前書き: 畳み込みニューラル ネットワークは、深層学習アルゴリズムの重要な部分であり、深層学習画像認識技術の応用において重要な役割を果たします。畳み込みニューラル ネットワークとリカレント ニューラル ネットワーク (RNN) は、従来の完全接続ニューラル ネットワーク (ディープ ニューラル ネットワークとも呼ばれ、DNN とも呼ばれます) に似ています。CNN は空間相関を符号化する DNN に属し、RNN は時間相関を符号化する DNN に属します。画像タスクが異なるため、CNN のネットワーク層も若干変更されますが、基本的には畳み込み層、プーリング層、非線形層が使用されます。この分野の理論的知識の理解を深めるために、この記事では、CNN の畳み込み演算、プーリング演算、および活性化関数についてさまざまな側面から詳しく説明します。
目次
1.畳み込み層
畳み込み層の機能は、入力画像内の情報を抽出することです。これらの情報は画像特徴と呼ばれます。これらの特徴は、画像のテクスチャ特徴や色特徴などの組み合わせまたは独立した方法を通じて、画像内の各ピクセルに反映されます。 。
1.1 畳み込み計算
具体的な畳み込み計算を説明する前に、いくつかのアニメーションを通して、異次元の畳み込み演算を直感的に感じてみましょう。
1 次元の畳み込み演算を次の図に示します。
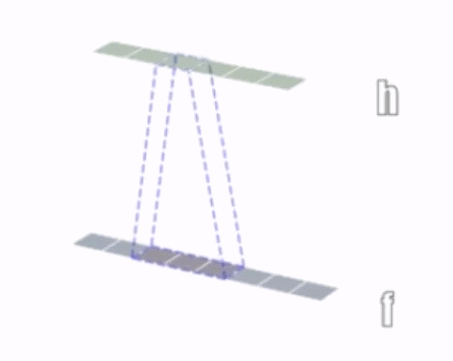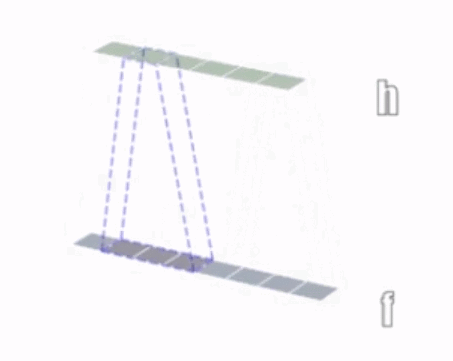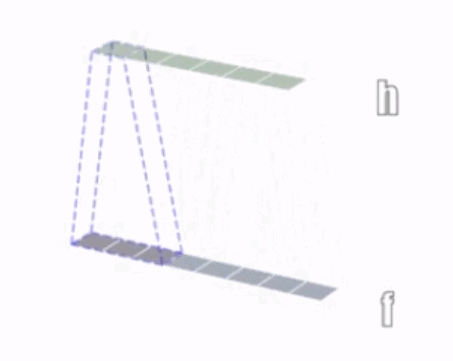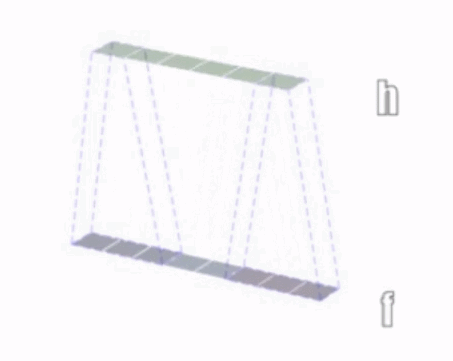
2 次元の畳み込み演算を次の図に示します。
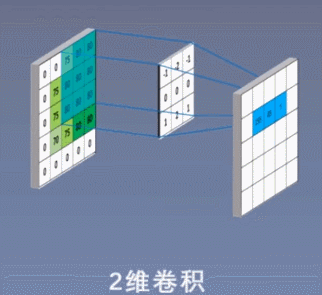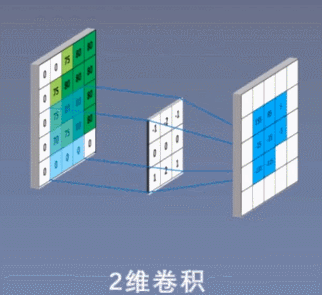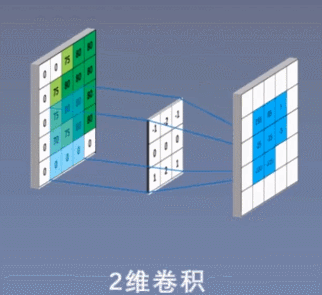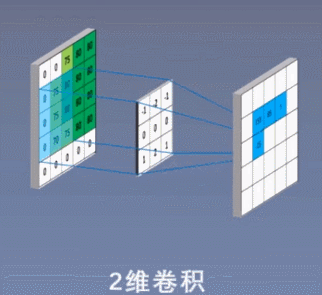
3 ビットの畳み込み演算を次の図に示します。

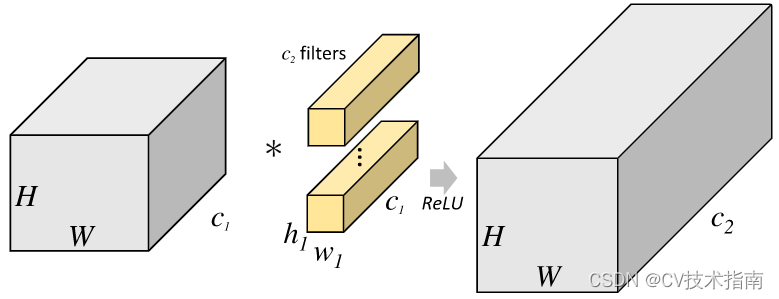
コンボリューション カーネルは線形演算を実行し、カーネル上の各値に、スライド先の対応する位置の値を乗算し、これらの値を加算します。Conv2d がどのように畳み込み計算を実行するかを説明するために、2 次元の畳み込みを例に挙げます。畳み込み計算を説明する前に、畳み込み演算を理解するのに非常に役立ついくつかの重要な概念を理解する必要があります。
①二次元畳み込みの二次元とは、畳み込みカーネルが二次元であるという意味ではなく、畳み込みカーネルの次元とは関係なく、畳み込みカーネルが二次元でのみスライドすることを意味します。同様に、1 次元コンボリューションと 3 次元コンボリューションは、上の 3 つの図に示すように、コンボリューション カーネルが 1 次元または 3 次元でスライドすることを意味します。
②コンボリューションカーネルチャネルの数(またはコンボリューションカーネルの数、コンボリューションカーネルのセットには複数のコンボリューションカーネルが存在します) = 入力層チャネルの数;
③出力層チャネルの数(つまり、特徴マップチャネルの数または特徴マップの数)=畳み込みカーネルグループの数、つまり、一連の畳み込みカーネルが実行した後に取得できる特徴マップは1つだけです1 つのチャネルは、入力に対して畳み込み計算を実行するために n セットの畳み込みカーネルを使用する必要があることを示します。
上記の概念を理解した後、例を使用して 2 次元の畳み込みがどのように計算されるかを具体的に体験してみましょう。
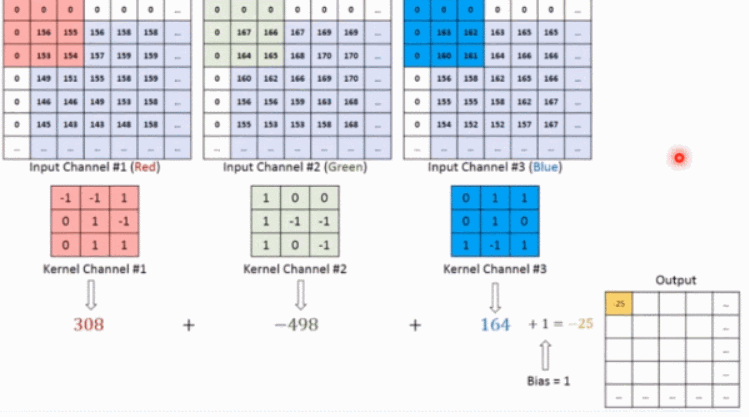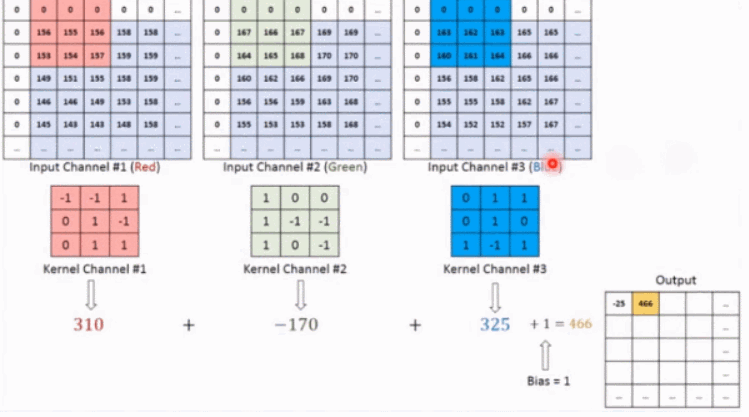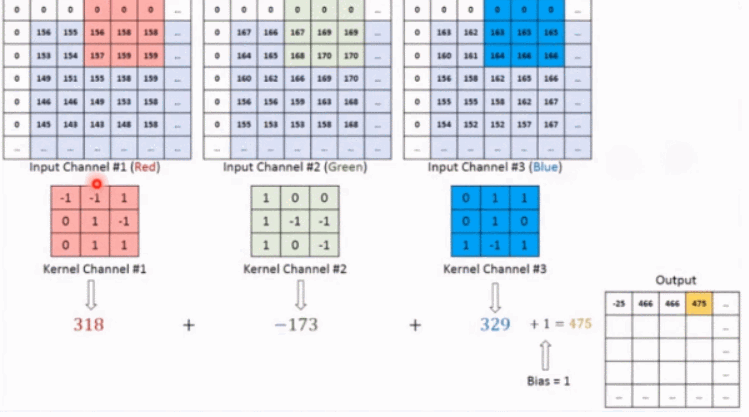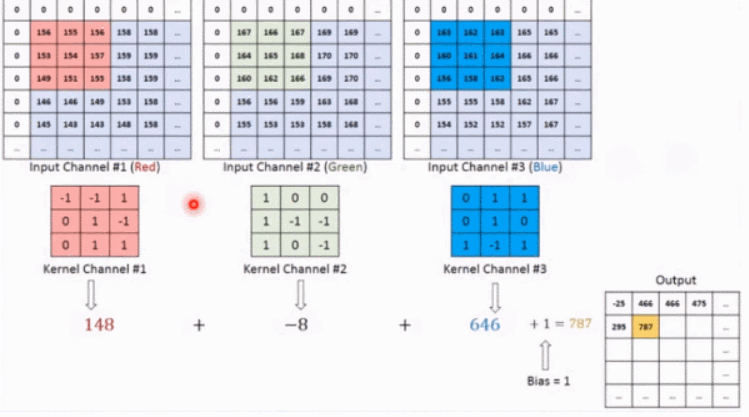
上の図に示すように、入力が RGB3 チャネルを持つ 2 次元画像であると仮定すると、コンボリューション カーネルのセットには 3 つの 2 次元コンボリューション カーネルが含まれます。つまり、コンボリューション カーネルにも 3 つのチャネルが必要です。これら 3 つのコンボリューション カーネルは、入力画像の 3 つのチャネル上をそれぞれスライドします。たとえば、R チャネルでは、スライドするたびに、対応する要素が乗算および加算されて数値が得られ、3 つのコンボリューション カーネルが 1 回スライドすると 3 が得られます。これら 3 つの数値を加算し、バイアスを追加して特徴マップ上の値を取得します。コンボリューション カーネルのセットが入力画像全体にスライドします。これで、完全な特徴マップが得られます。この特徴マップは、画像から抽出された特徴を表します。入力画像。一般に、入力画像上の 1 つの特徴だけを抽出するだけでは十分ではなく、多くの場合、入力画像上でより多くの特徴情報を取得する、つまり複数の特徴マップを取得する必要があり、その場合、畳み込みを実行するには複数セットの畳み込みカーネルが必要になります。画像上の商品計算です。以下の図では、2 セットの畳み込みカーネルを使用して 2 つの特徴マップを計算しています。
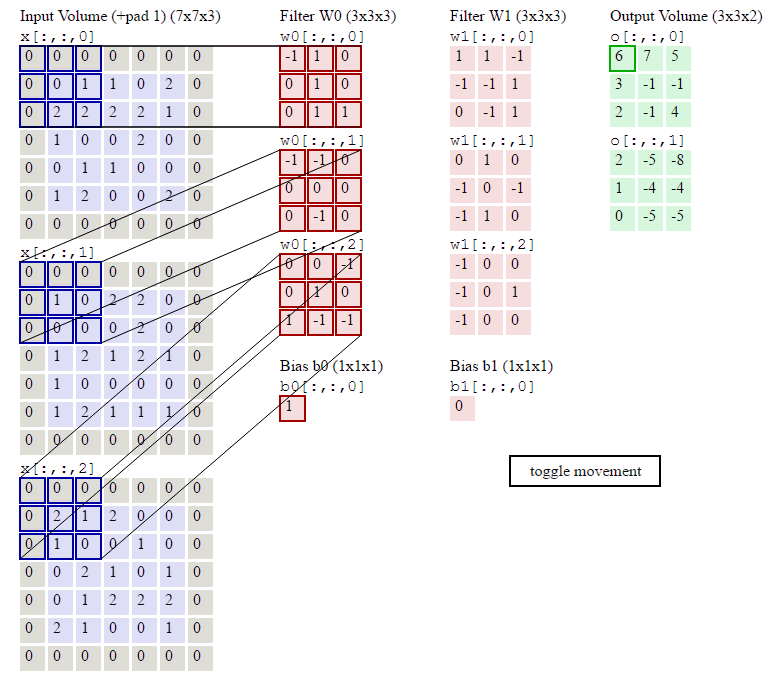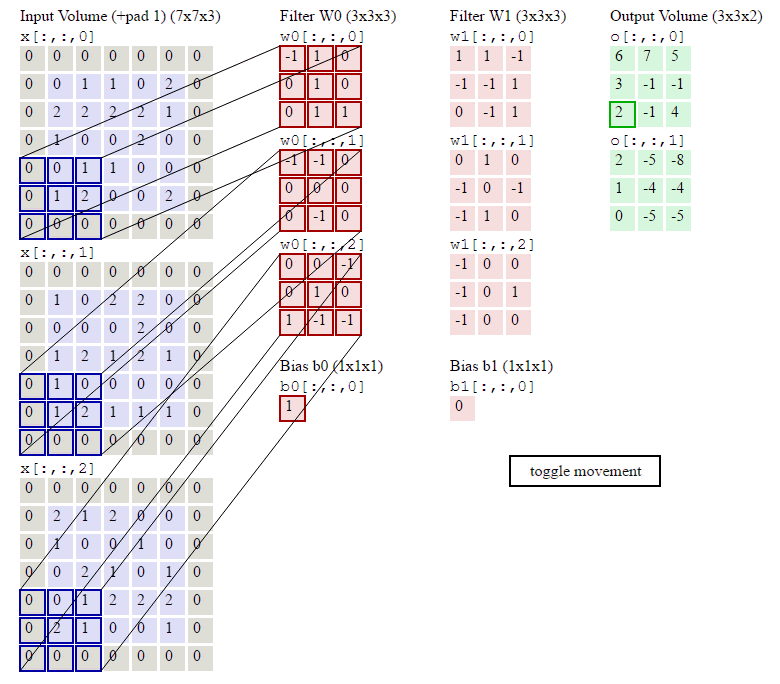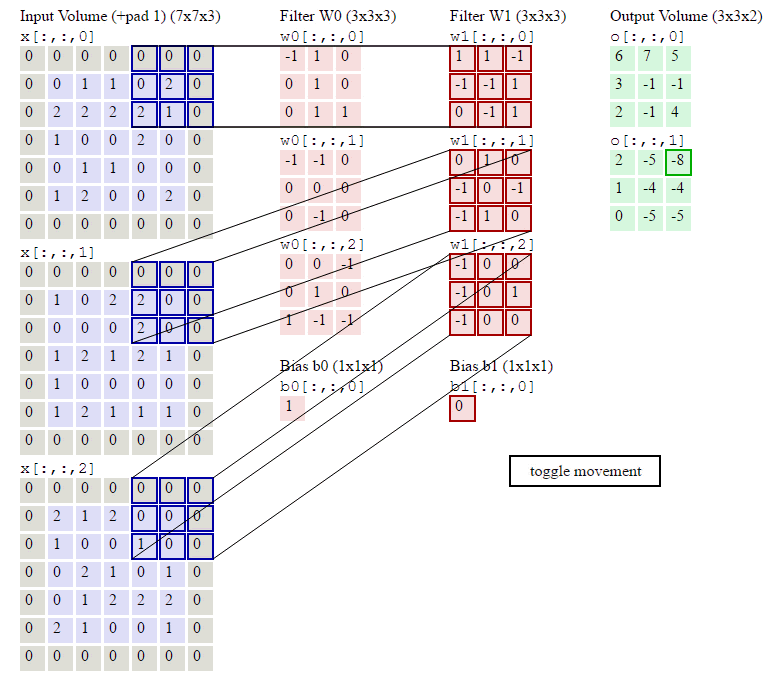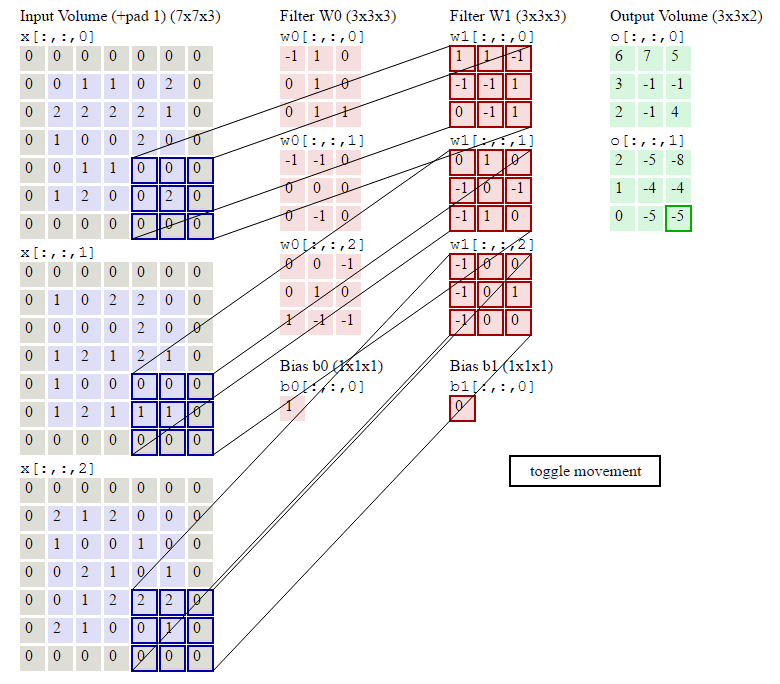
2 次元の畳み込み演算は、Pytorch では次の関数によって実装されます。
#二维卷积
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
#参数介绍:
#in_channels:输入的通道数
#out_channels:输出的通道数
#kernel_size:卷积核的大小
#stride:卷积核滑动的步长,默认是1
#padding:怎么填充输入图像,此参数的类型可以是int , tuple或str , optional 。默认padding=0,即不填充。
#dilation:设置膨胀率,即核内元素间距,默认是1。即如果kernel_size=3,dilation=1,那么卷积核大小就是3×3;如果kernel_size=3,dilation=2,那么卷积核大小为5×5
#groups:通过设置这个参数来决定分几组进行卷积,默认是1,即默认是普通卷积,此时卷积核通道数=输入通道数
#bias:是否添加偏差,默认true
#padding_mode:填充时,此参数决定用什么值来填充,默认是'zeros',即用0填充,可选参数有'zeros', 'reflect', 'replicate'或'circular'
入力サイズが、畳み込み後の出力サイズがであると仮定すると
、次のようになります。
1.2 畳み込み層の特徴
① 体重分担
同じパラメータのセットを使用して画像全体を走査し、テクスチャ特徴などの画像全体の共通の特徴情報を抽出します。画像のさまざまな側面に共通の特徴を持つ特徴情報を抽出するには、さまざまなコンボリューション カーネルが使用されます。演算後に得られる特徴マップは、抽出された画像の特徴を表します。重み共有は深層学習における重要なアイデアであり、ネットワーク パラメータを削減しながら良好なネットワーク容量を維持できます。畳み込みニューラル ネットワークは空間の重みを共有しますが、リカレント ニューラル ネットワークは時間の重みを共有します。
②ローカル接続
畳み込み層は完全接続層から発展し、各出力が重みを介してすべての入力に接続されます。視覚認識タスクでは、主要な画像の特徴、エッジ、コーナーなどは画像全体のごく一部のみを占め、画像内で遠く離れた 2 つのピクセルは相互に影響を与える可能性が低くなります。したがって、畳み込み層では、各出力ニューロンはチャネル的には完全に接続されたままですが、空間的にはその近傍の入力ニューロンの一部のみに接続されます。
1.3 一般的に使用される畳み込み演算
1) グループ畳み込み
グループ畳み込みと通常の畳み込みの違いは、通常の畳み込みはチャネル上の完全な接続を維持し、空間内の近傍にある少数の入力ニューロンにのみローカルに接続されるのに対し、グループ畳み込みはチャネルと空間の両方でローカル接続であることです。この場合、グループ畳み込みが通常の畳み込みに基づいてパラメータをさらに削減できることを見つけるのは難しくありませんが、その効果は通常の畳み込みよりも悪くなる可能性があります。以下の図に示すように、グループ畳み込みと通常の畳み込みの違いを直感的に観察できます。
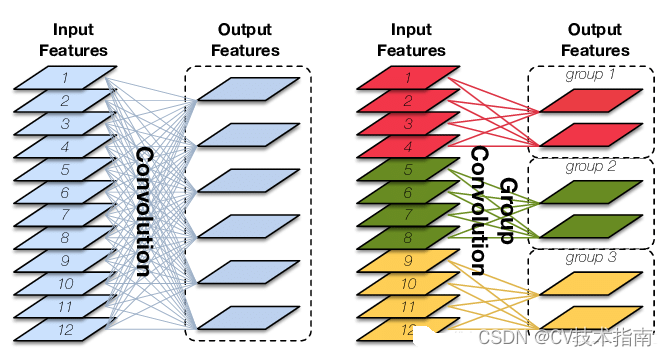
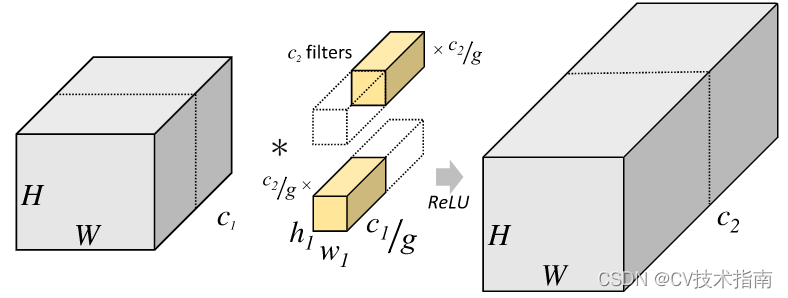
たとえば、入力形状が (1, 12, 24, 24)、コンボリューション カーネルの kernel_size が 3、出力チャネル数が 64 必要であるとします。通常のコンボリューションの場合、重みパラメータは 3×3×12×64=6912、グループ畳み込みを使用する場合、グループが 4 つであると仮定すると、重みパラメータの数は 3×3×3×16×4=1728、グループ畳み込みのパラメータ量は次のようになります。通常の畳み込みに削減され、製品パラメータ量の 4 分の 1 になります。グループ畳み込みのコード実装も非常に簡単で、torch.nn.Conv2d() 関数の groups パラメーターの値を変更し、それをいくつかのグループに変更するだけです。
2) 深さ分離可能な畳み込み
深さ方向の分離可能な畳み込みとは、畳み込みプロセスが深さ方向の畳み込みと点ごとの畳み込みに分割されることを意味します。Depthwise Convolution は、実際には、グループ = 入力チャンネルの数のグループ畳み込みです。これは、チャンネル上のピクセルの相互影響を完全に分離し、同じ空間位置にある異なるチャンネルの特徴情報を効果的に使用しないため、Pointwise Convolution が必要ですこれらの特徴マップはチャネル間で線形に結合されて、新しい特徴マップが生成されます。Depthwise Convolution と Pointwise Convolution の演算過程を下図に示します。
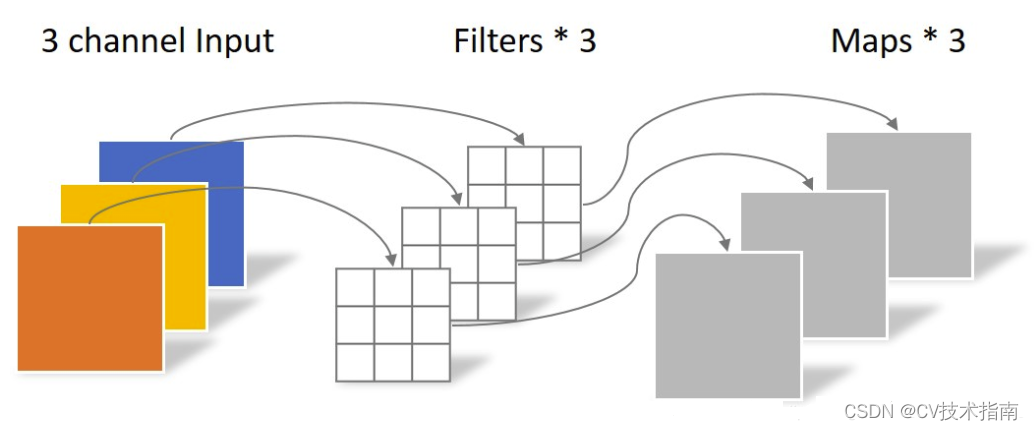
深さ方向の畳み込み
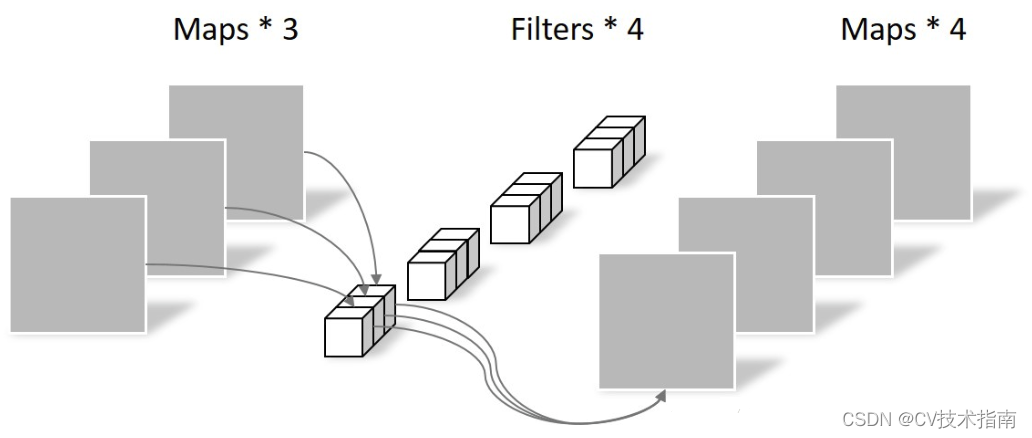
点ごとの畳み込み
注意すべき点の 1 つは、Depthwise Convolution が完了した後の特徴マップ チャネルの数は、入力層のチャネル数と同じであるということです。つまり、Depthwise Convolution ではチャネル数は変更されませんが、Pointwise Convolution ではチャネル数が変更されません。各ピクセルを異なるチャネルで線形結合するだけですが、チャネルの数を変更することもできます。
簡単に言うと、深さ分離可能な畳み込みは、コード実装時の入力チャネル数と同じグループ数を持つグループ畳み込みと 1×1 畳み込みを組み合わせたものと考えることができます。深さ分離可能な畳み込みは、通常の畳み込みと同様にチャネル上で完全な接続を実現し、空間内のローカル接続を実現するため、効果は良好であり、通常の畳み込みと同様の効果が得られます。画像ピクセルのインタラクションの特徴を利用しますが、深さ分離可能な畳み込みを使用すると、通常の畳み込みよりもパラメータの数が大幅に削減されます。たとえば、入力形状が (1, 12, 24, 24)、コンボリューション カーネルの kernel_size が 3、出力チャネル数が 64 必要であるとします。通常のコンボリューションの場合、重みパラメータは 3×3×12×64=6912 であり、深さ方向の分離可能な畳み込みが使用される場合、重みパラメータの数は 3×3×1×1×12+1×1×12×64=876 になります。
2. プーリング層
2.1 プーリングの役割
プーリング層の導入は、人間の視覚システムを模倣して次元を削減し、視覚入力オブジェクトを抽象化するもので、主に次の機能があります。
① 特徴の不変性: プーリング操作により、モデルは、特徴の位置やサイズなど、特徴が現れる形式に関係なく、画像内に特定の特徴が存在するかどうかにさらに注意を払うようになります。このうち、特徴不変性には主に翻訳不変性とスケール不変性が含まれます。変換不変性とは、出力から入力への変換が基本的に変更されないことを意味します。たとえば、入力が (4, 1, 3, 7, 2) の場合、最大プーリングには 7 がかかります。入力が左にシフトされた場合、 (1, 3, 7, 2, 0) を取得するために 1 ビットずつ移動しても、出力結果は 7 のままです。スケール不変性の場合、プーリング操作は画像のサイズ変更と同等です。通常、犬の画像は 2 倍になり、次のようになります。まだ認識している 犬の写真であるということは、犬の最も重要な特徴がこの画像に残っていることを意味します 画像内の写真が一目で犬であることがわかります 画像圧縮時に削除された情報は関係のない情報のみであり、残りの情報はスケール不変の特徴量であり、画像を最もよく表現できる特徴量となります。
②特徴の次元削減(ダウンサンプリング):画像には多くの情報が含まれており、多くの特徴があることはわかっていますが、一部の情報は画像タスクを実行するのにあまり役に立たなかったり、繰り返したりするため、この種の冗長情報を削除して、画像を抽出することができます。最も重要な機能は、プーリング操作の主要な役割でもあります。
③プーリング層はデータの空間サイズを継続的に削減していくため、パラメータ数や計算量も減少し、オーバーフィッティングもある程度抑制されます。
④ 非線形性を実現する(relu と同様)。
⑤受容野を広げる。
2.2 一般的に使用されるプーリング操作
1) 最大プーリング、平均プーリング、グローバル最大プーリング (GMP)、グローバル平均プーリング (GAP)
最大プーリング:イメージ内のプーリング カーネル領域の最大値を、領域のプール値として選択します。
平均プーリング:イメージ内のプールされたカーネル領域の平均値を、領域のプール値として計算します。
では、最大プーリングを使用するか平均プーリングを使用するかを決定する基準は何でしょうか? この質問に答える前に、画像から特徴を抽出するときにネットワークによって生成されるエラーは主に 2 つの側面から発生することを理解する必要があります。1近傍のサイズが限られているということは、領域のこの部分のデータ情報が十分に包括的ではないことを意味します。大きい; ②畳み込み層のパラメータの誤差により、推定値の偏差が増加します(誤差が偏差、分散、とノイズ、つまり誤差 = 偏差 + 分散 + ノイズ)。一般に、平均プーリングは最初のエラーを減らし、より多くの画像の背景情報を保持できますが、最大プーリングは 2 番目のエラーを減らし、より多くの画像のテクスチャ情報を保持できます。最大プーリングまたは平均プーリングの選択方法がまだ理解できない場合は、画像セグメンテーションで一般的に使用されるグローバル平均など、特徴マップ内のすべての情報がモデル予測結果に寄与する必要がある場合に平均プーリングを使用するという別の説明があります。グローバル コンテキストを取得するために使用されます。たとえば、画像分類タスクでは、最大プーリングの代わりに特徴マップの平均プーリングが実行されることがよくあります。これは、ディープ ネットワーク内の高レベルのセマンティック情報が分類器による一般的な情報の取得に役立つためです。分類; さらに、無駄な情報の影響を減らすために、 最大プーリング を使用します。たとえば、ネットワークの浅い層には画像にとって無駄な情報が多く含まれるため、ネットワークの浅い層では最大プーリングがよく見られます。要約すると、ネットワークの浅い層は通常最大プーリングを使用し、深い層は主に平均プーリングを使用します。
コード:
#1、最大池化
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
#参数解释
#kernel_size:池化核的大小
#stride:池化核滑动的步长,默认大小是kernel_size
#padding:在输入图像的两边进行填充,默认是0,即不填充,另外填充值默认是0
#dilation:设置核的膨胀率,默认 dilation=1,如果kernel_size =3,那么核的大小就是3×3。如果 dilation = 2,kernel_size =3×3,那么每列数据与每列数据,每行数据与每行数据中间都再加一行或列数据,数据都用0填充,那么核的大小就变成5×5。
#return_indices:这个参数用来控制要不要返回最大值的索引位置,如果为true那么要记住最大池化后最大值的所在索引位置,后面上采样可能要用上,为false则不用记住位置。
#ceil_mode:它决定的是在计算输出结果形状的时候,是使用向上取整还是向下取整。#2、平均池化
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)
#参数讲解,与最大池化相同的参数代表的意思一样
#count_include_pad:为True时表示平均计算时零填充也包含在内
#divisor_override:如果指定,它将用作除数,否则将使用池化区域的大小#3、全局最大池化
torch.nn.AdaptiveMaxPool2d(output_size, return_indices=False)
#这个函数用来自适应最大池化
#output_size:决定将输入图像分几个区域池化,如果output_size=1,就代表全局最大池化#全局平均池化
torch.nn.AdaptiveAvgPool2d(output_size)
#这个函数代表自适应平均池化
#output_size:决定输入图像分几个区域进行平均池化,output_size=1,就代表全局平均池化2) オーバーラッププーリング
つまり、隣接するプーリング ウィンドウの間に重なり合う領域が存在します。kernel_size > stride
3) 空間ピラミッドプーリング (SPP)
これにより、プーリングが複数のスケールのプーリングに変わります。異なるサイズのプーリング ウィンドウを使用して、上位層の機能マップに作用します。以下の図に示すように、入力特徴マップは異なるウィンドウ サイズで 3 回プールされ、完全接続層に送信されます。
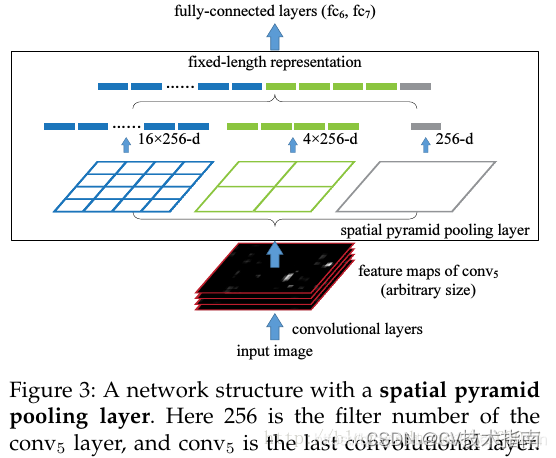
このような構造設計により、完全に接続された層を備えた畳み込みネットワークでも、さまざまなサイズの画像を確実に処理できるようになります。完全に接続されたレイヤーが異なるサイズの画像を処理できないのはなぜですか? これは、全結合層の両側のニューロンの数は固定する必要があり、異なるサイズの入力画像ではニューロンの数も異なる必要があるためです。そのコードは、前述の適応最大プーリングまたは適応平均プーリングを使用して実装できます。ASPP、ROI プーリングなど、多くの同様の構造が SPP から開発されていますが、ここではリストされません。
3. 非線形層
3.1 活性化関数の役割
活性化関数の導入により、ニューラル ネットワークに非線形機能をもたらすことができます。これは非常に重要です。なぜなら、世界中のほとんどのデータは非線形であり、線形ネットワークは画像や音声などの非線形データを学習してシミュレートできないからです。さらに、ニューラル ネットワークに非線形層が導入されない場合、ニューラル ネットワークは線形層の単純なスタックになり、多層線形ネットワークの単純なスタックは本質的に線形関数で表現できるため、深さが大きくなります。ニューラルネットワークの本来の意味が失われます。最後に、アクティベーション関数はデータを非線形空間から線形空間にマッピングすることもできるため、データをより適切に分類できます。
3.2 一般的に使用されるアクティベーション関数
1) シグモイド活性化関数
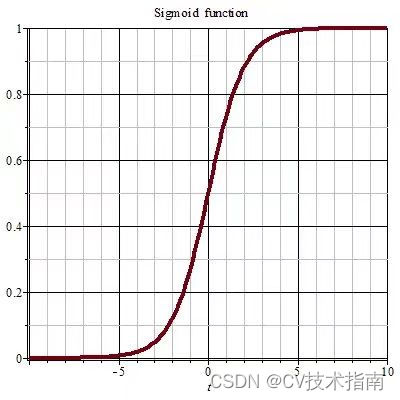
シグモイド関数は値の範囲を (0,1) に圧縮します。これは確率分布の特性にちょうど適合し、確率予測の出力層で使用できます。利点は連続的でどこにでも誘導できることですが、欠点は関数値が0と1に近い場合、関数の傾きが小さく傾きが消失しやすく、関数の出力値が小さくなってしまうことです。関数は常に正であり、0 を中心としないため、重みが一方向にのみ更新されるため、収束率に影響します。
2) Tanh活性化関数
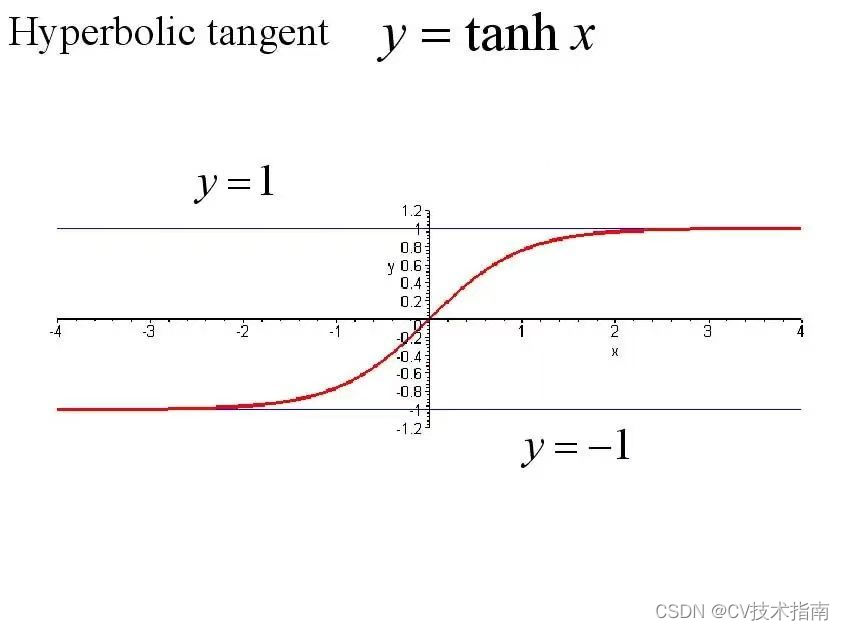
Tanhx 活性化関数は、ハイパボリック タンジェント活性化関数とも呼ばれます。この関数は、値の範囲を (-1,1) に圧縮します。その利点は、出力値が 0 を中心とすることです。これにより、シグモイド関数の重みが問題になる問題が解決されます。問題点、欠点は、一方向にしか更新できないことと、勾配が消失してしまうことと、計算量が膨大であることです。
3) ReLU活性化機能
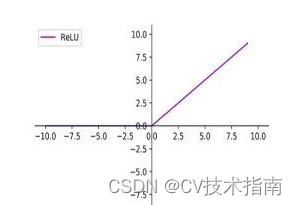
ReLU 活性化関数は、修正線形単位または線形整流関数とも呼ばれ、ニューラル ネットワークで非常に一般的に使用される活性化関数です。ReLU の利点は、スパース性、計算量が少なく、収束速度が速く、領域内の勾配消失がないことですが、欠点は、出力が 0 を中心とせず、
この部分のニューロンの重みが更新されないことです。
4) Leaky ReLU 活性化関数
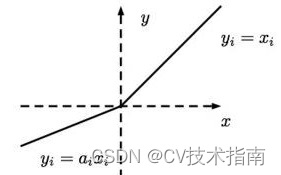
この活性化関数は、ReLU 活性化関数のこの部分のニューロンの重みが更新されない という問題を解決します。
問題。