記事ディレクトリ
ディープラーニングフレームワーク開発の歴史


loss は目的関数と損失関数と呼ばれます。
TensorFlow の 3 つのコア: tensorflow.layers (層)、tensorflow.metrics (行列)、tensorflow.losses (目的関数)
tfcontrib による勾配降下法をレビューする
TensorFlow フレームワーク開発の歴史
2015 年の TensorFlow 1.0 バージョンは明らかに PyTorch ほど単純ではありません
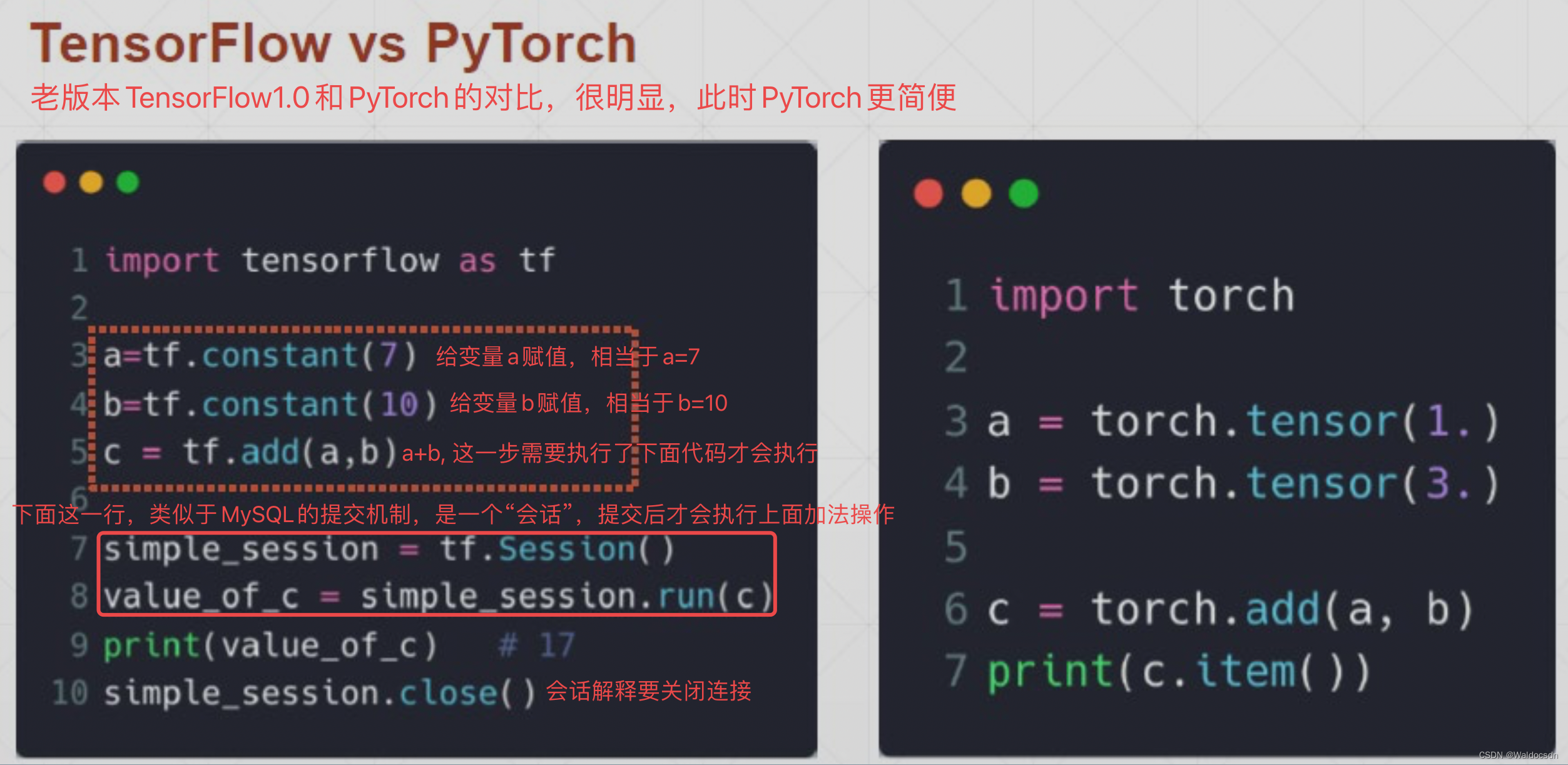
Google が TensorFlow を買収した後、TF+Keras を統合して TensorFlow 2.0 を立ち上げ、TensorFlow をより簡単にしました。


ニューラルネットワークの主流API

手書き数字の予備問題
思考: これはどのような問題なのか、この問題を解決するためにどのような技術 (方法) が使用されているのか、この技術をどのように実現するのか、コンピュータの思考にニューラル ネットワークがどのように組み込まれているのか、なぜ人間の思考をシミュレートするためにそのようなニューラル ネットワークを使用するのか?
導入
単純な線形モデル: y=w*x+b。以前は、x から y は 1 つの数値と 1 つの数値の間でマッピングされていました。つまり、x=1 の場合、y=2x+3 は y=5 にマッピングされるだけです。数。
また、入力と出力が変数になると、[0 1 1 2] を [3 5 5 7] にマッピングするなど、行列間のマッピングになる可能性があります。他のモデルでは、行列を単一の関数にマッピングすることもできます。番号。
映射就是工序,这个要牢记
[上、左、下、右]から[犬、猫、クジラ、鳥]へのマッピングなど、何らかのマッピングモデルを採用することも可能です。并不是只能数字映射到数字,也可以数字映射到文字,文字映射到数字。只要找到适当的映射,任何万物都可以相连起来。
上の文の考え方に基づいて、画像を分類する場合、入力は写真、出力は英単語となるので、写真をどのように表現するかを考える必要があります。MNIST データセットの概要は次のとおりです。
NLPCV基本記事5にミニストデータセットを導入
MNIST データセットの概要
Size:28×28 グレースケールの手書きデジタル画像、トレーニングセット
Num:60,000、テスト セット 10,000、合計 70,000 枚の写真0、1、2、3、4、5、6、7、8、9
Classes:
公式ダウンロードリンク: MNIST

データセットの読み取り
ジュピターラボでテスト済み。パスは変更するコンピュータによって異なります。ファイルを読み取ることができません。パラメータを変更してください:
download=True。
- MNIST データセット ファイル
train-images-idx3-ubyte.gz: トレーニング セット画像 (9912422 バイト) 55000 トレーニング セット + 5000 検証セット。train-labels-idx1-ubyte.gz: トレーニング セット ラベル (28881 バイト) トレーニング セットに対応するラベル。t10k-images-idx3-ubyte.gz: テスト セット画像 (1648877 バイト) 10000 テスト セット。t10k-labels-idx1-ubyte.gz: テスト セット ラベル (4542 バイト) テスト セットに対応するラベル。
- MNIST データセットを読み取る
データセットがダウンロードされていない場合は、パラメーターを変更します。download=True
from torchvision import datasets, transforms
train_data = datasets.MNIST(root="./MNIST",
train=True,
transform=transforms.ToTensor(),
download=False)
test_data = datasets.MNIST(root="./MNIST",
train=False,
transform=transforms.ToTensor(),
download=False)
print(train_data)
print(test_data)
出力結果:
Dataset MNIST
Number of datapoints: 60000
Root location: ./MNIST
Split: Train
StandardTransform
Transform: ToTensor()
Dataset MNIST
Number of datapoints: 10000
Root location: ./MNIST
Split: Test
StandardTransform
Transform: ToTensor()
完全なデータセット読み取りコード:
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
train_data = datasets.MNIST(root="./MNIST",
train=True,
transform=transforms.ToTensor(),
download=False)
test_data = datasets.MNIST(root="./MNIST",
train=False,
transform=transforms.ToTensor(),
download=False)
train_loader = DataLoader(dataset=train_data,
batch_size=64,
shuffle=True)
test_loader = DataLoader(dataset=test_data,
batch_size=64,
shuffle=True)
データの視覚化
データセットを例として挙げます。
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
train_data = datasets.MNIST(root="./MNIST",
train=True,
transform=transforms.ToTensor(),
download=False)
train_loader = DataLoader(dataset=train_data,
batch_size=64,
shuffle=True)
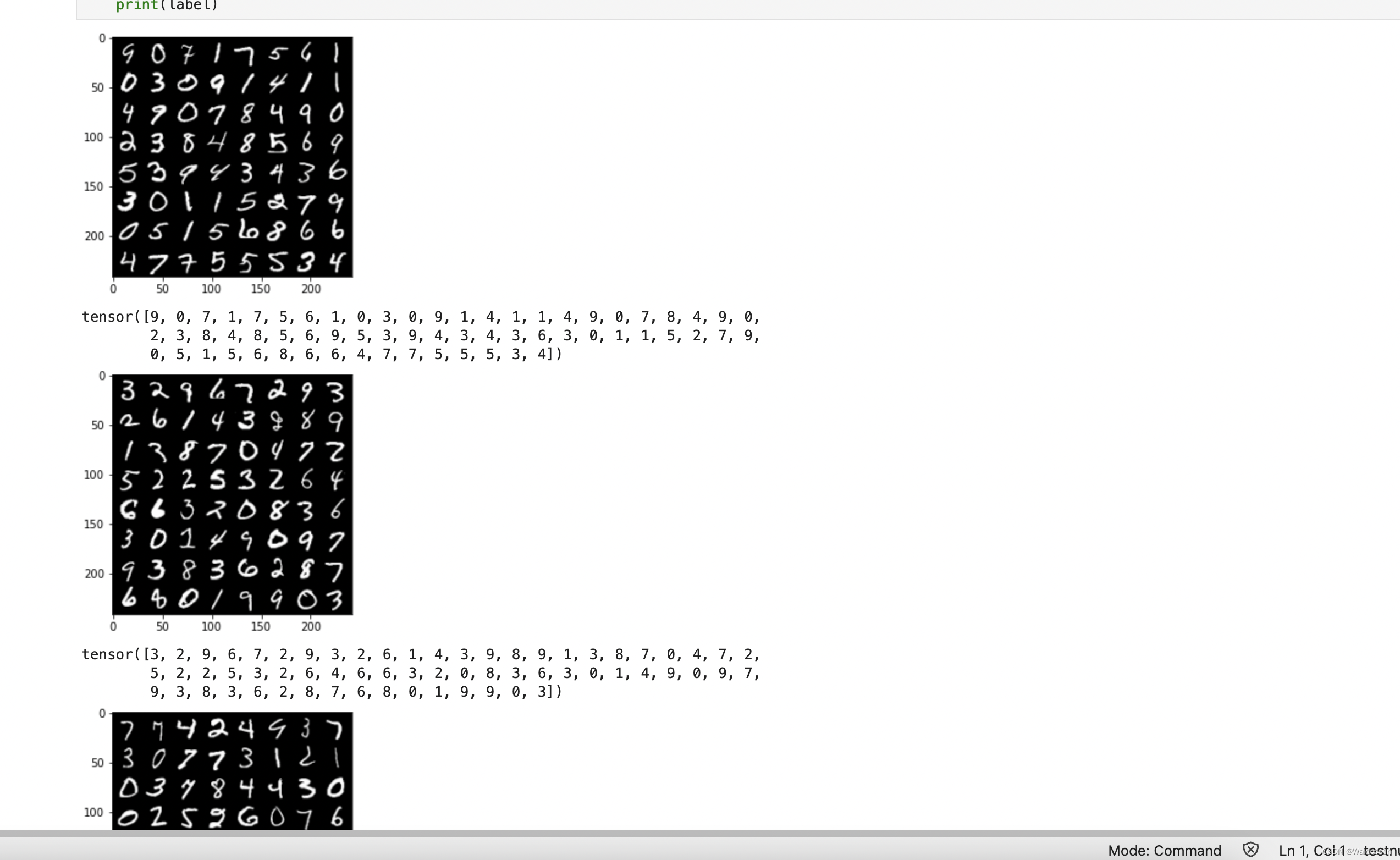
for num, (image, label) in enumerate(train_loader):
image_batch = torchvision.utils.make_grid(image, padding=2)
plt.imshow(np.transpose(image_batch.numpy(), (1, 2, 0)), vmin=0, vmax=255)
plt.show()
print(label)
出力:
行列表現図は、行列にどの値が配置されるかを研究するものです
人工知能には表現学習と呼ばれる方向性があり、自然界のものをコンピュータが受け入れられる形式に表現する方法を研究します。
png、jpg などの形式の画像の場合、コンピュータはこの形式を理解できません。一般的な画像表現は、RGB (トリプル)、グレー値 (クワッド) です。
下の「8」の画像では、28*28*1 ピクセルを使用し、これらのピクセルはこの画像を表す多次元行列を形成します。将来的には、この行列にどの値を入れるかに焦点を当てます。
行列表現図は、行列にどの値が配置されるかを研究するものです
存在する場合通用形式的输入x: [b, 784]。「b」は「バッチ」を意味し、データの集合を表し、bの値は画像が何枚あるかを表します。ここで、各ピクチャは「784」値で表されます。この入力 x も、[b, 28, 28]、[b, 28, 28, 1] と書くこともできます。ここで、入力 [b, 28, 28] は、各ピクチャが 28*28 の行列で表されることを意味します。マトリックスには 784 個の要素があります。
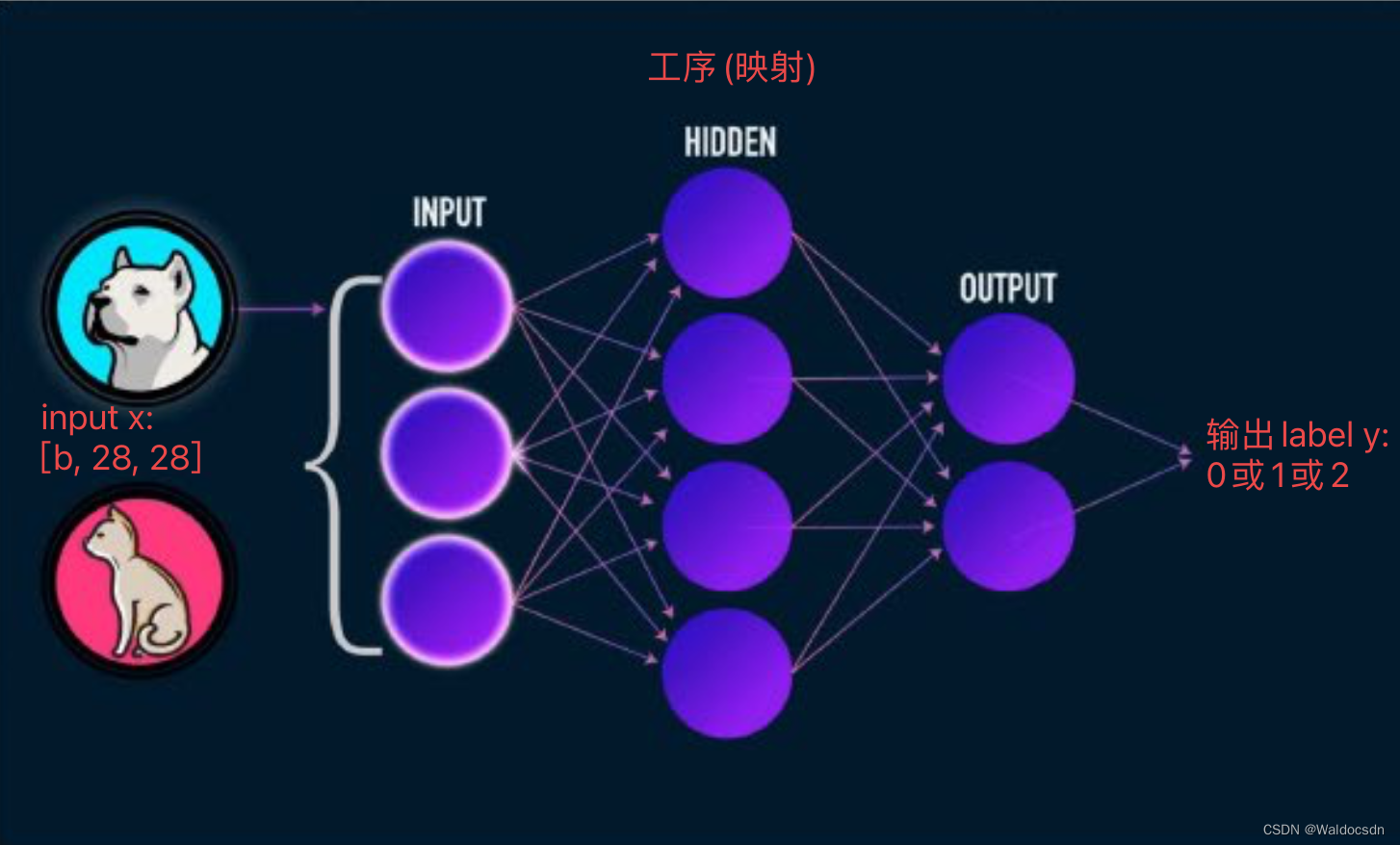
犬を0、猫を1、魚を2とすると、
[b, 28, 28]を入力し、複数の処理(マッピング)を経て、0 or 1 or 2を取得し、高次元行列をマッピングします。単一の数値にするには、複雑な複数ステップのプロセス (マッピング) が必要です。
計算グラフ、ワンホットワンホットエンコーディングの予備
次のビデオのクリアバージョン: リンク: https://pan.baidu.com/s/1xwzPn_e_Rcy-e7CMADMwkw?pwd=derx 抽出コード: derx
CVNLP基本記事5計算グラフ
予備的な relu 関数、ユークリッド距離
では、どのようにして前のニューラルネットワークに接続するのでしょうか? [b, 784] * [784, 10] = [b, 10] を直接使用すると、出力を取得するのに 1 ステップしかかかりませんが、複雑な問題を扱うには単純すぎて乱暴です。問題の複雑さに応じて、適切なモデルを選択してください。[b,10] を取得するために複数のステップに分割することができ、各ラウンドの入力を処理するために relu 関数を使用することをお勧めします。詳細については、画像の下のビデオを参照してください。

以下のビデオのクリアバージョン: リンク: https://pan.baidu.com/s/1ZMDVBjDBBotBhUer3oenUg?pwd=6a8t 抽出コード: 6a8t
CVNLP基本記事5relu関数予備ユークリッド距離
平均二乗誤差 MSE: 平均二乗誤差。多次元の場合、「ユークリッド距離」を使用して「出力 out」と「ラベル y」の間の損失値を計算できます。
要約する

次のビデオのクリアバージョン: リンク: https://pan.baidu.com/s/17pdfOT03NVhsiBmuDwVQNQ?pwd=f956 抽出コード: f956
CVNLP 基本第 5 条分類プロセス
少し練習
画像が 100 枚あり、入力 x は [100, 784]、出力ラベル y は 20 カテゴリです。3層処理のプロセスを書き出し、各w、bの次元と各層の出力次元を書き留めます。
