「Practice Deep Learning pytorch」の学習ノートの一部は、ご自身のレビューのみを目的としています。
畳み込みニューラルネットワーク(LENET)
ゼロからの多層パーセプトロンの実現:Fashion-MNISTデータセット内の画像を分類するために、単一の隠れ層を持つ多層パーセプトロンモデルを構築しました。各画像は高さと幅が28ピクセルです。画像のピクセルを1つずつ拡張して、次数784のベクトルを取得し、完全に接続されたレイヤーに入力します。ただし、この分類方法には特定の制限があります。
1.同じ列に隣接する画像のピクセルは、この方向に大きく離れている場合があります。それらが構成するパターンは、モデルでは認識しにくい場合があります。
2.大規模な入力画像の場合、完全に接続されたレイヤーの容量を使用すると、モデルが大きくなりすぎます。入力が、高さと幅が1000ピクセルのカラー写真(3チャネルを含む)であるとします。完全に接続されたレイヤーの出力数が256であっても、このレイヤーの重みパラメーターの形状は3000000×256であり、約3 GBのメモリまたはビデオメモリを占有します。これにより、モデルが複雑になり、ストレージのオーバーヘッドが過剰になります。
畳み込み層はこれら2つの問題を解決しようとします。
- 一方、畳み込み層は入力形状を保持するため、高さ方向と幅方向の両方の画像ピクセルの相関を効果的に認識できます。
- 一方、畳み込み層は、スライディングウィンドウを介して同じ畳み込みカーネルと同じ位置の入力を再計算するため、パラメーターのサイズが大きくなりすぎないようにします。
畳み込みニューラルネットワークは、畳み込み層を持つネットワークです。このセクションでは、手書きのデジタル画像を認識するために使用される初期の畳み込みニューラルネットワーク、LeNetを紹介します。名前は、LeNetの最初の著者Yann LeCunに由来しています。LeNetは、勾配降下法による畳み込みニューラルネットワークのトレーニングが、当時の手書き数字認識の最も高度な結果を達成できることを示しました。この基礎研究は、畳み込みニューラルネットワークが舞台に登場するのは初めてであり、世界に知られています。LeNetのネットワーク構造を次の図に示します。
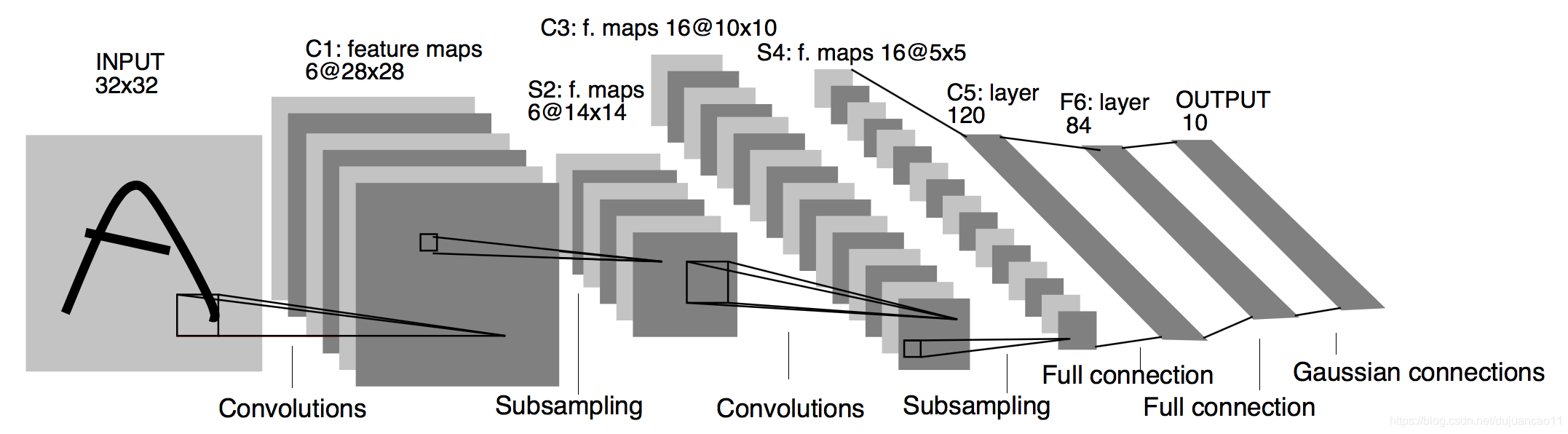
LENETモデル
LeNetは、たたみ込み層ブロックと完全に接続された層ブロックの2つの部分に分かれています。
たたみ込み層ブロックの基本単位は、たたみ込み層に続いて最大プーリング層です。
たたみ込み層は、ラインやオブジェクトパーツなどの画像の空間パターンを認識するために使用され、その後の最大プーリング層は、位置に対するたたみ込み層の感度を下げるために使用されます。たたみ込み層ブロックは、このような2つの基本ユニットが繰り返し積み重なって構成されています。たたみ込み層ブロックでは、各たたみ込み層は5x5ウィンドウを使用し、出力でシグモイド活性化関数を使用します。1番目の畳み込み層の出力チャネルの数は6で、2番目の畳み込み層の出力チャネルの数は16に増えます。これは、2番目の畳み込み層の入力の高さと幅が最初の畳み込み層のそれよりも小さいため、出力チャネルを増やすと2つの畳み込み層のパラメーターサイズが類似するためです。畳み込み層ブロックの最大の2つのプーリング層のウィンドウ形状は2×2で、ストライドは2です。プーリングウィンドウはストライドと同じ形状であるため、入力上のプーリングウィンドウの各スライドによってカバーされる領域は互いに重なりません。
たたみ込み層ブロックの出力形状は(バッチサイズ、チャネル、高さ、幅)です。たたみ込み層ブロックの出力が完全に接続された層ブロックに渡されると、完全に接続された層ブロックは小さなバッチの各サンプルを平坦化します。つまり、完全に接続されたレイヤーの入力形状は2次元になり、最初の次元はミニバッチのサンプルで、2番目の次元は各サンプルが平坦化された後のベクトル表現であり、方向はチャネルと高さです。そしてワイドの商品。完全に接続されたレイヤーブロックには、3つの完全に接続されたレイヤーが含まれています。それらの出力数はそれぞれ120、84、10です。10は出力カテゴリの数です。
LeNetモデルは、以下のSequentialクラスによって実装されます。
import time
import torch
from torch import nn, optim
import sys
sys.path.append("..")
import d2lzh_pytorch as d2l
device = torch.device('cuda' if torch.cuda.is_available() else
'cpu')
class LeNet(nn.Module):
def __init__(self):
# 初始化
super(LeNet, self).__init__()
# 卷积层 in_channels, out_channels,kernel_size
self.conv = nn.Sequential(nn.Conv2d(1, 6, 5),
nn.Sigmoid(),
# kernel_size, stride
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5),
nn.Sigmoid(),
nn.MaxPool2d(2, 2)
)
# 全连接层
self.fc = nn.Sequential(
nn.Linear(16*4*4, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
# 前向传播
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output各レイヤーの形状を確認してください。
net = LeNet()
print(net)出力:
LeNet((conv):Sequential(
(0):Conv2d(1、6、kernel_size =(5、5)、stride =(1、1))
(1
):Sigmoid()(2):MaxPool2d(kernel_size = 2 、ストライド= 2、パディング= 0、膨張= 1、
ceil_mode = False)
(3):Conv2d(6、16、kernel_size =(5、5)、stride =(1、1))
(4):Sigmoid()
(5):MaxPool2d(kernel_size = 2、stride = 2、padding = 0、dilation = 1、
ceil_mode = False)
)
(fc):Sequential(
(0):Linear(in_features = 256、out_features = 120、bias = True) )
(1):Sigmoid()
(2):Linear(in_features = 120、out_features = 84、bias = True)
(3):Sigmoid()
(4):Linear(in_features = 84、out_features = 10、bias = True )))
たたみ込み層ブロックの入力の高さと幅が層ごとに減少していることがわかります。たたみ込み層は高さと幅が5のたたみ込みカーネルを使用するため、高さと幅はそれぞれ4ずつ減りますが、プーリング層は高さと幅を半分にしますが、チャネル数は1から16に増えます。完全に接続されたレイヤーは、画像カテゴリの数が10になるまで、レイヤーごとに出力数を減らします。
データを取得してモデルをトレーニングする
実験的なLeNetモデル。実験では、トレーニングデータセットとして引き続きFashion-MNISTを使用します。
batch_size = 256
# 载入输数据集
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)ので、畳み込みニューラルネットワーク計算は、多層パーセプトロンよりも複雑です、それを使用することが推奨されるGPUを計算を加速します。したがって、GPUコンピューティングをサポートするために、ゼロからのソフトマックス回帰の実装で説明されているevaluate_accuracy関数を少し変更します。
# 本函数已保存在d2lzh_pytorch包中方便以后使用。
def evaluate_accuracy(data_iter, net, device=None):
if device is None and isinstance(net, torch.nn.Module):
# 如果没指定device就使用net的device
device = list(net.parameters())[0].device
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X.to(device)).argmax(dim=1) == y.to(device)).float().sum().cpu().item()
net.train() # 改回训练模式
else: # 自定义的模型, 不考虑GPU
if('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n定義されたtrain_ch3関数を少し変更して、計算に使用されるデータとモデルが同じメモリまたはビデオメモリにあることを確認します。
# 本函数已保存在d2lzh_pytorch包中方便以后使用
def train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs):
net = net.to(device)
print("training on ", device)
# 交叉熵损失函数
loss = torch.nn.CrossEntropyLoss()
batch_count = 0
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_l_sum += l.cpu().item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().cpu().item()
n += y.shape[0]
batch_count += 1
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f, time %.1f sec'
% (epoch + 1, train_l_sum / batch_count, train_acc_sum / n, test_acc, time.time() - start))
# 学习率采⽤0.001
lr, num_epochs = 0.001, 5
# 训练算法使用Adam算法
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch5(net, train_iter, test_iter, batch_size, optimizer, device,num_epochs)出力:
cuda
epoch 1でのトレーニング、損失0.0072、train acc 0.322、test acc 0.584、time 3.7 sec
epoch 2、loss 0.0037、train acc 0.649、test acc 0.699、time 1.8 sec
epoch 3、loss 0.0030、train acc 0.718、test acc 0.724 、時間1.7秒
エポック4、損失0.0027、トレインacc 0.741、テストacc 0.746、時間1.6秒
エポック5、ロス0.0024、トレインacc 0.759、テストacc 0.759、時間1.7秒
概要
- 畳み込みニューラルネットワークは、畳み込み層を持つネットワークです。
- LeNetは、畳み込み層と最大プーリング層を交互に使用し、続いて完全に接続された層を画像分類に使用します。