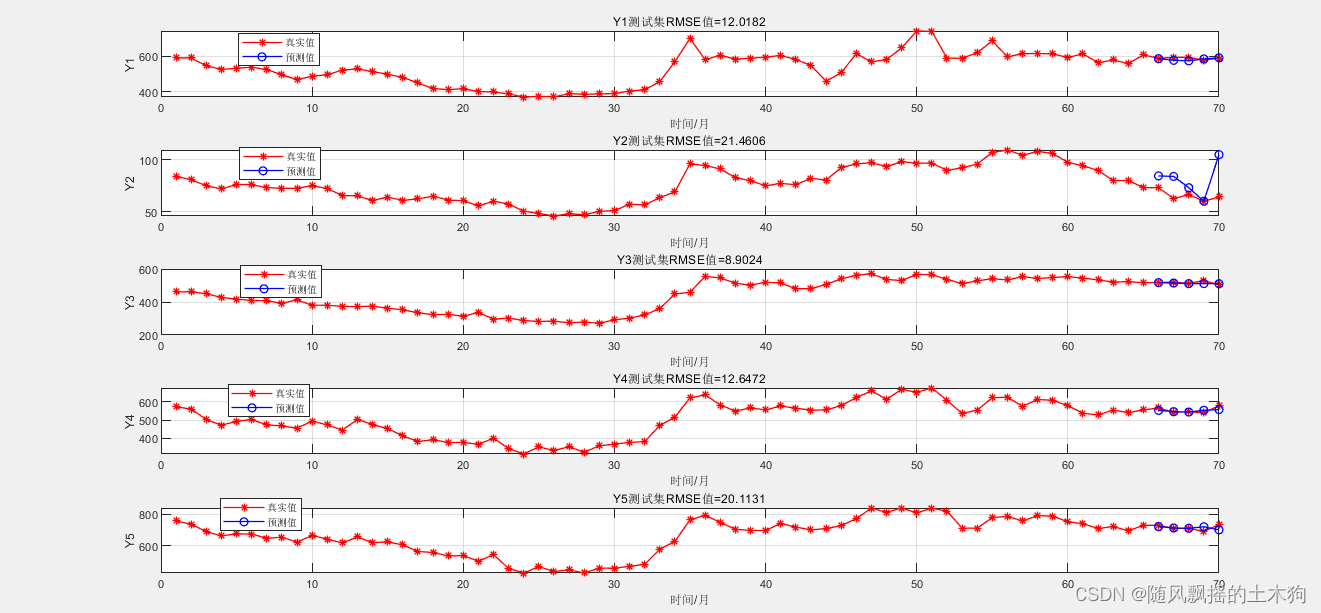
1. テストセットの効果
data_x にデータの最後の行、つまり 41 ~ 65 日を入力し、
[1 ~ 20 の構築データ] + 66 ~ 70 日のデータ、
フィルター後の 5 日分のデータを出力します。
2. 未来を予測する
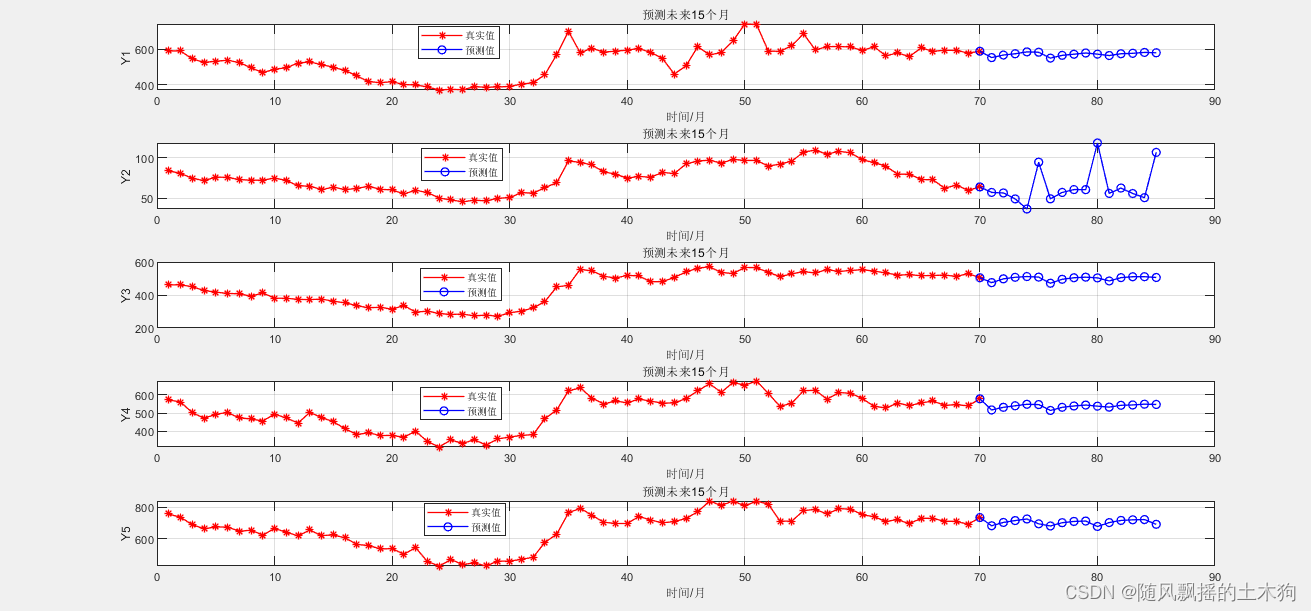
今後 5 日間の P1 (71 ~ 75) を予測する必要がある場合、
46 ~ 70 日の 5 つの変数データを入力するだけで
、[1*20 構築データ] + 71 ~ 75 日のデータが得られます。
今後 10 日間の P2 (76-80) を予測する必要がある場合、
51 日から 75 日までの 5 つの変数データを入力するだけで済みます (71 日から 75 日のデータは P1 によって提供されます)。
[1* 20 の構築データ] + 76 ~ 80 日分のデータ
今後 15 日間の P3 (81 ~ 85) を予測する必要がある場合、
56 ~ 80 日の 5 つの変数データを入力するだけで済みます (76 ~ 80 日のデータは P2 によって提供されます)。次の
結果が得られます。[1 *20構築データ]+81~85日分のデータ
4. コードの取得
ダウンロード リンクを取得するには、バックグラウンドでプライベート メッセージに「問題 68」と返信します。