目次
1. 実験の紹介
この記事では、予測の精度を計算する補助関数を実装します。Accuracy は、各ラウンドでのデータの各バッチの評価をサポートし、その結果を蓄積して、最終的にデータのバッチ全体の評価結果を取得します。
- トレーニングまたは検証中に
updateメソッドを繰り返し呼び出して評価メトリクスを更新します。 - メソッドを使用して
accumulate累積精度を取得します。 resetメソッドは、次の計算ラウンドの評価指標をリセットするために使用されます。
2. 実験環境
この一連の実験では、PyTorch 深層学習フレームワークを使用しており、関連する操作は次のとおりです。
1. 仮想環境を構成する
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. ライブラリバージョンの紹介
| ソフトウェアパッケージ | 今回の実験版は | 現在の最新バージョン |
| マットプロットライブラリ | 3.5.3 | 3.8.0 |
| しこり | 1.21.6 | 1.26.0 |
| パイソン | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| 松明 | 1.8.1+cu102 | 2.0.1 |
| トーショーディオ | 0.8.1 | 2.0.2 |
| トーチビジョン | 0.9.1+cu102 | 0.15.2 |
3. 実験内容
チャットGPT:
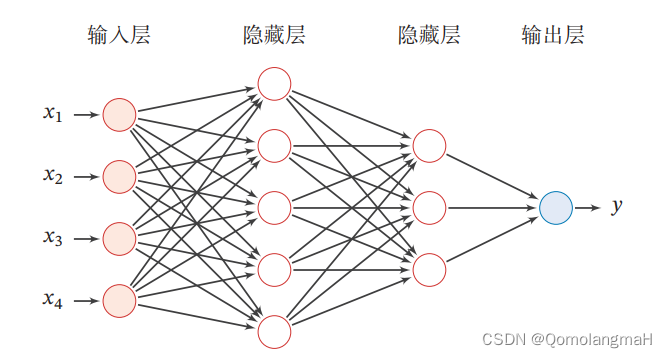
フィードフォワード ニューラル ネットワークは、多層パーセプトロン (MLP) としても知られる一般的な人工ニューラル ネットワーク モデルです。これは順伝播に基づくモデルであり、主に分類と回帰の問題を解決するために使用されます。
フィードフォワード ニューラル ネットワークは、入力層、隠れ層、出力層を含む複数の層で構成されます。その「フィードフォワード」という名前は、信号がネットワーク内でフィードバック接続なしで、つまり入力層から隠れ層を通って最後に出力層まで前方にのみ流れることができるという事実に由来しています。
フィードフォワード ニューラル ネットワークが一般的にどのように機能するかは次のとおりです。
入力層: 生データまたは特徴ベクトルをネットワークへの入力として受け取り、各入力はネットワークのニューロンとして表されます。各ニューロンは入力に重みを付け、活性化関数を通じて変換して出力信号を生成します。
隠れ層: フィードフォワード ニューラル ネットワークには、それぞれが複数のニューロンで構成される 1 つ以上の隠れ層を含めることができます。隠れ層のニューロンは前の層から入力を受け取り、活性化関数によって変換された信号の重み付けされた合計を次の層に渡します。
出力層: 最後の隠れ層の出力は、通常 1 つ以上のニューロンで構成される出力層に渡されます。出力層のニューロンは、解決する問題の種類 (分類または回帰) に応じて適切な活性化関数 (Sigmoid、Softmax など) を使用して、最終結果を出力します。
順方向伝播: 入力層から隠れ層を介して出力層に信号を送信するプロセスは、順方向伝播と呼ばれます。順方向伝播中、各ニューロンは前の層の出力に対応する重みを乗算し、結果を次の層に渡します。このような計算は、最終出力が生成されるまで、ネットワーク内の各層を通じて層ごとに実行されます。
損失関数とトレーニング: フィードフォワード ニューラル ネットワークのトレーニング プロセスには通常、モデルの予測出力と真のラベルの差を測定する損失関数の定義が含まれます。一般的な損失関数には、平均二乗誤差とクロスエントロピーが含まれます。バックプロパゲーションおよび最適化アルゴリズム (勾配降下法など) を使用することにより、ネットワークは損失関数の勾配に従ってパラメーターを調整し、損失関数の値を最小限に抑えます。
フィードフォワード ニューラル ネットワークの利点には、複雑な非線形関係を処理できること、さまざまな種類の問題への適合性、トレーニングを通じて特徴表現を自動的に学習する機能が含まれます。しかし、過学習しやすい、大規模データや高次元データの処理が難しいなどの課題もあります。これらの課題に対処するために、畳み込みニューラル ネットワークやリカレント ニューラル ネットワークなど、いくつかの改良されたネットワーク構造とトレーニング技術が提案されています。
このシリーズは実験的な内容であり、理論的な知識を詳しく解説するものではありません。
(ああ、実際にはそれを整理する時間がありません。機会があれば戻ってきてギャップを埋めます)
0. 必要なツールキットをインポートする
import torch
from sklearn.datasets import load_iris
from torch.utils.data import Dataset, DataLoader
DatasetDataLoaderデータセットとデータ読み込みを処理するためのクラスと
このコードは、Accuracyバッチでのモデル評価、特に分類タスクの精度の計算をサポートするために呼び出されるクラスを定義します。
1. __init__(コンストラクタ)
class Accuracy:
def __init__(self, is_logist=True):
self.num_correct = 0
self.num_count = 0
self.is_logist = is_logist- コンストラクターは、
Accuracyオブジェクトの作成時に呼び出されます。オプションのパラメータ を受け入れますis_logist。デフォルトは でTrue、logistフォームの値を予測するかどうかを示します。 self.num_correct正しく予測されたサンプルの数を記録するために使用されます。self.num_countサンプルの総数を記録するために使用されます。self.is_logistlogist予測値がフォームであるかどうかを示します。
2.アップデート機能(評価指標の更新)
def update(self, outputs, labels):
if outputs.shape[1] == 1:
outputs = outputs.squeeze(-1)
if self.is_logist:
preds = (outputs >= 0).long()
else:
preds = (outputs >= 0.5).long()
else:
preds = torch.argmax(outputs, dim=1).long()
labels = labels.squeeze(-1)
batch_correct = (preds==labels).float().sum()
batch_count = len(labels)
self.num_correct += batch_correct
self.num_count += batch_count
update評価指標を更新するメソッドです。これは、モデルの予測出力と真のラベルをそれぞれ表す2 つのパラメーターoutputsとを受け入れます。labelsoutputsタスクの形状 に基づいてタスクの種類を決定します。outputsそれが 2 次元テンソルで、2 番目の次元のサイズが 1 の 場合、それは 2 値分類タスクを表します。- の場合
is_logist=True、outputs予測値はしきい値 (0) によって変換されpreds、整数型に変換されます。 - の場合
is_logist=False、outputs予測値はしきい値 (0.5) で変換されpreds、整数型に変換されます。
- の場合
outputsそれが 2 次元テンソルであり、2 番目の次元が 1 より大きい 場合、それは多分類タスクを示します。このとき、outputs最も確率の高いカテゴリが予測値として使用されますpreds。
labels冗長な次元が削除され、このデータ バッチ内の正しく予測されたサンプルの数が計算されますbatch_correct。- このデータ バッチ内のサンプル数を取得します
batch_count。 - 合計を更新し
num_correct、num_count正しいサンプルの数とサンプルの総数を累積的に計算します。
5. 累積(精度を計算)
def accumulate(self):
if self.num_count == 0:
return 0
return self.num_correct / self.num_countaccumulate精度の計算に使用される方法。- 0の場合は
num_count更新が行われていないことを意味し、0を返します。 - それ以外の場合は、正しいサンプルの数をサンプルの総数で割った比率、つまり正解率を返します。
- 0の場合は
4.リセット(評価指標のリセット)
def reset(self):
self.num_correct = 0
self.num_count = 0resetこのメソッドは、評価インデックスをリセットし、次の評価ラウンドで合計を 0 にnum_correctリセットするために使用されます。num_count
5. テスト用のデータを構築する
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
acc = Accuracy()
acc.update(y_hat, y)
acc.num_correct6. コードの統合
import torch
# 支持分批进行模型评价的 Accuracy 类
class Accuracy:
def __init__(self, is_logist=True):
# 正确样本个数
self.num_correct = 0
# 样本总数
self.num_count = 0
self.is_logist = is_logist
def update(self, outputs, labels):
# 判断是否为二分类任务
if outputs.shape[1] == 1:
outputs = outputs.squeeze(-1)
# 判断是否是logit形式的预测值
if self.is_logist:
preds = (outputs >= 0).long()
else:
preds = (outputs >= 0.5).long()
else:
# 多分类任务时,计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1).long()
# 获取本批数据中预测正确的样本个数
labels = labels.squeeze(-1)
batch_correct = (preds == labels).float().sum()
batch_count = len(labels)
# 更新
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的评价指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
self.num_correct = 0
self.num_count = 0
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
acc = Accuracy()
acc.update(y_hat, y)
acc.num_correct