著者: ハン・シャンジエ
データベンドクラウド研究開発エンジニア

Kafka Connect の概要
Kafka Connect は、Apache Kafka® と他のデータ システム間のデータのスケーラブルで信頼性の高いストリーミングのためのツールです。Kafka 内外のデータの移動を標準化することで、Kafka で大規模なデータ セットを転送するためのコネクタを迅速に定義することが簡単になり、大規模なリアルタイム データ パイプラインの構築が容易になります。
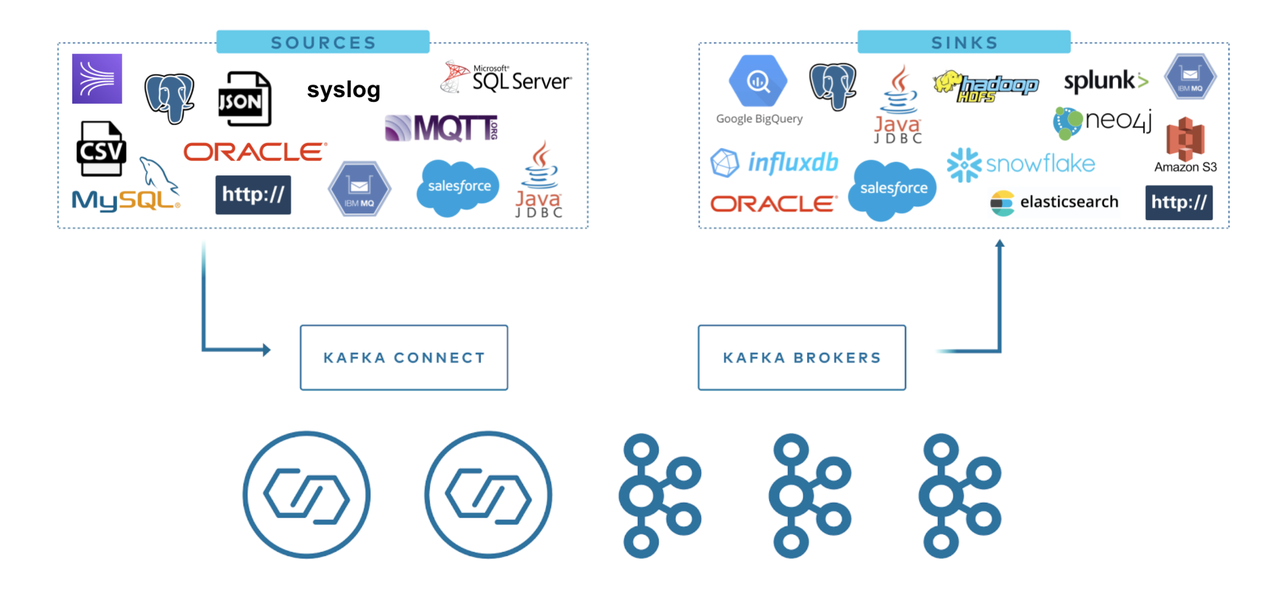
Kafka コネクタを使用して、新しいコードを開発することなく、外部システムの読み取りまたは書き込み、データ フローの管理、システムの拡張を行います。Kafka Connect は、他のシステムに接続する際のすべての一般的な問題 (スキーマ管理、フォールト トレランス、並列処理、レイテンシ、配信セマンティクスなど) を管理します。各コネクタは、ターゲット システムと Kafka の間でデータをコピーする方法のみに焦点を当てています。
Kafka コネクタは通常、データ パイプラインの構築に使用され、一般に 2 つの使用シナリオがあります。
-
開始エンドポイントと終了エンドポイント:たとえば、Kafka から Databend データベースにデータをエクスポートしたり、Mysql データベースから Kafka にデータをインポートしたりします。
-
データ送信の仲介:たとえば、大量のログ データを Elasticsearch に保存するには、まずログ データを Kafka に転送し、次に Kafka から Elasticsearch にデータをインポートして保存します。Kafka コネクタは、データ パイプラインの各ステージのバッファとして機能し、コンシューマ プログラムとプロデューサー プログラムを効果的に分離できます。
Kafka Connect は 2 つのタイプに分類されます。
- Source Connect: Kafka へのデータのインポートを担当します。
- シンク接続: Kafka システムからターゲット テーブルへのデータのエクスポートを担当します。
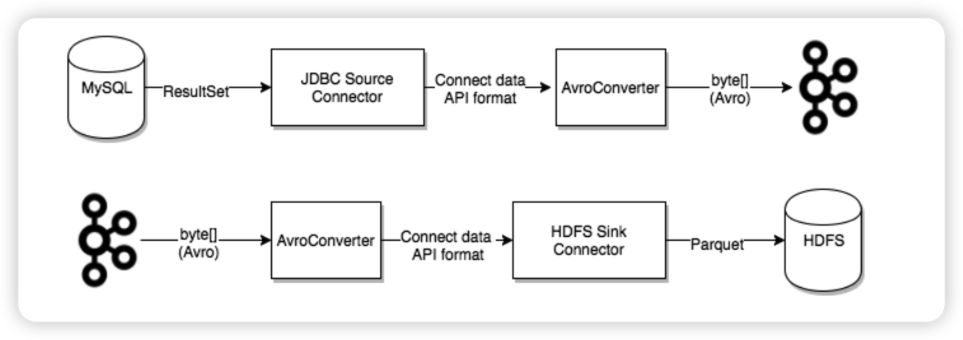
データベンド Kafka Connect
Kafka は現在、Elasticsearch Service Sink Connector、Amazon Sink Connector、HDFS Sinkなど、何百ものコネクタをConfluent Hub上に提供しています。ユーザーはこれらのコネクタを使用して、Kafka を中心とする任意のシステム間にデータ パイプラインを構築できます。Now we also offer Kafka Connect Sink Plugin for Databend . この記事では、MySQL JDBC Source Connector とDatabend Sink Connectorを使用してリアルタイム データ同期パイプラインを構築する方法を紹介します。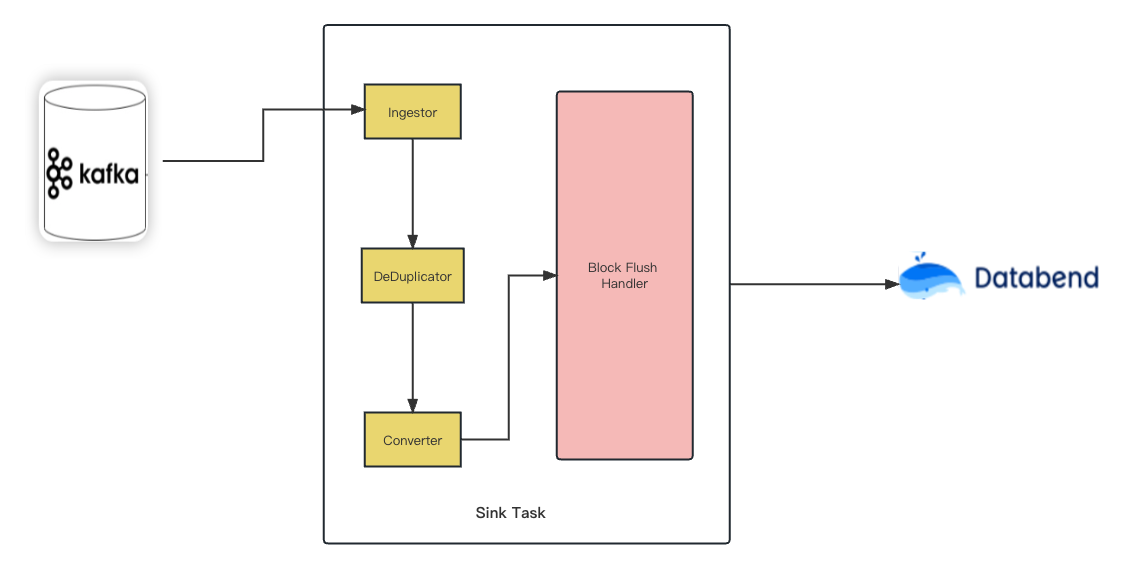
Kafka Connectを開始する
この記事では、Apache Kafka がオペレーティング マシンにインストールされていることを前提としています。ユーザーが Apache Kafka をインストールしていない場合は、Kafka クイックスタートを参照してインストールしてください。
Kafka Connect は現在、スタンドアロン モードと分散モードの 2 つの実行モードをサポートしています。
起動モード
スタンドアロンモード
スタンドアロン モードでは、すべての作業が 1 つのプロセスで実行されます。このモードは構成と開始が簡単ですが、フォールト トレランスなど、Kafka Connect のいくつかの重要な機能を最大限に活用できません。次のコマンドを使用してスタンドアロン プロセスを開始できます。
bin/connect-standalone.sh config/connect-standalone.properties connector1.properties [connector2.properties ...]
最初のパラメータ config/connect-standalone.properties はワーカー構成です。これには、Kafka 接続パラメーター、シリアル化形式、オフセット送信の頻度などの構成が含まれます。
bootstrap.servers=localhost:9092
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.file.filename=/tmp/connect.offsets
offset.flush.interval.ms=10000
以下の設定は、起動するコネクタを指定するパラメータです。上記のデフォルト構成は、config/server.properties で提供されるデフォルト構成で実行されているローカル クラスター用です。別の構成を使用する場合、または実稼働環境にデプロイする場合は、デフォルト構成を調整する必要があります。ただし、何があっても、すべてのワーカー (独立および分散) には何らかの構成が必要です。
-
bootstrap.servers:このパラメータには、Connect と連携するブローカー サーバーがリストされます。コネクタはこれらのブローカーにデータを書き込むか、ブローカーからデータを読み取ります。クラスター内のすべてのブローカーを指定する必要はありませんが、少なくとも 3 つを指定することをお勧めします。
-
key.converter および value.converter:メッセージ キーとメッセージ値に使用されるコンバーターをそれぞれ指定します。Kafka Connect 形式と Kafka に書き込まれたシリアル化形式の間で変換するために使用されます。これは、Kafka に書き込まれる、または Kafka から読み取られるメッセージのキーと値の形式を制御します。これはコネクタとは関係がないため、任意のコネクタを任意のシリアル化形式で使用できます。デフォルトでは、Kafka が提供する JSONConverter が使用されます。一部のコンバータには、特定の構成パラメータも含まれています。たとえば、key.converter.schemas.enable を true または false に設定することで、JSON メッセージにスキーマが含まれるかどうかを指定します。
-
offset.storage.file.filename:オフセット データの保存に使用されるファイル。
これらの構成パラメーターを使用すると、Kafka Connect プロデューサーとコンシューマーが構成、オフセット、およびステータスのトピックにアクセスできるようになります。Kafka Source タスクで使用されるプロデューサーと Kafka Sink タスクで使用されるコンシューマーを構成するには、同じパラメーターを使用できますが、それぞれ「Producer.」および「Consumer.」プレフィックスを追加する必要があります。bootstrap.servers は、プレフィックスを必要としない唯一の Kafka クライアント パラメーターです。
分散モード
分散モードでは、ワークロードのバランスが自動的に調整され、動的にスケールアップ (またはダウン) してフォールト トレランスを提供できます。分散モードの実行はスタンドアロン モードと非常に似ています。
bin/connect-distributed.sh config/connect-distributed.properties
違いは、起動されるスクリプトと構成パラメータにあります。分散モードでは、connect-standalone.sh の代わりに connect-distributed.sh を使用します。最初のワーカー構成パラメーターは、config/connect-distributed.properties 構成ファイルを使用します。
bootstrap.servers=localhost:9092
group.id=connect-cluster
key.converter.schemas.enable=true
value.converter.schemas.enable=true
offset.storage.topic=connect-offsets
offset.storage.replication.factor=1
#offset.storage.partitions=25
config.storage.topic=connect-configs
config.storage.replication.factor=1
status.storage.topic=connect-status
status.storage.replication.factor=1
#status.storage.partitions=5
offset.flush.interval.ms=10000
Kafka Connect は、オフセット、構成、およびタスクのステータスを Kafka トピックに保存します。必要なパーティション数とレプリケーション係数を達成するには、オフセット、構成、およびステータスのトピックを手動で作成することをお勧めします。Kafka Connect の開始時にトピックが作成されていない場合、トピックはデフォルトのパーティション数とレプリケーション係数を使用して自動的に作成されますが、これはアプリケーションには適していない可能性があります。クラスターを開始する前に、次のパラメーターを構成することが重要です。
-
group.id: Connect クラスターの一意の名前。デフォルトは connect-cluster です。同じグループ ID を持つワーカーは、同じ Connect クラスターに属します。これはコンシューマ グループ ID と競合できないことに注意してください。
-
config.storage.topic:コネクタとタスクの構成を保存するために使用されるトピック。デフォルトは connect-configs です。これは、パーティションが 1 つだけで、高レプリケーションと圧縮が必要なトピックであることに注意してください。自動的に作成されたトピックには複数のパーティションが含まれているか、圧縮されずに削除されるように自動的に構成されている可能性があるため、構成が正しいことを確認するためにトピックを手動で作成する必要がある場合があります。
-
offset.storage.topic:オフセットの保存に使用されるトピック。デフォルトは connect-offsets です。このトピックには複数のパーティションを含めることができます。
-
status.storage.topic:ステータスの保存に使用されるトピック。デフォルトは connect-status です。このトピックには複数のパーティションを含めることができます。
分散モードでは、コネクタは REST API を通じて管理する必要があることに注意してください。
例えば:
GET /connectors – 返回所有正在运行的connector名。
POST /connectors – 新建一个connector; 请求体必须是json格式并且需要包含name字段和config字段,name是connector的名字,config是json格式,必须包含你的connector的配置信息。
GET /connectors/{name} – 获取指定connetor的信息。
GET /connectors/{name}/config – 获取指定connector的配置信息。
PUT /connectors/{name}/config – 更新指定connector的配置信息。
コネクタの構成
MySQL ソース コネクタ
- MySQL ソース コネクタ プラグインをインストールする
ここでは、Confluent が提供する JDBC ソース コネクタを使用します。
Kafka Connect JDBCプラグインをConfluent ハブからダウンロードし、zip ファイルを /path/kafka/libs ディレクトリに抽出します。
- MySQL JDBC ドライバーをインストールする
コネクタはデータベースと通信する必要があるため、JDBC ドライバーも必要です。JDBC コネクタ プラグインには MySQL ドライバーが組み込まれていないため、ドライバーを個別にダウンロードする必要があります。MySQL は、多くのプラットフォーム用のJDBC ドライバーを提供します。[プラットフォームに依存しない] オプションを選択し、圧縮された TAR ファイルをダウンロードします。このファイルには、JAR ファイルとソース コードが含まれています。この tar.gz ファイルの内容を一時ディレクトリに抽出します。jar ファイル (mysql-connector-java-8.0.17.jar など) とこの JAR ファイルのみを、libskafka-connect-jdbc jar ファイルと同じディレクトリにコピーします。
cp mysql-connector-j-8.0.32.jar /opt/homebrew/Cellar/kafka/3.4.0/libexec/libs/
- 配置 MySQL Connector
/path/kafka/config以下の構成ファイルを作成しmysql.properties、次の構成を使用します。
name=test-source-mysql-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/mydb?useSSL=false
connection.user=root
connection.password=123456
#mode=timestamp+incrementing
mode=incrementing
table.whitelist=mydb.test_kafka
poll.interval.ms=1000
table.poll.interval.ms=3000
incrementing.column.name=id
#timestamp.column.name=tms
topics=test_kafka
mode設定については、ここでは、incrementing.column.name、およびいくつかのフィールドに焦点を当てますtimestamp.column.name。Kafka Connect MySQL JDBC Source は、次の 3 つの増分同期モードを提供します。
- 増加する
- タイムスタンプ
- タイムスタンプ+増分
- インクリメント モードでは、incrementing.column.name パラメーターで指定された列が使用されるたびに、クエリは最後のプル以降の最大 ID を超えます。
SELECT * FROM mydb.test_kafka
WHERE id > ?
ORDER BY id ASC
このパターンの欠点は、行の ID をインクリメントできないため、行の更新操作 (UPDATE、DELETE など) による変更をキャプチャできないことです。
- タイムスタンプ モードは、テーブルのタイムスタンプ列に基づいて新しい行または変更された行を検出します。この列は理想的には書き込みごとに更新され、値が単調増加する必要があります。タイムスタンプ列は、timestamp.column.name パラメーターを使用して指定する必要があります。
データテーブルではタイムスタンプ列を Nullable に設定できないことに注意してください。
タイムスタンプ モードでは、timestamp.column.name パラメーターで指定された列に基づいて、クエリは最後に成功したプル以降の gmt_modified よりも大きくなります。
SELECT * FROM mydb.test_kafka
WHERE tms > ? AND tms < ?
ORDER BY tms ASC
このモードでは行の UPDATE 変更をキャプチャできますが、データ損失が発生する可能性があるという欠点があります。タイムスタンプ列が唯一の列フィールドではないため、同じタイムスタンプを持つ列が 2 つ以上存在する可能性があります。2 番目の項目のインポート中にクラッシュが発生したとします。再インポートが復元されると、2 番目以降の項目は、同じタイムスタンプが表示され、いくつかのデータが失われます。これは、最初のエントリが正常にインポートされた後、対応するタイムスタンプが正常に消費されたものとして記録され、回復後にそのタイムスタンプより大きいレコードから同期が開始されるためです。さらに、タイムスタンプ列が時間とともに増加することも確認する必要があります。同期が成功するためにタイムスタンプ列が現在の最大タイムスタンプよりも小さくなるように人為的に変更された場合、その変更は同期されません。
- インクリメント モードまたはタイムスタンプ モードのみを使用する場合には落とし穴があります。タイムスタンプとインクリメントを併用すると、データを失うことなくインクリメント モードの利点と、更新操作での変更をキャプチャするタイムスタンプ モードの利点を最大限に活用できます。
incrementing.column.name厳密に増加する列を指定するにはパラメータを使用し、timestamp.column.nameタイムスタンプ列を指定するにはパラメータを使用する必要があります。
SELECT * FROM mydb.test_kafka
WHERE tms < ?
AND ((tms = ? AND id > ?) OR tms > ?)
ORDER BY tms, id ASC
MySQL JDBC ソース コネクタはクエリベースのデータ取得方法であるため、SELECT クエリを使用してデータを取得し、削除された行を検出する複雑なメカニズムがないため、この操作はサポートされていません
DELETE。ログベースの「Kafka Connect Debezium」を利用することができます。
上記のモードの効果は、後続のデモで個別に説明します。設定パラメータの詳細については、「MySQL ソース設定」を参照してください。
データベンド Kafka コネクタ
- Databend Kafka コネクタをインストールまたはコンパイルする
jar はソース コードからコンパイルすることも、リリースから直接ダウンロードすることもできます。
git clone https://github.com/databendcloud/databend-kafka-connect.git & cd databend-kafka-connect
mvn -Passembly -Dmaven.test.skip package
ディレクトリdatabend-kafka-connect.jarにコピーします。/path/kafka/libs
- データベンド JDBC ドライバーのインストール
最新の Databend JDBC をMaven Centralからダウンロードし、/path/kafka/libsディレクトリにコピーします。
- 配置 Databend Kafka Connector
/path/kafka/config以下の構成ファイルを作成しmysql.properties、次の構成を使用します。
name=databend
connector.class=com.databend.kafka.connect.DatabendSinkConnector
connection.url=jdbc:databend://localhost:8000
connection.user=databend
connection.password=databend
connection.attempts=5
connection.backoff.ms=10000
connection.database=default
table.name.format=default.${topic}
max.retries=10
batch.size=1
auto.create=true
auto.evolve=true
insert.mode=upsert
pk.mode=record_value
pk.fields=id
topics=test_kafka
errors.tolerance=all
auto.createと がauto.evolveに設定されている場合、trueソース テーブルの構造が変更されたときにテーブルが自動的に作成され、ターゲット テーブルに同期されます。その他の構成パラメーターの概要については、「Databend Kafka Connect プロパティ」を参照してください。
テストデータベンド Kafka Connect
各種コンポーネントを用意する
- StartMySQL
version: '2.1'
services:
postgres:
image: debezium/example-postgres:1.1
ports:
- "5432:5432"
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
mysql:
image: debezium/example-mysql:1.1
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=123456
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
- データベンドの開始
version: '3'
services:
databend:
image: datafuselabs/databend
volumes:
- /Users/hanshanjie/databend/local-test/databend/databend-query.toml:/etc/databend/query.toml
environment:
QUERY_DEFAULT_USER: databend
QUERY_DEFAULT_PASSWORD: databend
MINIO_ENABLED: 'true'
ports:
- '8000:8000'
- '9000:9000'
- '3307:3307'
- '8124:8124'
- Kafka Connect をスタンドアロン モードで起動し、MySQL ソース コネクタとデータベンド シンク コネクタをロードします。
./bin/connect-standalone.sh config/connect-standalone.properties config/databend.properties config/mysql.properties
[2023-09-06 17:39:23,128] WARN [databend|task-0] These configurations '[metrics.context.connect.kafka.cluster.id]' were supplied but are not used yet. (org.apache.kafka.clients.consumer.ConsumerConfig:385)
[2023-09-06 17:39:23,128] INFO [databend|task-0] Kafka version: 3.4.0 (org.apache.kafka.common.utils.AppInfoParser:119)
[2023-09-06 17:39:23,128] INFO [databend|task-0] Kafka commitId: 2e1947d240607d53 (org.apache.kafka.common.utils.AppInfoParser:120)
[2023-09-06 17:39:23,128] INFO [databend|task-0] Kafka startTimeMs: 1693993163128 (org.apache.kafka.common.utils.AppInfoParser:121)
[2023-09-06 17:39:23,148] INFO Created connector databend (org.apache.kafka.connect.cli.ConnectStandalone:113)
[2023-09-06 17:39:23,148] INFO [databend|task-0] [Consumer clientId=connector-consumer-databend-0, groupId=connect-databend] Subscribed to topic(s): test_kafka (org.apache.kafka.clients.consumer.KafkaConsumer:969)
[2023-09-06 17:39:23,150] INFO [databend|task-0] Starting Databend Sink task (com.databend.kafka.connect.sink.DatabendSinkConfig:33)
[2023-09-06 17:39:23,150] INFO [databend|task-0] DatabendSinkConfig values:...
入れる
挿入モードでは、次の MySQL コネクタ構成を使用する必要があります。
name=test-source-mysql-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/mydb?useSSL=false
connection.user=root
connection.password=123456
#mode=timestamp+incrementing
mode=incrementing
table.whitelist=mydb.test_kafka
poll.interval.ms=1000
table.poll.interval.ms=3000
incrementing.column.name=id
#timestamp.column.name=tms
topics=test_kafka
MySQL でデータベースmydbとテーブルを作成しますtest_kafka。
CREATE DATABASE mydb;
USE mydb;
CREATE TABLE test_kafka (id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(255) NOT NULL,description VARCHAR(512));
ALTER TABLE test_kafka AUTO_INCREMENT = 10;
データを挿入する前は、databend-kafka-connect はテーブル作成とデータ書き込みのイベントを受け取りません。
データを挿入します:
INSERT INTO test_kafka VALUES (default,"scooter","Small 2-wheel scooter"),
(default,"car battery","12V car battery"),
(default,"12-pack drill bits","12-pack of drill bits with sizes ranging from #40 to #3"),
(default,"hammer","12oz carpenter's hammer"),
(default,"hammer","14oz carpenter's hammer"),
(default,"hammer","16oz carpenter's hammer"),
(default,"rocks","box of assorted rocks"),
(default,"jacket","water resistent black wind breaker"),
(default,"cloud","test for databend"),
(default,"spare tire","24 inch spare tire");
ソーステーブルにデータを挿入した後、
データベンド ターゲット テーブルが新しく作成されます。
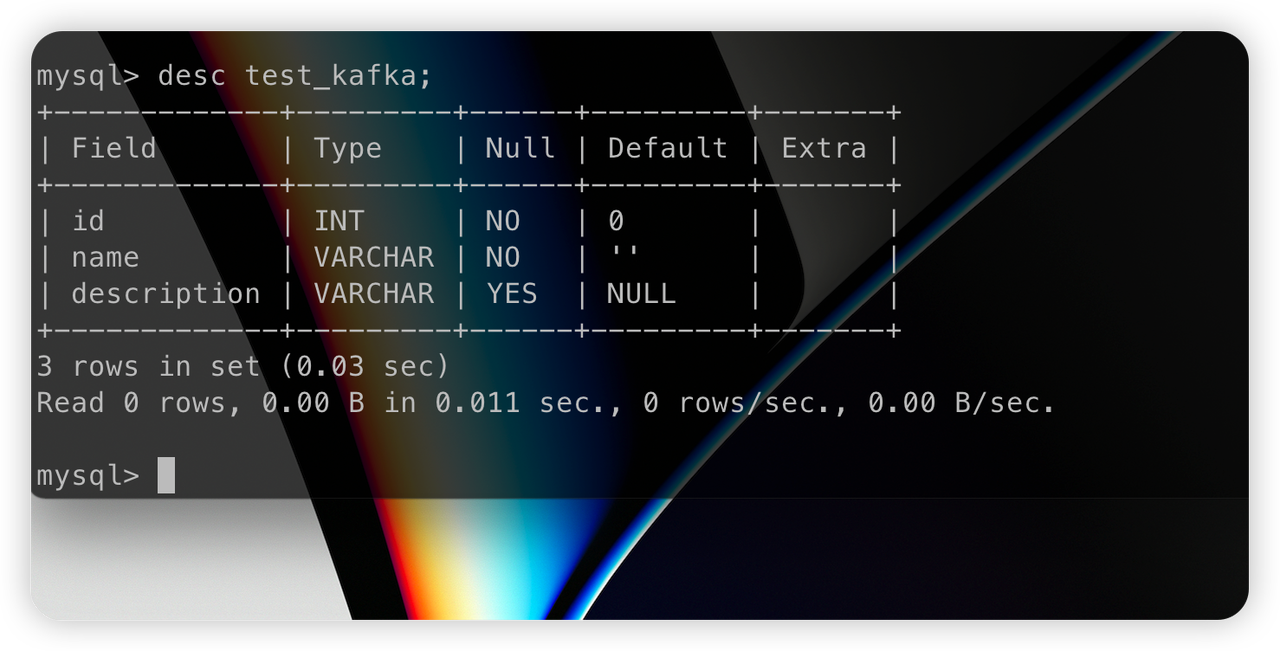
同時に、データは正常に挿入されます。
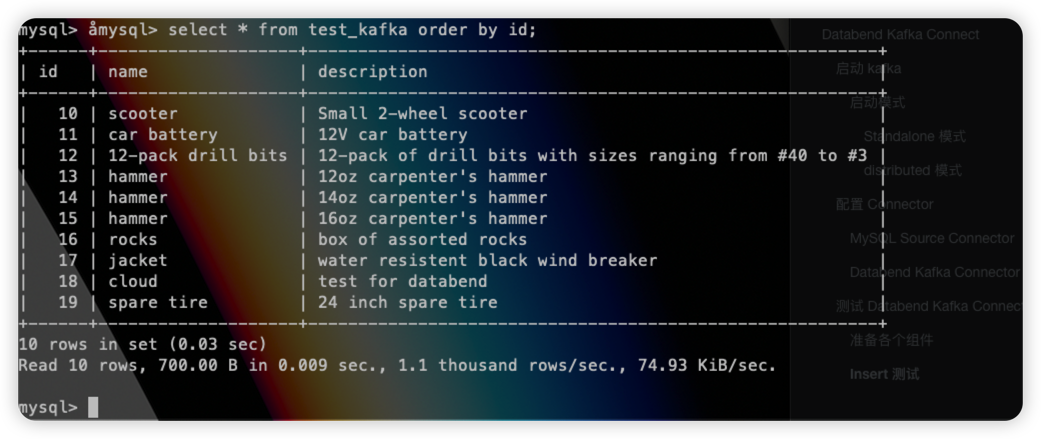
DDLのサポート
ここでは構成ファイル内にいるauto.evolve=trueため、ソース テーブルの構造が変更されると、DDL がターゲット テーブルに同期されます。ここで必要なのは、 MySQL Source Connector のモードを から にincrementing変更することだけです。フィールドを追加して設定を開くtimestamp+incrementing必要があります。元のテーブルで実行します。timestamptimestamp.column.name=tms
alter table test_kafka add column tms timestamp;
そしてデータを挿入します。
insert into test_kafka values(20,"new data","from kafka",now());
ターゲット テーブルに移動して、以下を表示します。
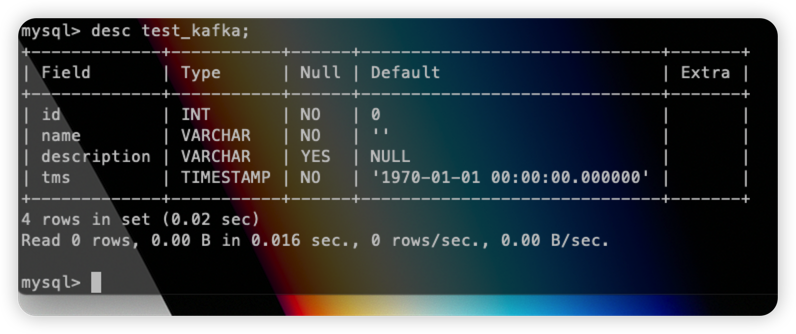
tmsフィールドがデータベンド テーブルに同期されており、データが正常に挿入されていることがわかります。

アップサート
MySQL コネクタの構成を次のように変更します。
name=test-source-mysql-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:mysql://localhost:3306/mydb?useSSL=false
connection.user=root
connection.password=123456
mode=timestamp+incrementing
#mode=incrementing
table.whitelist=mydb.test_kafka
poll.interval.ms=1000
table.poll.interval.ms=3000
incrementing.column.name=id
timestamp.column.name=tms
topics=test_kafka
主にフィールドmodeの変更timestamp+incrementingと追加を行いますtimestamp.column.name。
Kafka Connectを再起動します。
ソーステーブル内のデータを更新します。
update test_kafka set name="update from kafka test" where id=20;
ターゲット テーブルに移動して、更新されたデータを確認します。

要約する
上記の内容からわかるように、Databend Kafka Connect次のような特徴があります。
-
テーブルと列の自動作成のサポート: と の構成サポートにより、テーブルと列を自動的に作成できます。テーブル名は Kafka トピック名に基づいて作成されます
auto.create。auto-evolve -
Kafka Shemas のサポート:コネクタは、Avro、JSON スキーマ、および Protobuf 入力データ形式をサポートします。スキーマ レジストリ ベースの形式を使用するには、スキーマ レジストリを有効にする必要があります。
-
複数の書き込みモード:コネクタのサポート
insertとupsert書き込みモード。 -
マルチタスクのサポート: Kafka Connect の機能により、コネクタは 1 つ以上のタスクの実行をサポートします。タスクの数を増やすと、システムのパフォーマンスが向上します。
-
高可用性:分散モードでは、自動的にワークロードのバランスをとり、動的に拡張 (または縮小) し、フォールト トレランスを提供できます。
同時に、Databend Kafka Connect は、ネイティブ Connect によってサポートされる構成も使用できます。詳細な構成については、「Confluent プラットフォームの Kafka Connect シンク構成プロパティ」を参照してください。
私達と接続
Databend は、リアルタイム分析も実行できる、オブジェクト ストレージに基づくオープン ソースの柔軟で低コストの新しいデータ ウェアハウスです。私たちは、新世代のオープンソース データ クラウドを作成するために、クラウド ネイティブ データ ウェアハウス ソリューションを一緒に検討していただけることを楽しみにしています。
オープンソース フレームワーク NanUI の作者がスチールの販売に切り替えたため、プロジェクトは中断されました。Apple App Store の無料リストのナンバー 1 はポルノ ソフトウェア TypeScript です。人気が出てきたばかりなのに、なぜ大手はそれを放棄し始めるのでしょうか。 ? TIOBE 10月リスト:Javaが最大の下落、C#はJavaに迫る Rust 1.73.0リリース AIガールフレンドにイギリス女王暗殺を勧められた男性に懲役9年の実刑判決 Qt 6.6正式リリース ロイター:RISC-Vテクノロジーが中米テクノロジー戦争の鍵となる 新たな戦場 RISC-V: 単一の企業や国に支配されない レノボ、Android PC の発売を計画