From:https://www.zybuluo.com/sambodhi/note/1208157
解決策は何ですか? - 未知のクラスの添加(飛ばない)、サンプル・データを認識し、知られるようにデータを一致度を検出し、
残念ながら、私は簡単にこの問題を解決する方法がわかりません。良いニュースは、私は希望の光を参照してくださいいくつかの戦略があるということです。最も明白なスタートはトレーニングデータに「不明」カテゴリを追加することです。悪いニュースは、次のように、これは、問題の完全に異なるセットをもたらすということです。
- どのような種類含まれるべきサンプルの?潜在自然画像は、ほぼ無制限なので、どのようにそれが含まれたサンプルを選ぶのですか?
- 不明なクラス、どのように多くの異なる種類のオブジェクトをあなたは必要ですか?
- あなたがオブジェクトの位置に非常に似て気のようなルックスのために、どのように処分する必要がありますか?例えば、1000年に品種ないImageNetを追加するが、それは品種と集中化されたデータはほとんど似ています、で「不明バレル」に多くの正しい対応を強制することがあります。
- あなたのトレーニングデータは、どのような割合は、未知の組成クラスのサンプルすべきですか?
この最後の点は、実際には大きな問題に関連しています。画像分類ネットワーク予測値から得られたことは確率ではありません。その仮定の特定のクラスを見ての任意のチャンスは、このタイプの周波数トレーニングデータで発生に等しいです。あなたはアマゾンのジャングルなど、ペンギンなどの動物の分類を、使用しようとすると、(可能)すべてのペンギンの目撃情報が誤報であるため、あなたは、この問題が発生します。品種のさえ、米国の都市は、ImageNetのトレーニングデータで、希少種の品種の犬の発生頻度が公園で見られるよりも高くあるべきであるので、彼らは多くの場合、偽陽性です。通常の解決策は、製造番号に遭遇し、次いで較正値が確率は、実際の結果に近いことにより、ネットワークの出力に適用され使用されている場合に事前確率を計算することです。
主な戦略は、トレーニングデータとオブジェクトが一致ように見えるという仮定の下での制限のモデルを使用する実用的なアプリケーションの全体的な問題を解決するのに役立ちます。簡単な方法は、製品設計を通じて問題を解決することです。あなたがアプリケーションをチェックしたり、同じの他の文書を撃つ尋ねるような、分類器、興味のある対象を心配デバイスを実行する前に、人々をガイドユーザーインターフェイスを作成することができます。
もう少し複雑な、プライマリ画像分類器の条件は、このために設計されていない特定しようとすると、別の画像分類器を書き込むことができます。これは、詳細なモデルの前に多くのカスケード、または1つのフィルタのようなものであるため、「不明」カテゴリが異なっている追加されます。作物の病気、十分な視覚的に透明な動作環境が発生した場合には、それゆえ、ブレード及び他のランダムに選択された画像とを区別するための唯一の学習モデルとすることができます。十分な類似性があるため、ゲーティングモデルは、画像がサポートされていないシーンが撮影されたか否かを、少なくともすることができるはずです。それが先にどんな作物を見つけることができませんでしたエラーメッセージの表示されます植物、どのように見えるか検出されない場合は、このゲーティングモデルは、完全な画像分類器の前に実行されます。
クレジットカードは、一般的に曖昧携帯電話の画面の組み合わせの方向とモデルを検出するために使用され、又は写真が正しく、ユーザーが正常に写真を処理することができます導くためにカメラを整列されていない、「存在するブレードがある写真を撮影したり、OCRのアプリケーションの他の種類を実行する必要があります「モデルは、インターフェイスモードの簡易版です。
これは非常に満足のいく答えのグループではないかもしれないが、研究課題の特定の範囲を超えて機械学習は、ユーザーが結果は同じではありません期待していたときに、これは、正反映しています。人々は常識と外部の知識がたくさんある、物体認識、および古典的な画像分類タスクには知識ではありません。結果は、ユーザーの期待に応えるために取得するために、我々は世界を理解することができるように展開される、とだけでなく、モデル出力に基づいて情報に基づいた意思決定を行うことができ、完全なシステムを設計するために我々のモデルに焦点を当てる必要があります。
次元削減、達成次いで同様の距離KNNを使用して以下CNN。
基づく未知の深さの調査を特定する変調タイプ信号
[学位レベル: マスター
[年]学位授与: 2018
[DOI]: TN911.7、TP181
ここでは、結論を引き出すことができます。テストドメインでの分類が完全に分類されていない場合、分類が誤って分類されます強制された場合、分類は、テストドメインカテゴリに定義されていません。
私たちは、人々があなたのように分類されたカテゴリがわからない場合は、任意の概念のためにその分類カテゴリは、そうすることを場合ことを知っていることを知っている「のカテゴリを見ていません。」だから我々は、アルゴリズムFのための問題から出てくる、トレーニングドメインC内の任意の概念は、PACが学習可能である、とのコンセプトのXのテストドメインの一部は、トレーニングフィールドに属していない、つまり、ドメインXの訓練の概念上のデータがありません、トレーニングフィールドにアルゴリズムF Xのコンセプトは「目に見えないカテゴリ」として分類方法を訓練?
分類とフィールド説明
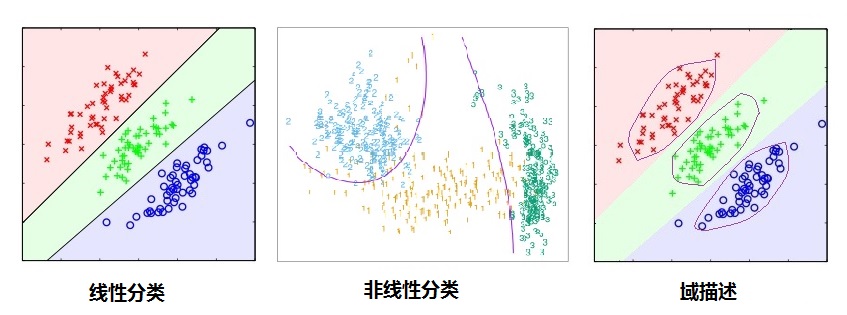
上に示したように、我々はよりリラックスした境界(境界)データフィールド(データドメインの説明)に記載されたアルゴリズムよりも分類(差別)をはっきりと見ることができる、すなわち、分類はわずかな分類を達成する限り、分類アルゴリズムとして、クラス間の境界線を引く必要がその上にエラーが、その時間のカテゴリを区別する必要性を見ていないクラスの境界の具体的な説明は、存在しない、唯一の分類分類アルゴリズムを拒否する意思決定における意思決定のカテゴリー(低確率に知られている分類アルゴリズムは、依然として大きな問題です)、それらが容易にだまされている[8]、ドメイン記述カテゴリの境界を記述しているので、正確に、データ点マーカの既知のクラス外部データのセクタに分類することができ、境界が見えないカテゴリに分類され。(産業分類アルゴリズムを説明有界ドメインに収束したときにランドマークのカテゴリに正式な発言は無限大になる傾向がありません)。
最適化明示的なクラス間及びクラス距離
関数F(x)の最適化された分類タスクのためには、コスト関数を最小クロスエントロピーは次のように、コスト関数であります
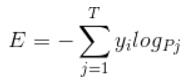
表面上の決定は、このように、図のようにして得られました。
図ドメインに記載したものと同様の効果を得るために、我々は、コントラストの損失として、明示的な距離クラス間の距離を最適化することができる[9-11]
またはトリプル損失[12]
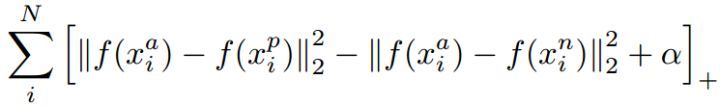
これは、顔認識アルゴリズムの顔WANの問題(オープンセット)提案し、広く顔認識、顔認識と人間の脳に類似して使用することは、より多くの質問ではなく、意思決定の問題の検索機能のようなものです、認識します 1のコントラストをさらに1:Nの検索なので、顔認識アルゴリズムの多くは、それが1であるかどうか、問題が見えないカテゴリを解決することができます。
判別モデルとモデルの生成
判別モデル(差別的モデル)は、直接判別モデル学習Pである(Y | X)、それは、入出力マッピングは、我々は通常、分類アルゴリズムは、SVM、LR、NN ...として判別モデルが、です。
生成モデル(生成モデル)は、P(x、y)を学ぶためのpを学習(Y | X)があり、p(x)は、最終的にP(X、Y)= P(Y | X)は、p(x)は、判別モデルは、事後確率を与えるであり、p(x)は、このような入力は、馴染みの不慣れであるか否かなどの事前確率(また、コンテキストまたは精通呼び出すことができる、である[すなわち、トレーニングの一部ではない| P(X、Y)と考えることができますデータ分布])より小さいP(x)の値を有し、yはxは、見えないような判別モデルとしてモデルを生成する可能性が低い場合にP(x、y)は信頼の包括的なセットとして理解することができますエラーカテゴリに分類カテゴリ[8]。
---------------------
オリジナルます。https://blog.csdn.net/u010165147/article/details/54429644
米国Numenta社2016年11月14日には、既存のマルチDNN(ディープニューラルネットワークは、同社の提案ニューラルネットワークの深さに、脳の神経ネットワーク理論のオリジナルモデル「階層一時記憶(HTM)」に基づき、実際のインポートを発表しました性能比較のための)技術は、)を参照してください(良い結果を得ました。そして、同社はまた、関連する発行します。
| 図1:予測誤差の比較である、乗客の最小数は、他の技術のHTM上ニューヨークタクシーの予測精度は、AI誤差を残しました。入力データのための適切な条件が途中で変更されたときに発生する予測誤差。4月1日には、二パーセント、夜に要求する2パーセントの増加により減少した朝のタクシーを要求します。LSTM6000(緑色の線)は、この根本的な変化、およびHTM(赤線)に対処することはできません学ぶために約2週間かかりました、その後徐々に予測誤差を減らします。(Numenta社からの画像) |
同社のパームコンピューティングの創業者ジェフ・ホーキンス(ジェフ・ホーキンス)によってNumentaはHTM理論と実践的な開発に従事し、2005年に作成されました。ホーキンスの紹介によると、HTMは、目標と新皮質(新皮質)の機能を再現するために、最新の脳科学に基づく知識を持つニューラルネットワークモデルです。
最大で異なる既存のDNNは「シナプス」スイッチとメモリ多くの倍以上として「ニューロン」との間です。以前DNN、脇役の状態では、百せいぜい数、各ニューロンのシナプス機能に対応する部分では。数千の割り当てられた「ニューロン」にHTMの意志「シナプスを。」研究者は、脳が実際にそれぞれが約10,000シナプスを持つニューロンと信じています。
Numenta HTMアルゴリズムの性能特性をある提案:(1)既存のDNNと比較して、時系列データの処理にも強い能力を有する;(2)可能な(つまり、これらの時系列データを学習すると同時に推定することができます(3)同時に推論の数を実装することができ;「オンライントレーニング」)を達成(4)各タスクは、良好な結果を受け取るために微調整されません。大HTM「シナプス」は差別ロジックと記録時系列データの前後に使用されています。
HTMは最近、「皮質プロセッサ」プロジェクトの米国国防高等研究計画庁(DARPA)によって使用されてきた、いくつかの懸念を引き起こしました。Numentaは、その性能を確認し、競合技術と比較して3月に発表された最初の実用的な理論を()、導入しました。
急激な変化のデータが続きます
実験の平均自己回帰移動統合(ARIMA)、エクストリーム機械学習(ELM)、ロング短期記憶(LSTM)、エコー状態ネットワーク(ESN)および他の作業性能とHTMを比較することによって。具体的には、比較の精度は、ニューヨーク市のタクシーの乗客の数を予測します。
結果(図1の左側)の平均最小HTMの予測誤差、およびオンライントレーニング機能のおかげで、データ入力モードが途中で変更された場合でも、すぐに予測誤差(図1における右側)を低減するために学ぶことができることを示しています。LSTMは、予測誤差を減らすことではありません。
ホーキンスは私たちの最初の目標は、大脳皮質の新しいメカニズムを識別することである」と述べた。第二の目的は、ブリッジを行うために、神経科学や人工知能(AI)の間である。実験結果は、我々が今で動いていることを示しますこの目標を持ちます。」
ホワイトペーパーHTMアルゴリズム:https://numenta.com/assets/pdf/biological-and-machine-intelligence/zh-cn/BaMI-HTM-Overview.pdf 中国語の翻訳版は、あなたが見ることができます。