目次
4. Redis クラスターのマスター/スレーブ レプリケーション モデル
1. Redis の高可用性
Web サーバーにおける高可用性とは、サーバーに正常にアクセスできる時間を指し、通常のサービスをどれだけ長く提供できるかを測定します。(99.9%、99.99%、99.999%など)
高可用性の計算式は 1-(ダウンタイム)/(ダウンタイム + 実行時間) で、これはネットワーク送信パラメータのビット誤り率に似ています。可用性を表すには 9 という数字を使用します。
2 ナイン: 99%=1%365=3.6524h=87.6h
フォーナイン: 99.99%=0.01%36524*60=52.56分
ファイブナイン: 99.999%=0.001%*365=5.265分
11 ナイン: わずか数分でほぼ 1 年間のダウンタイムが発生
ただし、Redis の文脈での高可用性の意味はもっと広いと思われ、通常のサービス(マスター/スレーブ分離や迅速な災害復旧技術など)の提供を確保することに加えて、高可用性の拡張も考慮する必要があります。損失のないデータ容量とデータセキュリティ。
Redis では、高可用性を実現するテクノロジーには、主に永続性、マスター/スレーブ レプリケーション、センチネル、クラスター クラスターが含まれます。
1.持久化
永続化は最も単純な高可用性方法です (高可用性方法として分類されない場合もあります)。その主な機能はデータのバックアップ、つまり、プロセスによってデータが失われないようにデータをハードディスクに保存することです。出口。
2. マスター/スレーブ レプリケーション
マスター/スレーブ レプリケーションは高可用性 Redis の基礎であり、センチネルとクラスターは高可用性を実現するためにマスター/スレーブ レプリケーションに基づいています。マスター/スレーブ レプリケーションでは、主にデータのマルチマシン バックアップ、読み取り操作の負荷分散、および単純な障害回復が実装されます。
欠点: 障害回復は自動化できません。書き込み操作の負荷分散はできません。ストレージ容量は 1 台のマシンによって制限されます。
3. セントリー
マスター/スレーブ レプリケーションに基づいて、Sentinel はマスター ノードの自動障害回復を実現しますが、スレーブ ノードを自動的にフェイルオーバーすることはできません。読み取り/書き込み分離シナリオでは、スレーブ ノードの障害により読み取りサービスが停止されます。利用できません。
欠点: 書き込み操作は負荷分散できません。ストレージ容量は 1 台のマシンによって制限されます。スレーブ ノードの追加監視が必要です。
4. クラスタークラスター
Redis はクラスターを通じて、書き込み操作の負荷分散ができず、ストレージ容量が単一マシンによって制限されるという問題を解決し、比較的完全な高可用性ソリューションを実現します。
短所: コストとリソースの要件が満たされます。
2. マスター/スレーブ レプリケーション
1.コンセプト
マスター/スレーブ レプリケーションとは、1 つの Redis サーバーのデータを他の Redis サーバーにコピーすることを指します。前者はマスターノードMasterと呼ばれ、後者はスレーブノードSlaveと呼ばれます。
データ レプリケーションは一方向であり、マスター ノードからスレーブ ノードへのみです
。デフォルトでは、各 Redis サーバーはマスター ノードであり、マスター ノードは複数のスレーブ ノードを持つことができます (またはスレーブ ノードを持たないこともできます)。ただし、スレーブ ノードは 1 つしかありません。 1 つのマスターノードになります。
2.機能
(1) データ冗長化:マスタ・スレーブレプリケーションは、永続化以外のデータ冗長化方式であるデータのホットバックアップを実現します。
(2) 障害回復:マスター ノードに問題が発生した場合、スレーブ ノードは迅速な障害回復を実現するためのサービスを提供できますが、これは実際には一種のサービス冗長です。
(3) 負荷分散:マスター/スレーブ レプリケーションに基づいて、読み書き分離と組み合わせることで、マスター ノードは書き込みサービスを提供し、スレーブ ノードは読み取りサービスを提供できます (つまり、アプリケーションは、次の場合にマスター ノードに接続します)。 Redis データの書き込み、および Redis データの読み取り時にアプリケーションが接続します。スレーブ ノード) を使用してサーバーの負荷を共有します。特に書き込みを減らし、読み取りを増やすシナリオでは、複数のスレーブ ノードで読み取り負荷を共有すると、Redis サーバーの同時実行性が大幅に向上します。 。
(4) 高可用性の基礎:上記の機能に加えて、マスター/スレーブ レプリケーションはセンチネルやクラスターの実装の基盤でもあり、したがって、マスター/スレーブ レプリケーションは Redis の高可用性の基盤となります。
3. マスター/スレーブ レプリケーション プロセス
(1)スレーブ マシンのプロセスが開始されると、マスター マシンに「sync command」コマンドを送信して同期接続を要求します。
(2)最初の接続であっても再接続であっても、マスター マシンはバックグラウンド プロセスを開始してデータ ファイルにデータ スナップショットを保存し (rdb 操作を実行)、マスターはデータとキャッシュを変更するためのすべてのコマンドも記録します。データファイルの途中にあります。
(3)バックグラウンド プロセスがキャッシュ操作を完了した後、マスター マシンはデータ ファイルをスレーブ マシンに送信し、スレーブ マシンはデータ ファイルをハードディスクに保存してメモリにロードし、次にマスター マシンがデータ ファイルをスレーブ マシンに送信します。マシンはすべてのデータ ファイルを変更します。操作はスレーブ マシンにも送信されます。スレーブに障害が発生してダウンタイムが発生した場合、通常に戻った後、自動的に再接続されます。
(4)マスター マシンがスレーブ マシンからの接続を受信した後、完全なデータ ファイルをスレーブ マシンに送信します。マスターが複数のスレーブから同期要求を同時に受信した場合、マスターはバックグラウンドでプロセスを開始し、データファイルを保存してすべてのスレーブマシンに送信し、すべてのスレーブマシンが正常であることを確認します。
4. マスター/スレーブ レプリケーションを構成する
マスターノード: 192.168.116.40
スレーブノード: 192.168.116.50
スレーブノード: 192.168.116.60
マスターおよびスレーブノード構成ファイルの変更
vim /etc/redis/6379.conf
#70行,每台添加本机的地址
bind 127.0.0.1 192.168.116.40
#700行,开启AOF
appendonly yesノードから追加
vim /etc/redis/6379.conf
#288行,指定master
replicaof 192.168.116.40 6379

ログを確認すると、マスターとスレーブが RDB データを完全に同期していることがわかります。
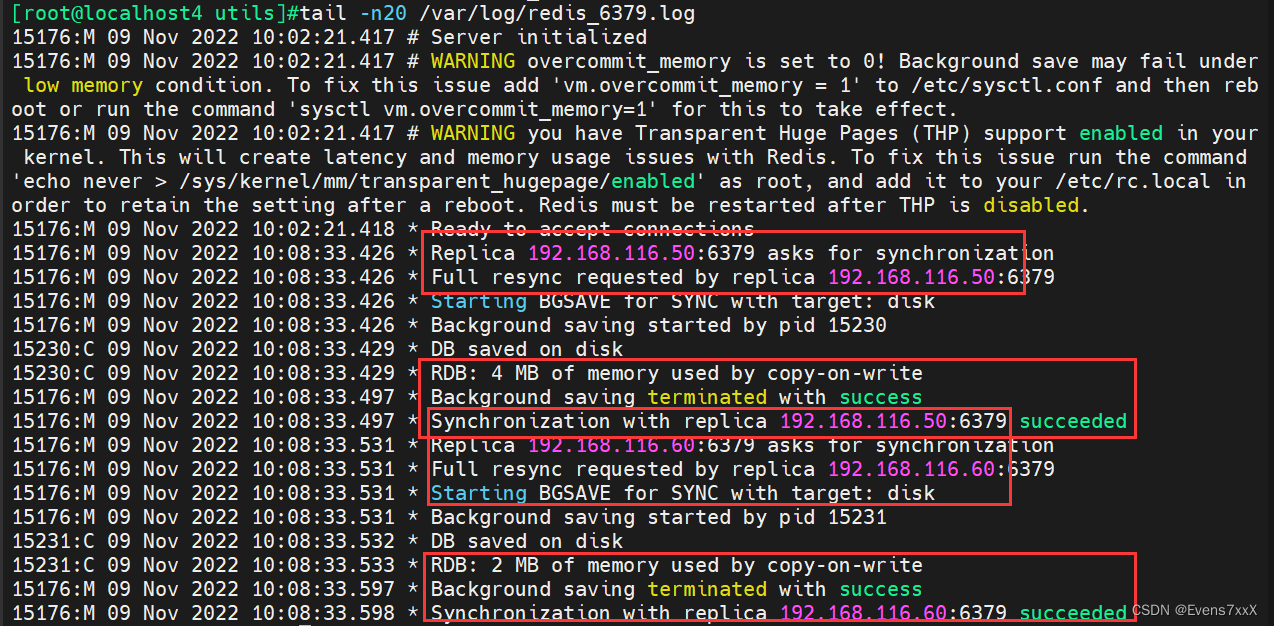
情報レプリケーションを実行して同期情報を表示する

主にデータの追加、同期のテスト

スレーブノードにこのデータがあるかどうかを確認します (あれば、同期は成功します)。

3.センチネルモード
1.機能
Sentinel は、マスター/スレーブ レプリケーションに基づいて、マスター ノードの自動フェイルオーバーを導入します。
2.機能
監視: Sentry は、マスター ノードとスレーブ ノードが適切に機能していることを常にチェックします。
自動フェイルオーバー:マスター ノードが正常に動作しない場合、Sentinel は自動フェイルオーバー操作を開始します。障害が発生したマスター ノードのスレーブ ノードの 1 つを新しいマスター ノードにアップグレードし、代わりに他のスレーブ ノードに新しいマスター ノードをコピーさせます。 。
通知: Sentry はフェイルオーバー結果をクライアントに送信できます。
3. 構成
Sentinel ノード: Sentinel システムは、データを保存しない特別な Redis ノードである 1 つ以上の Sentinel ノードで構成されます。
データ ノード:マスター ノードとスレーブ ノードは両方ともデータ ノードです。
4. フェイルオーバーメカニズム
(1) センチネルノードはマスターノードに障害がないか定期的に監視しており、各センチネルノードはマスターノード、スレーブノード、その他のセンチネルノードに1秒ごとにpingコマンドを送信してハートビートテストを行います。マスター ノードが一定の時間内に応答しない場合、またはエラー メッセージで応答した場合、センチネル ノードの半数以上がマスター ノードがオフラインであると判断した場合、センチネルは主観的にマスター ノードが(一方的に)オフラインであると判断します。主観的にはオフラインですが、これは客観的にはオフラインです。
(2) マスター ノードに障害が発生した場合、センチネル ノードは Raft アルゴリズム (選挙アルゴリズム) を通じて選挙メカニズムを実装し、マスター ノードのフェイルオーバーと通知の処理を担当するリーダーとしてセンチネル ノードを共同で選出します。したがって、Sentinel を実行するクラスターの数は 3 ノード以上である必要があります。
(3) フェイルオーバーはリーダーセンチネルノードによって実行され、プロセスは次のようになります。
スレーブ ノードを新しいマスター ノードにアップグレードし、他のスレーブ ノードが新しいマスター ノードを指すようにします。元のマスター ノードが回復すると、そのノードもスレーブ ノードになり、新しいマスター ノードを指すようになります。マスター ノードが回復したことをクライアントに通知します。ノードが交換されました。
客観的オフラインはマスター ノードに固有の概念であることに注意することが重要です。スレーブ ノードまたはセンチネル ノードに障害が発生し、センチネルによって主観的にオフラインになった場合、その後の客観的オフラインおよびフェイルオーバー操作は行われません。
5. マスターノード選択の基礎
- センチネルの ping 応答に応答しない、異常な (オフラインの) スレーブ ノードをフィルターで除外します。
- 構成ファイル内で最も優先度の高い構成を持つスレーブ ノードを選択します。(レプリカの優先順位、デフォルト値は 100)
- 最大のレプリケーション オフセットを持つスレーブ ノード、つまり最も完全なレプリケーションを選択します。
6.センチネルモードの設定
まず、マスター/スレーブ レプリケーションを適切に行う必要があります。これで前の部分は完了です。
Sentinel 設定ファイルをコピーして変更する
cp /opt/redis-5.0.7/sentinel.conf /etc/redis/
cd /etc/redis/
vim sentinel.conf
#关闭保护模式
protected-mode no
#默认端口
port 26379
#打开后台运行
daemonize yes
#指定哨兵的pid和日志文件
pidfile "/var/run/redis-sentinel.pid"
logfile "/var/log/sentinel.log"
#指定redis数据文件
dir "/var/lib/redis/6379"
#指定哨兵模式主节点(2代表最少两个哨兵主观认为主宕机,才是客观宕机)
sentinel monitor mymaster 192.168.116.40 6379 2
#判定服务器down掉的时间周期,默认30000毫秒(30秒)
sentinel down-after-milliseconds mymaster 10000
#同一个sentinel对同一个master两次故障恢复之间的间隔时间(180秒)
sentinel failover-timeout mymaster 180000変更したファイルをスレーブノードにコピーし、サービスを再起動します
#在主节点的/etc/redis/下执行远程传输
scp sentinel.conf 192.168.116.50:`pwd`
scp sentinel.conf 192.168.116.60:`pwd`
#从节点重启服务加载配置
service redis restartセントリーモードを開始する
#主从都执行
/usr/local/redis/bin/redis-sentinel sentinel.conf
セントリーモード情報の表示

7. 故障シミュレーション
まずセンチネル ログを追跡します。マスターとスレーブが正常であることが示されています。
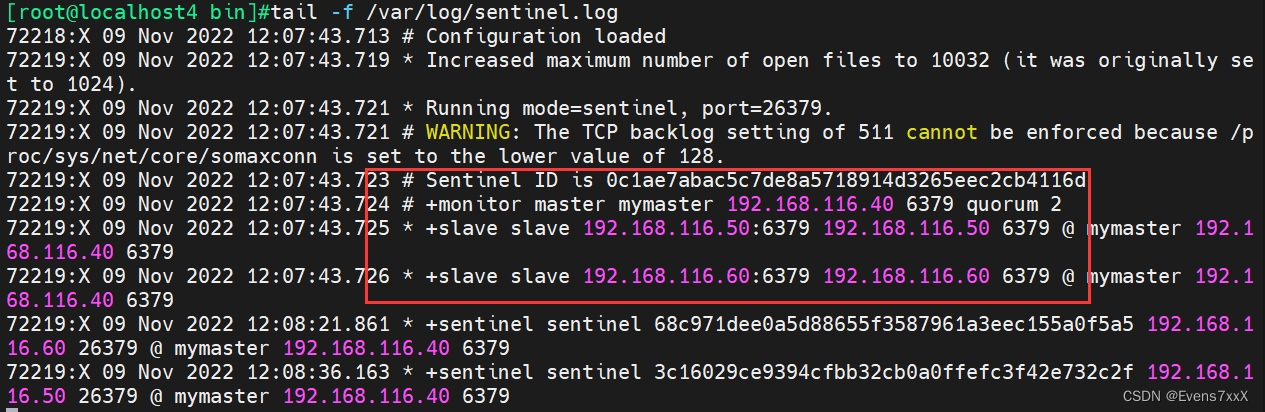
マスターノードのredisサービスを終了し、フェイルオーバーが完了したかどうかを確認します。

新しいマスターノードの情報を確認します

スレーブノード構成ファイルの表示


8. 障害が発生したノードの復元
元のダウンタイム マスター ノードを復元して、スレーブ ノードに参加できるかどうかを確認します。

構成ファイルを表示する


回復に成功しました!
4、クラスタークラスター
1 はじめに
クラスター、つまり Redis クラスターは、Redis 3.0 によって導入された分散ストレージ ソリューションです。
クラスターは複数のノード グループ (ノード) で構成され、Redis データはこれらのノード間に分散されます。クラスター内のノードはマスター ノードとスレーブ ノードに分割されます。マスター ノードのみが読み取りおよび書き込みリクエストとクラスター情報のメンテナンスを担当し、スレーブ ノードはマスター ノードのデータとステータス情報のみを複製します。
2.機能
(1) データパーティション
データのパーティショニングはクラスターの中核機能です。クラスターはデータを複数のノードに分散します。一方で、Redis 単一マシンのメモリー サイズの制限を突破し、ストレージ容量が大幅に増加します。他方、各マスター ノードは外部の読み取りおよび書き込みサービスを提供でき、これにより、クラスターの応答性が大幅に向上します。
Redis スタンドアロン メモリ サイズの制限については、永続性とマスター/スレーブ レプリケーションの紹介で説明されています。たとえば、スタンドアロン メモリが大きすぎる場合、bgsave および bgrewriteaof のフォーク操作によりマスター プロセスがブロックされる可能性があります。マスター/スレーブ環境ではホストが切り替わる可能性があり、その結果、スレーブノードが長時間サービスを提供できなくなり、フルレプリケーションフェーズ中にマスターノードのレプリケーションバッファ領域がオーバーフローする可能性があります。
(2) 高可用性
クラスターは、マスター/スレーブ レプリケーションとマスター ノードの自動フェイルオーバー (Sentinel と同様) をサポートしており、いずれかのノードに障害が発生しても、クラスターは引き続き外部サービスを提供できます。
3. データ断片化の原理
Redis クラスターにはハッシュ スロットの概念が導入されており、Redis クラスターには 16384 個のハッシュ スロット (番号は 0 ~ 16383) があり、クラスターの各ノードはハッシュ スロットの一部を担当します。
3 つのノードで構成されるクラスターを例に挙げます。
ノード A にはハッシュ スロット 0 ~ 5460 が含まれます
ノード B にはハッシュ スロット 5461 ~ 10922 が含まれます
ノード C にはハッシュ スロット 10923 ~ 16383 が含まれています
各キーは CRC16 アルゴリズムを通じて値を生成し、この値を使用して 16384 の余りを取得します。どのノードのハッシュ スロット間隔を使用して、どのノードのハッシュ スロットに入れるかを決定し、対応するアクセス操作に直接かつ自動的にジャンプします。ノード上で実行されます
。
4. Redis クラスターのマスター/スレーブ レプリケーション モデル
たとえば、クラスタ内に 3 つのノード A、B、C があり、ノード B に障害が発生すると、5461 ~ 10922 の範囲のスロットが不足するため、クラスタ全体が使用できなくなります。
したがって、各ノードにスレーブ ノード A1、B1、および C1 を追加すると、クラスター全体は 3 つのマスター ノードと 3 つのスレーブ ノードで構成されます。ノード B に障害が発生した後、クラスターは B1 をマスター ノードとして選択してサービスを継続します。および B1 障害が発生すると、クラスターは使用できなくなります。
5. Redis クラスタークラスターの構築
一般に、クラスターにはマスターとスレーブの 3 つのペアが必要ですが、デモンストレーションの便宜上、ここではホスト Redis の 6001 ~ 6004 ポートを使用して 6 つの異なる Redis インスタンスをシミュレートします。
Redis ノードごとにディレクトリを作成し、必要なファイルをコピーします。
mkdir -p redis-cluster/redis600{1..6}
#批量复制所需文件到6个目录下
cd /opt/redis-5.0.7/
for i in {1..6};do cp /opt/redis-5.0.7/redis.conf /etredis600$i;cp /opt/redis-5.0.7/src/redis-server /opt/redis-5.0.7/src/redis-cli /etredis600$i;done

6 つのインスタンスの構成ファイルを変更し、すべてを開きます
#先修改一个,再复制给其他的,修改端口和文件名序号即可
cd /etc/redis/redis-cluster/redis6001
vim redis.conf
#修改以下字段,其他可自行修改
bind 0.0.0.0 #为实验方便监听所有
protected-mode no #关闭保护模式
port 6001 #监听端口(每台需要不一样6001-6002)
daemonize yes #打开后台运行
appendonly yes #打开aof
cluster-enabled yes #开启集群模式
cluster-config-file nodes-6001.conf #集群节点配置文件名(每台需要不一样6001-6002)
cluster-node-timeout 15000 #集群故障监听超时时间
#开启所有
for i in {1..6};do cd /etc/redis/redis-cluster/redis600$i;./redis-server redis.conf;done
#开启cluster模式
./redis-cli --cluster create 127.0.0.1:6001 127.0.0.1:6002 127.0.0.1:6003 127.0.0.1:6004 127.0.0.6005 127.0.0.1:6006 --cluster-replicas 1
#结尾的选项1,代表每个主有1个从节点 

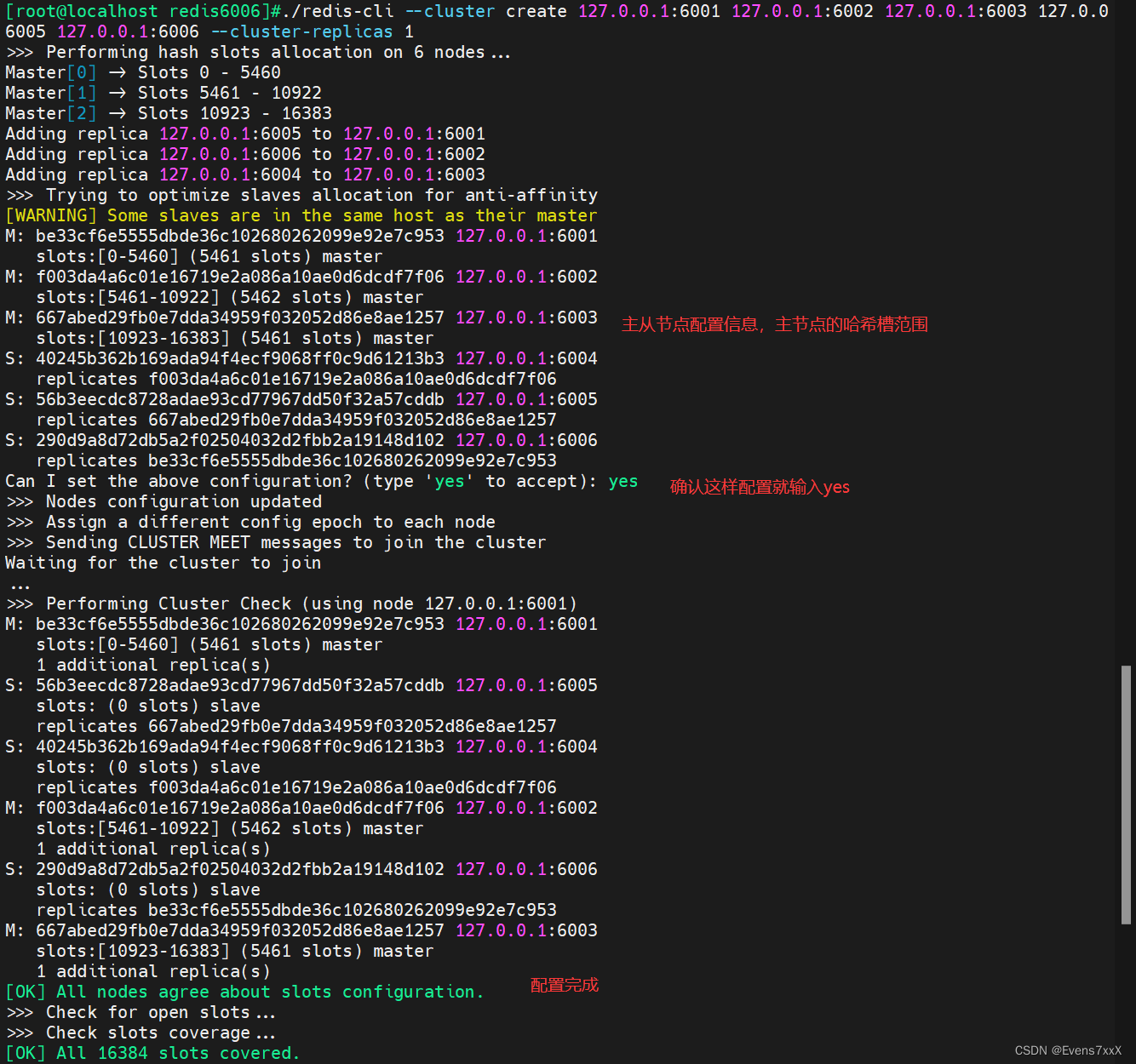
データベース内のクラスター スロットを使用してクラスター情報を表示できます。

データの挿入テスト(ログイン時に -c オプションを追加しないと、ノードが自動的に切り替わりません)
