導入
既存の従来のハッシュは、少なくとも 1 つのタグが一致する限り考慮されるため、図に示す例では、ab と ac の両方が一致するとみなされ、top1 が複数ラベルのペアの類似性をソートすることが不可能になります
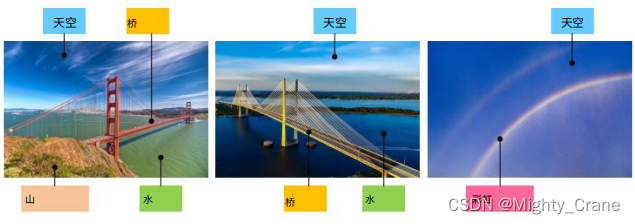
。各画像が保持するセマンティクス ラベルは、ペアごとの類似性のソフトな定義を提案します。具体的には、正規化された意味ラベルを使用して、ペアごとの類似性がパーセンテージとして定量化されます。(投稿: 1)
そこで 2 つの類似度を提案します. ハード類似度ではすべてのラベルが一致するとみなされるため、クロスエントロピー学習が使用されます; ソフト類似度では部分的なラベルの一致が考慮されるため、平均二乗誤差が使用されます (貢献 2)
関連作業
深層ハッシュ学習への簡単なアプローチは、クラス ハッシュ表現を学習する DLBHC [46] に代表される高レベルの特徴を直接閾値処理することです。ネットワークは分類タスクに関して適切に調整されていますが、潜在ハッシュ層の特徴は
識別力があると考えられており、実際に手作りの特徴よりも優れたパフォーマンスを示します。(也就是说deephash比特征工程好,但相比起直接deep,直接Alexnet或者传统hash效果咋样呢)
マルチラベル検索の場合、DSRH [25] は、ハッシュ関数を学習するためにマルチレベルの類似性のランキング情報を利用しようとし、ランキング指標の最適化問題を解決するために代理損失を提案しています。IAH [47] は、インスタンスを認識した画像表現の学習に焦点を当てており、重み付き三重項損失を使用して、マルチラベル画像の類似性ランキングを維持します。ただし、DSRH [25] と IAH [47] で採用されている重み付きトリプレット損失関数は、画像との類似性に応じて画像の正しいランキングを維持することに重点を置いているため、きめの細かいマルチレベルの意味的類似性の学習に直接制約を課しません。クエリ(也就是说一直在纠结于损失函数,而没有针对多标签相似度的痛点来解决问题吧)
これに基づいて、DMSSPH [48] は、マルチラベル画像間のマルチレベルの類似性を保存するために、出力空間の識別可能性を最大化するハッシュ関数の構築を試みます。DMSSPH [48] は、ペアごとの類似性学習にきめの細かいマルチレベルの意味論的類似性を利用していますが、さらなる探求の余地がまだあります。新しい効果的な TALR アプローチが [36] で提案されています。これは、整数値のハミング距離に対する制限されたランキングを考慮し、ランキングベースの評価メトリクスである平均精度 (MAP) [49] と正規化割引累積ゲイン (NDCG) [50] を直接最適化します。 ]。いくつかのベンチマーク データセットで高いパフォーマンスを実現します。[51] では、教師ありハッシュ法を評価するための 2 つの新しいプロトコルが転移学習のコンテキストで提案されています。
この論文では、ハッシュ品質を向上させるために、マルチラベル データセット上のペアごとの意味論的類似性の多様性を調査します。具体的には、きめ細かいペアワイズ類似度値が連続形式で定義されます(将离散的汉明距离改成连续值?)。したがって、ペアワイズ類似度は 2 つのケースに分けられ、特徴学習とハッシュ コード生成を同時に実行するために結合ペアワイズ損失関数が構築されます。
方法
マルチラベルの類似性を調べるために、定量的なラベルは連続値のパーセンテージ、つまり 2 つの画像の意味ラベル ベクトルのコサイン類似性です (この論文は、詳細なラベルの定量化にコサイン距離を使用した最初の論文です)。ペア画像の粒度の細かい意味的類似性)
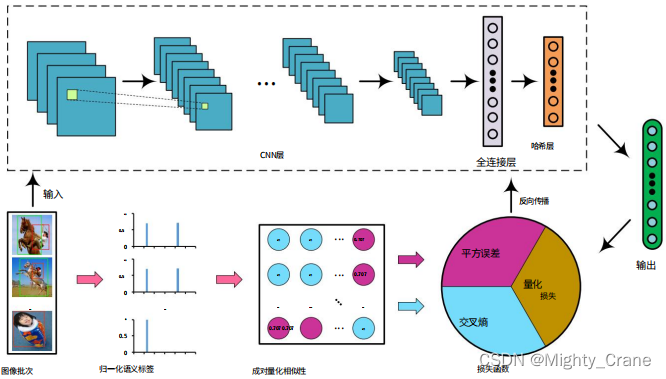
画像は Alexnet を通過し、最終的な fc8 レイヤーの出力は次のアクティベーション関数によって (-1,1) にマッピングされます。(提到本文的Alexnet是可以随意替换成vgg、Googlenet等,所以为啥这俩更新的网络不如初号机有啥说道吗)
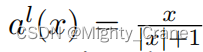
厳密な類似性
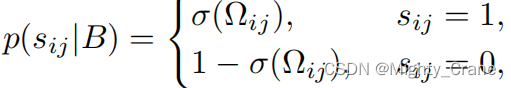
ここで、Ω は 2 つのハッシュ コードの内積です。
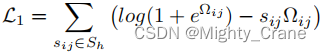
ソフトな類似性
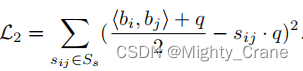
共同学習
両方のケースを同時に学習し、統一された形式を形成するために、Mij を使用して 2 つのケースにラベルを付けます。Mij = 1 は「ハード類似性」ケースを示し、Mij = 0 は「ソフト類似性」ケースを示します。したがって、ペアごとの類似性損失は次のように書き換えられます。(这不其实就是那俩损失函数结合嘛)
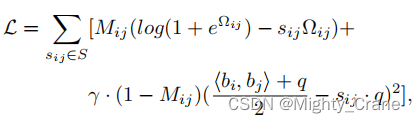
方程式を直接最適化するのは困難です。バイナリ制約 bi ∈ {−1, 1} q ではネットワーク出力のしきい値処理が必要なため、トレーニング中にバックプロパゲーションで勾配消失問題が発生する可能性があります。
スケーリングされたペアワイズ量子化損失

最終的な損失は C = L + λQ です
実験
パフォーマンス
平均累積利得 (ACG) [60]、正規化
割引累積利得 (NDCG) [50]、平均
平均精度 (MAP) [49] および加重平均精度 (WAP) [25]。
ハッシュ損失関数に関しては、高次元データを低次元バイナリ コードにマッピングして、データ検索の速度と効率を向上させます。
入力は 4 つのパラメータで構成されます。
D: 形状 のサンプルの固有ベクトル行列を表します(batch_size, feature_dim)。label: サンプルのラベル ベクトル行列を表します。形状は です(batch_size, num_class)。ここで、num_classはカテゴリの数を表します。alpha、belta、gama: は 3 つの損失項目の重み係数を表します。m:ハッシュコードの長さを示します。
具体的には、このハッシュ損失関数は、コサイン類似度損失、ハッシュ コード長制約、および正則化項の 3 つの部分で構成されます。その中で、コサイン類似度損失は、サンプルペア間のコサイン類似度を比較することによってハッシュコードと一致することができ、
最初にラベルのコサイン類似度行列を計算します
label_count = tf.expand_dims(tf.sqrt(tf.reduce_sum(tf.square(label), 1)),1)
# 标签向量的模长
norm_label = label/tf.tile(label_count,[1,args.num_class])
# 标签向量的单位向量
w_label = tf.matmul(norm_label, norm_label, False, True)
# 标签向量之间的余弦相似度矩阵
semi_label = tf.where(w_label>0.99, w_label-w_label,w_label)
# 将大于阈值0.99的相似度设置为0后的相似度矩阵
次に、サンプルのコサイン類似度を計算します。
p2_distance = tf.matmul(D, D, False, True)
ハッシュ コードの長さの制約により、ハッシュ コードの長さが指定された値を超えないようにすることができます。実装では、サンプルのハッシュ コードを計算し、指定されたハッシュ コード長と比較して、ハッシュ コード長の制約損失を取得する必要があります。
scale_distance = belta * p2_distance / m
# 对距离矩阵进行缩放后的值
temp = tf.log(1+tf.exp(scale_distance))
loss = tf.where(semi_label<0.01,temp - w_label * scale_distance, gama*m*tf.square((p2_distance+m)/2/m-w_label))
regularizer = tf.reduce_mean(tf.abs(tf.abs(D) - 1))
d_loss = tf.reduce_mean(loss) + alpha * regularizer
このように、論文のC=L+αQ
ハッシュ コード長制約により、ハッシュ コードの長さが指定値を超えないようにすることができ、正則化項はモデルの過学習を防ぐのに役立ちます。
この関数の出力は 2 つの値で構成されます。
d_loss:ハッシュロスの合計値を示します。w_label: の形状を持つタグ間のコサイン類似度行列を表します(batch_size, batch_size)。
関数の実装では、最初にサンプル ラベルが標準化され、次にラベル間のコサイン類似度行列が計算され、しきい値を超える類似度が 0 に設定されます。次に、サンプル間のコサイン類似度行列を計算し、距離行列を 0 から 1 までの値の範囲にマッピングします。最後に、3 つの損失項目が計算され、それらの加重合計がハッシュ損失の合計値となります。
主要
このコードの役割は、tfrecord ファイル内のデータを読み取り、AlexNet モデルを構築し、ハッシュ損失 ( d_loss) を計算し、トレーニングにオプティマイザーを使用することです。
具体的には、まずreader.read_and_decode関数 を通じて tfrecord ファイルからデータを読み取り(这个在tf2版本里要大改了,需要换成data相关函数)、一連の画像 ( img) とそれらに対応するラベル ( label) を取得します。次に、関数を使用して、読み取った画像とラベルをシャッフルして、モデルのトレーニングに使用される size のバッチtf.train.shuffle_batchを形成します。args.batch_size
次に、AlexNet関数を使用して AlexNet モデルを構築し、バッチ内の画像データを入力として取得し、出力を取得しますD。この出力には、各画像に対応するハッシュ コードが含まれています。(哈希码的维度由num_bits控制)
次に、hashing_loss関数を使用してハッシュ損失を計算し、出力値Dとラベル値をlabel_batch入力パラメーターとして受け取ります。このうち、args.alpha、 、args.beltaはargs.gamaハイパーパラメータで、それぞれ類似性損失、ハッシュ コード長制約、正則化項の重みを制御します。
最後に、計算されたハッシュ損失 ( d_loss) とモデル出力 ( out) が返されます。
次に、トレーニング プロセスを最適化します。
- 指定された Skip_layers に従って、すべてのトレーニング可能な変数は var_list1 と var_list2 の 2 つのカテゴリに分類されます。このうち、var_list1 には微調整が必要なすべての変数が含まれており、var_list2 には最初からトレーニングする必要があるすべての変数が含まれています。
- learning_rate を定義し、指数関数的減衰を設定します。
- 2 つの Adam オプティマイザー、opt1 と opt2 を定義します。このうち、opt1 の学習率は learning_rate*0.01 で、var_list1 の変数の最適化に使用され、opt2 の学習率は learning_rate で、var_list2 の変数の最適化に使用されます。
- すべての変数の勾配 grads を計算し、var_list1 と var_list2 に従って grads1 と grads2 の 2 つの部分に分割します。
- opt1 と opt2 を使用して、それぞれ grads1 と grads2 の勾配を最適化し、global_step を更新します。
- 2 つのオプティマイザーの更新操作を 1 つの train_op に結合します。
したがって、モデル全体のトレーニング プロセスが実現され、2 種類の変数の勾配が異なるオプティマイザーを通じて更新されるため、微調整とゼロからのトレーニングという 2 つの異なるトレーニング方法が実現されます。
トレーニング ループでは、TensorFlow 計算グラフ (Graph) 内のノードがセッション (Session) オブジェクトを通じて実行されます。
まず、トレーニングされたモデルを保存するための Saver オブジェクトが定義されます。次に、sess.runメソッドを使用してグローバル変数とローカル変数を初期化し、事前トレーニングされたモデルの重みをネットワークに読み込みます。次に、データセット キュー スレッドを開始し(这个应该只能用在tf1中,tf2就尬住了)、トレーニング ループに入ります。
トレーニング ループでは、sess.runメソッドを通じて 3 つのノード、つまりtrain_op(トレーニング ノード)、d_loss(損失ノード)、およびglobal_step(グローバル ステップ ノード) が実行されます。このうち、train_op計算された勾配を変数に適用する演算ノードであり、戻り値は None です;d_loss損失を計算するノードであり、戻り値はスカラーです;global_step変数であり、その値は増加しますトレーニング ノードが実行されるたびに 1 ずつ増加します。
トレーニング プロセス中、step1 % 10 == 0現在の反復数 (step1)、損失値 (loss_t)、および所要時間 (elapsed_time) を含むトレーニング情報を 10 反復ごとに出力するように制御されます。step1 % args.save_freq == 0反復回数ごとにargs.save_freqモデルの保存を制御するために使用します。データセット内のすべてのサンプルが走査されると、トレーニングは終了します。最後に、キュー スレッドを停止し、セッションを終了します。
alexnet については、畳み込み方法は caffe と似ており、グループが 1 の場合は直接畳み込み演算が実行され、グループが 1 より大きい場合は入力と畳み込みカーネルがグループの数に応じてグループ化され、畳み込み演算は個別に実行され、最後に結果が結合されます。最終的な出力結果は、バイアス、ReLU アクティベーションなどによって処理されます。(グループ: グループ畳み込みのグループ数、デフォルトは 1)