序文
前の 2 つの記事では、Redis のメモリ モデルと Redis の永続性についてそれぞれ紹介しました。
Redis の永続性で述べたように、Redis の高可用性ソリューションには、永続性、マスター/スレーブ レプリケーション (および読み取り/書き込み分離)、センチネル、クラスターが含まれます。その中で、永続性は Redis データのスタンドアロン バックアップ (メモリからハードディスクへのバックアップ) に焦点を当てており、マスター/スレーブ レプリケーションはデータのマルチマシンのホット バックアップに焦点を当てています。さらに、マスター/スレーブ レプリケーションにより、負荷分散と障害回復も実現できます。
この記事では、マスター スレーブ レプリケーションの使用方法、マスター スレーブ レプリケーションの原理 (完全レプリケーションと部分レプリケーション、ハートビート メカニズムに焦点を当てます)、マスター スレーブ レプリケーションのあらゆる側面を詳しく紹介します。実際のアプリケーションで注意が必要な問題 (データの不整合、レプリケーション タイムアウト、レプリケーション バッファ オーバーフローなど)、マスター/スレーブ レプリケーションに関連する構成 (repl タイムアウト、クライアント出力バッファ制限スレーブに焦点を当てる) など。
1. マスタ・スレーブ型レプリケーションの概要
マスター/スレーブ レプリケーションとは、1 つの Redis サーバーのデータを他の Redis サーバーにコピーすることを指します。前者をマスターノード(master)、後者をスレーブノード(slave)と呼び、データの複製はマスターノードからスレーブノードへのみの一方向です。
デフォルトでは、各 Redis サーバーはマスター ノードであり、マスター ノードは複数のスレーブ ノードを持つことができます (またはスレーブ ノードを持たない) が、スレーブ ノードが持つことができるマスター ノードは 1 つだけです。
マスター/スレーブ レプリケーションの役割
マスター/スレーブ レプリケーションの機能は主に次のとおりです。
- データ冗長性: マスター/スレーブ レプリケーションは、永続化以外のデータ冗長化方法であるデータのホット バックアップを実装します。
- 障害回復: マスター ノードに問題が発生した場合、スレーブ ノードは迅速な障害回復を実現するためのサービスを提供できます。これは実際には一種のサービス冗長性です。
- 負荷分散: 読み取り/書き込み分離と組み合わせたマスター/スレーブ レプリケーションに基づいて、マスター ノードは書き込みサービスを提供し、スレーブ ノードは読み取りサービスを提供できます (つまり、アプリケーションは Redis データの書き込み時にマスター ノードに接続します) 、アプリケーションは Redis データの読み取り時にスレーブ ノードに接続します)、サーバーの負荷を共有するため、特に書き込みを減らし読み取りを増やすシナリオでは、複数のスレーブ ノードで読み取り負荷を共有すると、Redis サーバーの同時実行性が大幅に向上します。
- 高可用性の基礎: 上記の機能に加えて、マスター/スレーブ レプリケーションもセンチネルとクラスターの実装の基礎となるため、マスター/スレーブ レプリケーションは Redis の高可用性の基礎となります。
2. マスタースレーブレプリケーションの使用方法
マスター/スレーブ レプリケーションをより直観的に理解するために、その内部原理を紹介する前に、まずマスター/スレーブ レプリケーションを有効にするためにどのように操作する必要があるかを説明します。
1. コピーを作成する
マスター/スレーブ レプリケーションのアクティブ化はスレーブ ノードで完全に開始されるため、マスター ノードでは何もする必要がないことに注意してください。
スレーブ ノードでマスター/スレーブ レプリケーションを有効にするには、次の 3 つの方法があります。
(1) 設定ファイル
スレーブサーバーの設定ファイルにslaveof <masterip> <masterport>を追加します。
(2) 起動コマンド
redis-server 起動コマンドの後に --slaveof <masterip> <masterport> を追加します
(3) クライアントコマンド
Redis サーバーが起動した後、クライアント経由でコマンド「slaveof <masterip> <masterport>」を直接実行すると、Redis インスタンスがスレーブ ノードになります。
上記 3 つのメソッドは同等ですが、クライアント コマンド メソッドを例として、slaveof 実行後の Redis マスター ノードとスレーブ ノードの変化を見てみましょう。
2. 例
準備: 2 つのノードを起動します
便宜上、実験で使用されるマスター ノードとスレーブ ノードは 1 台のマシン上の異なる Redis インスタンスであり、マスター ノードはポート 6379 をリッスンし、スレーブ ノードはポート 6380 をリッスンします。スレーブ ノードがリッスンするポート番号は変更できます。構成ファイル内:

起動後、以下が表示されます。

2 つの Redis ノード (それぞれ 6379 ノードおよび 6380 ノードと呼ばれます) が起動されると、デフォルトでは両方ともマスター ノードになります。
コピーを作成する
この時点で、6380 ノードでslaveof コマンドを実行して、6380 ノードをスレーブ ノードにします。

効果を観察する
マスター/スレーブ レプリケーションが確立された後、マスター ノードのデータがスレーブ ノードにコピーされることを確認してみましょう。
(1) まず、スレーブ ノードから存在しないキーをクエリします。

(2) 次に、このキーをマスター ノードに追加します。

(3) この時点で、スレーブ ノードでキーを再度クエリすると、マスター ノードの動作がスレーブ ノードに同期されていることがわかります。

(4) 次に、マスター ノード上のキーを削除します。

(5) この時点で、スレーブ ノードでキーを再度クエリすると、マスター ノードの動作がスレーブ ノードに同期されていることがわかります。

3. レプリケーションの切断
マスターとスレーブのレプリケーション関係が、slaveof <masterip> <masterport> コマンドによって確立された後は、slaveof no one によって切断できます。スレーブ ノードがレプリケーションを切断した後、既存のデータは削除されませんが、マスター ノードの新しいデータの変更は受け付けられなくなることに注意してください。
スレーブノードがslaveof no oneを実行した後の印刷ログは以下のようになり、レプリケーションが切断された後、スレーブノードが再びマスターノードになっていることがわかります。

マスター ノードは次のようにログを出力します。

3. マスタスレーブレプリケーションの実装原理
前節ではマスター/スレーブ関係を確立するための操作方法を紹介しましたが、このセクションではマスター/スレーブ レプリケーションの実装原理を紹介します。
マスタ・スレーブ・レプリケーションのプロセスは、接続確立段階(準備段階)、データ同期段階、コマンド伝播段階の 3 つの段階に大別されますので、それぞれ紹介します。
1. 接続確立フェーズ
この段階の主な機能は、マスター ノードとスレーブ ノード間の接続を確立してデータ同期の準備をすることです。
ステップ 1: マスターノード情報を保存する
スレーブ ノード サーバー内には 2 つのフィールド、つまり masterhost フィールドと masterport フィールドが維持され、これらはマスター ノードの IP およびポート情報を保存するために使用されます。
なお、slaveofは非同期コマンドであり、スレーブノードはマスターノードのipとポートの保存が完了すると、 slaveofコマンドを送信したクライアントに直接OKを返し、その後実際のコピー動作が開始されます。
このプロセス中に、スレーブ ノードが次のようにログを出力することがわかります。

ステップ 2: ソケット接続を確立する
スレーブ ノードは、レプリケーション タイミング関数 replicationCron() を 1 秒に 1 回呼び出し、接続可能なマスター ノードが存在することを検出すると、マスター ノードの IP とポートに従ってソケット接続を作成します。接続が成功した場合は、次のようになります。
スレーブ ノード: コピー作業を処理するソケットのファイル イベント ハンドラーを作成し、RDB ファイルの受信やコマンド伝播の受信など、後続のコピー作業を担当します。
マスター ノード: スレーブ ノードからソケット接続を受信した後 (つまり、受け入れ後)、ソケットに対応するクライアント状態を作成し、スレーブ ノードをマスター ノードに接続されたクライアントと見なし、次の手順に基づきます。スレーブ ノード上でこれはコマンド リクエストをマスター ノードに送信することによって行われます。
このプロセス中に、スレーブ ノードは次のようにログを出力します。

ステップ 3: ping コマンドを送信する
スレーブ ノードがマスター ノードのクライアントになった後、最初のリクエストに対して ping コマンドを送信して、ソケット接続が利用可能かどうか、およびマスター ノードが現在リクエストを処理できるかどうかを確認します。
スレーブ ノードが ping コマンドを送信した後、次の 3 つの状況が発生する可能性があります。
(1) return pong: ソケット接続が正常であり、マスター ノードが現在リクエストを処理でき、レプリケーション プロセスが続行されていることを示します。
(2) タイムアウト: 一定時間が経過してもスレーブ ノードはマスター ノードからの応答を受信せず、ソケット接続が利用できないことを示し、スレーブ ノードはソケット接続を切断して再接続します。
(3) pong 以外の結果を返す: マスター ノードが時間外に実行されるスクリプトの処理など、マスター ノードが現在コマンドを処理できないことを示す他の結果を返した場合、スレーブ ノードはソケット接続を切断して再接続します。
マスター ノードが pong を返すと、スレーブ ノードは次のようにログを出力します。

ステップ 4: 認証
masterauth オプションがスレーブ ノードに設定されている場合、スレーブ ノードはマスター ノードに対して認証する必要がありますが、このオプションが設定されていない場合、認証は必要ありません。スレーブノードの認証はマスターノードにauthコマンドを送信することで行われ、authコマンドのパラメータは設定ファイルのmasterauthの値となります。
マスター ノードによって設定されたパスワードの状態がスレーブ ノードの masterauth の状態と一致する場合 (一致とは、両方が存在し、パスワードが同じであるか、どちらも存在しないことを意味します)、認証は成功し、レプリケーション プロセスが続行されます。 ; それらが矛盾している場合、スレーブ ノードはソケット Connect を切断し、再接続します。
ステップ 5: スレーブノードのポート情報を送信する
認証後、スレーブ ノードはリッスンするポート番号 (前の例では 6380) をマスター ノードに送信し、マスター ノードはこの情報をスレーブ ノードに対応するクライアントのslave_listening_port フィールドに保存します。はマスターノードには含まれません。 info Replication 実行時に表示される以外の効果はありません。
2. データ同期フェーズ
マスター ノードとスレーブ ノード間の接続が確立された後、データ同期を開始できます。これは、スレーブ ノード データの初期化として理解できます。具体的な実行方法は、スレーブノードがマスターノードにpsyncコマンドを送信し(以前はRedis2.8がsyncコマンドでした)、同期が開始されます。
データ同期ステージはマスター/スレーブ レプリケーションの中核ステージです。マスター/スレーブ ノードの現在の状態に応じて、完全レプリケーションと部分レプリケーションに分けることができます。次の章では、これら 2 つのレプリケーション方法と実行について具体的に説明しますpsync コマンドのプロセス。ここではこれ以上の詳細はありません。
データ同期段階以前では、スレーブ ノードはマスター ノードのクライアントであり、マスター ノードはスレーブ ノードのクライアントではなく、この段階以降では、マスター ノードとスレーブ ノードはクライアントになることに注意してください。お互い。その理由は、これまではマスター ノードはスレーブ ノードからのリクエストに応答するだけで済み、積極的にリクエストを送信する必要はありませんが、データ同期フェーズとその後のコマンド伝播フェーズでは、マスター ノードが要求を送信する必要があるためです。アクティブにスレーブ ノードにリクエスト (エリア内のプッシュ バッファ書き込みコマンドなど) を送信して、コピーを完了します。
3. コマンド伝播フェーズ
データ同期フェーズが完了すると、マスター/スレーブ ノードはコマンド伝播フェーズに入ります。この段階で、マスター ノードは実行する書き込みコマンドをスレーブ ノードに送信し、スレーブ ノードはコマンドを受信して実行します。マスター/スレーブ ノードのデータの一貫性。
コマンド伝播フェーズでは、書き込みコマンドの送信に加えて、マスター ノードとスレーブ ノードはハートビート メカニズム (PING および REPLCONF ACK) も維持します。ハートビート メカニズムの原理には部分レプリケーションが含まれるため、ハートビート メカニズムについては、部分レプリケーションの関連内容を紹介した後で別途紹介します。
レイテンシーと不整合
コマンドの伝播は非同期プロセスであることに注意してください。つまり、マスターノードは書き込みコマンドを送信した後、スレーブノードからの応答を待たないため、マスターノードとマスターノードの間でリアルタイムの一貫性を維持することは実際には困難です。スレーブノードに接続されるため、遅延は避けられません。データの不整合の程度は、マスター ノードとスレーブ ノード間のネットワークの状態、マスター ノードの書き込みコマンドの実行頻度、マスター ノードの repl-disable-tcp-nolay 設定に関連します。
repl-disable-tcp-nolay no: この設定は、マスター ノードがスレーブ ノードとの TCP_NODELAY を禁止するかどうかを制御するためにコマンド伝播フェーズで使用されます。デフォルトは no、つまり TCP_NODELAY は禁止されていません。「はい」に設定すると、TCP はパケットをマージして帯域幅を削減しますが、送信頻度が減少し、スレーブ ノードのデータ遅延が増加し、一貫性が低下します。特定の送信頻度は Linux カーネルの構成に関連します。 、デフォルト設定は 40ms です。no に設定すると、TCP はマスター ノードのデータをすぐにスレーブ ノードに送信し、帯域幅は増加しますが、遅延は小さくなります。
一般に、アプリケーションが Redis データの不整合に対して高い耐性を持ち、マスター ノードとスレーブ ノード間のネットワーク状態が良好でない場合にのみ、yes に設定されます。ほとんどの場合、デフォルト値の no が使用されます。
4. [データ同期フェーズ] フルコピーと部分コピー
Redis2.8 より前では、スレーブノードはマスターノードに sync コマンドを送信してデータの同期を要求し、このときの同期方法はフルコピーでしたが、Redis2.8 以降では、スレーブノードが psync コマンドを送信してデータを要求できるようになりました。同期、現時点ではマスター/スレーブ ノードに応じて 現在のステータスに応じて、同期方法は完全レプリケーションまたは部分レプリケーションになる場合があります。以下の紹介では、Redis 2.8 以降のバージョンを例として取り上げます。
- フル レプリケーション: 初期レプリケーションまたは部分レプリケーションが不可能なその他の状況に使用されます。マスター ノード内のすべてのデータをスレーブ ノードに送信することは、非常に負荷の高い操作です。
- 部分レプリケーション: ネットワーク中断などの後のレプリケーションに使用され、中断中にマスターノードが実行した書き込みコマンドのみがスレーブノードに送信されるため、フルレプリケーションよりも効率的です。ネットワーク中断時間が長すぎて、マスターノードが中断中に実行された書き込みコマンドを完全に保存できない場合、部分レプリケーションは実行できず、完全レプリケーションが引き続き使用されることに注意してください。
1. フルコピー
psync コマンドを使用した Redis 完全レプリケーションのプロセスは次のとおりです。
(1) スレーブノードが部分レプリケーション不可と判断しマスターノードに完全レプリケーション要求を送信するか、スレーブノードが部分レプリケーション要求を送信するがマスターノードが部分レプリケーション不可と判断するか、具体的な判断部分レプリケーション導入の原理を説明した後にプロセスを説明する必要があります。
(2) マスターノードはフルコピーコマンドを受信した後、bgsave を実行し、バックグラウンドで RDB ファイルを生成し、バッファ (コピーバッファと呼ばれます) を使用して、今後実行されるすべての書き込みコマンドを記録します。
(3) マスターノードの bgsave 実行完了後、RDB ファイルをスレーブノードに送信すると、スレーブノードは古いデータをクリアした後、受信したRDBファイルをロードし、データベースの状態をデータ保存時のデータベースの状態に更新します。マスターノードが bgsave を実行する
(4) マスターノードは前述のコピーバッファ内のすべての書き込みコマンドをスレーブノードに送信し、スレーブノードはこれらの書き込みコマンドを実行してデータベースの状態をマスターノードの最新の状態に更新します。
(5) スレーブ ノードで AOF が有効になっている場合、bgrewriteaof の実行がトリガーされ、AOF ファイルがマスター ノードの最新の状態に更新されるようになります。
以下は、完全レプリケーションの実行時にマスター ノードとスレーブ ノードによって出力されるログです。ログの内容が上記の手順に正確に対応していることがわかります。
マスターノードの印刷ログは以下のとおりです。

ノードからのログは、次の図に示すように出力されます。
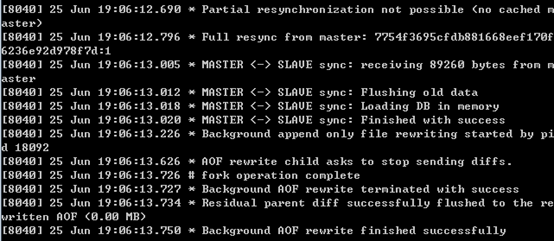
その中で、注意すべき点がいくつかあります: スレーブ ノードはマスター ノードから 89260 バイトのデータを受信しました; スレーブ ノードはマスター ノードからデータをロードする前に古いデータをクリアする必要があります; スレーブ ノードがデータを同期した後、bgrewriteaof を呼び出します。
フル コピーのプロセスを通して、フル コピーが非常に重い操作であることがわかります。
(1) マスターノードは bgsave コマンドを使用して子プロセスをフォークし、RDB 永続化を実行します。このプロセスは大量の CPU、メモリ (ページ テーブル コピー)、およびハードディスク IO を消費します。bgsave のパフォーマンスについては、以下を参照してください。 Redis の詳細な研究: 永続性
(2) マスターノードはネットワーク経由でRDBファイルをスレーブノードに送信します。これにより、マスターノードとスレーブノードの帯域幅が大量に消費されます。
(3) 古いデータをクリアしてスレーブ ノードから新しい RDB ファイルをロードするプロセスがブロックされ、クライアント コマンドに応答できなくなります。スレーブ ノードが bgrewriteaof を実行すると、追加の消費も発生します。
2. 部分コピー
マスター ノードに大量のデータがある場合、完全レプリケーションは非効率すぎるため、Redis 2.8 では、ネットワークが中断された場合にデータ同期を処理するために部分レプリケーションの提供を開始しました。
部分レプリケーションの実現は、次の 3 つの重要な概念に依存しています。
(1) コピーオフセット
マスター ノードとスレーブ ノードはそれぞれ、マスター ノードからスレーブ ノードに渡されるバイト数を表すレプリケーション オフセット (オフセット) を維持します。マスター ノードが N バイトのデータをスレーブ ノードに送信するたびに、オフセットはマスター ノードは N を増加させ、スレーブ ノードがマスター ノードから N バイトのデータを受信するたびに、スレーブ ノードのオフセットは N ずつ増加します。
オフセットは、マスターノードとスレーブノードのデータベースの状態が一致しているかどうかを判断するために使用され、両者のオフセットが同じであれば一致しており、オフセットが異なっていれば不一致となります。スレーブノードからの距離は、2 つのオフセットに従って見つけることができます。たとえば、マスター ノードのオフセットが 1000、スレーブ ノードのオフセットが 500 の場合、部分レプリケーションではオフセット 501 ~ 1000 のデータをスレーブ ノードに転送する必要があります。オフセット 501 ~ 1000 のデータが格納される場所が、以下で紹介するレプリケーション バックログ バッファです。
(2) バックログバッファをコピーする
レプリケーション バックログ バッファは、マスター ノードによって維持される固定長の先入れ先出し (FIFO) キューで、デフォルト サイズは 1MB です。マスター ノードがスレーブ ノードを持ち始めるときに作成され、その機能はこれは、マスター ノードからスレーブ ノードに最近送信されたデータをバックアップすることです。マスターに 1 つ以上のスレーブがあるかどうかに関係なく、必要なレプリケーション バックログ バッファーは 1 つだけであることに注意してください。
コマンド伝播フェーズでは、書き込みコマンドをスレーブ ノードに送信するだけでなく、マスター ノードも書き込みコマンドのバックアップとしてレプリケーション バックログ バッファにコピーを送信し、書き込みコマンドを保存するだけでなく、それぞれのレプリケーション バックログ バッファにも格納されます。このバイトはコピー オフセット (オフセット) に対応します。レプリケーション バックログ バッファーは固定長で先入れ先出し方式であるため、プライマリ ノードによって実行された最新の書き込みコマンドが保存され、古い書き込みコマンドはバッファーから押し出されます。
バッファの長さは固定で制限されているため、バックアップできる書き込みコマンドも制限され、マスタとスレーブのノードオフセット間のギャップが大きすぎてバッファ長を超えた場合、部分レプリケーションを実行できません。また、完全なレプリケーションのみを実行できます。逆に、ネットワークが中断されたときに部分レプリケーションが実行される確率を高めるために、必要に応じてレプリケーション バックログ バッファのサイズを増やすことができます (repl-backlog-size を構成することで)。たとえば、ネットワーク中断の平均時間がは 60 秒であり、1 秒あたりに生成される書き込みコマンド (特定のプロトコル形式) によって占有される平均バイト数は 100KB で、コピー バックログ バッファの平均需要は 6MB です。安全のため、次のように設定できます。 12MB を確保すると、ほとんどの切断状況でも部分コピーを使用できます。
スレーブ ノードがマスター ノードにオフセットを送信した後、マスター ノードはオフセットとバッファ サイズに従って部分レプリケーションを実行するかどうかを決定します。
- オフセット offset 以降のデータがまだコピー バックログ バッファーにある場合は、部分コピーを実行します。
- オフセット offset 以降のデータがコピー バックログ バッファーにない (データが絞り出されている) 場合は、フル コピーを実行します。
(3) サーバ実行ID(runid)
各 Redis ノード (マスターとスレーブに関係なく) は、起動時に 40 個のランダムな 16 進文字で構成されるランダム ID (起動ごとに異なります) を自動的に生成します。runid は、Redis ノードを一意に識別するために使用されます。info Server コマンドを使用して、ノードの runid を表示できます。

マスター/スレーブ ノードが初めて複製されるとき、マスター ノードは自身の runid をスレーブ ノードに送信し、スレーブ ノードは runid を保存します。切断して再接続すると、スレーブ ノードは runid をマスター ノードに送信します。いいえ部分コピー:
- スレーブ ノードによって保存された runid がマスター ノードの現在の runid と同じである場合、それはマスター/スレーブ ノードが以前に同期されていることを意味し、マスター ノードは引き続き部分レプリケーションの使用を試行します (部分レプリケーションが可能かどうかに関係なく)。部分的にレプリケートされるかどうかは、オフセットとレプリケーション バックログ バッファーによって異なります)。
- スレーブノードが保存したrunidがマスターノードの現在のrunidと異なる場合は、切断前にスレーブノードが同期していたRedisノードが現在のマスターノードではないことを意味し、フルコピーのみ可能となります。
3. psyncコマンドの実行
レプリケーション オフセット、レプリケーション バックログ バッファ、ノード実行 ID を理解した後、このセクションでは psync コマンドのパラメータと戻り値を紹介し、マスター/スレーブ ノードが完全レプリケーションと部分レプリケーションのどちらを使用するかを決定する方法を説明します。の psync コマンドの実行中。
psync コマンドの実行プロセスを以下の図に示します (画像出典:「Redis Design and Implementation」)。
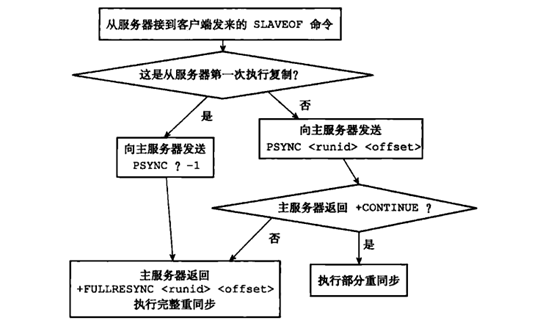
(1) まず、スレーブ ノードは、現在の状態に応じて psync コマンドを呼び出す方法を決定します。
- スレーブ ノードがこれまでにslaveofを実行していないか、最近誰にもslaveofを実行していない場合、スレーブ ノードはコマンド psync ? -1 を送信してマスター ノードからの完全なレプリケーションを要求します。
- スレーブ ノードが以前に smileof を実行したことがある場合、送信するコマンドは psync <runid> <offset> です。ここで、runid は最後にレプリケートされたマスター ノードの runid、offset は最後のレプリケーション時にスレーブ ノードによって保存されたレプリケーション オフセットです。期限切れ。
(2) マスター ノードは、受信した psync コマンドと現在のサーバーのステータスに基づいて、完全レプリケーションを実行するか部分レプリケーションを実行するかを決定します。
- マスター ノードのバージョンが Redis2.8 より低い場合、-ERR 応答が返されます。このとき、スレーブ ノードは完全レプリケーションを実行するために同期コマンドを再送信します。
- マスター ノードのバージョンが十分に新しく、runid がスレーブ ノードによって送信された runid と同じで、スレーブ ノードによって送信されたオフセット以降のデータがレプリケーション バックログ バッファーに存在する場合は、部分的であることを示す +CONTINUE を応答します。レプリケーションが実行され、スレーブ ノードはマスターを待ちます。ノードは欠落したデータを送信します。
- マスター ノードのバージョンが十分に新しいが、runid がスレーブ ノードによって送信された runid と異なる場合、またはスレーブ ノードによって送信されたオフセット以降のデータがレプリケーション バックログ バッファーに存在しない (キューに押し出された) 場合、 +FULLRESYNC <runid> <offset> と応答すると、フル コピーを実行することを意味します。runid はマスター ノードの現在の runid を示し、offset はマスター ノードの現在のオフセットを示し、スレーブ ノードは将来の使用のためにこれら 2 つの値を保存します。 。
4. デモを部分的に再現する
以下のデモでは、数分間のネットワーク停止後に切断されたマスター/スレーブ ノードが部分的に複製されます。ネットワーク停止をシミュレートするために、この例のマスター/スレーブ ノードはローカル エリア ネットワーク内の 2 台のマシン上にあります。
ネットワークの中断
ネットワークが一定時間中断されると、マスター ノードとスレーブ ノードの両方が相互接続を失ったことに気づきます (マスター/スレーブ ノードのタイムアウトの判断メカニズムについては後述します)。 、スレーブ ノードはマスター ノードへの再接続を開始します。この時点ではネットワークが回復していないため、再接続は失敗し、スレーブ ノードは常に再接続を試みます。
メインノードのログは次のとおりです。

スレーブノードのログは次のとおりです。

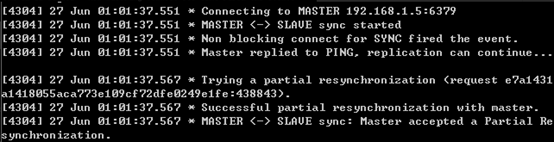
ネットワークの回復
ネットワークが復旧すると、スレーブ ノードはマスター ノードに正常に接続して部分レプリケーションを要求し、マスター ノードが要求を受信すると、両者は部分レプリケーションを実行してデータを同期します。
メインノードのログは次のとおりです。

スレーブノードのログは次のとおりです。
5. 【コマンド伝播フェーズ】ハートビートの仕組み
コマンド伝播フェーズでは、書き込みコマンドの送信に加えて、マスター ノードとスレーブ ノードはハートビート メカニズム (PING および REPLCONF ACK) も維持します。ハートビート機構はマスタスレーブレプリケーションのタイムアウト判定やデータセキュリティに役立ちます。
1. マスター→スレーブ: PING
マスターノードは指定時間ごとにスレーブノードに対してPINGコマンドを送信しますが、このPINGコマンドの役割は主にスレーブノードがタイムアウトを判定することです。
PING 送信の頻度は、repl-ping-slave-period パラメーターによって秒単位で制御され、デフォルト値は 10 秒です。
PING コマンドがマスター ノードからスレーブ ノードに送信されるか、またはその逆かについてはいくつかの議論があります。公式の Redis ドキュメントでは、パラメーターのコメントにスレーブ ノードがマスター ノードに PING コマンドを送信すると記載されているため、以下の図に示すように:

しかし、パラメータの名前(ping-slaveを含む)とコードの実装によると、PINGコマンドはマスターノードからスレーブノードに送信されると思います。関連するコードは次のとおりです。
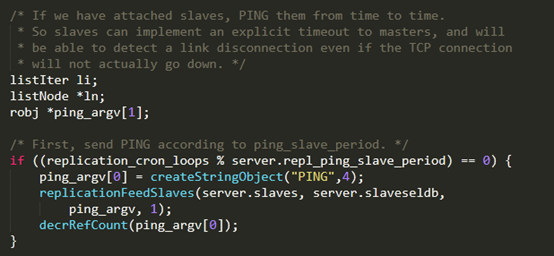
2. スレーブ -> マスター: REPLCONF ACK
コマンド伝播フェーズでは、スレーブ ノードは 1 秒に 1 回の頻度でREPLCONF ACKコマンドをマスター ノードに送信します。コマンドの形式は次のとおりです: REPLCONF ACK {offset}、ここでの offset はスレーブ ノードによって保存されたレプリケーション オフセットを指します。REPLCONF ACK コマンドの機能は次のとおりです。
(1) マスタノードとスレーブノードのネットワーク状態のリアルタイム監視: このコマンドはマスタノードがレプリケーションのタイムアウトを判断するために使用します。さらに、マスター ノードで info Replication を使用すると、マスター ノードが最後に REPLCONF ACK コマンドを受信した時間間隔を表すスレーブ ノードのステータスのラグ値を確認できます。通常の状況では、この値は 0 である必要があります。または、以下に示すように 1。

(2) コマンドロス検出: スレーブノードが自身のオフセットを送信し、マスターノードが自身のオフセットと比較し、スレーブノードのデータが欠落している場合(ネットワークパケットロスなど)、マスターノードが欠落データをプッシュします。 (ここでもレプリケーション バックログ バッファーを使用します)。オフセットおよびコピー バックログ バッファは、部分コピーだけでなく、コマンド損失などの状況に対処するためにも使用できることに注意してください。違いは、前者は切断および再接続後に実行されるのに対し、後者は切断および再接続後に実行されることです。この状況下では、マスター ノードとスレーブ ノードは切断されません。
(3) 補助はスレーブ ノードの数と遅延を保証します。Redis マスター ノードは min-slaves-to-write パラメーターと min-slaves-max-lag パラメーターを使用して、マスター ノードが安全でない状況で書き込みコマンドを実行しないようにします。いわゆる安全でないとは、スレーブ ノードの数が少なすぎるか、遅延が大きすぎることを意味します。たとえば、min-slaves-to-write と min-slaves-max-lag はそれぞれ 3 と 10 です。これは、スレーブ ノードの数が 3 未満であるか、すべてのスレーブ ノードの遅延値が 10 秒を超えていることを意味します。場合、マスターノードは書き込みコマンドの実行を拒否します。ここでのスレーブノードのディレイ値の取得は、マスタノードがREPLCONF ACKコマンドを受信した時刻、つまり前述のinfo Replicationにおけるラグ値によって判断される。
6. アプリケーションの問題点
1. 読み書き分離とその問題点
マスター/スレーブ レプリケーションに基づく読み取りと書き込みの分離により、Redis の読み取り負荷分散を実現できます。マスター ノードは書き込みサービスを提供し、1 つ以上のスレーブ ノードは読み取りサービスを提供します (複数のスレーブ ノードはデータの冗長性を向上させ、読み取り負荷を最大化することもできます)容量); 読み取り負荷が大きいアプリケーション シナリオでは、Redis サーバーの同時実行性を大幅に向上させることができます。Redis の読み取り/書き込み分離を使用する場合に注意する必要がある問題を次に紹介します。
(1) 遅延と不整合の問題
前述したように、マスター/スレーブ レプリケーションのコマンド伝播は非同期であるため、遅延とデータの不一致は避けられません。アプリケーションによるデータの不整合の許容度が低い場合は、マスター ノードとスレーブ ノード間のネットワーク環境の最適化 (同じコンピューター ルームに展開するなど)、マスター ノードとスレーブ ノードの遅延を (オフセットによって) 監視して、値が大きすぎる場合は、スレーブ ノードを介してデータを読み取らないようにアプリケーションに通知し、クラスターを使用して書き込み負荷と読み取り負荷を同時に拡張します。
スレーブ ノードのデータの不整合は、接続がデータ同期フェーズにあるときや、スレーブ ノードがマスター ノードとの接続を失ったときなど、コマンド伝播フェーズ以外の他の状況でより深刻になる可能性があります。スレーブ ノードのslave-serve-stale-dataパラメータはこれに関連しています: この場合、これはスレーブ ノードのパフォーマンスを制御します; これがyes (デフォルト値) の場合、スレーブ ノードは引き続きクライアントのコマンドに応答できます。 noの場合、スレーブノードはinfoやslaveofなどのいくつかのコマンドにのみ応答できます。このパラメータの設定は、アプリケーションのデータ整合性要件に関連しています。データ整合性要件が非常に高い場合は、「いいえ」に設定する必要があります。
(2) データ有効期限問題
Redis のスタンドアロン バージョンでは、2 つの削除戦略があります。
- 遅延削除: サーバーはデータを積極的に削除せず、クライアントが特定のデータをクエリした場合にのみ、サーバーがデータの有効期限が切れているかどうかを判断し、有効期限が切れている場合は削除します。
- 定期的な削除: サーバーはスケジュールされたタスクを実行して期限切れのデータを削除しますが、メモリと CPU の間の妥協点 (削除するとメモリは解放されますが、頻繁な削除操作は CPU に優しくありません) を考慮して、この削除の頻度と実行時間は制限されます。
マスター/スレーブ レプリケーション シナリオでは、マスター ノードとスレーブ ノードのデータの整合性を確保するために、スレーブ ノードはデータを積極的に削除しませんが、マスター ノードはスレーブ ノード内の期限切れデータの削除を制御します。マスター ノードの遅延削除と定期的な削除戦略により、マスター ノードは期限切れのデータを適時に削除することを保証できません。そのため、クライアントが Redis 経由でノードからデータを読み取る場合、簡単に削除できます。期限切れのデータを読み取ります。
Redis 3.2 では、スレーブ ノードがデータを読み取るときに、データの有効期限が切れているかどうかの判断が追加されます。データの有効期限が切れている場合、データはクライアントに返されません。Redis を 3.2 にアップグレードすると、データの有効期限の問題を解決できます。
(3) フェイルオーバーの問題
Sentinel を使用しない読み取り/書き込み分離シナリオでは、アプリケーションは読み取りと書き込みのために異なる Redis ノードに接続します。マスター ノードまたはスレーブ ノードに問題が発生して変更された場合、読み取りと書き込みを行うためにアプリケーションの接続を変更する必要があります。 Redis データを時間内に接続; 接続の切り替え 手動で切り替えることも、監視プログラムを自分で作成することによって切り替えることもできますが、前者は応答が遅くエラーが発生しやすく、後者は実装が複雑でコストも低くありません。
(4) まとめ
読み取りと書き込みの分離を使用する前に、Redis の読み取り負荷容量を増やす他の方法を検討できます。たとえば、マスター ノードを可能な限り最適化する (遅いクエリを減らし、永続性などの他の状況によって引き起こされるブロックを減らす) などです。負荷容量の向上、Redis クラスターを使用して読み取り負荷容量を同時に増加させる 負荷容量と書き込み負荷容量など。読み取りと書き込みの分離を使用する場合、センチネルを使用してマスター ノードとスレーブ ノードのフェイルオーバーを可能な限り自動化し、アプリケーションへの侵入を減らすことができます。
2. レプリケーションのタイムアウトの問題
マスター/スレーブ ノードのレプリケーション タイムアウトは、レプリケーション中断の最も重要な理由の 1 つです。このセクションではタイムアウトの問題について個別に説明し、次のセクションではレプリケーション中断の原因となる可能性のあるその他の問題について説明します。
タイムアウト判定の意味
レプリケーション接続の確立中および確立後に、マスター ノードとスレーブ ノードには、接続がタイムアウトしたかどうかを判断するメカニズムが備わっています。これは、次のことを意味します。
(1) マスターノードが接続がタイムアウトしたと判断した場合、対応するスレーブノードの接続を解放し、さまざまなリソースを解放します。そうでない場合、無効なスレーブノードは引き続きマスターノードのさまざまなリソース(出力バッファ、帯域幅)を占有します。また、接続タイムアウトの判定により、マスターノードは現在有効なスレーブノードの数をより正確に知ることができ、データセキュリティの確保に役立ちます(min-slaves-toなどのパラメータと連携してください) -上記のことを書いてください)。
(2) スレーブ ノードは、接続がタイムアウトしたと判断した場合、マスター ノードのデータとの長期にわたる不一致を回避するために、時間内に接続を再確立できます。
判断の仕組み
マスター/スレーブ レプリケーションのタイムアウト判定の中核は repl-timeout パラメータにあり、これはタイムアウトしきい値 (デフォルトでは 60 秒) を指定します。これはマスター ノードとスレーブ ノードの両方で有効であり、マスター/スレーブ ノードがトリガーされる条件です。タイムアウトは次のとおりです。
(1) マスタノード:レプリケーションタイミング関数 replicationCron()を 1 秒に 1 回呼び出し、現在時間が各スレーブノードから最後に REPLCONF ACK を受信してからの repl-timeout 値より長いかどうかを判定し、したがって、ノードから対応する接続を解放します。
(2) スレーブノード:スレーブノードのタイムアウト判定もレプリケーションタイミング機能で判定します 基本ロジックは以下の通りです。
- 現在接続確立フェーズにあり、最後にマスター ノードから情報を受信してからの時間が repl-timeout を超えている場合は、マスター ノードとの接続を解放します。
- 現在データ同期段階にあり、マスター ノードからの RDB ファイルの受信時間がタイムアウトになった場合は、データ同期を停止して接続を解放します。
- 現在コマンド伝播フェーズにあり、最後にマスター ノードから PING コマンドまたはデータを受信してからの時間が repl-timeout 値を超えている場合は、マスター ノードとの接続を解放します。
接続タイムアウトを判断するマスター/スレーブノードの関連ソースコードは次のとおりです。
/* Replication cron function, called 1 time per second. */
void replicationCron(void) {
static long long replication_cron_loops = 0;
/* Non blocking connection timeout? */
if (server.masterhost &&
(server.repl_state == REDIS_REPL_CONNECTING ||
slaveIsInHandshakeState()) &&
(time(NULL)-server.repl_transfer_lastio) > server.repl_timeout)
{
redisLog(REDIS_WARNING,"Timeout connecting to the MASTER...");
undoConnectWithMaster();
}
/* Bulk transfer I/O timeout? */
if (server.masterhost && server.repl_state == REDIS_REPL_TRANSFER &&
(time(NULL)-server.repl_transfer_lastio) > server.repl_timeout)
{
redisLog(REDIS_WARNING,"Timeout receiving bulk data from MASTER... If the problem persists try to set the 'repl-timeout' parameter in redis.conf to a larger value.");
replicationAbortSyncTransfer();
}
/* Timed out master when we are an already connected slave? */
if (server.masterhost && server.repl_state == REDIS_REPL_CONNECTED &&
(time(NULL)-server.master->lastinteraction) > server.repl_timeout)
{
redisLog(REDIS_WARNING,"MASTER timeout: no data nor PING received...");
freeClient(server.master);
}
//此处省略无关代码……
/* Disconnect timedout slaves. */
if (listLength(server.slaves)) {
listIter li;
listNode *ln;
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
redisClient *slave = ln->value;
if (slave->replstate != REDIS_REPL_ONLINE) continue;
if (slave->flags & REDIS_PRE_PSYNC) continue;
if ((server.unixtime - slave->repl_ack_time) > server.repl_timeout)
{
redisLog(REDIS_WARNING, "Disconnecting timedout slave: %s",
replicationGetSlaveName(slave));
freeClient(slave);
}
}
}
//此处省略无关代码……
}注意すべきピット
レプリケーションフェーズ中の接続タイムアウトに関連する実際的な問題をいくつか次に示します。
(1) データ同期段階: マスター/スレーブ ノードが bgsave のフル コピーを実行する場合、マスター ノードはまず子プロセスをフォークして現在のデータを RDB ファイルに保存し、次に RDB ファイルをスレーブ ノードに転送する必要があります。ネットワークを通じて。RDBファイルが大きすぎると、マスターノードが子プロセスのfork+RDBファイルの保存に時間がかかりすぎ、スレーブノードが長時間データの受信に失敗してタイムアウトが発生する可能性がありますが、このとき、スレーブ ノードはマスター ノードに再接続し、その後再びフルになります。レプリケーション、タイムアウト、再接続...これは悲しいサイクルです。この状況を回避するには、Redis スタンドアロンのデータ量が大きすぎないことに注意することに加えて、repl-timeout 値を適切に増やす必要があります。 bgsave には時間がかかります。
(2) コマンド伝播フェーズ: 前述したように、このフェーズでは、マスター ノードがスレーブ ノードに PING コマンドを送信し、頻度は repl-ping-slave-period によって制御されます。このパラメータは、 repl-timeout 値 (後者は前者の少なくとも数倍です)。2 つのパラメータが等しいか近い場合、ネットワーク ジッターにより個々の PING コマンドが失われますが、このときマスター ノードはスレーブ ノードにデータを送信せず、スレーブ ノードはタイムアウトを簡単に判断できます。
(3) 遅いクエリによるブロック: マスター ノードまたはスレーブ ノードがいくつかの遅いクエリ (ビッグ データの key * や hgetall など) を実行すると、サーバーがブロックされ、レプリケーションがタイムアウトになります。
3. レプリケーション中断問題
マスター/スレーブ ノードのタイムアウトは、レプリケーション中断の原因の 1 つですが、レプリケーション中断を引き起こす可能性のある状況は他にもありますが、その中で最も重要なのはレプリケーション バッファ オーバーフローの問題です。
コピーバッファオーバーフロー
前述したように、フル コピー フェーズでは、マスター ノードは実行された書き込みコマンドをレプリケーション バッファーに置き、このバッファーに格納されたデータには、次の期間にマスター ノードによって実行された書き込みコマンドが含まれます。 bgsave は RDB ファイルを生成します。 RDB ファイルはマスター ノードからスレーブ ノードに送信され、スレーブ ノードは古いデータをクリアして RDB ファイルにデータをロードします。マスターノードに大量のデータがある場合、またはマスターノードとスレーブノード間のネットワーク遅延が大きい場合、バッファのサイズが制限を超える可能性があり、この時点でマスターノードはスレーブノードから切断されます。フルコピー -> コピーバッファオーバーフローによる接続中断 -> 再接続 -> フルコピー -> コピーバッファオーバーフローによる接続中断...というサイクルが発生する可能性があります。
コピー バッファのサイズは、client-output-buffer-limit スレーブ {ハード リミット} {ソフト リミット} {ソフト秒} によって構成されます。デフォルト値は client-output-buffer-limit スレーブ 256MB 64MB 60 です。これは、次のことを意味します。バッファーが 256MB を超えるか、60 秒連続で 64MB を超えると、マスター ノードはスレーブ ノードから切断されます。このパラメーターは、config set コマンドを使用して動的に構成できます (つまり、Redis を再起動しなくても有効になります)。
レプリケーション バッファーがオーバーフローすると、マスター ノードは次のようにログを出力します。

コピー バッファはクライアント出力バッファの一種であり、マスター ノードは各スレーブ ノードにコピー バッファを割り当てますが、コピー バックログ バッファは、スレーブ ノードがいくつあっても、マスター ノードは 1 つだけであることに注意してください。
4. 各シナリオにおけるレプリケーションの選択と最適化手法
Redis レプリケーションの詳細を紹介した後、部分レプリケーションをいつ使用するか、および次の一般的なシナリオでどのような問題に注意する必要があるかを要約できます。
(1) 初めてコピーを作成する
現時点では完全なレプリケーションは避けられませんが、マスター ノードに大量のデータがある場合は、輻輳を避けるためにトラフィックのピーク時間帯を避けるようにしてください。複数のスレーブ ノードがある場合は、注意すべき点がいくつかあります。マスター ノードのレプリケーションを確立する必要がある場合は、マスター ノードの過度の帯域幅占有を避けるために、複数のスレーブ ノードをずらすことを検討できます。さらに、スレーブ ノードが多すぎる場合は、マスター/スレーブ レプリケーションのトポロジを調整して、マスター/複数スレーブ構造からツリー構造に変更することもできます (中間ノードはマスター ノードのスレーブ ノードであり、ただし、ツリー構造を使用する場合は、マスター ノードの直接のスレーブ ノードの数が減り、マスター ノードの負担は軽減されますが、マルチノードの遅延が大きくなることに注意する必要があります。階層スレーブノードが増えてデータの整合性が悪くなり、構造が複雑になりメンテナンスが非常に困難になります。
(2) マスターノードの再起動
マスターノードの再起動は、障害によるダウンタイムと計画的な再起動の 2 つの状況に分けて説明します。
マスターノードがダウンしている
マスターノードが停止して再起動されると、runid が変更されるため、部分レプリケーションは実行できなくなり、完全レプリケーションのみが可能になります。
実際、マスター ノードがダウンした場合は、フェイルオーバー処理が実行され、スレーブ ノードの 1 つがマスター ノードにアップグレードされ、他のスレーブ ノードは新しいマスター ノードからコピーされ、フェイルオーバーは自動化される必要があります。次の記事で紹介するように、Sentinel は自動フェイルオーバーを実行できます。
安全な再起動: デバッグのリロード
シナリオによっては、マスター ノードのメモリ断片化率が高すぎる場合や、起動時にのみ調整できる一部のパラメーターを調整する場合など、マスター ノードを再起動する必要がある場合があります。通常の方法でマスターノードを再起動すると runid が変更され、不必要な完全レプリケーションが発生する可能性があります。
この問題を解決するために、Redis はデバッグ リロードの再起動メソッドを提供します。再起動後、マスター ノードのrunidとオフセットは影響を受けず、完全なレプリケーションが回避されます。
次の図に示すように、デバッグ リロードの再起動後、runid と offset は影響を受けません。
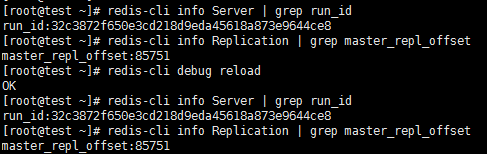
ただし、デバッグリロードは諸刃の剣で、カレントメモリ上のデータをクリアしてRDBファイルから再ロードすることにより、マスターノードの閉塞を引き起こすため注意が必要です。
(3) ノードからの再起動
スレーブノードがダウンして再起動すると、スレーブノードが保存していたマスターノードのrunidが失われるため、再度slaveofを実行しても部分レプリケーションは行えません。
(4) ネットワークの中断
マスター ノードとスレーブ ノードの間にネットワークの問題があり、短期間のネットワーク中断が発生する場合は、複数の状況に分けて議論することができます。
ケース 1: ネットワークの問題は非常に短期間で発生し、短期間のパケット損失のみが発生し、マスター ノードもスレーブ ノードもタイムアウトを判断していません (repl-timeout がトリガーされていません)。現時点では、タイムアウトだけが発生しています。 REPLCONF ACK を通じて失われたデータを補うために必要です。
2 番目の状況: ネットワークの問題が長時間続き、マスター/スレーブ ノードがタイムアウトと判断し (repl-timeout がトリガーされる)、失われたデータが多すぎてレプリケーション バックログ バッファーの保存範囲を超えます。この時点では、 、マスター/スレーブ ノードは部分コピーはできず、完全コピーのみです。この状況を可能な限り回避するには、レプリケーション バックログ バッファのサイズを実際の状況に応じて適切に調整する必要があります。また、ネットワーク中断をタイムリーに検出して修復することで、完全なレプリケーションを減らすこともできます。
3 番目のケース: 上記 2 つのケースの間で、マスタ/スレーブ ノードの判定がタイムアウトになり、失われたデータがレプリケーション バックログ バッファに残っている場合、この時点ではマスタ/スレーブ ノードは部分レプリケーションを実行できます。
5. 関連設定のコピー
ここでは、レプリケーションに関連する設定をまとめ、各設定の機能、動作フェーズ、設定方法などを説明し、これらの設定を理解することで、Redis レプリケーションについての理解が深まる一方で、一方、これらの構成の方法をマスターすると、Redis の使用を最適化し、落とし穴を回避できます。
構成は大きく分けて、マスターノードに関する構成、スレーブノードに関する構成、およびマスターノードとスレーブノードの両方に関する構成に分けて説明します。
(1) マスターノードとスレーブノードの両方に関する設定
最も具体的な構成が最初に導入され、ノードがマスターかスレーブかを決定します。
1) smileof <masterip> <masterport>: Redis の起動時に機能します; この機能はレプリケーション関係を確立することであり、この構成がオンになっている Redis サーバーは起動後にスレーブ ノードになります。このコメントはデフォルトでコメントアウトされます。つまり、Redis サーバーがデフォルトでマスターノードになります。
2) repl-timeout 60: 各段階でのマスター/スレーブ ノード接続のタイムアウト判定に関連します。前の紹介を参照してください。
(2) マスターノード関連の設定
1) repl-diskless-sync no: フル レプリケーション フェーズで使用され、プライマリ ノードがディスクレス レプリケーション (ディスクレス レプリケーション) を使用するかどうかを制御します。いわゆるディスクレス レプリケーションとは、完全レプリケーション中に、マスター ノードが最初にデータを RDB ファイルに書き込むのではなく、スレーブのソケットに直接書き込むことを意味します。プロセス全体にハードディスクは関与しません。ディスクレス レプリケーションは、ディスク IO とネットワーク速度が遅い 速いほど有利です。Redis 3.0 の時点では、ディスクレス レプリケーションは実験段階にあり、デフォルトでは無効になっていることに注意してください。
2) repl-diskless-sync-delay 5: この設定は完全なレプリケーション フェーズに適用されます。マスター ノードがディスクレス レプリケーションを使用する場合、この設定はマスター ノードがスレーブ ノードに送信する前の一時停止時間を秒単位で決定します (ディスクレスの場合のみ)。レプリケーションが有効です。有効です。デフォルトは 5 秒です。一時停止時間が設定される理由は、次の 2 つの考慮事項に基づいています。 (1) スレーブのソケットへの送信が開始されると、新しく接続されたスレーブは、新しいデータを開始する前に現在のデータ送信の終了を待つことしかできません。 (2) 複数のスレーブノード 短時間でマスター/スレーブレプリケーションを確立できる可能性が高くなります。
3) client-output-buffer-limit スレーブ 256MB 64MB 60: フル コピー フェーズのマスター ノードのバッファ サイズに関連します。前の紹介を参照してください。
4) repl-disable-tcp-nolay no: コマンド伝播フェーズの遅延に関連します。前の紹介を参照してください。
5) masterauth <master-password>: 接続確立フェーズの ID 検証に関連します。前の紹介を参照してください。
6) repl-ping-slave-period 10: コマンド伝播フェーズにおけるマスター/スレーブ ノードのタイムアウト判定に関連します。前の紹介を参照してください。
7) repl-backlog-size 1mb: レプリケーション バックログ バッファーのサイズ。前の説明を参照してください。
8) repl-backlog-ttl 3600: マスター ノードにスレーブ ノードがない場合、切断されたスレーブ ノードが再接続したときに部分的なレプリケーションを実行できるように、レプリケーション バックログ バッファーを保持する時間。デフォルトは 3600 秒です。0 に設定すると、コピー バックログ バッファは解放されません。
9) min-slaves-to-write 3 および min-slaves-max-lag 10: マスター ノードのスレーブ ノードの最小数と、対応する最大遅延を指定します。前の説明を参照してください。
(3) スレーブノード関連の設定
1)slave-serve-stale-data yes: データが古いときにスレーブ ノードがクライアント コマンドに応答するかどうかに関連します。前の紹介を参照してください。
2) スレーブ読み取り専用 はい: スレーブ ノードが読み取り専用かどうか; デフォルトは読み取り専用です。スレーブノードが書き込み動作を開始すると、マスターノードとスレーブノードのデータが不整合になる可能性が高いため、この構成はできるだけ変更しないでください。
6. スタンドアロンのメモリ サイズ制限
「Deep Learning Redis、Redis Persistence」の記事では 、Redis スタンドアロン マシンのメモリ サイズに対するフォーク操作の制限について説明しました。実際、Redis の使用には、スタンドアロン メモリのサイズを制限する多くの要因があります。マスター/スレーブ レプリケーションにおける過剰なスタンドアロン メモリの考えられる影響を以下にまとめます。
(1) マスター カット: マスター ノードがダウンした場合、一般的な災害復旧戦略は、スレーブ ノードの 1 つをマスター ノードに昇格させ、他のスレーブ ノードを新しいマスター ノードにマウントすることです。スタンドアロンのメモリが 10GB に達すると、スレーブ ノードの同期時間は数分レベルになりますが、スレーブ ノードの数が増えると、回復速度が遅くなります。システムの読み取り負荷が高く、この期間にスレーブ ノードがサービスを提供できない場合、システムに多大な負荷がかかります。
(2) スレーブライブラリの拡張:トラフィックが急激に増加した場合、読み込み負荷を分散するためにスレーブノードを増やすことが望ましいですが、データ量が多すぎるとスレーブノードの同期が遅すぎて対応が困難になります。タイムリーにトラフィックが突然増加します。
(3) バッファ オーバーフロー: (1) と (2) はどちらも、スレーブ ノードは正常に同期できますが (遅いですが)、データ量が多すぎるとマスター ノードのレプリケーション バッファが満杯になる場合です。レプリケーションフェーズがオーバーフローしてレプリケーションが中断されると、マスター/スレーブノードのデータ同期が完全にレプリケーションされます -> レプリケーションバッファオーバーフローによりレプリケーションが中断されます -> 再接続 -> 完全レプリケーション -> レプリケーションバッファオーバーフローによりレプリケーションが中断されます。 ..サイクル。
(4) タイムアウト: データ量が大きすぎると、フルコピーフェーズでマスターノードが RDB ファイルをフォークして保存するのに時間がかかりすぎ、スレーブノードは長時間データを受信できずにタイムアウトが発生します。 、マスター/スレーブノードのデータ同期も、フルコピー→タイムアウトによりレプリケーション中断→再接続→フルレプリケーション→タイムアウトによりレプリケーション中断…というサイクルに陥る可能性もあります。
さらに、マスター ノードの単一マシン メモリの絶対量は大きすぎてはならず、ホストのメモリに占めるメモリの割合も大きすぎてはなりません。メモリの 50% ~ 65% のみを使用し、30 個を残すのが最善です。 bgsave コマンドやコピー バッファの作成などに使用するメモリの % ~ 45%。
7. 情報レプリケーション
Redis クライアントの info Replication を通じてレプリケーションに関連するステータスを表示できます。これは、マスター/スレーブ ノードの現在のステータスを理解し、発生する問題を解決するのに役立ちます。
マスターノード:

ノードから:
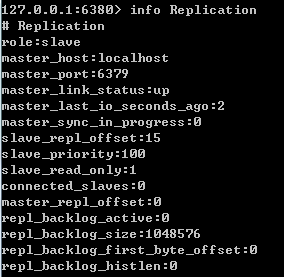
スレーブノードの場合、上部はスレーブノードとしてのステータスを示し、connectd_slaves から始まり、潜在的なマスターノードとしてのステータスを示します。
info Replication に表示される内容のほとんどは記事で説明されているため、ここでは詳しく説明しません。
7. まとめ
この記事の主な内容を確認してみましょう。
1. マスター/スレーブ レプリケーションの役割: マスター/スレーブ レプリケーションがどのような種類の問題 (データ冗長性、障害回復、読み取りロード バランシングなど) を解決するように設計されているかをマクロで理解します。
2. マスター/スレーブ レプリケーションの操作:slaveof コマンド。
3. マスター/スレーブ レプリケーションの原理: マスター/スレーブ レプリケーションには、接続確立フェーズ、データ同期フェーズ、およびコマンド伝播フェーズが含まれます。データ同期フェーズには、完全レプリケーションと部分レプリケーションの 2 つのデータ同期方法があります。コマンド伝播フェーズ、マスター/スレーブ ノード 相互のハートビートを確認するための PING および REPLCONF ACK コマンドがあります。
4. アプリケーションの問題: 読み取りと書き込みの分離 (データの不整合、データの有効期限、フェイルオーバーなど)、レプリケーションのタイムアウト、レプリケーションの中断などの問題を含み、マスター/スレーブ レプリケーションに関連する構成を要約します。 repl-Timeout、client-output-buffer-limit slide などは、Redis マスター/スレーブ レプリケーションの問題を解決するのに役立つ場合があります。
マスター/スレーブ レプリケーションは、データの冗長性、障害回復、読み取り負荷分散などの問題を解決または軽減しますが、障害回復を自動化できない、書き込み操作の負荷分散ができない、ストレージ容量が 1 台のマシンによって制限される、などの欠点は依然として明らかです。これらの問題の解決策には、セントリーとクラスターの助けが必要です。次の記事で紹介します。注目してください。
参考文献
「Redisの開発と運用保守」
「Redisの設計と実装」
「アクション中の Redis」
http://mdba.cn/2015/03/16/redis レプリケーション中断の問題 - クエリが遅い/
https://redislabs.com/blog/top-redis-headaches-for-devops-replication-buffer/
http://mdba.cn/2015/03/17/redis マスター/スレーブ レプリケーション (2)-レプリケーション バッファーとレプリケーション バックログ/