記事ディレクトリ
Numpy 配列処理ライブラリ
numpy ライブラリをインポートし、np というエイリアスを付けます。
import numpy as np
numpy ライブラリで提供されるものを確認する
dir(np)或help(np)
jupyerの機能の補足説明
関数の上にカーソルを置き、押すとshift+tab関数の説明が呼び出されます。

numpyのrandom関数を使って配列をランダムに生成する
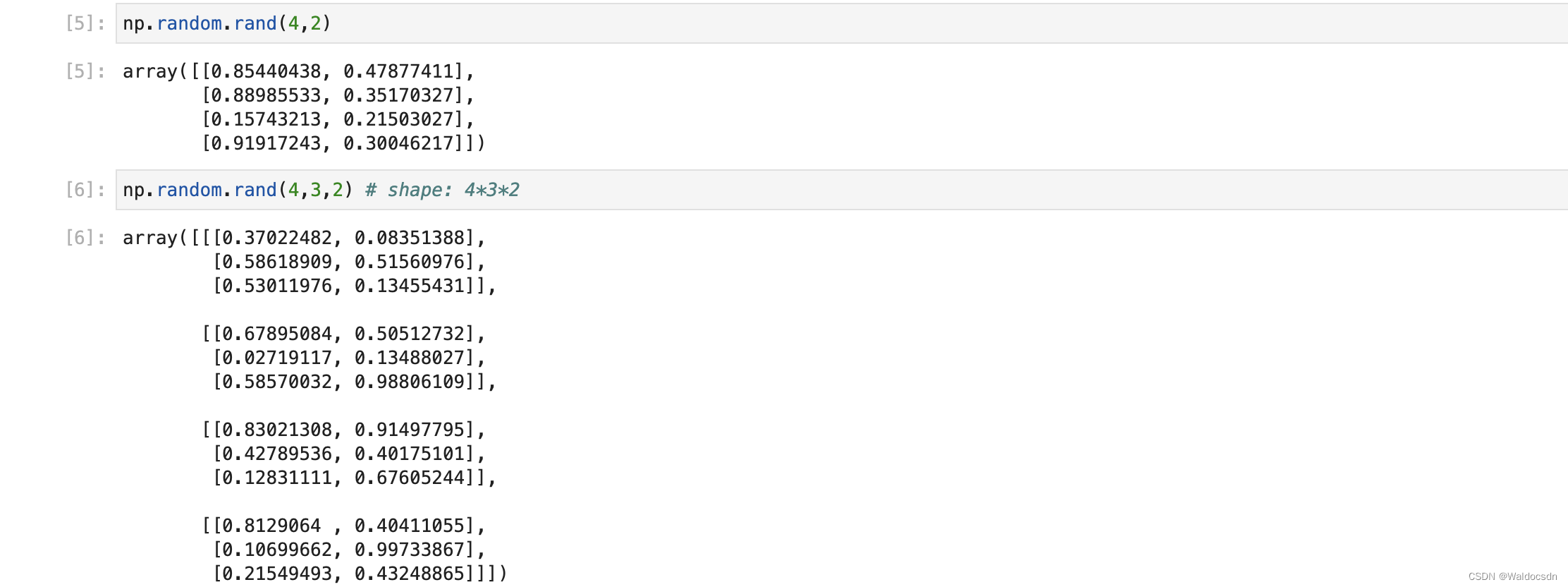
numpy.random.rand()
numpy.random.rand(d0,d1,…,dn)
- rand 関数は、指定された次元に従って、0 を含み 1 を除く [0,1) の間のデータを生成します。
- dnは寸法を示します
- 戻り値は指定された次元の配列です
例:
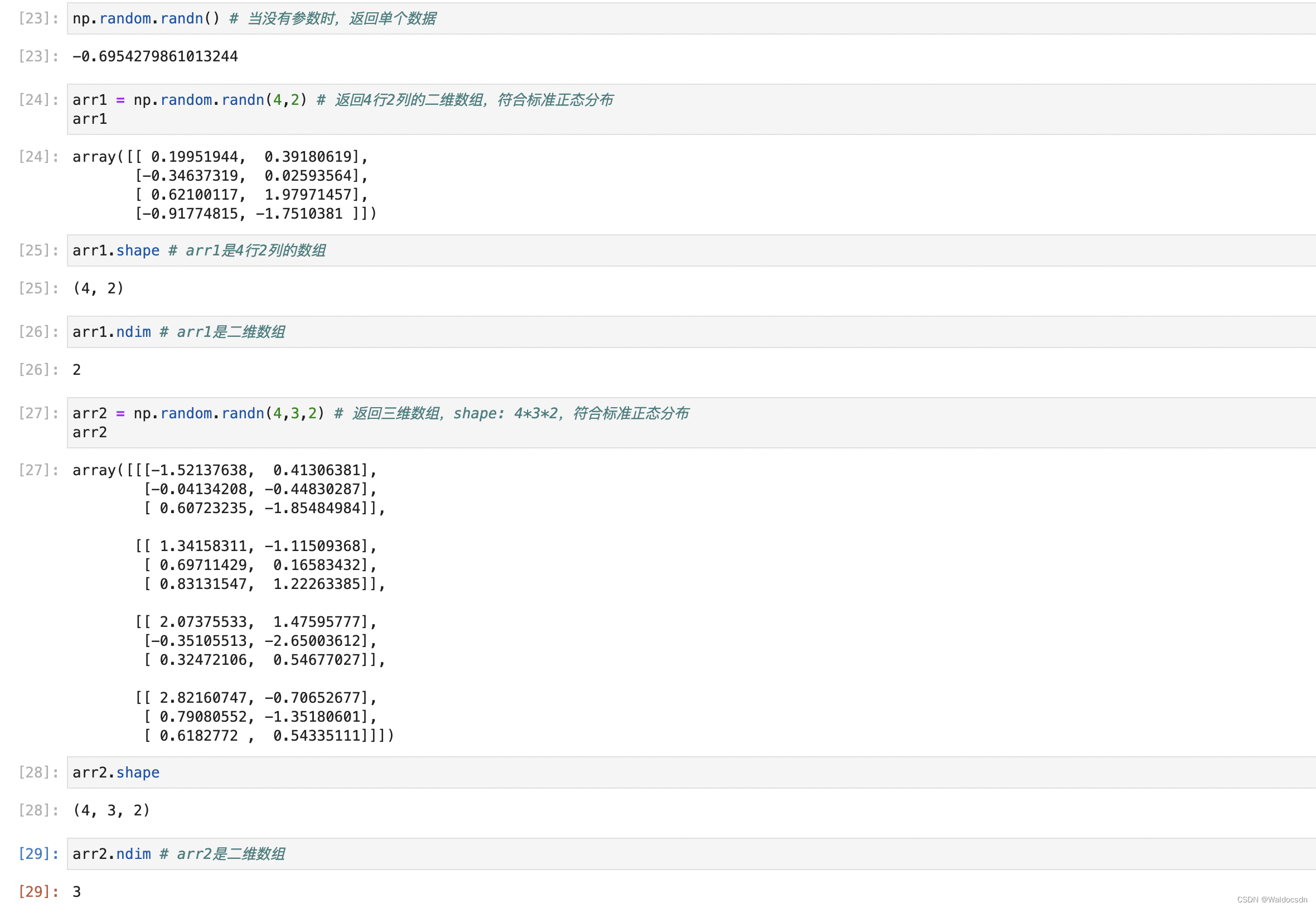
numpy.random.randn() - 重要
numpy.random.randn(d0,d1,…,dn)
-
randn 関数は、標準正規分布を使用してサンプルまたはサンプルのセットを返します。
-
dnは寸法を示します
-
戻り値は指定された次元の配列です
-
.shape結果の配列の構造は、次のようにして確認できます。 -
.ndim配列の次元を見ることによって(「軸」の数としても理解できます) -
.size配列に含まれる要素の数を見ると
-
.argmax: 指定された軸の最大値のインデックス (添え字) を返します。二次元配列では、パラメータ「0」が列を表し、パラメータ「1」が行を表します。

なぜそれが使用されるかを説明した後.argmax(axis=0)、出力 array([1, 1, 0]) ? は
.argmax最大値を返します。指定された軸の索引(下标)。fetch二维数组中,参数“0”代表列,参数“1”代表行。
を使用します。生成された 3 行 3 列の配列 arr3 の最初の列は、0.78650488、1.30572907、-0.49828544 で、このうち 1.30572907 が最大で、そのインデックスは 1 です。生成された 3 行 3 列の配列 arr3 の 2 列目は、0.38190384、1.60970205、-2.00096618 で、このうち 1.60970205 が最大で、インデックスは 1 です。生成された 3 行 3 列の配列 arr3 の 3 列目は、1.145984、-0.2094228、-0.85838297 で、このうち 1.145984 が最大で、インデックスは 0 です。.argmax(0)列的最大值的索引
同様に、.argmax(axis=1)fetch を使用します行的最大值的索引。

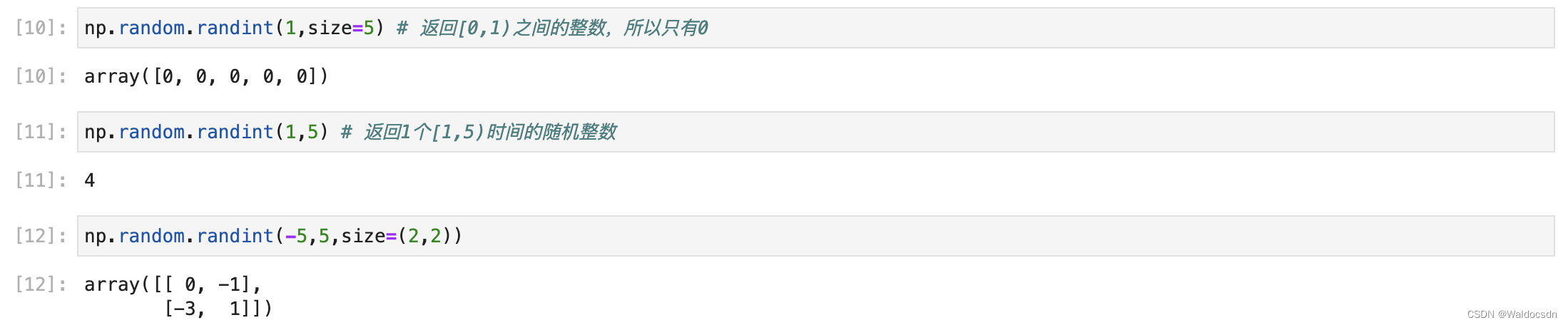
numpy.random.randint()
numpy.random.randint(low, high=None, size=None, dtype=numpy.int32)
- ランダムな整数を返します。範囲は [low, high) (low を含み、high を除く) です。
- パラメータ: low は最小値、high は最大値、size は配列次元のサイズ、dtype はデータ型、デフォルトのデータ型は np.int です。
- 高を入力しない場合、デフォルトの乱数生成範囲は[0、低)です。
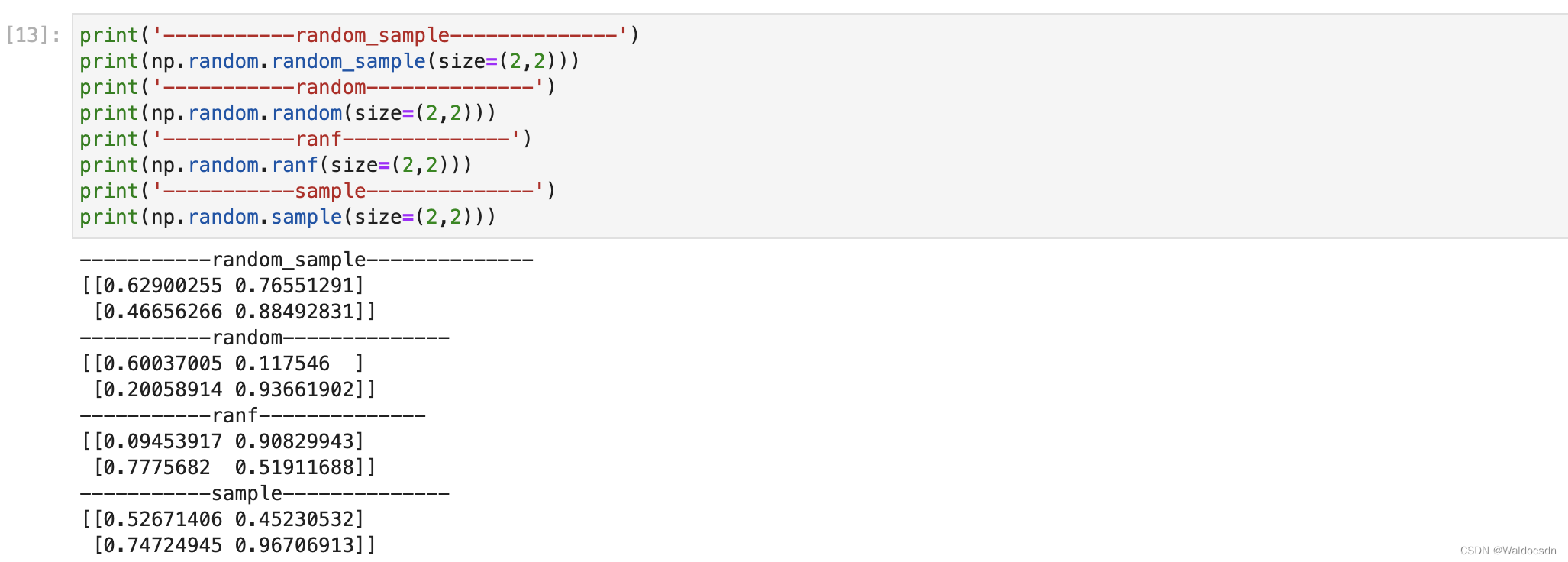
[0,1) の間の浮動小数点数を生成します。
- numpy.random.random_sample(size=なし)
- numpy.random.random(size=なし)
- numpy.random.ranf(size=なし)
- numpy.random.sample(size=なし)
numpy.random.choice()
numpy.random.choice(a, size=None, replace=True, p=None)
- 指定された 1D 配列から乱数を生成します
- パラメータ: a はデータまたは整数に似た 1 次元配列、size は配列の次元、p は配列内のデータが出現する確率です。
- a が整数の場合、対応する 1 次元配列は np.arange(a) です。

- パラメータ p の長さはパラメータ a の長さと一致する必要があります。
- パラメータ p は確率であり、p のデータの合計は 1 になる必要があります。

numpy.random.seed()
- np.random.seed() の役割: ランダム データを予測可能にします。
- 同じシードを設定すると、毎回生成される乱数は同じになります。シードが設定されていない場合は、毎回異なる乱数が生成されます。

numpy.zeros()
すべて 0 の配列を生成するために使用され、変数の型は dtype パラメータで指定できます。
例: 3 行 4 列のすべて 0 の配列を生成し、型は float32 です。

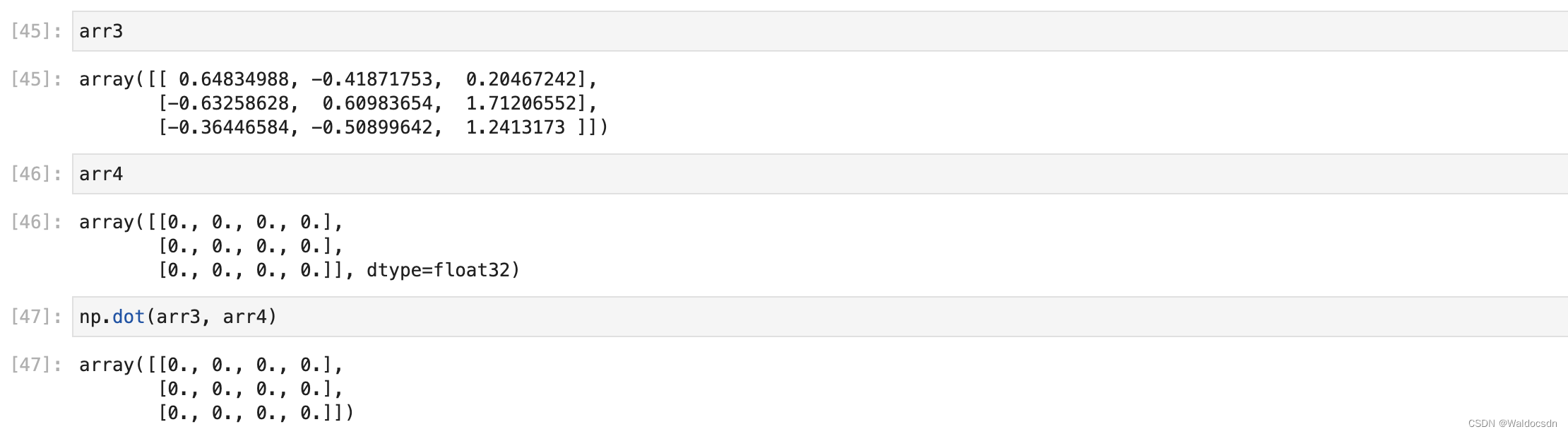
配列乗算 numpy.dot()
numpy.arange() - 重要
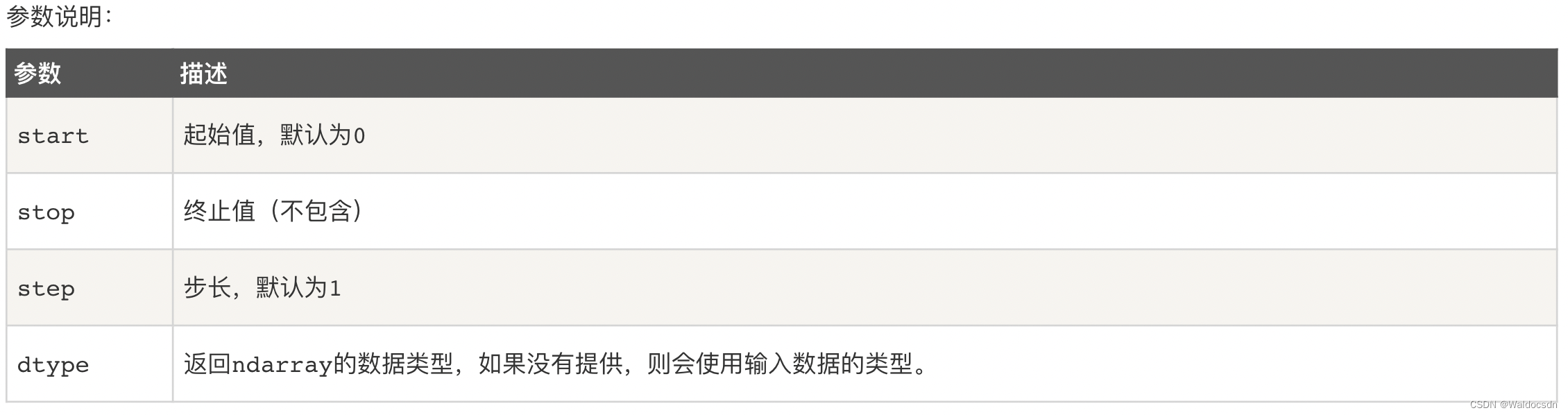
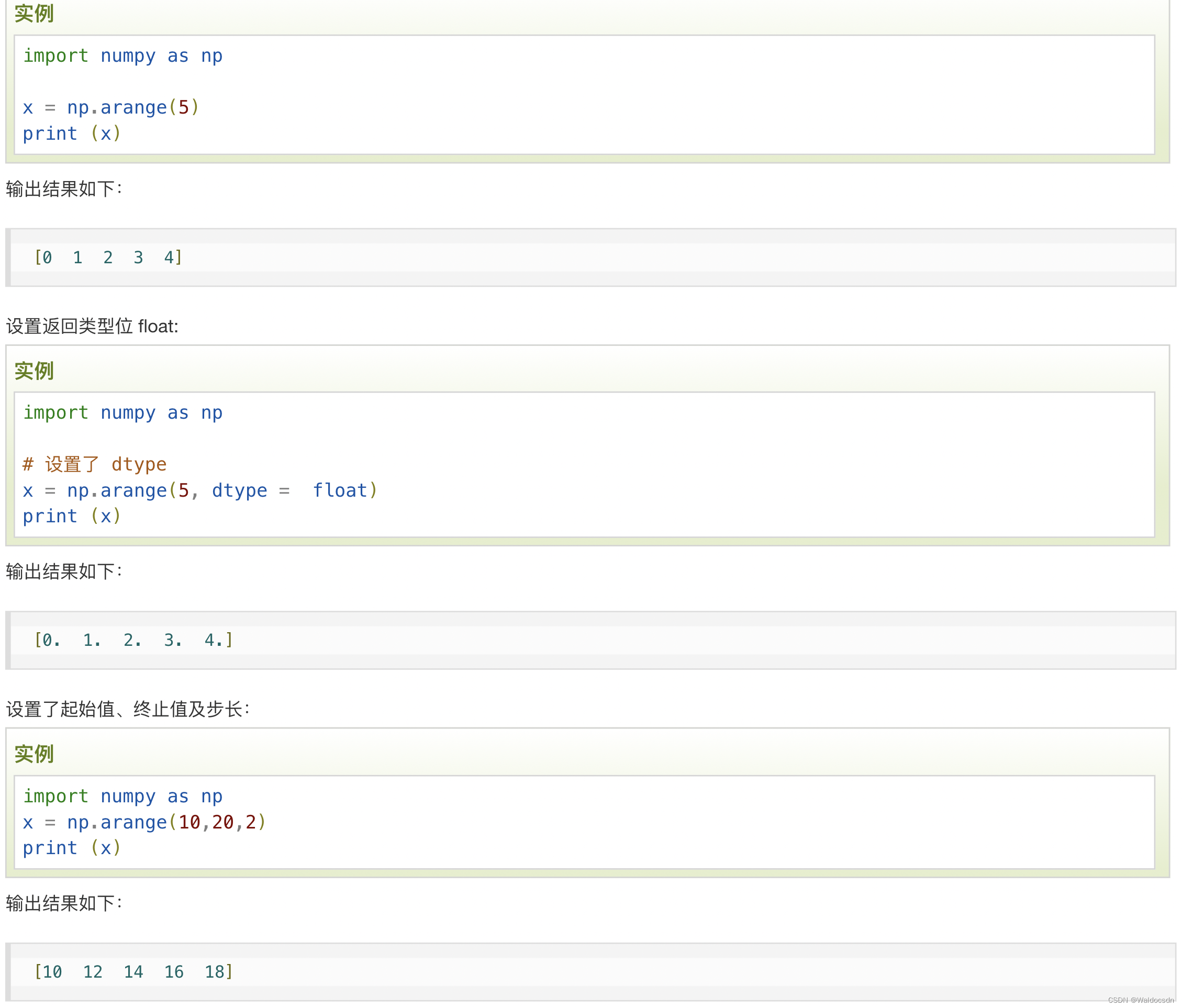
numpy ライブラリの arange 関数を使用して、値の範囲を作成し、ndarray (n 次元配列、n 次元配列) オブジェクトを返します。関数の形式は次のとおりです。
numpy.arange(開始、停止、ステップ、dtype)
startとstopで指定した範囲とstepで設定したステップサイズに従ってndarrayを生成します。
アレイブロードキャスト
配列を 10 倍すると、配列内のすべての数値が 10 倍になります。
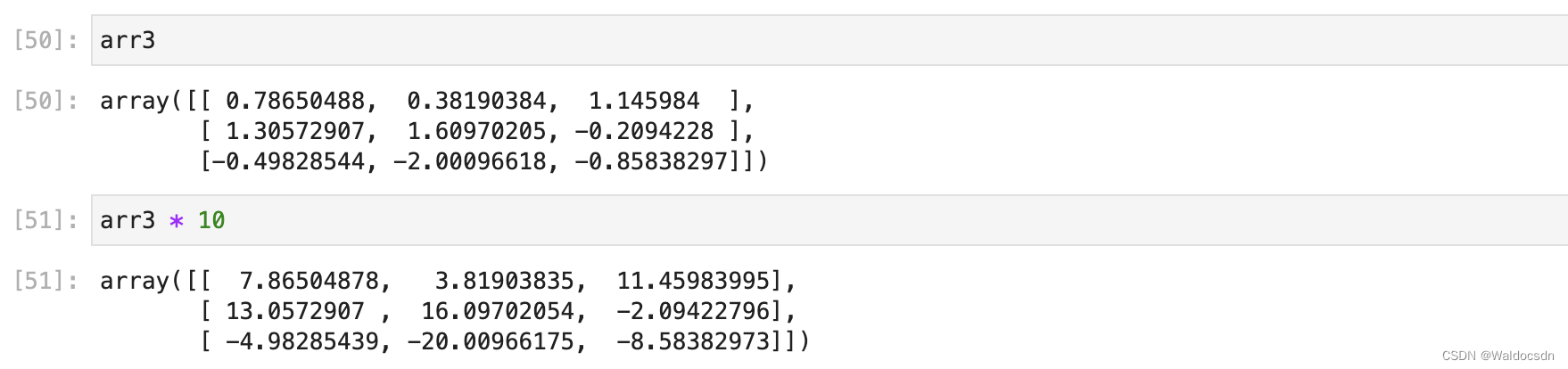
配列に数値を追加します。各要素はこの数値を追加します。
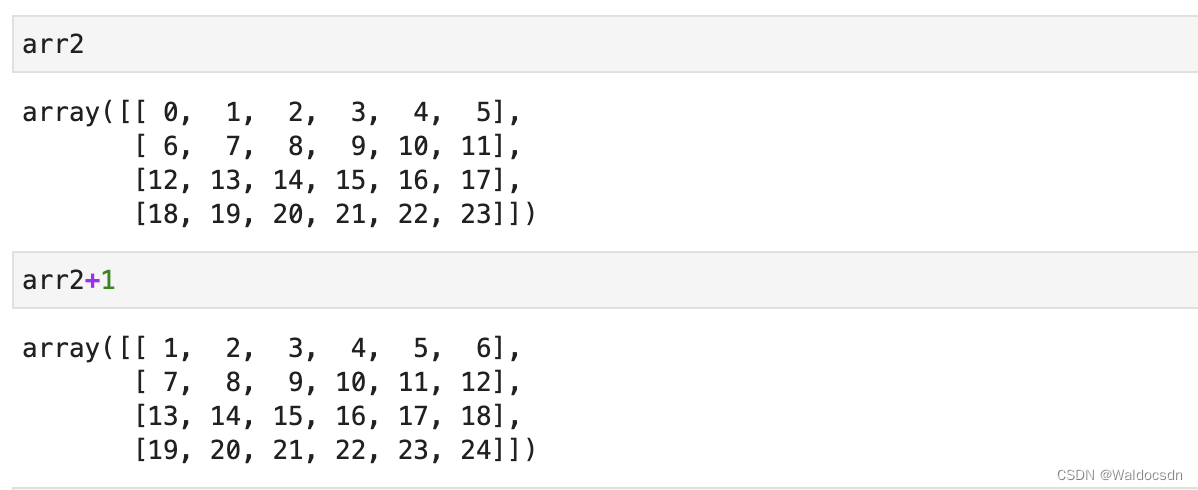
arr2 が 4 行 6 列の配列、arr3 が 1 行 6 列の行列の場合、arr2 + arr3 は、arr2 の各行と arr3 の対応する要素を加算したものになります。
アレイ型の特徴
- 独自の形状(シェイプ)を持っています
- dtype=numpy.int32; dtype=numpy.float32 などのデータ型 (dtype) があります。
- 配列内の要素の値を変更できます
配列の形状を変更する numpy.reshape() - 非常に重要
- 準備作業として、まず配列オブジェクトを生成します。
arr5 = np.arange(0, 24, dtype=np.int32)
arr5

- 配列を 3 行 8 列の配列に変換します。
arr5.reshape(3, 8)

- 配列を 4 行 6 列の配列に変換します。
arr5.reshape(4, 6)

-
インデックス付けによって形状が変更された配列の最初の要素を見つけます (リストのインデックス付けとの違いに注意してください。配列のインデックス付けは少し単純で、括弧が少ないことに注意してください)。

-
補足リストのインデックス付き要素:

-
配列内の要素を変更します。
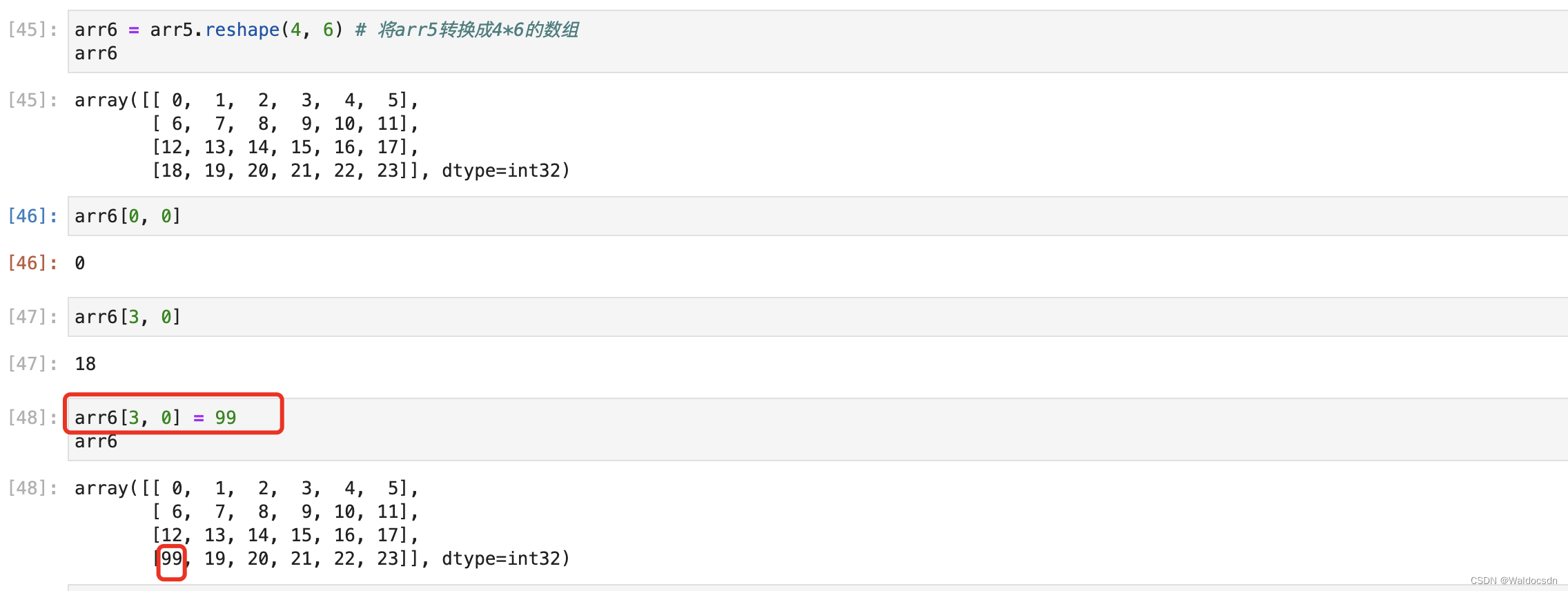
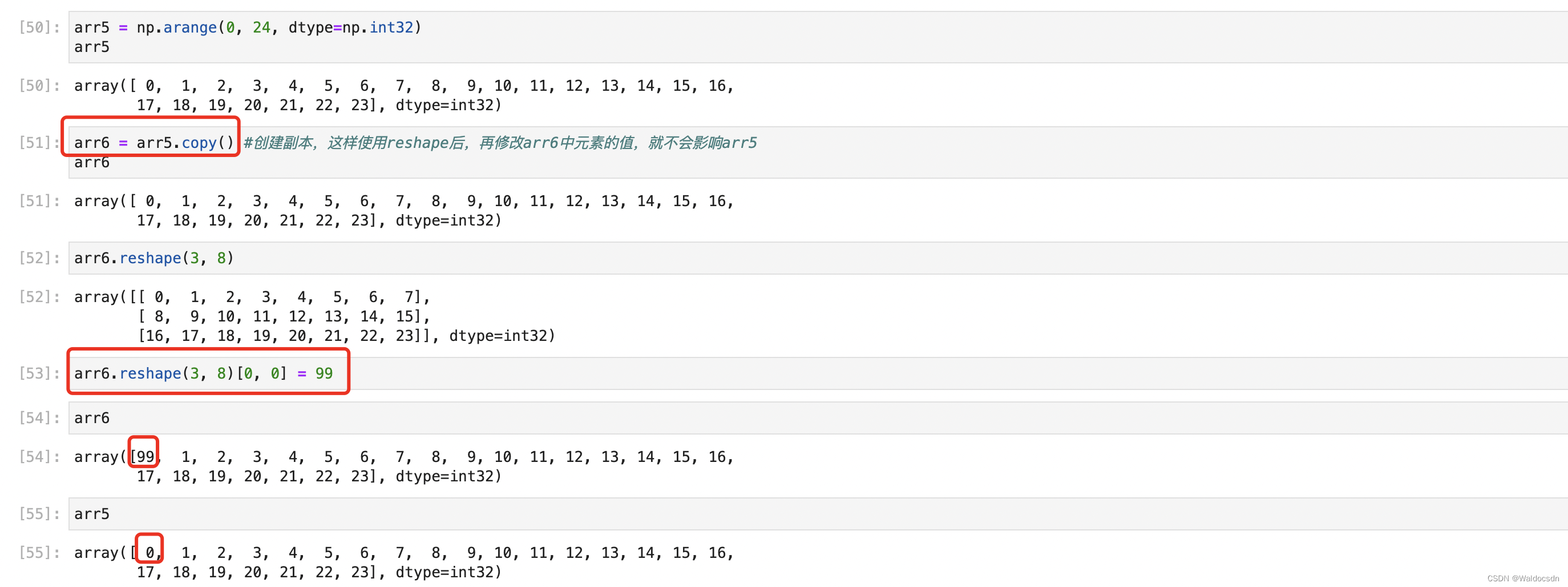
注意,使用reshape函数时,不会创建副本。例如,这里修改了arr6的元素,但是也修改了arr5的元素,arr5和arr6指向同一个元素,没有创建副本,如下图:

使用copy函数,创建副本
arr6 = arr5.copy()
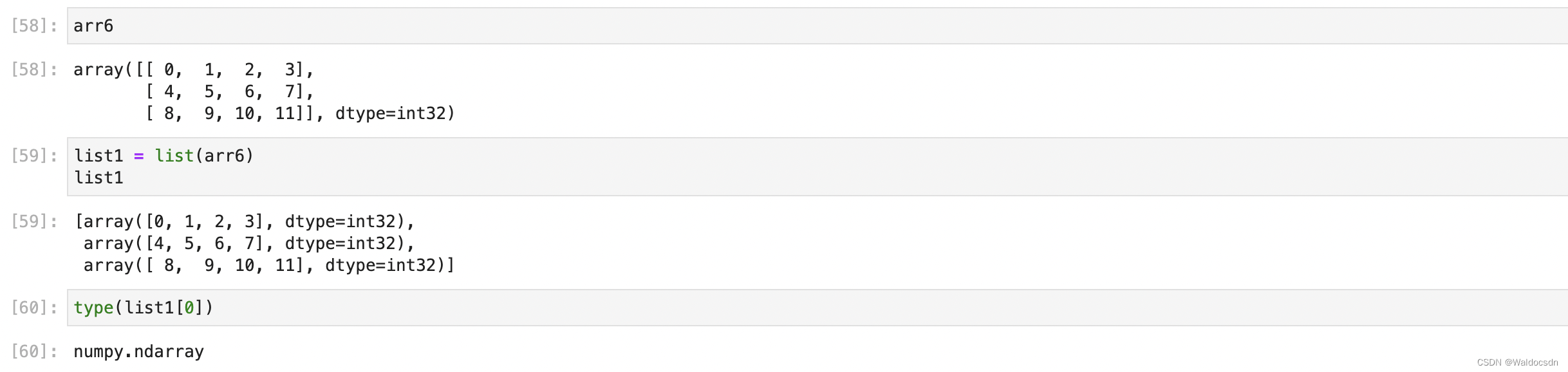
list() 関数を使用して、配列を強制的にリストに変換します。
関数 list() を使用して、3 行 4 列の配列を強制的にリストに変換します。この場合、各要素は配列型のままです。
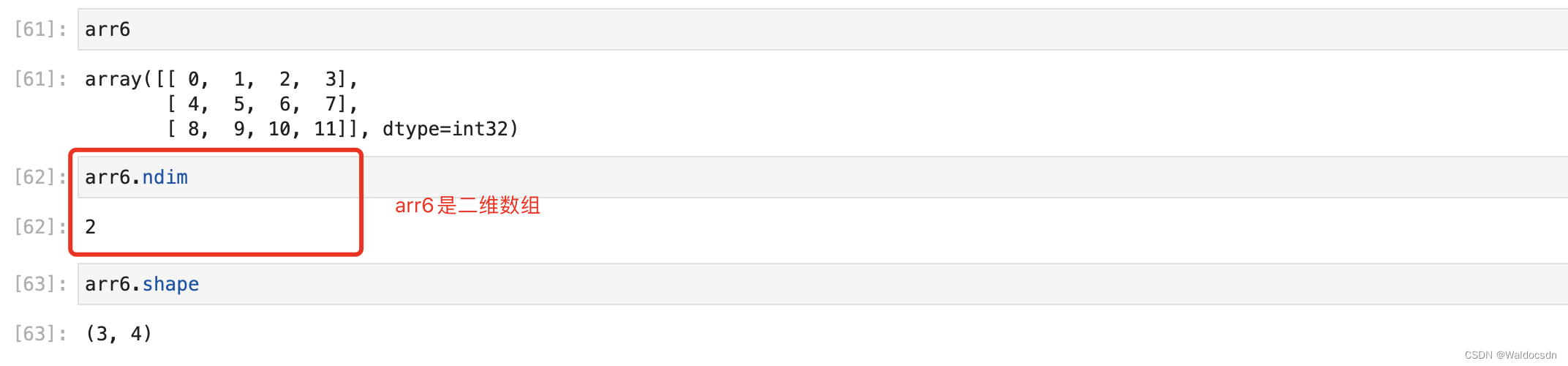
.ndim を使用して配列の次元を表示する
配列内の軸の数としても理解できます。
例: arr6 は 3 行 4 列の配列です。
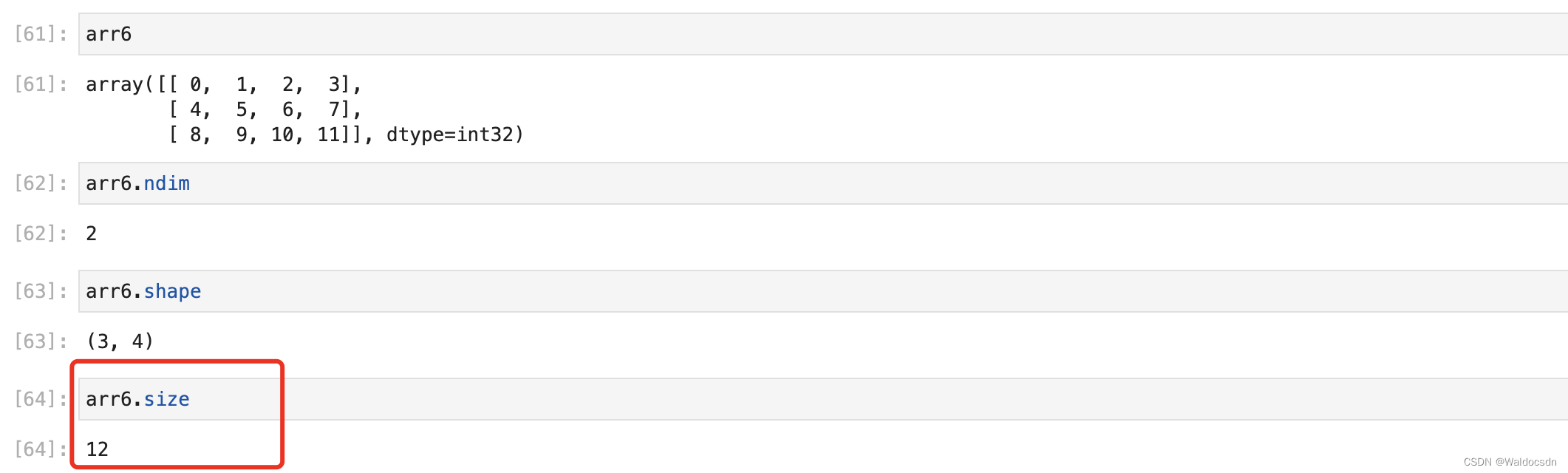
.size を使用して配列内の要素の数を表示します
型変換(強調)
numpy.array() を使用してリストを配列に変換します
type() 関数と dtype 属性の使用を含むコメントに注意してください。
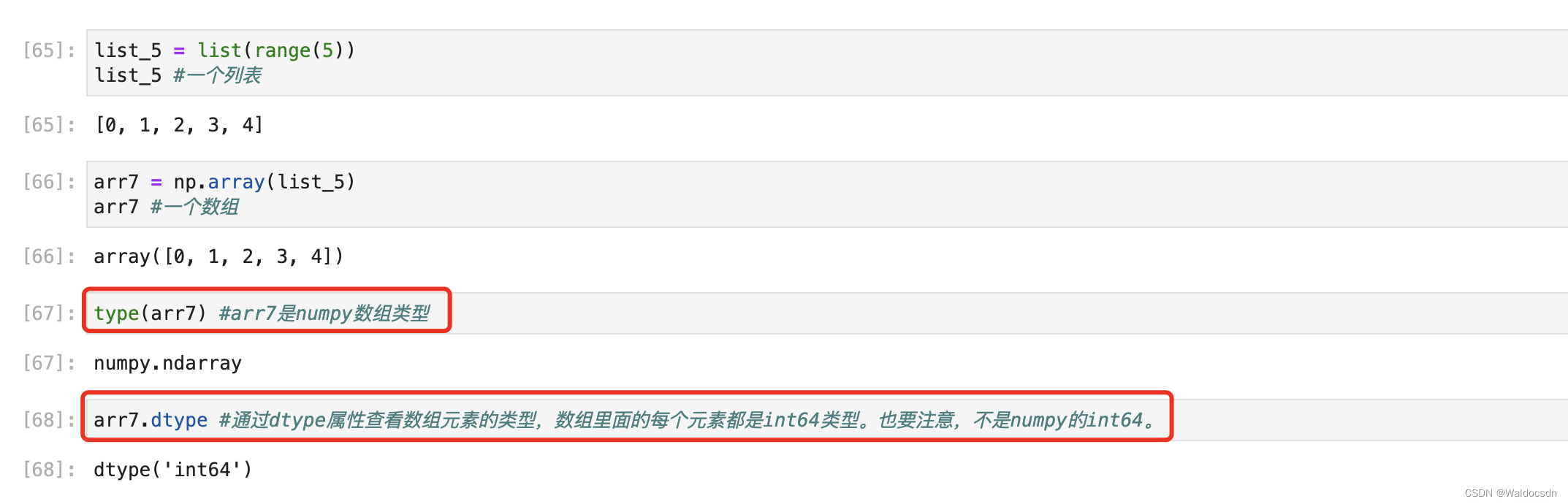
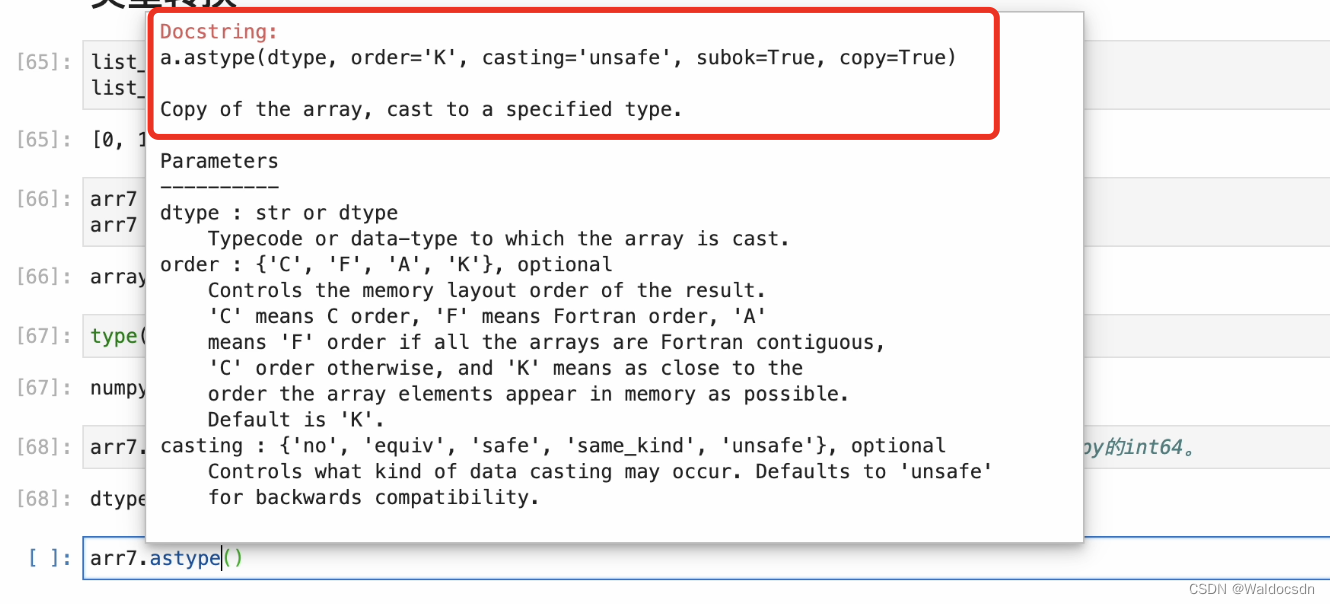
numpy.astype()
関数の説明を見ると、astype() が元の配列のコピーを作成し、配列内の要素の型を変更できることがわかります。
例:
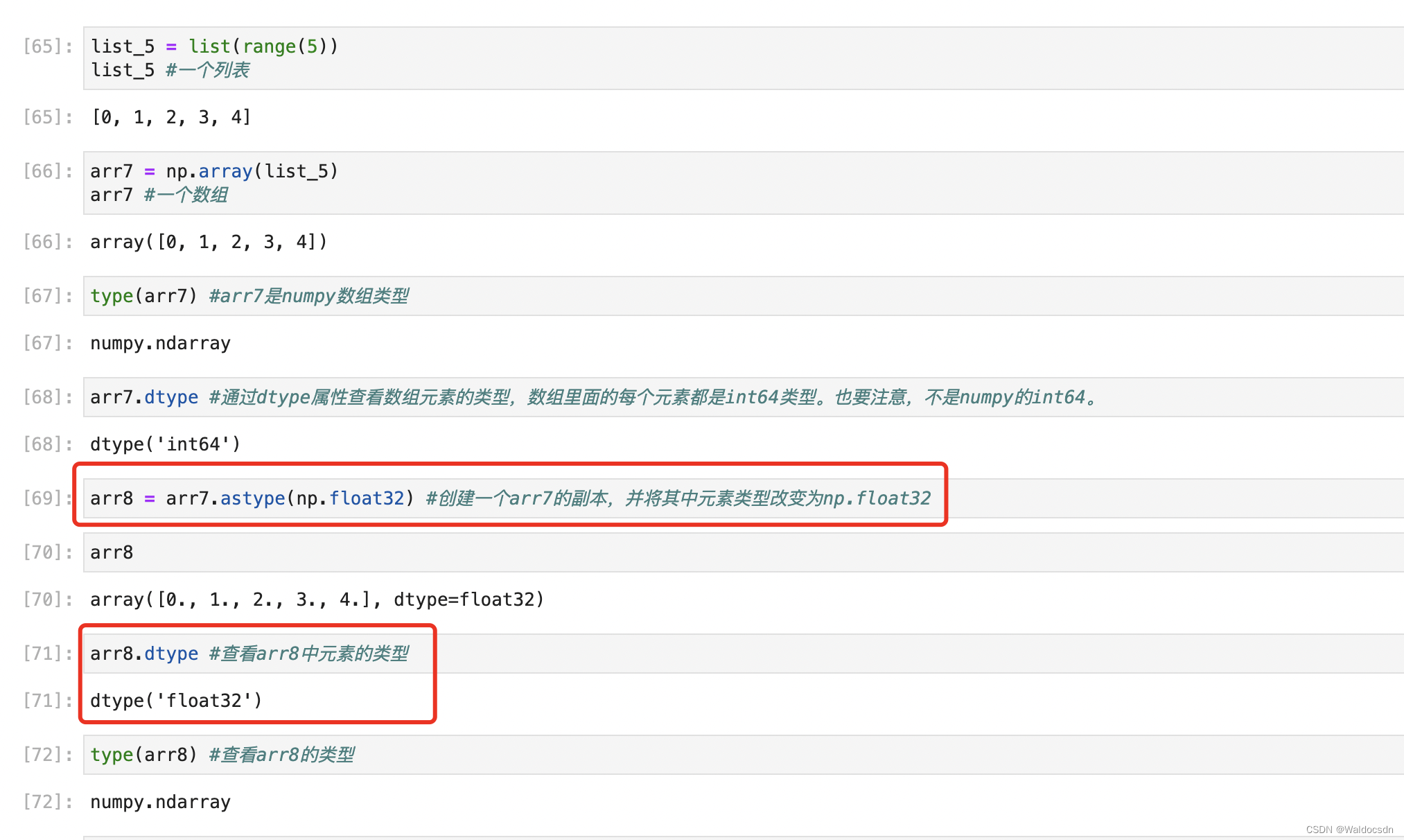
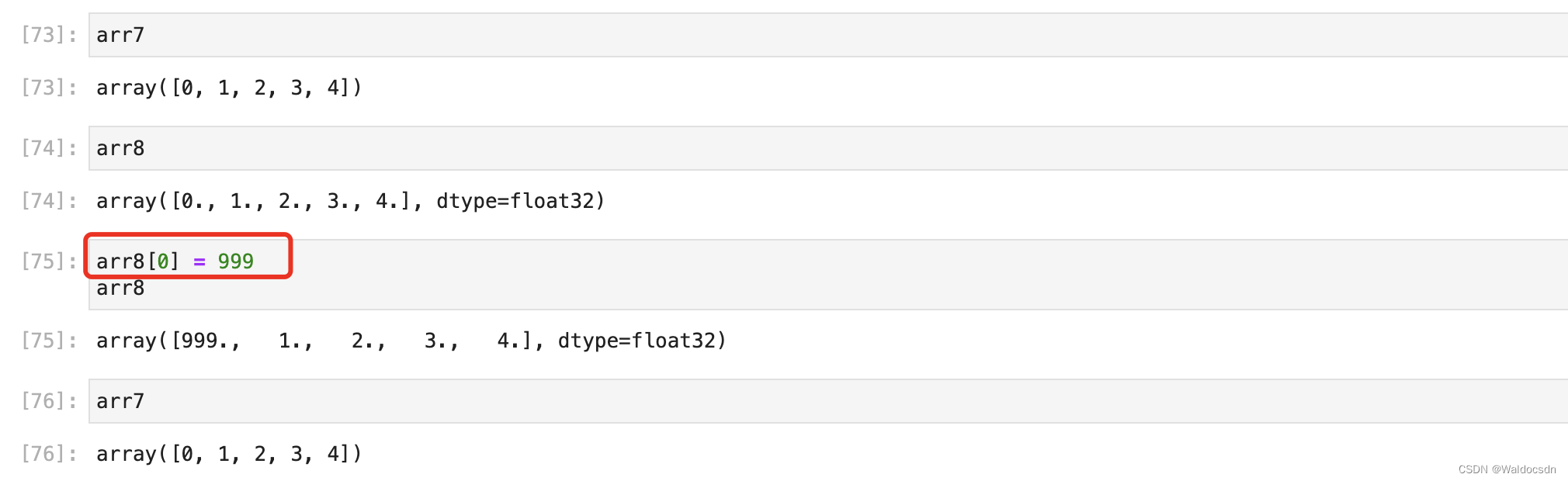
astype() 関数を使用した後、arr8 の要素を通じてそれが arr7 のコピーであるかどうかを確認します。
配列スライス
数组切片是原始数据的视图,也就是不会创造副本。注意这与列表切片的区别。
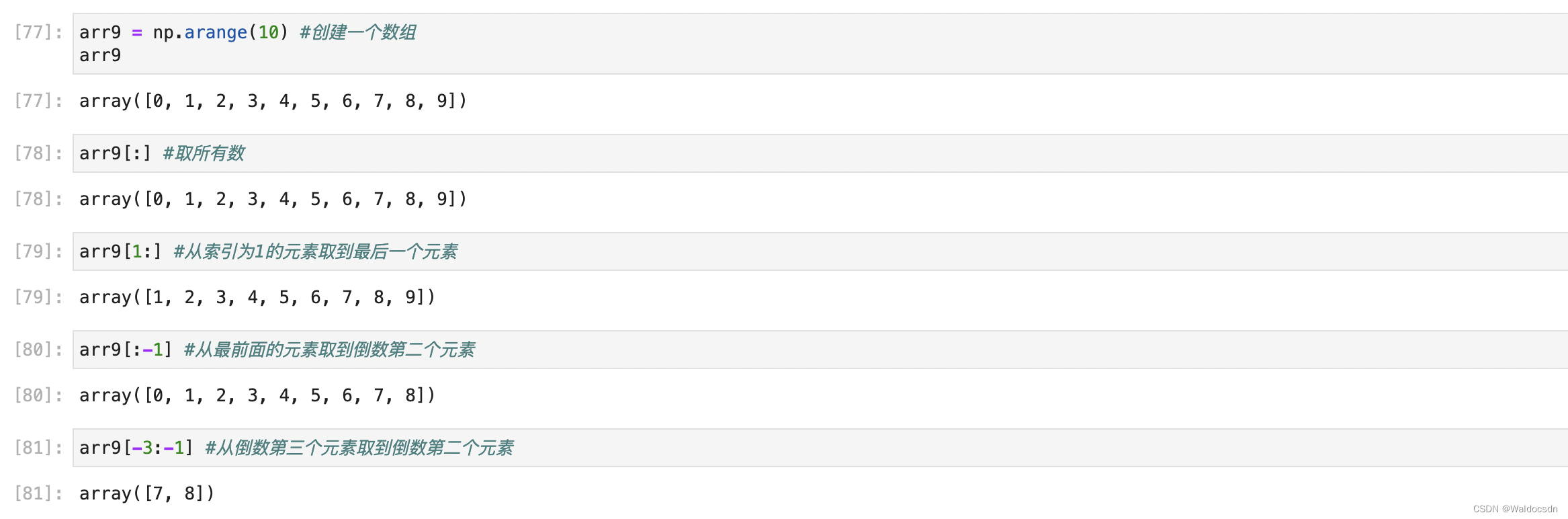
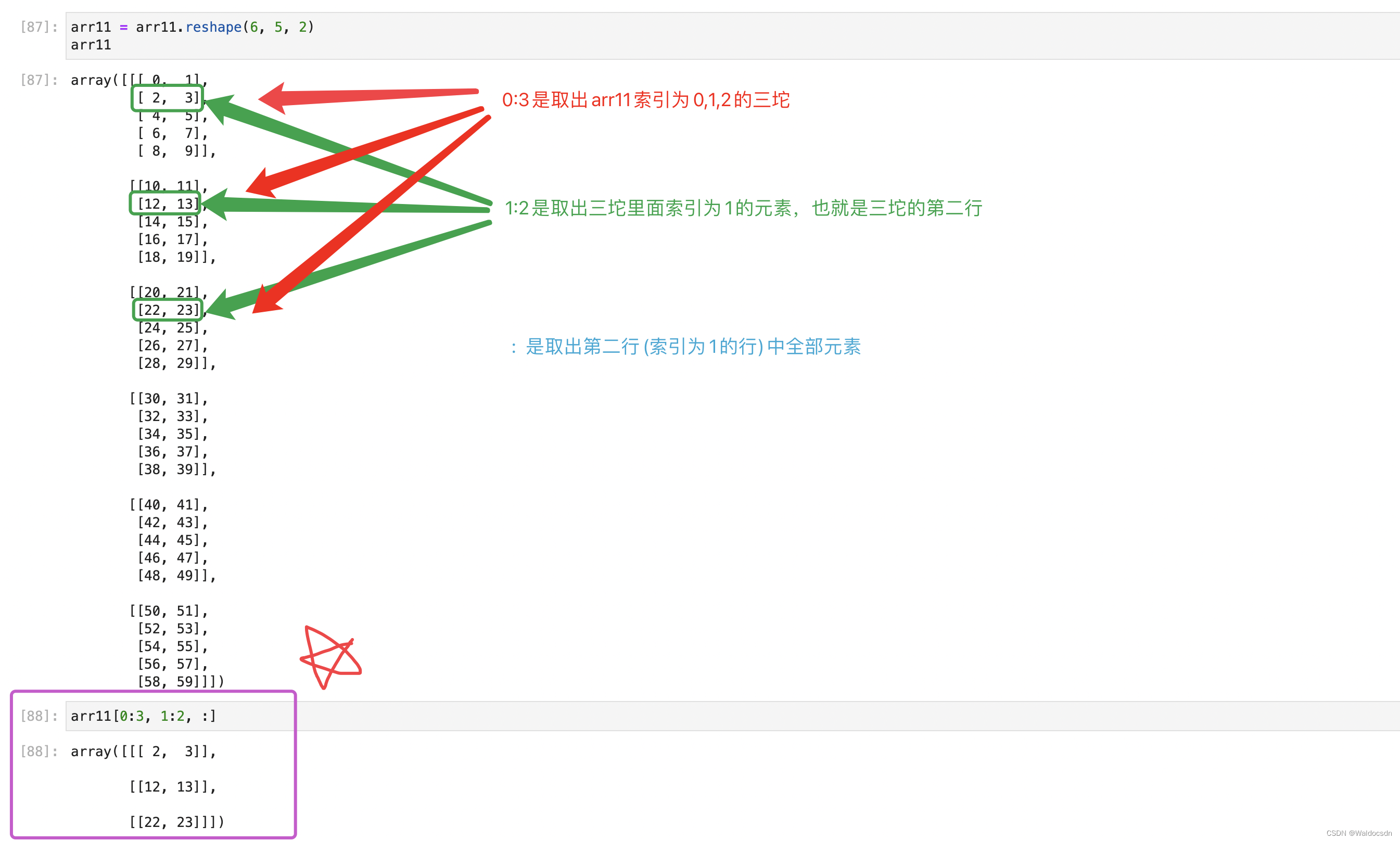
高次元配列スライス:
例1:
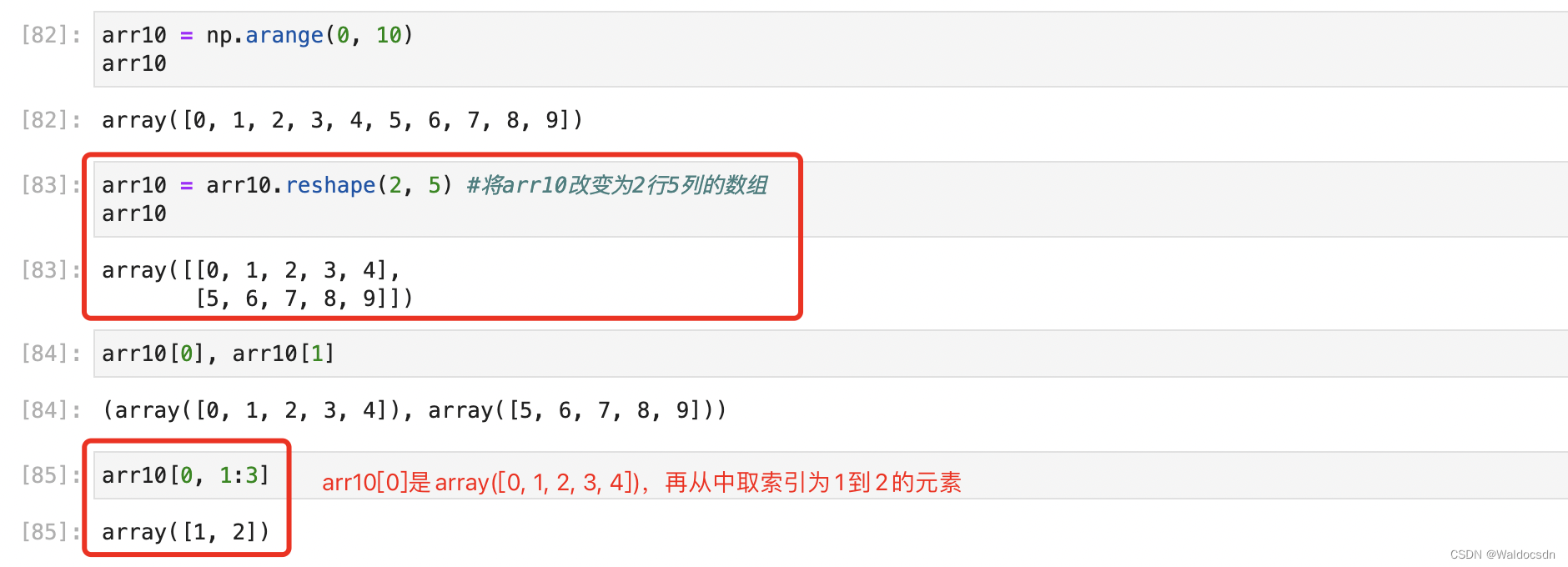
例2: