イベント駆動型アーキテクチャ (EDA) は、効率的でスケーラブルなシステムをサポートするために、イベントの生成、検出、消費に焦点を当てたソフトウェア設計パターンです。EDA では、イベントはコンポーネント間の通信の主な手段であり、コンポーネントがリアルタイムで対話し、変更に応答できるようにします。このアーキテクチャは、疎結合、スケーラビリティ、応答性を促進し、最新の分散型の拡張性の高いアプリケーションに最適です。EDA は、最新のシステムにおける俊敏性とシームレスな統合のための強力なソリューションとして登場しました。
イベント駆動型アーキテクチャでは、イベントはシステム内の重要なイベントまたは変更を表し、ユーザーのアクション、システム プロセス、外部サービスなどのさまざまなソースによって生成される可能性があります。イベント プロデューサーと呼ばれるコンポーネントは、イベント配布の仲介者として機能する中央のイベント バスまたはブローカーにイベントを発行します。イベント コンシューマーと呼ばれる他のコンポーネントは、対象となる特定のイベントをサブスクライブし、それに応じて反応します。
EDA の主な利点は、俊敏性と柔軟性をサポートできることです。イベント駆動型システムのコンポーネントは独立して進化できるため、メンテナンス、更新、拡張性が容易になります。新しいイベント タイプを導入したり、既存のイベントをサブスクライブしたりすることで、システム全体に影響を与えることなく、新しい機能を追加できます。この柔軟性と拡張性により、EDA は動的で進化するビジネス ニーズに特に適しています。
EDA は、異なるシステムまたはサービス間のシームレスな統合も促進します。EDA は、通信メカニズムとしてイベントを使用することにより、基礎となるテクノロジーやプログラミング言語に関係なく相互運用性をサポートします。イベントは、システムが情報を交換するための標準化された疎結合の方法を提供し、企業が異種システムをより簡単に統合できるようにします。この統合アプローチにより、システム全体を中断することなくコンポーネントを接続または切断できるため、モジュール性と再利用性が促進されます。
EDA の主要コンポーネント: イベントのストリーミングと処理の有効化
EDA は、システム内のイベントのフローと処理をサポートするいくつかの主要なコンポーネントで構成されています。これらのコンポーネントは連携して、イベントの生成、配布、消費、処理を容易にします。EDA の主要なコンポーネントは次のとおりです。
(1) イベントプロデューサー
イベントプロデューサーは、イベントの生成と発行を担当します。これらは、ユーザー インターフェイス、アプリケーション、マイクロサービス、外部システムなど、システム内のさまざまなエンティティである可能性があります。イベント プロデューサーは、重要なイベントまたは変更をキャプチャし、イベント バスまたはブローカーにイベントを送信します。これらのイベントは、ユーザーのアクション、システム イベント、センサー データ、またはその他の関連ソースによってトリガーされる可能性があります。
(2) イベントバス/プロキシ
イベント バス/ブローカーは、イベントの中央通信チャネルとして機能します。イベントプロデューサーによって公開されたイベントを受信し、関心のあるイベントコンシューマーに配布します。イベント バス/ブローカーは、メッセージ キュー、パブリッシュ/サブスクライブ システム、または特殊なイベント ストリーミング プラットフォームにすることができます。信頼性の高いイベント配信を保証し、イベント プロデューサーをイベント コンシューマーから切り離し、非同期イベント処理をサポートします。
(3) イベントコンシューマ
イベント コンシューマは、特定のイベントまたは関心のあるイベントの種類をサブスクライブします。イベント バス/ブローカーからイベントを受信し、それに応じて処理します。イベント コンシューマは、マイクロサービス、ワークフロー、データ プロセッサなど、システム内のさまざまなコンポーネントにすることができます。ビジネス ロジックの実行、データの更新、さらなるアクションのトリガー、または他のシステムとの通信によってイベントに応答します。
(4) イベントハンドラ
イベント ハンドラは、イベント コンシューマが受信したイベントを処理します。これらには、イベントの内容に基づいて特定のアクションを実行するビジネス ロジックとルールが含まれています。イベント ハンドラーは、データ検証、状態変更、データベース更新、トリガー通知を実行したり、他のサービスを呼び出したりすることができます。これらは、特定のイベントに関連付けられた動作をカプセル化し、システム内での適切なイベント処理を保証します。
(5) イベントストレージ
イベント ストアは、システム内で発行されたすべてのイベントを記録し、イベントの履歴とそれに関連するデータを提供する永続的なデータ ストレージ コンポーネントです。イベント ストレージは、イベントの再生、監査、およびイベント ソーシング パターンをサポートし、システムが過去のイベントに基づいてその状態を再構築できるようにします。イベント駆動型アーキテクチャでのスケーラビリティ、フォールト トレランス、データの一貫性をサポートします。

これらの主要コンポーネントを利用することで、EDA はシステム内のイベントのスムーズなフロー、配信、および処理をサポートします。イベントプロデューサー、イベントバス/ブローカー、イベントコンシューマー、イベントハンドラー、およびイベントストアが連携して、リアルタイムのイベントドリブンインタラクションを処理し、変化するニーズに適応し、外部と統合できる、疎結合でスケーラブルで応答性の高いシステムを作成します。システムとかサービスとか。
EDA パターン: スケーラビリティと自律性のためのシステムの構築
EDA は、拡張性と自律性を実現するシステムの設計に役立ついくつかのパターンを提供します。これらのパターンは、多くのイベントを処理し、コンポーネントを分離し、独立した開発と展開をサポートする機能を強化します。EDA の主なパターンをいくつか次に示します。
(1) イベントトレーサビリティ
イベント ソーシングは、アプリケーションの状態が一連のイベントから派生するパターンです。アプリケーションの状態に対するすべての変更は、現在の状態を保存するのではなく、イベント ストア内の一連のイベントとしてキャプチャされます。アプリケーションは、これらのイベントを再生することでその状態を再構築できます。イベント ソーシングは完全なイベント履歴を提供し、きめ細かいクエリを実行できるようにし、イベント プロセッサを簡単に複製および拡張できるようにして、スケーラビリティと監査可能性を実現します。
(2) コマンドとクエリの責任の分離 (CQRS)
コマンドとクエリの責任の分離 (CQRS) は、読み取り操作と書き込み操作を別個のモデルに分離するパターンです。書き込みモデルはコマンド モデルとも呼ばれ、システムの状態を変更し、イベントを生成するコマンドを処理します。読み取りモデル (クエリ モデルと呼ばれる) はクエリを処理し、独自の最適化されたデータ ビューを更新します。CQRS を使用すると、読み取り操作と書き込み操作を個別にスケーリングできるようになり、特定のクエリのニーズに合わせて読み取りモデルを最適化することでパフォーマンスが向上し、各モデルを個別に進化させる柔軟性が提供されます。
(3) パブリッシュ/サブスクライブ
パブリッシュ/サブスクライブ パターンは、イベント プロデューサーをイベント コンシューマーから切り離すことにより、疎結合とスケーラビリティを実現します。このパターンでは、イベント プロデューサーは、どの特定のコンシューマーがイベントを受信するかを知らずに、中央のイベント バス/ブローカーにイベントを発行します。イベント コンシューマは、関心のある特定の種類のイベントをサブスクライブし、イベント バス/ブローカーはイベントを関連するサブスクライバに配布します。このパターンは、柔軟性、スケーラビリティ、およびイベント プロデューサーや他のコンシューマーに影響を与えることなくコンシューマーを追加または削除する機能をサポートします。
(4) イベント駆動型メッセージ
イベント駆動型メッセージングには、イベントベースのコンポーネント間のメッセージの交換が含まれます。非同期通信とコンポーネント間の疎結合をサポートします。このパターンでは、イベント プロデューサーがイベントをメッセージ キュー、トピック、またはイベント ハブに発行し、イベント コンシューマーがメッセージング インフラストラクチャからこれらのイベントを消費します。このパターンにより、コンポーネントが独立して動作できるようになり、システムのスケーラビリティが向上し、信頼性の高い非同期イベント処理がサポートされます。
これらのパターンを採用することにより、システムの構造はスケーラビリティと自律性を効果的に処理できます。イベント ソーシング、CQRS、パブリッシュ/サブスクライブ、およびイベント ドリブンのメッセージング パターンは、疎結合を促進し、コンポーネントの独立したスケーリングを可能にし、フォールト トレランスを提供し、パフォーマンスを向上させ、イベント ドリブン アーキテクチャでのシステムとサービスのシームレスな統合を可能にします。これらのパターンは、個々のコンポーネントの高度な自律性を維持しながら、大量のイベントを処理できる、回復力があり、スケーラブルで適応性のあるシステムを構築するのに役立ちます。
Kafka: リアルタイム データ ストリームとイベント駆動型アプリケーションをサポート
Kafka は、リアルタイム データ ストリームやイベント駆動型アプリケーションの構築に広く使用されている分散ストリーミング プラットフォームです。大量のデータを処理できるように設計されており、低遅延、スケーラブル、フォールトトレラントなストリーム処理を提供します。Kafka は、システム間のシームレスで信頼性の高いデータ フローをサポートし、イベント駆動型アーキテクチャを構築するための強力なツールとなります。
Kafka はその中核として、データがトピックに編成されるパブリッシュ/サブスクライブ モデルを使用します。イベント プロデューサーはトピックにデータを書き込み、イベント コンシューマーはこれらのトピックをサブスクライブしてリアルタイムでデータを受信します。Kafka のこの分離された性質により、イベントの非同期および分散処理が可能になり、アプリケーションが大量のデータを処理し、必要に応じて水平方向に拡張できるようになります。
Kafka の分散アーキテクチャは、フォールト トレランスと高可用性を提供します。複数のブローカー間でデータをレプリケートし、障害が発生した場合でもデータの耐久性とアクセス性を確保します。Kafka はデータのパーティショニングもサポートしており、複数のイベント コンシューマ間での並列処理と負荷分散が可能です。これにより、リアルタイム データ ストリームを処理する際の高スループットと低遅延が可能になります。
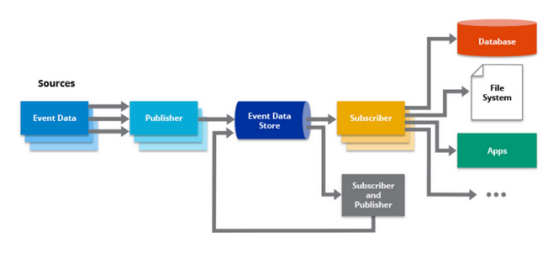
さらに、Kafka は、イベント駆動型アーキテクチャ エコシステムの他のコンポーネントと適切に統合されます。中央のイベント バスとして機能し、さまざまなサービスやシステム間のシームレスな統合と通信を可能にします。Kafka Connect は、さまざまなデータ ソースおよびシンクと統合するためのコネクタを提供し、統合プロセスを簡素化します。Kafka Streams は、Kafka 上に構築されたストリーム処理ライブラリであり、データ ストリームをリアルタイムで処理および変換できるため、複雑なイベント駆動型アプリケーションを簡単に構築できます。
Kafka EDA を構築するためのステップバイステップ ガイド
Kafka は、堅牢でスケーラブルな EDA の開発を可能にする強力なストリーミング プラットフォームとして登場しました。Kafka は、分散型、フォールト トレラント、高スループットの機能を備えているため、リアルタイム データ ストリームやイベント駆動型アプリケーションの構築に最適です。以下に、設計から実装まで Kafka EDA を構築する手順を示します。
ステップ 1: システム要件を定義する
最初のステップは、EDA の目標と要件を明確に定義することです。キャプチャする必要があるイベントのタイプ、必要なスケーラビリティとフォールト トレランス、特定のビジネス要件や制約を決定します。
ステップ 2: イベント ジェネレーターを設計する
イベントを生成するソースを特定し、それらのイベントを Kafka トピックに公開できるイベント プロデューサーを設計します。アプリケーション、サービス、システムのいずれであっても、イベントが適切に構造化され、関連するメタデータが含まれていることを確認してください。実装を簡素化するために、Kafka プロデューサー ライブラリまたはフレームワークの使用を検討してください。
プロデューサを作成するための Python コードの例:
Python
from kafka import KafkaProducer
# Kafka broker configuration
bootstrap_servers = 'localhost:9092'
# Create Kafka producer
producer = KafkaProducer(bootstrap_servers=bootstrap_servers)
# Define the topic to produce messages to
topic = 'test_topic'
# Produce a message
message = 'Hello, Kafka Broker!'
producer.send(topic, value=message.encode('utf-8'))
15
16 # Wait for the message to be delivered to Kafka
17 producer.flush()
18
19 # Close the producer
20 producer.close()
21ステップ 3: Kafka トピックを作成する
Kafka でトピックをイベント通信のチャネルとして定義します。予想される負荷とデータの要件に基づいて、トピック構造、パーティショニング戦略、レプリケーション係数、保持ポリシーを慎重に計画します。トピックがイベントの粒度と一貫していることを確認し、将来のスケーラビリティをサポートします。
ステップ 4: イベント コンシューマの設計
Kafka イベントを消費および処理するコンポーネントまたはサービスを特定します。関連トピックをサブスクライブし、リアルタイム処理を実行するイベント コンシューマーを設計します。必要なコンシューマの数を考慮し、それに応じてコンシューマ アプリケーションを設計します。
コンシューマを作成するための Python コードの例:
Python
from kafka import KafkaConsumer
# Kafka broker configuration
bootstrap_servers = 'localhost:9092'
# Create Kafka consumer
consumer = KafkaConsumer(bootstrap_servers=bootstrap_servers)
# Define the topic to consume messages from
topic = 'test_topic'
# Subscribe to the topic
consumer.subscribe(topics=[topic])
# Start consuming messages
for message in consumer:
# Process the consumed message
print(f"Received message: {message.value.decode('utf-8')}")
# Close the consumer
consumer.close()
ステップ 5: イベント処理ロジックを実装する
コンシューマ アプリケーションにイベント処理ロジックを作成します。これには、データ変換、エンリッチメント、集約、またはその他のビジネス固有の操作が含まれる場合があります。Kafka のコンシューマ グループ機能を活用して、処理負荷を複数のインスタンスに分散し、スケーラビリティを確保します。
ステップ 6: フォールト トレランスを確保する
フォールト トレラント メカニズムを実装し、障害を処理し、データの永続性を確保します。Kafka ブローカーに適切なレプリケーション係数を構成して、データの冗長性を提供します。コンシューマ アプリケーションにエラー処理と再試行のメカニズムを実装して、例外的な状況を処理します。
ステップ 7: パフォーマンスを監視および最適化する
監視ツールと可観測性ツールをセットアップして、Kafka クラスターとイベント駆動型アプリケーションの健全性とパフォーマンスを追跡します。スループット、レイテンシ、コンシューマーレイテンシなどの主要な指標を監視して、ボトルネックを特定し、システムを最適化します。Kafka の組み込み監視機能を活用するか、サードパーティの監視ソリューションと統合することを検討してください。
ステップ 8: ダウンストリーム システムとの統合
イベント駆動型アーキテクチャが下流のシステムまたはサービスとどのように統合されるかを決定します。Kafka から他のシステムへのシームレスなデータ フローを可能にするコネクタまたはアダプターを設計します。外部データ ソースまたはシンクと統合するための強力なツールである Kafka Connect を探索してください。
ステップ 9: テストと反復
EDA は、信頼性、拡張性、パフォーマンスを保証するために徹底的にテストされています。負荷テストを実行して、さまざまなワークロード下でのシステムの動作を検証します。テスト結果と実際のフィードバックに基づいて設計を繰り返し、改善します。
ステップ 10: 拡張と進化
システムが成長するにつれて、そのパフォーマンスを監視し、それに応じて拡張します。Kafka ブローカーを追加したり、パーティショニング戦略を調整したり、増加したデータ量を処理するためにコンシューマ アプリケーションを最適化したりできます。
Kafka EDA の使用例
Kafka EDA は、高スループット、フォールトトレラント、およびリアルタイムのデータ ストリームを処理できるため、さまざまな分野でさまざまなアプリケーションがあります。Kafka が優れている一般的な使用例をいくつか示します。
リアルタイムのデータ処理と分析: Kafka は、大量のリアルタイム データ ストリームを処理できるため、大規模なデータの処理と分析に最適です。ユーザーは、複数のソースから Kafka トピックにデータを取り込み、Apache Flink、Apache Spark、Kafka Streams などのストリーミング フレームワークを使用してリアルタイムでデータを処理および分析できます。このユースケースは、リアルタイムの不正検出、IoT デバイスの監視、クリックストリーム分析、パーソナライズされた推奨事項などのシナリオで価値があります。
- イベント駆動型のマイクロサービス アーキテクチャ: Kafka はマイクロサービス アーキテクチャの通信バックボーンとして機能し、さまざまなサービスがイベントを通じて通信します。各マイクロサービスはイベント プロデューサーまたはコンシューマーとして機能し、疎結合でスケーラブルなアーキテクチャを実現します。Kafka は信頼性の高い非同期イベント配信を保証し、サービスが独立して動作し、独自のペースでイベントを処理できるようにします。このユースケースは、スケーラブルで分離されたシステムの構築に役立ち、マイクロサービスベースのアプリケーションの俊敏性と自律性を実現します。
- ログ集約とストリーム処理: Kafka の耐久性と耐障害性により、Kafka はログ集約とデータ ストリーム処理に最適です。ログ イベントを Kafka トピックに公開することで、ユーザーはさまざまなシステムからのログを一元管理し、リアルタイム分析を実行したり、将来の監査、デバッグ、またはコンプライアンスの目的でログを保存したりできます。Kafka と Elasticsearch や Apache Hadoop エコシステムなどのツールとの統合により、効率的なログのインデックス作成、検索、分析が可能になります。
- メッセージングとデータの統合: Kafka のパブリッシュ/サブスクライブ モデルと分散型の性質により、Kafka はさまざまなアプリケーションやシステムを統合するための信頼できるメッセージング システムになります。システム間でメッセージを転送するためのデータ バスとして機能し、分離された非同期通信をサポートします。Kafka 用のコネクタを使用すると、リレーショナル データベース、Hadoop、クラウド ストレージなどの他のデータ システムとのシームレスな統合が可能になり、データ パイプラインや ETL プロセスがサポートされます。
- モノのインターネット:フォールトトレラントかつスケーラブルな方法で大量のストリーミング データを処理する Kafka の機能は、IoT アプリケーションに最適です。IoT デバイスからリアルタイムでデータを取得して処理できるため、リアルタイムの監視、異常検出、アラートが可能になります。Kafka はレイテンシが低いため、高速な応答時間とリアルタイムの洞察が重要な IoT ユースケースに最適です。
これらは、Kafka EDA を適用できる幅広いユースケースのほんの一例です。その柔軟性、拡張性、耐障害性により、ストリーミング データを処理し、リアルタイムのイベント駆動型アプリケーションを構築するための多用途のプラットフォームになります。
関連コンテンツの拡充:(技術フロンティア)
伝統的な企業でも大規模なデジタル化が始まったこの10年で、社内ツールの開発過程では、大量のページ、シーン、コンポーネントなどが常に繰り返されていることが分かりました。このホイールはエンジニアにとって多くの時間を無駄にしました。
このような問題に対応して、ローコードでは、特定の繰り返し発生するシナリオとプロセスを個別のコンポーネント、API、データベース インターフェイスに視覚化し、ホイールの繰り返し作成を回避します。プログラマーの生産性が大幅に向上しました。
ローコード テクノロジーをまだ理解していない場合は、公式 Web サイト: https://www.jnpfsoft.com/?csdnを体験して、すぐに体験して学ぶことができます。
プログラマーが知っておくべきソフトウェア JNPF 高速開発プラットフォームを推奨します。業界をリードする SpringBoot マイクロサービス アーキテクチャを採用し、SpringCloud モードをサポートし、プラットフォーム拡張の基盤を改善し、迅速なシステム開発、柔軟な拡張、シームレスな統合、高度なニーズを満たします。パフォーマンスアプリケーションなどの包括的な機能。フロントエンドとバックエンドの分離モードを採用し、フロントエンドとバックエンドの開発者が協力して異なるセクションを担当できるため、手間が省け便利です。
結論は
Kafka EDA は、ユーザーがデータ ストリームを処理し、リアルタイム アプリケーションを構築する方法に革命をもたらしました。高スループットでフォールトトレラントなデータ ストリームを処理する能力により、Kafka はスケーラブルで分離されたシステムをサポートし、それによって柔軟性、自律性、およびスケーラビリティを強化します。リアルタイム データ処理、マイクロサービス通信、ログ集約、メッセージ統合、または IoT アプリケーションのいずれであっても、Kafka の信頼性、拡張性、シームレスな統合機能により、Kafka はリアルタイムの洞察を促進し、ユーザーがデータの価値。