ニューラルネットワークに基づく一般的な株価予測モデル
ダウンロードアドレス: LSTM ニューラルネットワークに基づく一般的な株価予測ソースコード + モデル + データセット
0 使い方 使い方
-
- getdata.py を使用してデータをダウンロードするか、独自のデータ ソースを使用してデータをstock_daily ディレクトリに置きます
-
- data_preprocess.py を使用してデータを前処理し、pkl ファイルを生成し、それを pkl_handle ディレクトリに配置します (オプション)
-
- train.py と init.py のパラメーターを調整します。まず、predict...py を使用してモデルをトレーニングし、モデル ファイルを生成します。次に、predict.py を使用して予測を行い、予測結果を生成するか、比較グラフをテストします。
0.1 detect.py パラメーターの概要
-
- –model: モデル名、現在 lstm とtransformer をサポートしています
-
- –mode: モード、現在トレーニング、テスト、予測をサポートしています
-
- –pkl: pkl ファイルを使用するかどうか。現在は 1 と 0 をサポートしています。
-
- –pkl_queue: トレーニング速度を上げるために pkl キュー モードを使用するかどうか。現在は 1 と 0 をサポートしています。
-
- –test_code: テスト コード。現在ストック コードをサポートしています。
-
- –test_gpu: GPU テストを使用するかどうか。現在は 1 と 0 をサポートしています。
-
- –predict_days: 予測する日数。現在は数値をサポートしています。
0.2 init.py のいくつかのパラメータの紹介 init.py のいくつかのパラメータの紹介
-
- TRAIN_WEIGHT: トレーニングの重み。現在は 1 以下の数値をサポートしています。
-
- SEQ_LEN: シーケンスの長さ、現在は数値をサポートしています
-
- BATCH_SIZE: バッチ サイズ。現在は数値をサポートしています。
-
- EPOCH: トレーニング ラウンドの数、現在サポートされている数値
-
- LEARNING_RATE: 学習率。現在は 1 以下の数値をサポートしています。
-
- WEIGHT_DECAY: 重みの減衰。現在は 1 以下の数値をサポートしています。
-
- SAVE_NUM_ITER: モデル間隔を保存します。現在は数値をサポートしています。
-
- SAVE_NUM_EPOCH: モデル間隔を保存します。現在は数値をサポートしています。
-
- SAVE_INTERVAL: モデルの時間間隔 (秒) を保存します。現在は数値をサポートしています。
-
- OUTPUT_DIMENSION: 出力ディメンション。現在数値をサポートしています。
-
- INPUT_DIMENSION: 入力ディメンション、現在数値をサポートしています
-
- NUM_WORKERS: スレッドの数。現在サポートされている数値
-
- PKL: pkl ファイルを使用するかどうか。現在は True と False をサポートしています。
-
- BUFFER_SIZE: バッファ サイズ、現在は数値をサポートしています
-
- シンボル: 株式コード、現在は株式コードまたは汎用をサポートしています。データとは、ダウンロードされたすべてのデータを意味します
-
- name_list: 予測する必要があるコンテンツの名前
-
- use_list: 予測する必要があるコンテンツ スイッチ。1 は使用を意味し、0 は使用しないことを意味します
1 プロジェクトの紹介プロジェクトの紹介
新しい
-
20230402
-
- データセットの読み取り方法を変更し、データキューとバッファを使用し、IO 数を減らし、トレーニング速度を向上させます。
-
- 簡単に変更できるようにグローバル変数を init.py に移動します
-
20230328
-
- 前処理データ ファイル形式を変更し、後で使用できるように 2 つのフィールド ts_code と date を追加します。
-
- lstm およびトランスフォーマー モデルを変更して、混合長入力をサポートする
-
- Transformer モデルではデコーダ層が追加され、予測精度の向上が期待できます。
-
20230327
-
- 実行ロジックの一部を変更し、load pkl 前処理ファイルと組み合わせることで、トレーニング速度が大幅に向上しました。
-
- データ フローの方向に関する大きな影響を与えるバグを修正しました
-
- 新しいモデルを試してみる
-
- モデルの良さを評価するための新しい指標を追加しました
-
20230325
-
- データ前処理機能を強化し、前処理後のキューをpklファイルとして保存することでIOロスを削減します。
-
- 不要なコードを修正する
-
- ロジックを簡素化し、時間の責任を減らし、空間を時間に置き換える方向性
-
- 共通指標を追加して予測精度を向上させる
-
20230322
-
- 出力コンテンツの制御を強化し、出力のコンテンツと量を自分で定義できます
-
- 読み取ったデータソースをローカルCSVファイルに変更します。
-
- IO ロジックを変更し、マルチスレッドを使用して指定したフォルダー内の CSV ファイルを読み取り、メモリに保存し、繰り返しトレーニングして IO の数を削減します。
-
- lstm、変圧器モデルを変更する
-
- データダウンロード機能を追加します。独自のAPIトークンを使用してください
データをダウンロードするための API トークンを取得します: データをダウンロードするための API トークンを取得します:
-
- https://tushare.pro/ Webサイトに登録し、必要なポイントを獲得してください(2023年3月まではユーザー情報の変更のみで十分なポイントとなり、今後は未定です)
-
- https://tushare.pro/user/token ページで独自の API トークンを表示できます。
-
- このプロジェクトのルートディレクトリに api.txt を作成し、取得した API トークンをこのファイルに書き込みます
-
- このプロジェクト getdata.py を使用して、毎日のデータを自動的にダウンロードします
株式市場は取引市場の変化を導く重要な要素であり、株式市場の動向を把握できれば個人や企業の投資に大きく役立ちます。しかし、株価の動向はさまざまな要因によって影響を受けるため、影響要因を定量的に測定することは困難です。しかし現在では、機械学習の助けを借りて、ネットワークを構築し、一定規模の株価データを学習し、ネットワーク学習を通じてより正確に株価を予測できるモデルを取得することが可能となり、株価の動向を把握するのに役立ちます。かなりの範囲で。このプロジェクトでは、**LSTM (Long Short-Term Memory Network)** を構築し、株価の動向を予測することに成功しました。
まず、データセットに関しては、上海証券取引所 No. 000001、中国平安株 (No. SZ_000001) データセットは 2016.01.01 ~ 2019.12.31 の株価データを使用しており、データ内容には当日の日付が含まれています、始値、終値、最高値、最安値、出来高、出来高。データ セットは 0.1 の比率で分割され、テスト セットが生成されます。トレーニング プロセスでは、T-99 日から T 日までのデータをトレーニング入力として使用し、T+1 日の株価の始値を予測します。(ここで、株式日次データセットを提供してくれたTushareに感謝し、サポートを歓迎します)
トレーニングモデルと結果の面では、従来のニューラルネットワークと比較してコンテキスト情報を維持でき、将来の市場を予測するために元の市場に基づいた株価予測モデルにさらに役立つLSTM(Long Short-Term Memory Network)を初めて採用しました。LSTM ネットワークのおかげで良好なフィッティング結果が得られ、損失はすぐに 0 に近づくことができました。その後、テスト用に LSTM モデルを更新するために提案された Transformer Encoder パーツを使用しました。ただし、結果はLSTMほど優れておらず、カーブフィッティングの誤差が大きく、損失の低下が遅いことがわかります。したがって、このプロジェクトは株式市場を予測するための LSTM モデルの実現に焦点を当てています。
2 LSTM モデルの原則 LSTM モデルの原則
2.1 時系列モデル 時系列モデル
時系列モデル: 時系列予測分析は、過去のイベント時間の特徴を使用して、将来のイベントの特徴を予測することです。これは比較的複雑な予測モデリング問題です。回帰分析モデルの予測とは異なり、時系列モデルはイベントの順序に依存します。同じサイズの値を順番に変更すると、入力モデルの結果は異なります。 。
2.1 RNN から LSTM へ RNN から LSTM へ
RNN: RNN の各隠れ層の計算結果は、現在の入力と最後の隠れ層の結果に関連します。この方法により、RNN の計算結果は前回の結果を記憶する特性を持ちます。このうち、xは入力層、o は出力層、sは隠れ層、 tは計算回数、V、W、Uは重み、t 番目の隠れ層の状態は次の式で示されます。
S t = f ( U ∗ X t + W ∗ S t − 1 ) (1) St = f(U*Xt + W*St-1) (1)セント=f ( U∗Xt+W∗セント−1 ) (1)

現在の隠れ層の状態が RNN モデルを通じて過去の n 回の状態に関連付けられている場合、計算量を増やす必要があり、複雑さが指数関数的に増加することがわかります。ただし、この問題は LSTM ネットワークを使用することで解決できます。
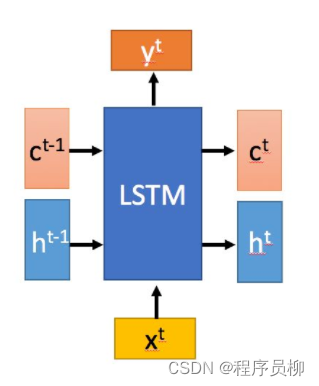
LSTM (長短期記憶ネットワーク) LSTM (長短期記憶ネットワーク):
LSTM は特別な種類の RNN であり、主に Eileen による長いシーケンスのトレーニングの過程での勾配消失と勾配爆発の問題を解決します。RNN と比較して、LSTM は長いシーケンスでより優れたパフォーマンスを発揮します。
-
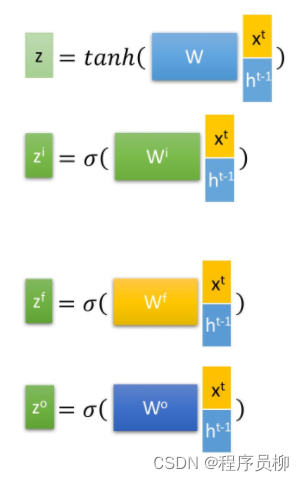
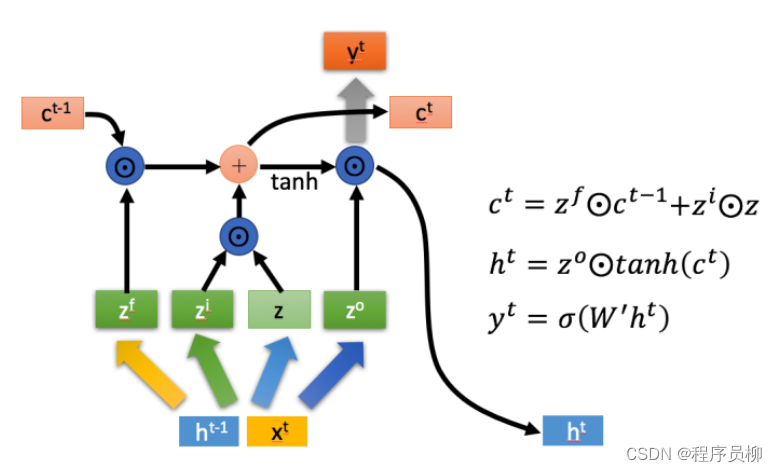
LSTM 内には、忘却ステージ、選択メモリ ステージ、出力ステージの3 つのステージがあります。 LSTM には、忘却ステージ、選択メモリ ステージ、および出力ステージの 3 つのステージがあります。
-
**忘却段階: **計算をゲート制御として使用し、前の状態で忘れる必要がある内容を制御します。
-
**選択メモリ ステージ: ** 入力のメモリを選択し、ゲート信号は によって制御され、入力コンテンツは [外部リンク画像の転送に失敗しました。ソース サイトにはリーチ防止メカニズムがある可能性があります。画像を保存し、表現のために直接アップロードします。
-
**出力ステージ:**制御を通じて現在の状態の出力内容を決定し、前のステージで得られた出力もスケーリングします。
-
株価予測のための 3LSTM 予測モデルの実装
1. データセットの準備
1. データセットの準備
-
データセットの分割: データセットは 0.1 の比率で分割され、テスト セットを生成します。トレーニング プロセスでは、T-99 日から T 日までのデータをトレーニング入力として使用し、T+1 日の株価の始値を予測します。
-
データを標準化する: トレーニング セットとテスト セットの両方を列ごとの範囲で分割する必要があります。トレーニングの完了後に結果を取得するには、逆処理が必要です。
train ( [ : , i ] ) = ( train ( [ : , i ] ) ) − min ( train [ : , i ] ) / ( max ( train [ : , i ] ) − min ( train [ : , i ] ) ) ( 2 ) train([:,i])=(train([:,i]))-min(train[:,i])/(max(train[:,i])-min(train[: 、i])) (2)電車( [ : _、私])=(電車( [ : _、私]))−分(電車[ : _ _、i ] ) / ( max ( t r ain [ :、私])−分(電車[ : _ _、] )) (2 )
test ( [ : , i ] ) = ( test ( [ : , i ] ) ) − min ( train [ : , i ] ) / ( max ( train [ : , i ] ) − min ( train [ : , i ] ) ) ( 3 ) test([:,i])=(test([:,i]))-min(train[:,i])/(max(train[:,i])-min(train[: ,i])) (3)テスト( [ : _、私])=(テスト( [ : _、私]))−分(電車[ : _ _、i ] ) / ( max ( t r ain [ :、私])−分(電車[ : _ _、] )) (3 )
2. モデルの構築
2. モデルの構築
pytorch フレームワークを使用して LSTM モデルとtorch.nn.LSTM() に含まれるパラメーター設定を構築します。
-
入力フィーチャのディメンション: input_size=dimension(dimension=8)
-
LSTM の隠れ層の次元: hidden_size=128
-
リカレント ニューラル ネットワークの層数: num_layers=3
-
バッチファースト: TRUE
-
バイアス: バイアスはデフォルトで使用されます
完全に接続されたレイヤーのパラメーター設定:
-
最初のレイヤー: in_features=128、out_features=16
-
2 番目のレイヤー: in_features=16、out_features=1 (値にマップ)
3. モデルのトレーニング
3. モデルのトレーニング
-
デバッグ後、学習率 lr=0.00001 であることが判明しました。
-
最適化機能:バッチ勾配降下法(SGD)
-
バッチサイズbatch_size=4
-
トレーニング代数エポック=100
-
損失関数: MSELoss 平均二乗損失関数。最終トレーニング モデルでは MSELoss が約 0.8 まで下がります。
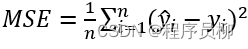
4. モデル予測
4. モデル予測
テスト セットはトレーニング済みモデルを使用して検証され、実際のデータと比較した平均絶対パーセント誤差 (MAPELoss) は 0.04 で、テスト セットの精度は 96% を取得できます。
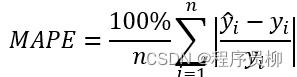
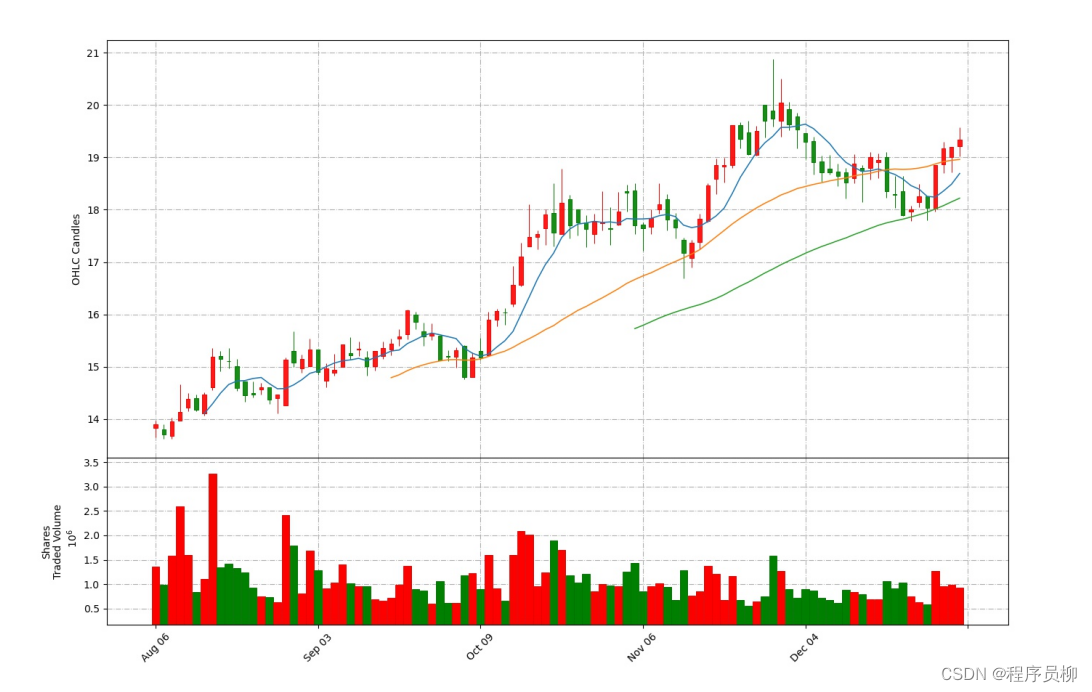
5. モデルの結果
5. モデルの結果
以下の図は、データセット全体の過去 100 日間の K ライン表示を示しています。その日の始値が終値よりも低い場合は赤で表示され、その日の始値が終値よりも高い場合は赤で表示されます。終値の場合は緑色になります。この図には、その日の取引高や移動平均などの情報も表示されます。
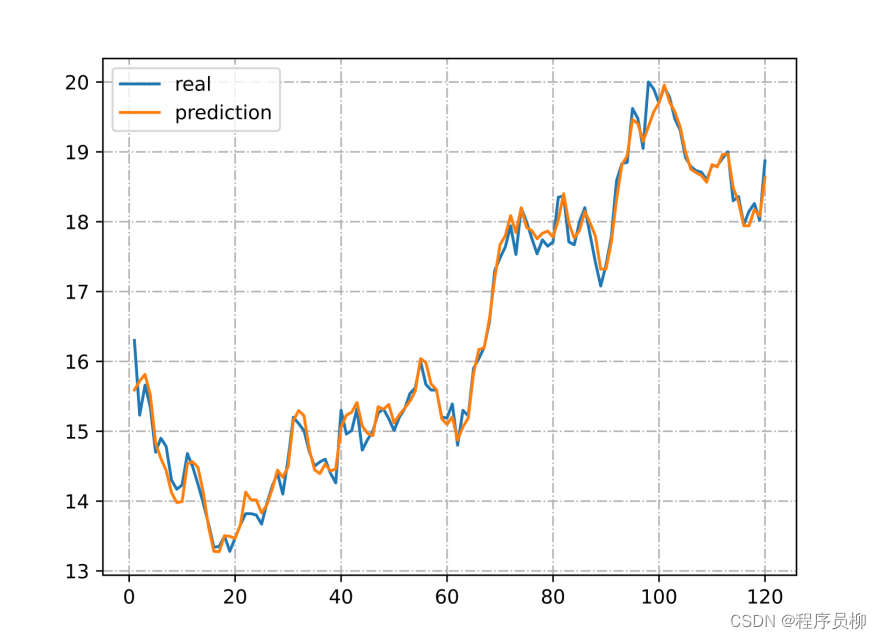
LSTM モデルによって予測されたテスト セットの結果と実際の結果の比較グラフは、LSTM モデルによって予測された結果が実際の株価傾向に非常に近いことを示しており、非常に参考価値があります。
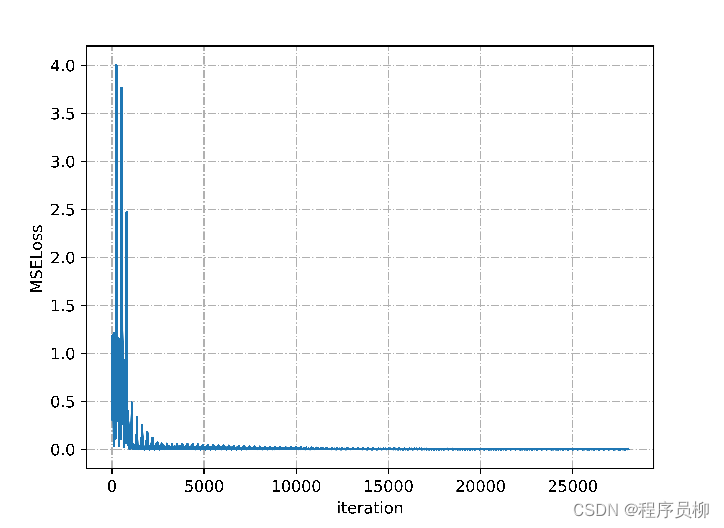
LSTM モデルのトレーニング中の MSELoss の変化: トレーニングの世代数が増加するにつれて、このモデルの MSELoss は徐々に 0 に近づく傾向にあることがわかります。
4 結論
4 結論
このプロジェクトは、機械学習手法を使用して株式市場予測の問題に取り組みます。このプロジェクトは、オープンソースの株式データセンターである上海証券取引所第000001号の中国平安証券(No.SZ_000001)を採用し、長期配列予測により適したLSTM(長短期記憶ニューラルネットワーク)を使用しています。トレーニング セット シーケンス、テスト セットのトレーニングを通じて、始値を予測することにより、精度 96% の LSTM 株価予測モデルが最終的に得られ、株式市場予測の問題をより正確に解決しました。
プロジェクトの開発プロセスでは、LSTM よりも最近提案された Transformer モデルも使用されましたが、テスト セットに対する予測効果は良好ではなく、その後の分析では、一般的な Transformer のエンコーダとそれに対応するデコーダ層が原因である可能性があると考えられました。モデルですが、このプロジェクトのモデルではデコーダの代わりに全結合層が使用されているため、効果は良くありません。その後の研究では、さらに改良することができ、おそらく LSTM よりも最適化された結果が得られるでしょう。
ダウンロードアドレス: LSTM ニューラルネットワークに基づく一般的な株価予測ソースコード + モデル + データセット