出典: ハート・オブ・ザ・マシン
NLP グループに入る —> NLP 交換グループに参加する
モデルが一定の規模に達すると創発現象が起こりますが、モデルを一定期間学習させると別の現象、つまり「理解」現象が現れることがGoogleの研究でわかっています。
2021 年、研究者は一連のミニチュア モデルをトレーニングする際に驚くべき発見をしました。つまり、長期間のトレーニングの後、最初は「トレーニング データを記憶する」だけであったモデルが、まったく記憶されなくなるまで変化します。このデータは、強力な一般化機能も示しています。
この現象を「グロッキング」といいますが、下図に示すように、モデルを学習データに長時間当てはめると、突然「グロッキング」という現象が現れるようになります。
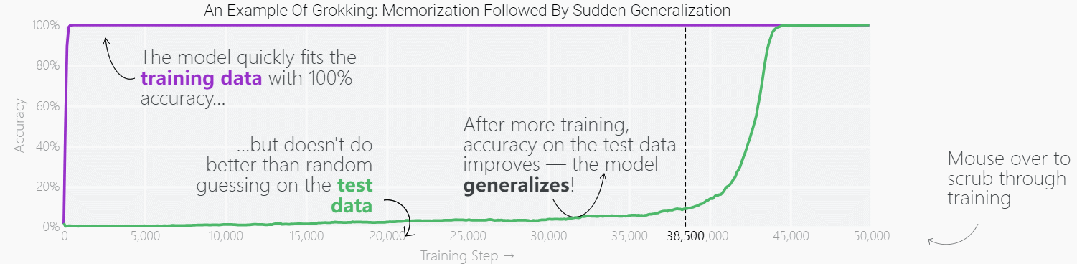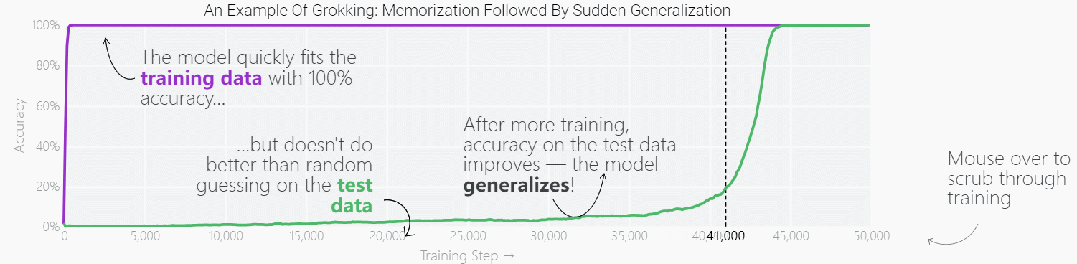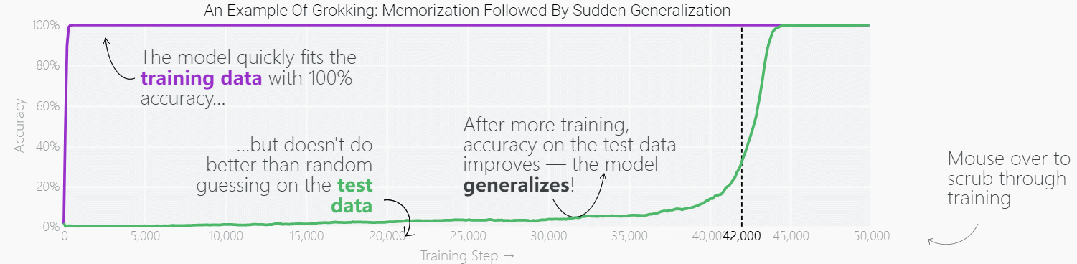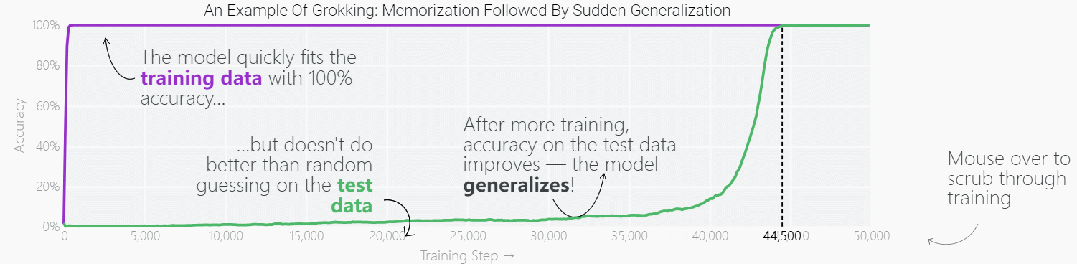
ミニチュアモデルにはこのような特徴があるので、より複雑なモデルは、より長いトレーニング期間を経て突然「理解」されるようになるのでしょうか?最近、大規模言語モデル (LLM) が急速に発展しています。LLM は世界を豊かに理解しているようです。多くの人は、LLM が記憶したトレーニング内容を繰り返しているだけだと考えています。この記述はどの程度正しいでしょうか? LLM が記憶を出力しているとどのように判断できますか?内容は?、それとも入力データに対して適切に一般化されていますか?
この問題をより深く理解するために、この記事の Google の研究者はブログを書き、大規模モデルの突然の「理解」現象の本当の理由を解明しようとしました。
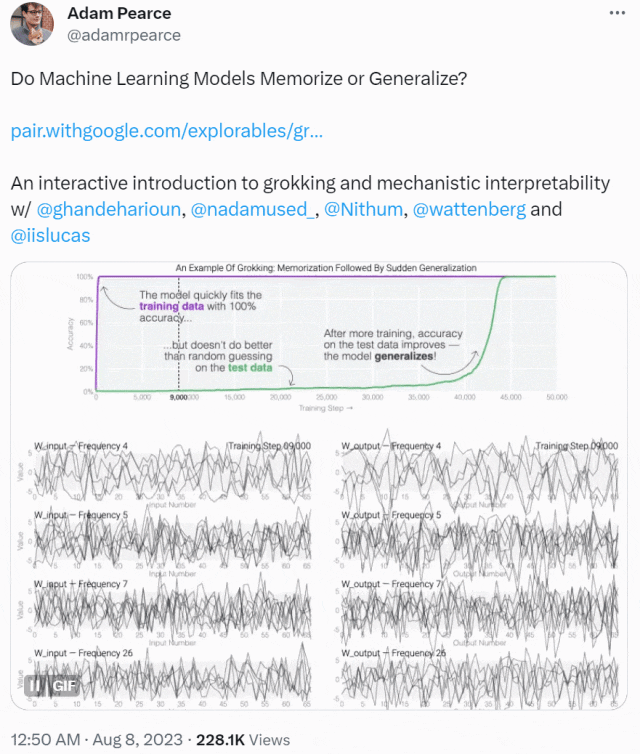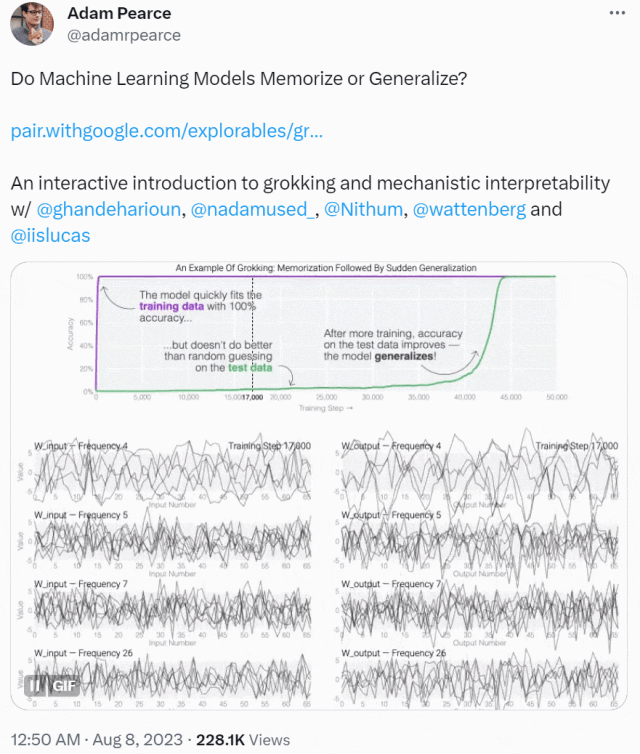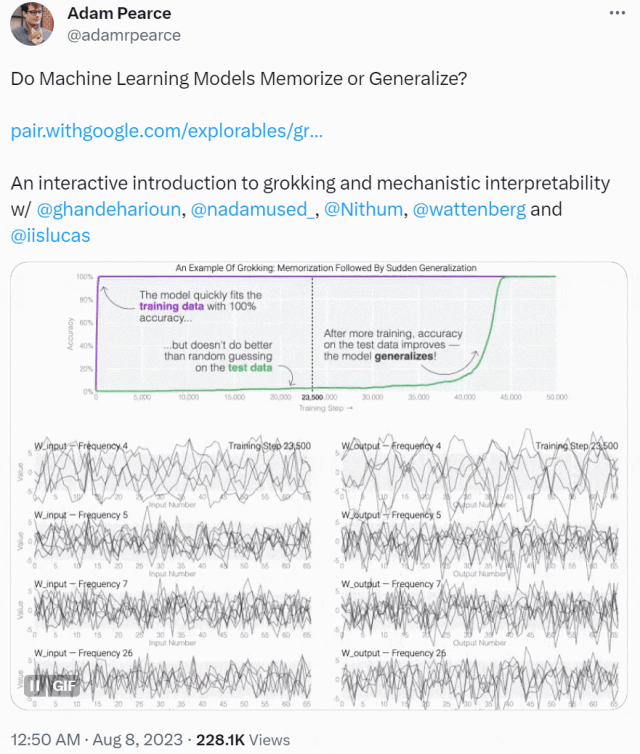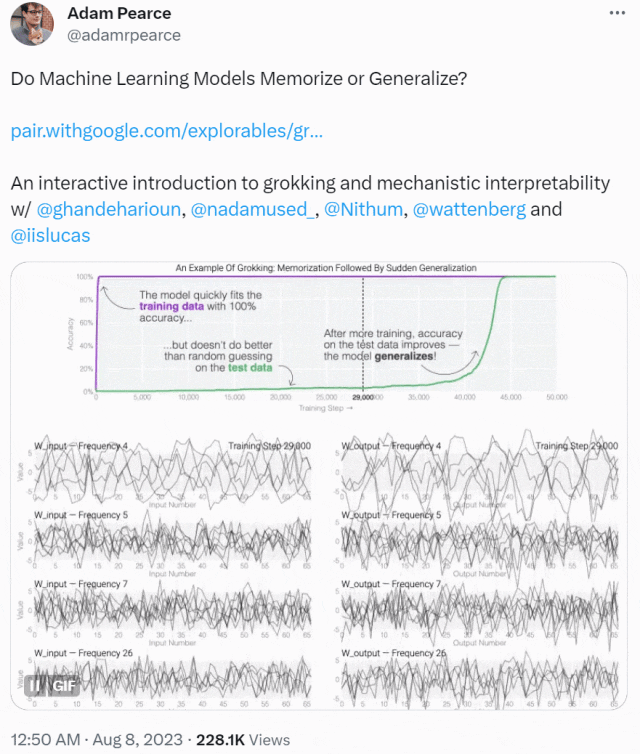
この記事は、ミニチュア モデルのトレーニング ダイナミクスから始まります。彼らは 24 個のニューロンを備えた単層 MLP を設計し、モジュール加算のタスクを実行する方法を学習するようにトレーニングしました。このタスクの出力が周期的であることだけを知っておく必要があります。 (a + b) mod n の形式。
MLP モデルの重みは次の図に示されており、最初はモデルの重みに非常にノイズが含まれていますが、時間が経過するにつれて周期性を示し始めることがわかります。

この周期性は、個々のニューロンの重みを視覚化するとさらに明白になります。

周期性を過小評価しないでください。重みの周期性は、モデルが特定の数学的構造を学習していることを示しており、これはモデルを記憶データから一般化能力に変換するための鍵でもあります。多くの人は、なぜモデルがデータ パターンの記憶からデータ パターンの一般化に変化するのか、この移行によって混乱しています。
01 シーケンスを試してみる
モデルが一般化しているのか記憶しているのかを判断するために、この研究では、30 個の 1 と 0 のランダムなシーケンスの最初の 3 桁に奇数の 1 があるかどうかを予測するようにモデルをトレーニングしました。たとえば、000110010110001010111001001011 は 0、010110010110001010111001001011 は 1 です。これは基本的に、干渉ノイズを伴う少し複雑な XOR 問題です。モデルが一般化している場合は、シーケンスの最初の 3 桁のみを使用する必要があります。モデルがトレーニング データを記憶している場合は、後続の桁も使用します。
この研究で使用されるモデルは、1200 シーケンスの固定バッチでトレーニングされた単層 MLP です。最初は、トレーニングの精度のみが向上します。つまり、モデルはトレーニング データを記憶します。モジュラー算術の場合と同様、テストの精度は本質的に確率的であり、モデルが一般的な解を学習するにつれて急激に上昇します。
なぜこれが起こるのかは、01 シーケンス問題の簡単な例を使用するとより簡単に理解できます。その理由は、モデルがトレーニング中に 2 つのこと、つまり損失を最小限に抑えることと重量減衰を行うためです。トレーニング損失は、正しいラベルの出力に関連する損失と引き換えに重みを低くするため、モデルが一般化する前に実際にはわずかに増加します。
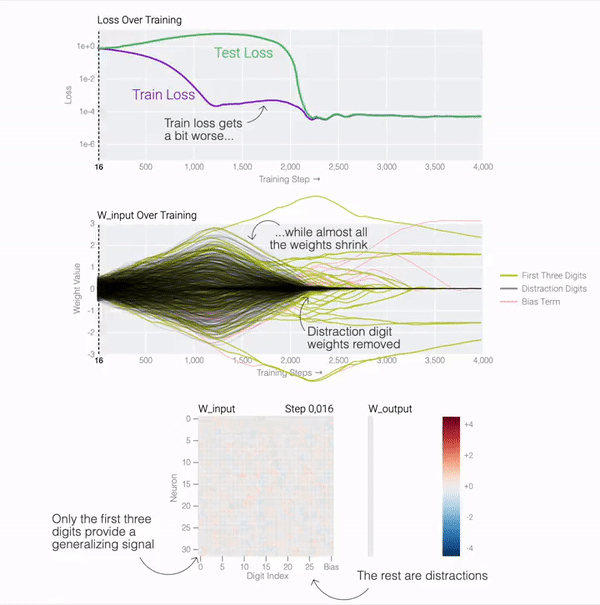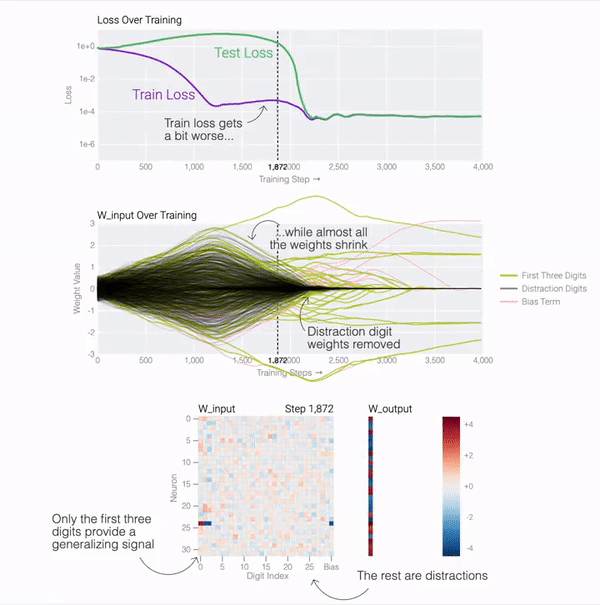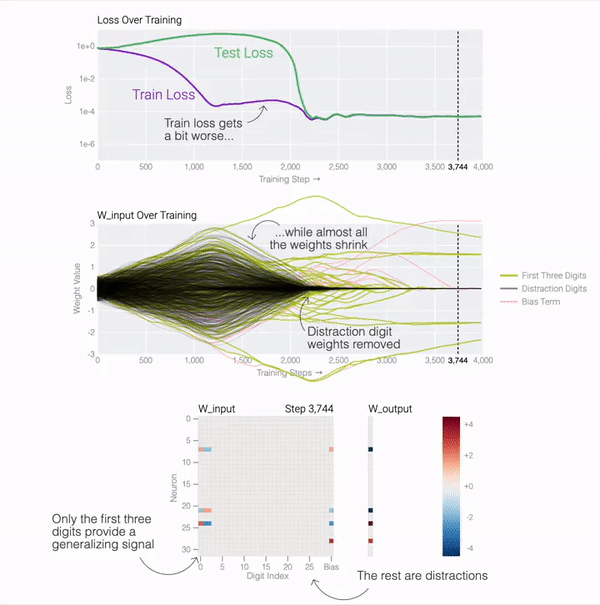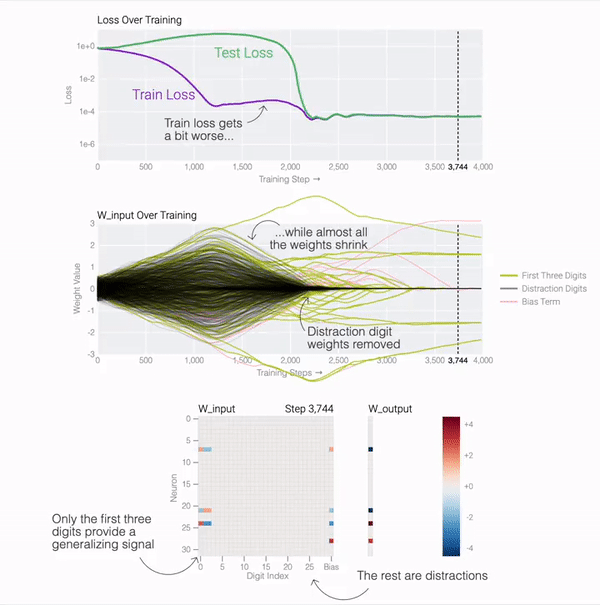
テスト損失が急激に低下しているため、モデルが突然一般化しているように見えますが、トレーニング中にモデルの重みを見ると、ほとんどのモデルは 2 つの解の間をスムーズに補間しています。後続の気を散らす数字に接続された最後の重みが重みの減衰によって枝刈りされると、高速一般化が発生します。
「理解」という現象はいつ起こったのでしょうか?
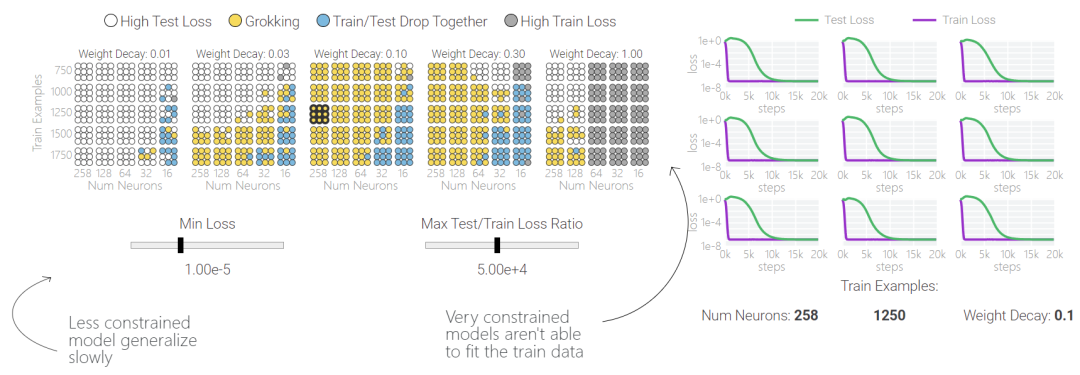
「グロッキング」は偶発的な現象であることに注意してください。モデルのサイズ、重みの減衰、データ サイズ、その他のハイパーパラメーターが適切でない場合、「グロッキング」現象は消えてしまいます。重みの減衰が小さすぎる場合、モデルはトレーニング データに過剰適合します。重みが減衰しすぎると、モデルは何も学習できなくなります。
以下の研究では、さまざまなハイパーパラメータを使用して 1 タスクと 0 タスクで 1000 を超えるモデルをトレーニングしています。トレーニング プロセスにはノイズが多いため、ハイパーパラメーターのセットごとに 9 つのモデルがトレーニングされます。青と黄色の 2 種類のモデルだけが「理解」現象を起こしていることがわかります。
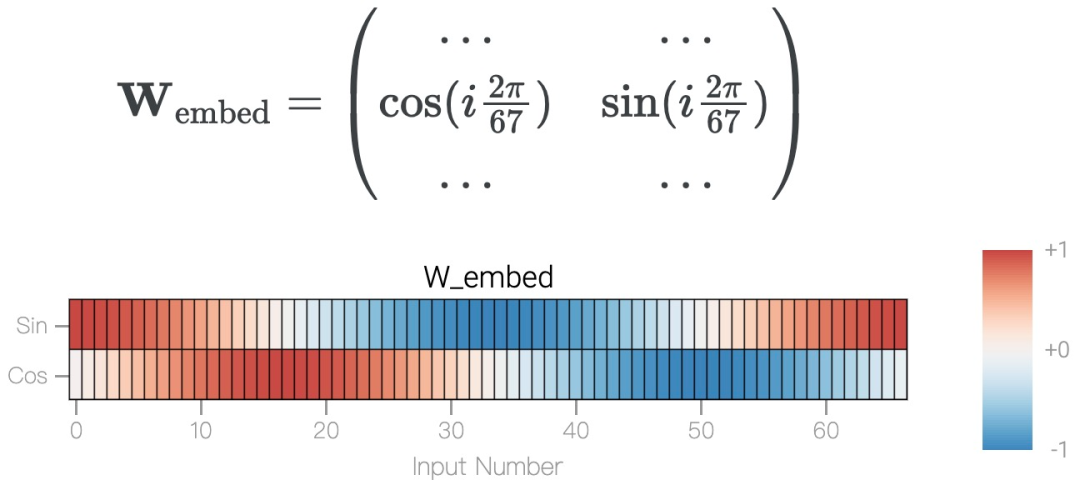
5 つのニューロンによるモジュール加算
モジュロ加算 a+b mod 67 は周期的で、合計が 67 を超えると、答えはラップ現象を引き起こします。これは円で表すことができます。問題を単純化するために、この研究では cos と sin を使用して a と b を円上に配置する埋め込み行列を構築し、次の形式で表します。
このモデルは、わずか 5 つのニューロンを使用して完全かつ正確に解を見つけていることがわかります。
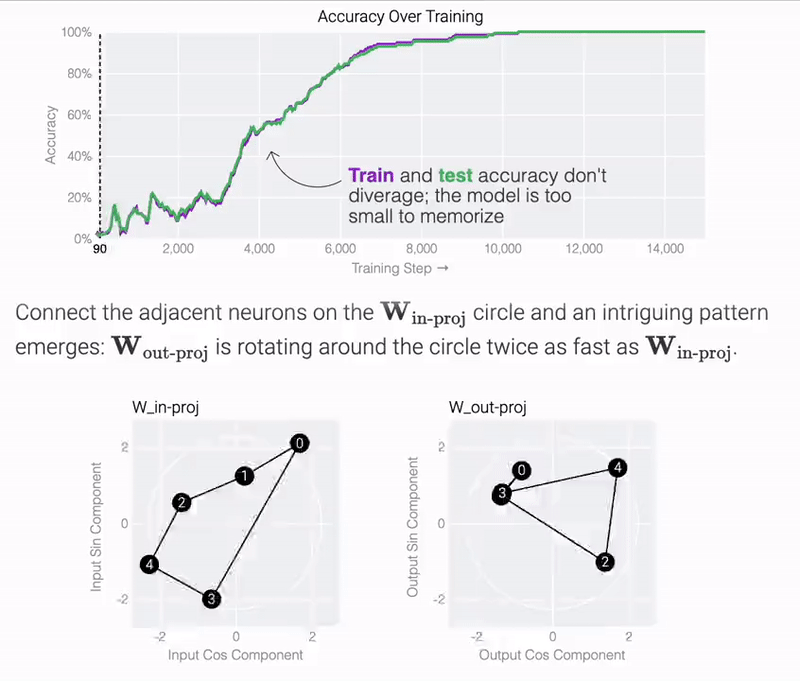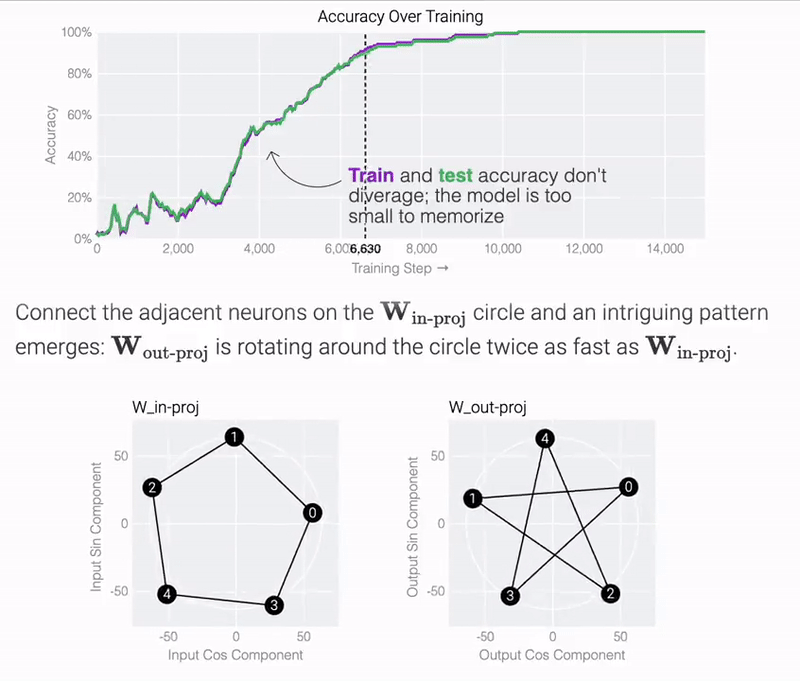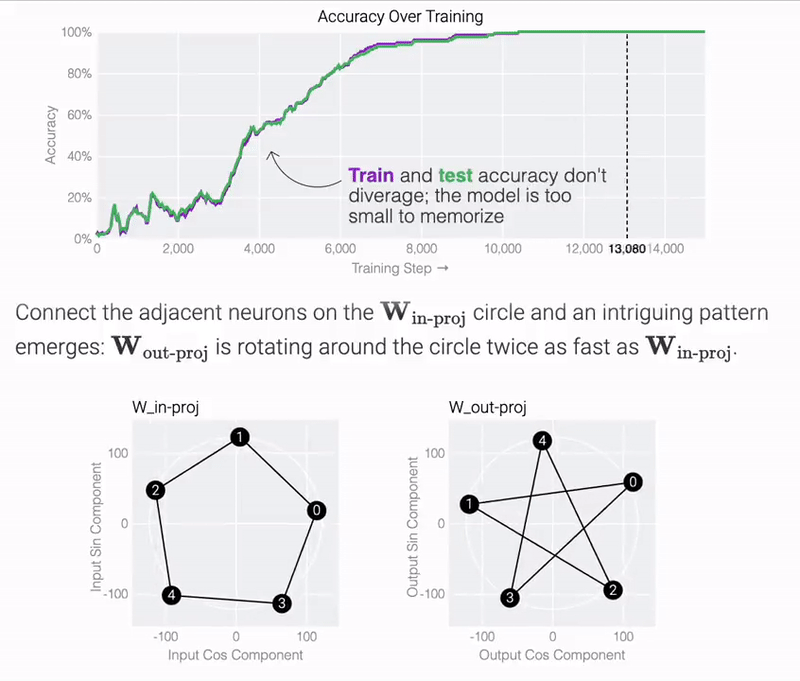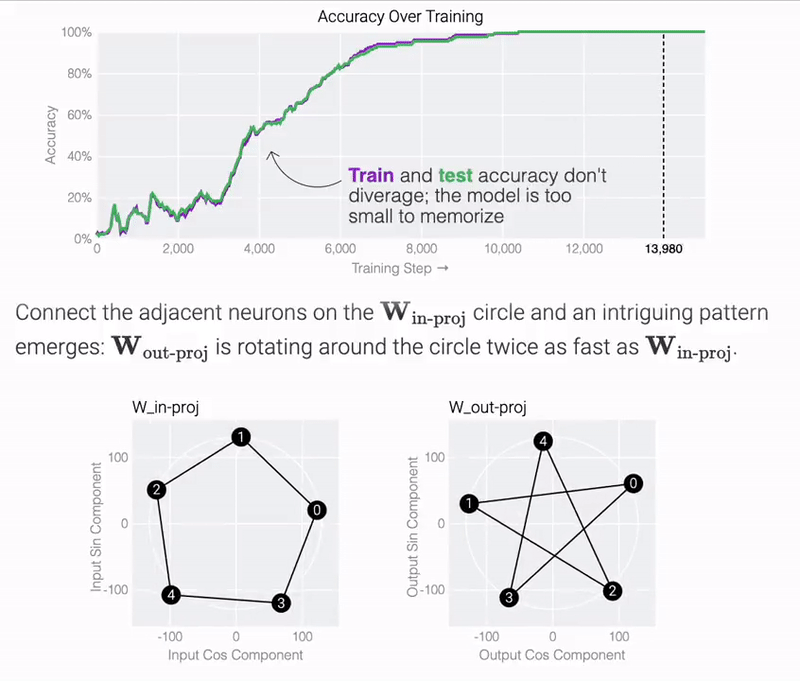
研究チームは、訓練されたパラメーターを観察すると、すべてのニューロンがほぼ同じ基準に収束していることを発見しました。cos 成分と sin 成分を直接プロットすると、それらは基本的に円上に均等に分布します。
次に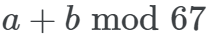 、周期性が組み込まれていない状態でゼロからトレーニングされており、モデルにはさまざまな周波数が含まれています。
、周期性が組み込まれていない状態でゼロからトレーニングされており、モデルにはさまざまな周波数が含まれています。

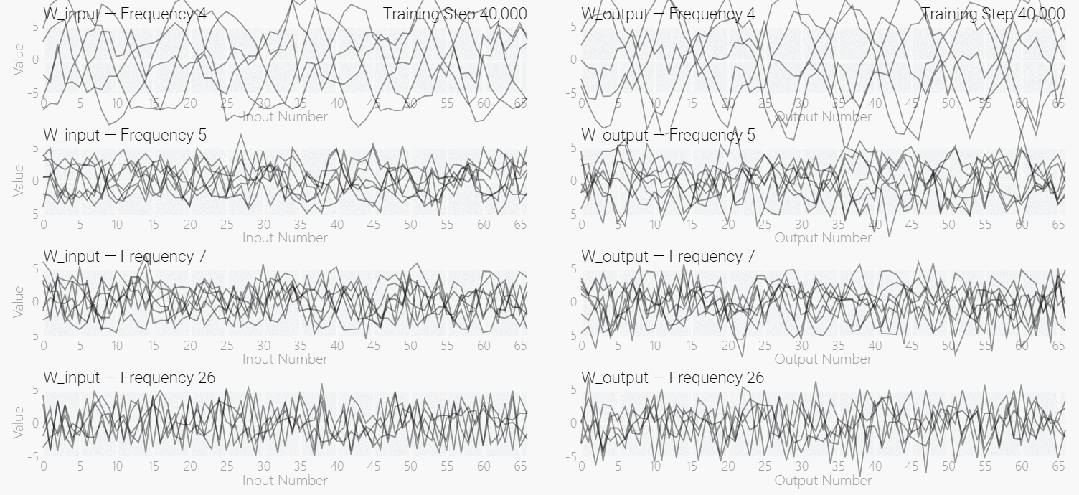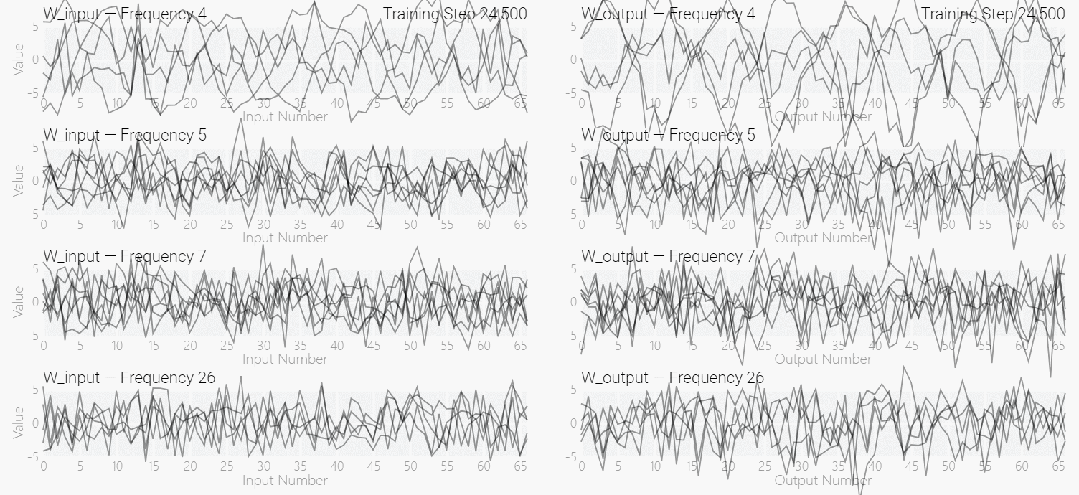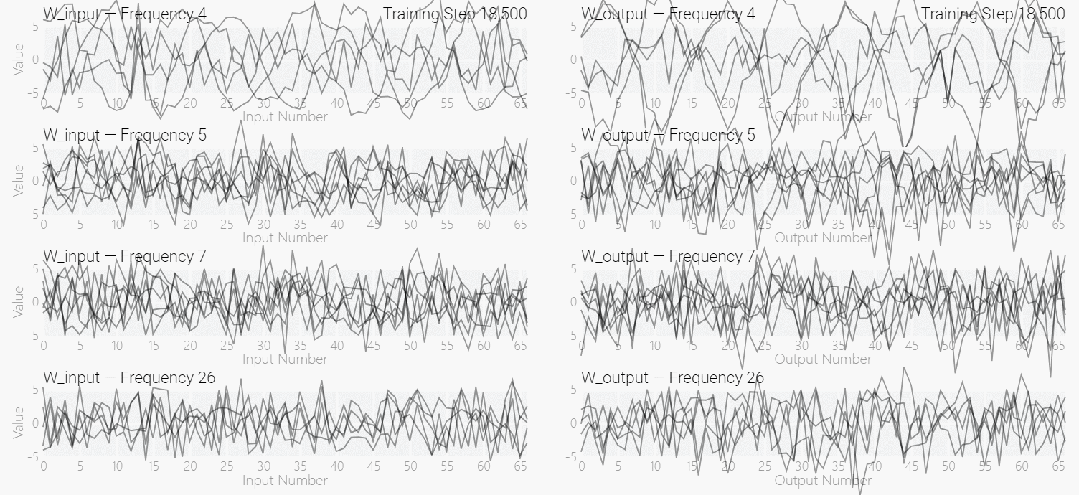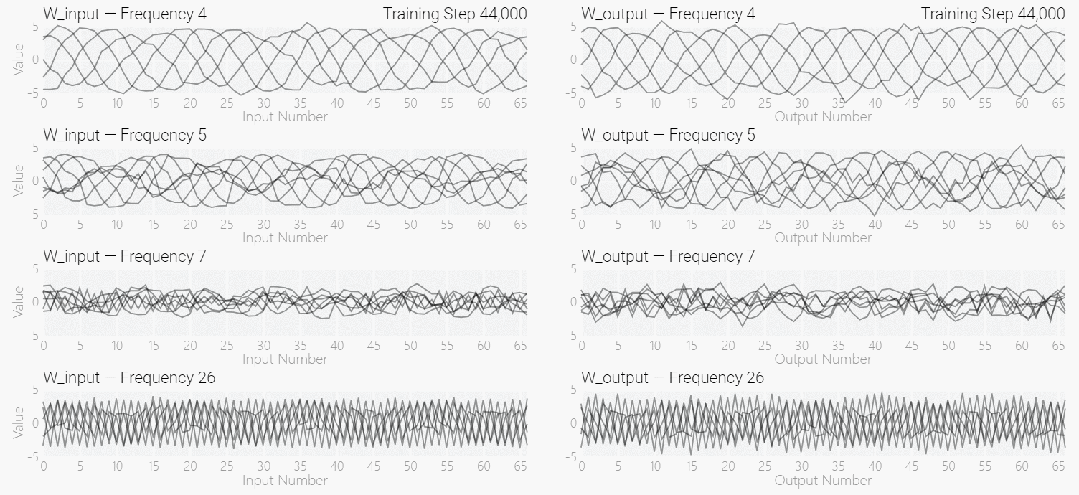
この研究では、離散フーリエ変換 (DFT) を使用して周波数を分離しました。1 と 0 のタスクと同様に、いくつかの重みだけが重要な役割を果たします。
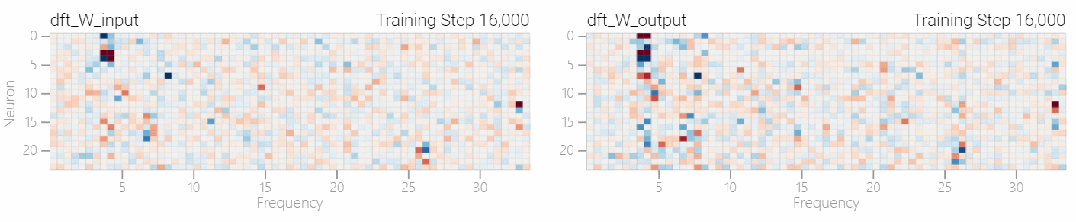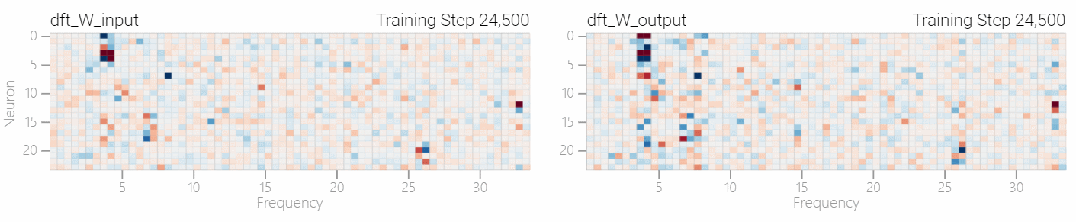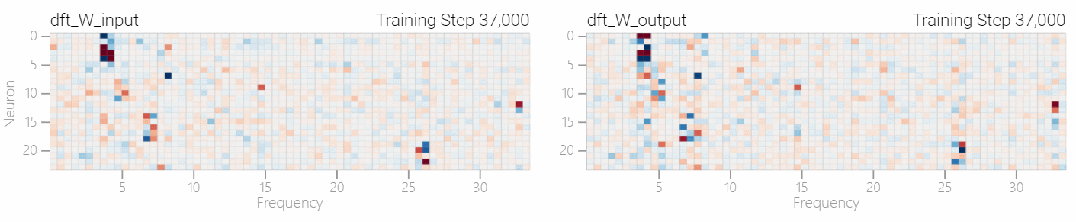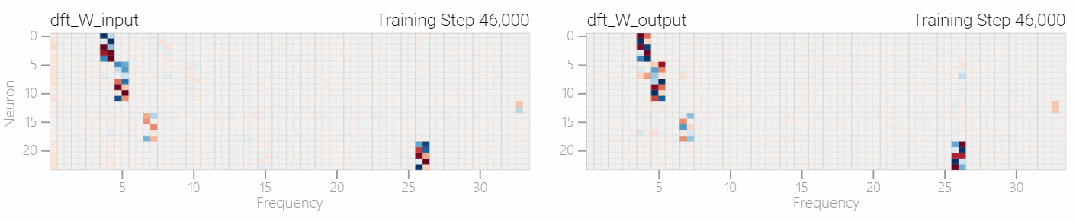
以下の図は、さまざまな周波数でもモデルが「理解」を達成できることを示しています。
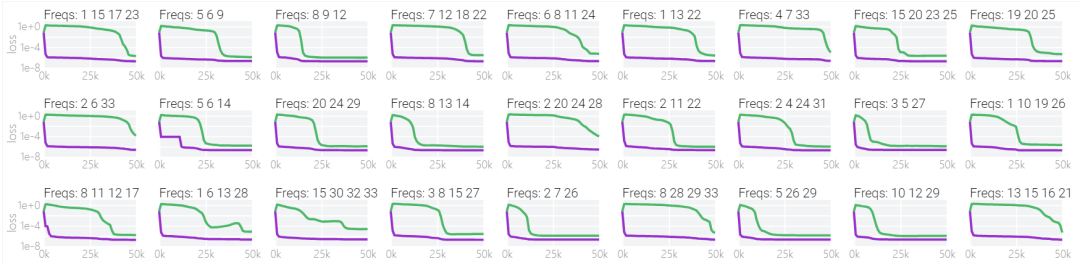
未解決の質問
これで、単層 MLP がモジュラー加算をどのように解決するか、およびトレーニング中にそれが発生する理由についてはしっかりと理解できましたが、記憶と一般化の観点からは、まだ多くの興味深い未解決の疑問が残っています。
どちらのモデルがより制約されていますか?
大まかに言えば、重みの減衰はさまざまなモデルをトレーニング データの記憶を避けるように導く可能性があります。過学習の回避に役立つその他の手法には、ドロップアウト、モデルのダウンサイジング、さらには数値的に不安定な最適化アルゴリズムなどがあります。これらの方法は複雑な非線形な方法で相互作用するため、どの方法が最終的に一般化を引き起こすかを事前に予測することは困難です。
また、ハイパーパラメータが異なると、改善が急激に遅くなります。
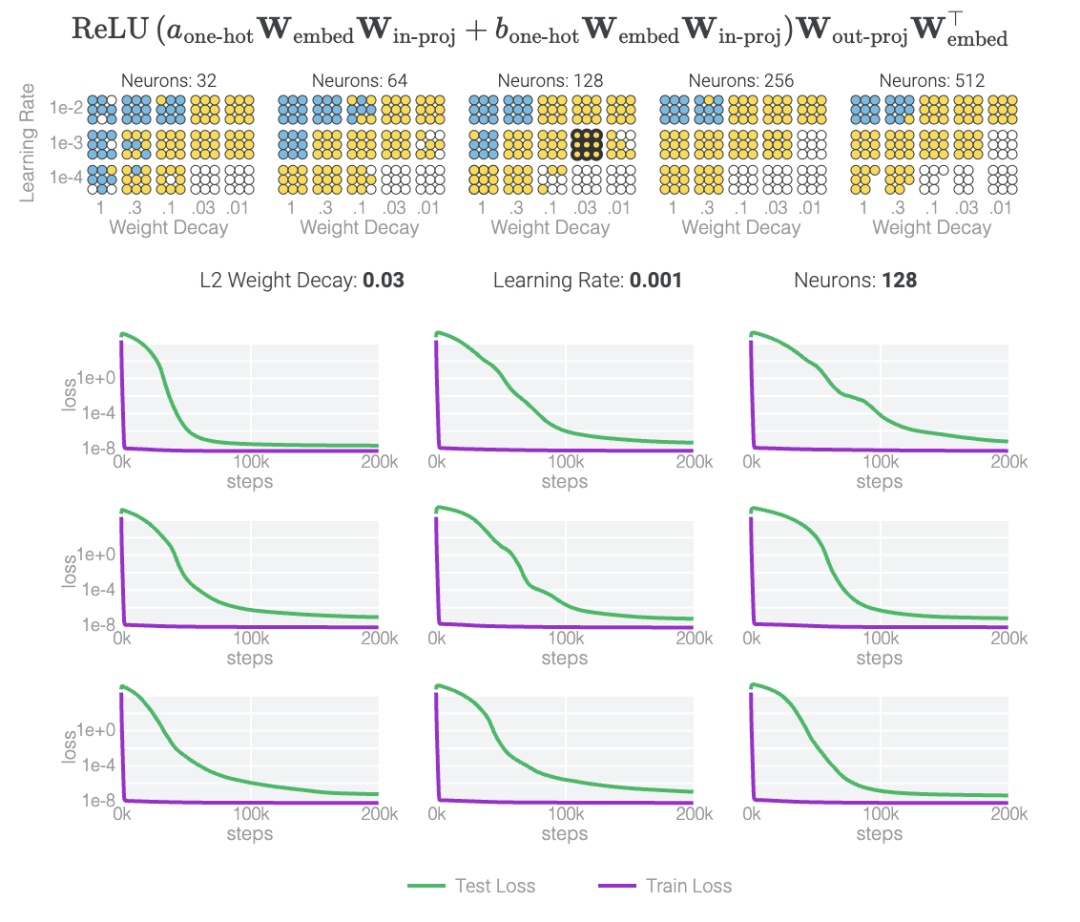
一般論より暗記のほうが簡単なのはなぜですか?
ある理論では、トレーニング セットを記憶するには一般化するよりも多くの方法があるのではないかということです。したがって、統計的には、特に正則化がない、またはほとんどない場合には、暗記が最初に起こる可能性が高くなります。重み減衰などの正則化手法は、特定のソリューションを優先します。たとえば、「密」なソリューションよりも「疎」なソリューションが優先されます。
研究によると、一般化は適切に構造化された表現と関連していることがわかっています。ただし、これは必須条件ではありません。対称入力を持たない一部の MLP バリアントは、モジュラー加算を解くときに学習する「循環的」表現が少なくなります。研究チームはまた、適切に構造化された表現が一般化の十分条件ではないことも発見しました。この小さなモデル (重み減衰なしでトレーニングされた) は一般化を開始し、再帰的に埋め込まれたメモリの使用に切り替わります。
在下图中可以看到,如果没有权重衰减,记忆模型可以学习更大的权重来减少损失。
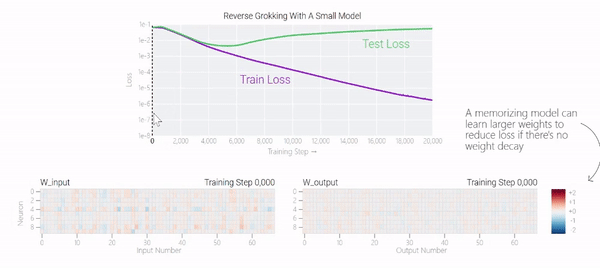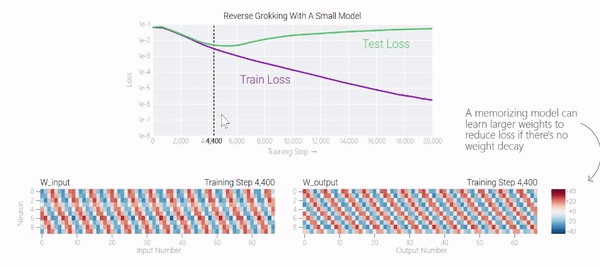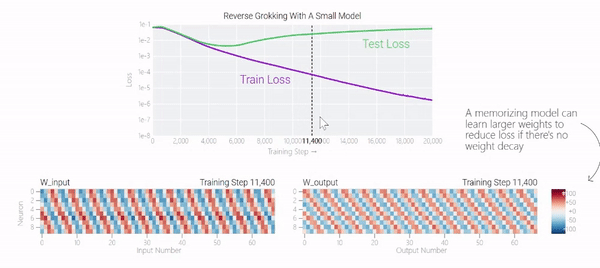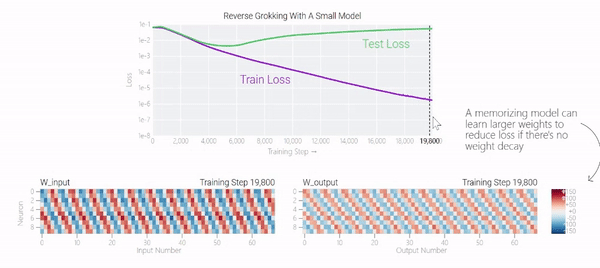
甚至可以找到模型开始泛化的超参数,然后切换到记忆,然后切换回泛化。
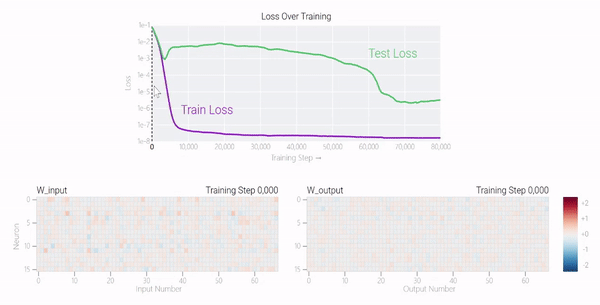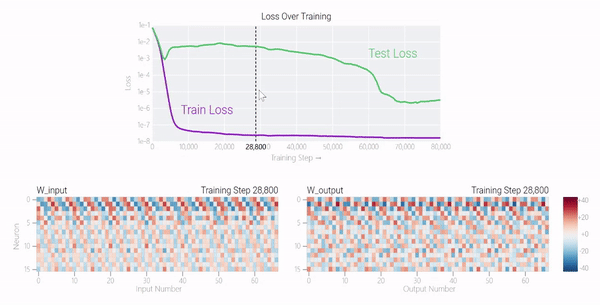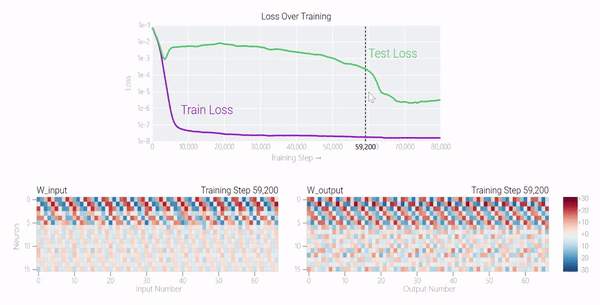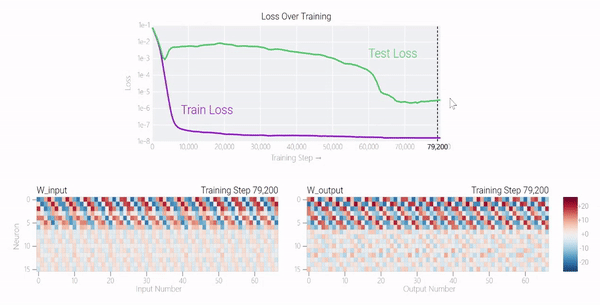
较大的模型呢?
理解模加法的解决方案并非易事。我们有希望理解更大的模型吗?在这条路上可能需要:
1) 训练更简单的模型,具有更多的归纳偏差和更少的运动部件。
2) 使用它们来解释更大模型如何工作的费解部分。
3) 按需重复。
研究团队相信,这可能是一种更好地有效理解大型模型的的方法,此外,随着时间的推移,这种机制化的可解释性方法可能有助于识别模式,从而使神经网络所学算法的揭示变得容易甚至自动化。
更多详细内容请阅读原文。
原文链接:https://pair.withgoogle.com/explorables/grokking/
进NLP群—>加入NLP交流群