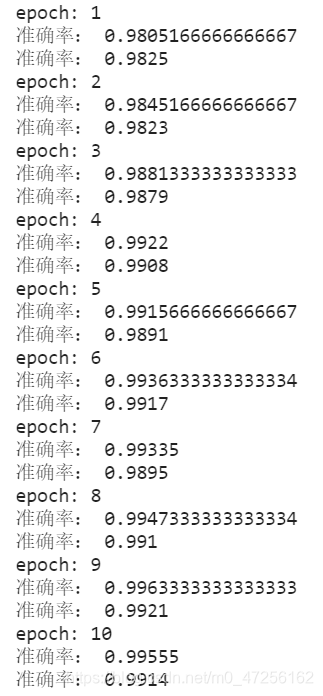
# 该维度表示64张图片,每张的channel为1,宽高为28,28for i, data inenumerate(train_loader):
inputs, labels = data
print(inputs.shape)print(labels.shape)break
5.✌畳み込みネットワーク層を定義します
# nn.ModuleclassCNN(nn.Module):# 初始化相关网络层def__init__(self):# 初始化父类super(CNN,self).__init__()# 定义第一个卷积层
self.conv1=nn.Sequential(nn.Conv2d(1,64,5,1,2),nn.ReLU(),nn.MaxPool2d(2,2))# 定义第二个卷积层
self.conv2=nn.Sequential(nn.Conv2d(64,128,5,1,2),nn.ReLU(),nn.MaxPool2d(2,2))# 定义全连接层
self.fc1=nn.Sequential(nn.Linear(128*7*7,1000),nn.Dropout(p=0.2),nn.ReLU())
self.fc2=nn.Sequential(nn.Linear(1000,10),nn.Softmax(dim=1))# 定义传播函数defforward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.reshape(x.shape[0],-1)
x = self.fc1(x)
x = self.fc2(x)return x