前回のブログでは、標準的な粒子群とその実装について紹介し、多くの改善の方向性を示しましたが、今回から粒子群の改善を順次更新していきます。この問題の改善の方向性は主に 3 つあります。初期化 粒子群
2 慣性重量の非線形調整
3 学習係数の動的変更。
これらの改善戦略については、以下で詳しく説明します。
00 記事ディレクトリ
1 粒子群改善戦略
2 コードディレクトリ
3 問題のインポート
4 シミュレーション
5 ソースコードの取得
01 粒子群改善戦略
粒子群最適化アルゴリズムは、複雑な最適化問題を解決する際に大きな利点を示します。しかし、他のインテリジェントなアルゴリズムと同様に、粒子群最適化アルゴリズムにも、時期尚早の問題など、克服するのが難しい欠陥があります。
PSO アルゴリズムの慣性重みや学習係数などのパラメーターの値は、アルゴリズムの収束パフォーマンスにおいて非常に重要な役割を果たしており、研究者は主にこれらのパラメーターに従来の値を使用しており、必然的に収束と収束に影響を与えます。初期化もアルゴリズムの精度と速度に大きな影響を与え、解空間の不均一な分布は局所最適に陥る傾向があります。
1.1 カオスの初期化
従来の粒子群最適化アルゴリズムは通常、ランダム初期化を使用して初期集団の位置分布を決定し、コンピュータによって乱数が生成され、次の式に従って各粒子の初期位置がランダムに生成されます。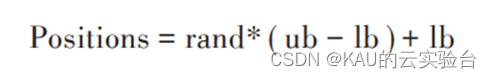
Positions は生成された粒子の位置を表します。rand は生成された乱数を表し、値の範囲は [0, 1] です。ub、lb はそれぞれ解空間の上限と下限です。
通常、この種のランダムな初期化では毎回異なる初期集団が生成されるため、より使いやすくなります。しかし、欠点もあります。つまり、溶液空間内の初期粒子の分布は均一ではなく、局所領域の粒子が濃すぎると同時に、一部の初期粒子が密になることがよくあります。地域がまばらすぎる。このような状況は、最適化アルゴリズムの早期収束にとって非常に不利であり、局所最適に陥りやすい群最適化アルゴリズムでは、収束速度の低下や収束不能につながる可能性がある。
無秩序な初期化により、これらの問題を効果的に回避できます。カオス初期化にはランダム性、エルゴード性、規則性という特徴があります。独自のルールに従って、反復することなく一定範囲内の探索空間を横断します。この方法で生成された初期母集団は、解の精度と収束速度が明らかに向上しています。この論文のカオス初期化にはロジスティック カオス モデルが使用され、その式は次のとおりです。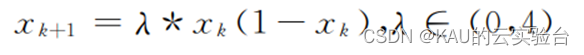
このうち、lamda はカオス モデルのマッピング パラメータであり、μ∈[3.57,4] の場合、システムはカオス状態にあり、μ=4 の場合、システムは完全なカオス状態にあります。一般にμは4とします。
上記の 2 つの初期化方法によって生成された解空間分布図は次のとおりです。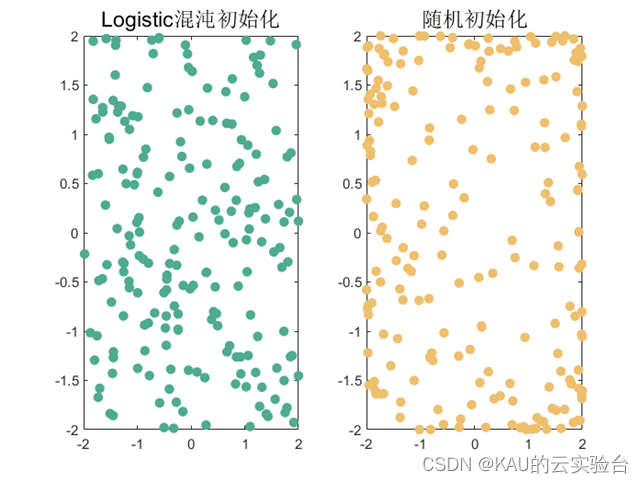
カオス初期化後の解空間の分布は、ランダム初期化の分布よりも均一であり、密すぎる領域や疎すぎる領域がないことがわかります。
1.2 適応慣性重量
慣性重み係数は PSO アルゴリズムのパフォーマンスに影響します。値が大きいとグローバル範囲での検索に有利であり、重み値が小さいとアルゴリズムの収束速度の高速化に役立ち、より多くの値が得られます。地域のきめ細やかな発展に貢献します。
PSO アルゴリズムのグローバル検索能力とローカル改善能力のバランスを取るために、非線形動的慣性重み係数式が使用され、その式は次のとおりです。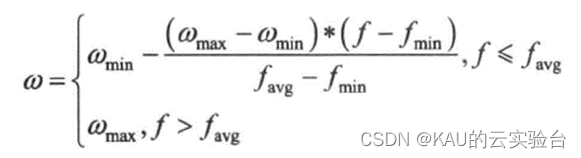
このうち、f はパーティクルのリアルタイム目的関数値を表し、favg と fmin はそれぞれ現在のすべてのパーティクルの平均値と最小目標値を表します。上の式から、粒子の目的関数の値が変化すると慣性重みが変化することがわかります。パーティクルの目標値がばらつく場合は慣性ウェイトを小さくし、パーティクルの目標値が一定の場合は慣性ウェイトを大きくします。
1.3 動的学習要素
標準的な粒子群最適化アルゴリズムでは、c1 と c2 は学習係数であり、一般に固定値をとります。学習係数 c1 は粒子自身についての考え方、つまり粒子が自分自身から学習する部分を表し、学習係数 c2 は粒子の社会的性質、つまり粒子の全体的に最適な粒子から学習した特徴。
粒子群最適化アルゴリズムのプロセス中、アルゴリズムは粒子の多様性を高めるために最初に空間内を広範囲に探索する必要があり、後の段階ではアルゴリズムに反映されるアルゴリズムの収束に注意を払う必要があります。学習係数 c1 と c2 は、アルゴリズムの進行に応じて重み付けされる必要があります。値は可変であり、固定されるべきではありません。
そこで、進化の初期段階で粒子が局所最適解の周囲に急速に集まるのを防ぎ、粒子が大域場の広い範囲を探索できるようにするために、c1 をより大きな値、c2 をより小さな値とする。探索の後半段階で粒子を迅速かつ正確に大域最適解に収束させ、アルゴリズムの収束速度と精度を向上させるために、c1 をより小さい値に設定し、c2 をより大きな値に設定します。そこで本論文では C1 を単調減少関数、C2 を単調増加関数として構成し、両者の式は次のようになります。
ここで、 t は現在の反復番号です。Tmax は粒子群の最大反復回数であり、学習係数の値を動的に調整することで、グループは粒子群の初期段階で短時間で迅速に最適値を探索できることがわかります。進化の後期段階では迅速かつ正確に最適解に収束します。
C1、C2の機能イメージは以下のとおりです。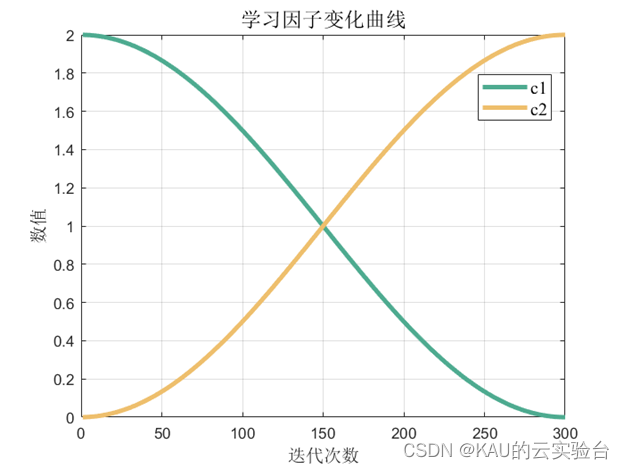
02 コードディレクトリ
まず main_ipso.m と main_pso.m を実行してから、compare.m を実行して反復比較を確認します。
03 質問インポート
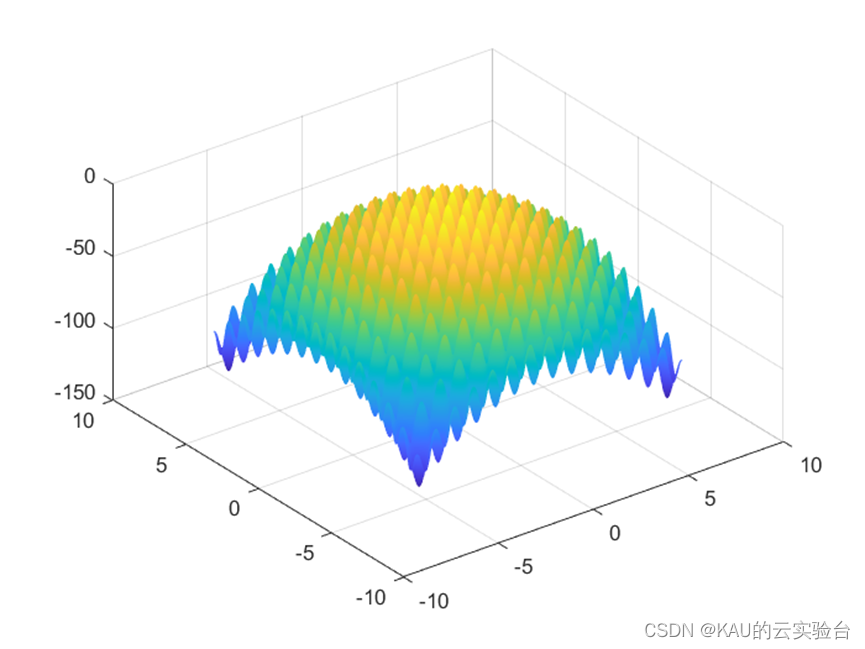
アルゴリズムのパフォーマンスを検証するために、ベンチマークで一般的に使用されるテスト関数 Rastrigrin 関数が使用されます。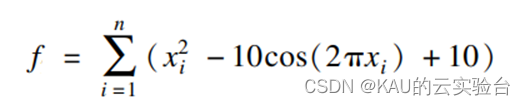
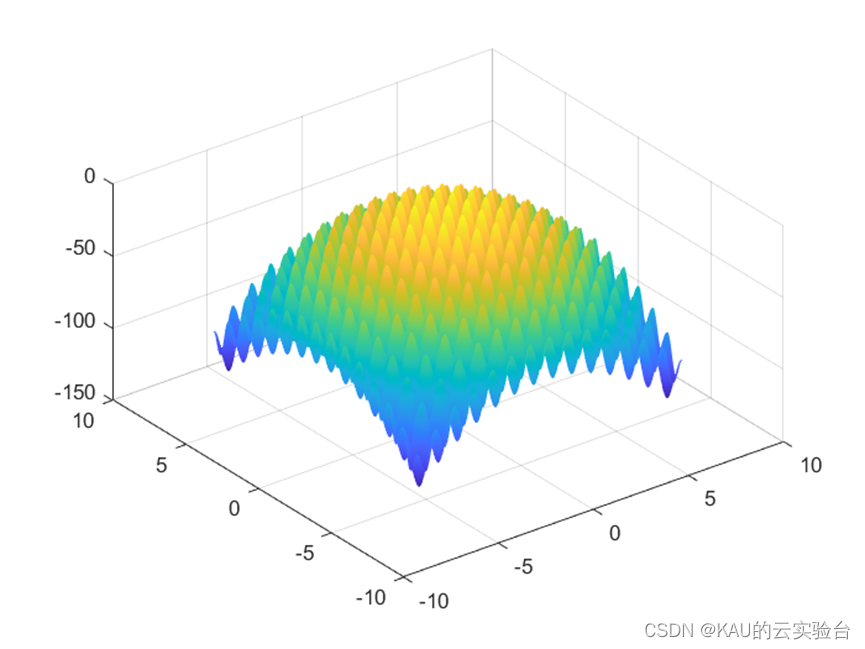
関数
が負の場合、適応度は大きいほど良いことになります。
この関数はマルチモーダル関数であり、(0,0,...,0) に収束します。
04 シミュレーション
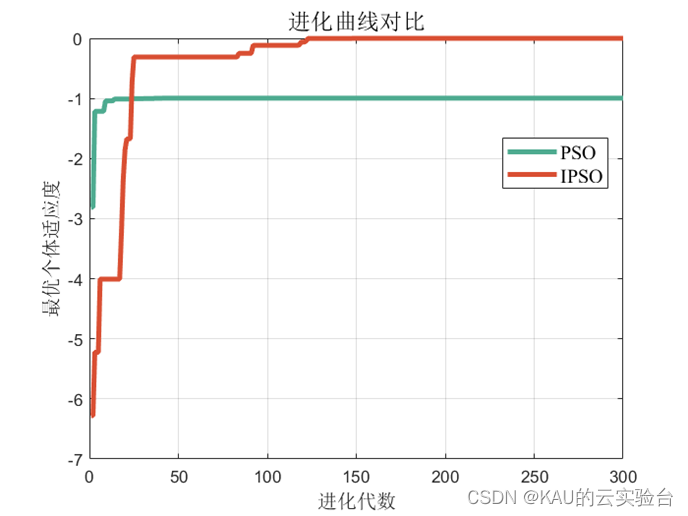
上記の改良された戦略を標準粒子群に追加し、Rastrigrin 関数を通じて比較すると、次の結果が得られます。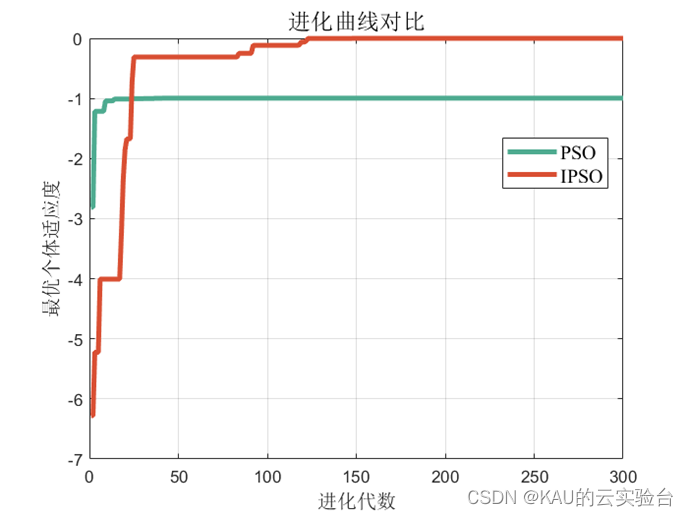
その中で、IPSO の価値と適合性は次のとおりです。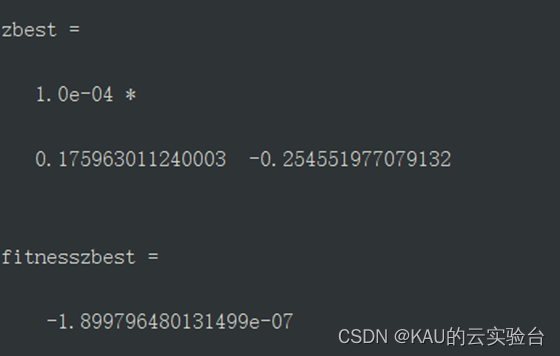
PSO の価値と適合性は次のとおりです。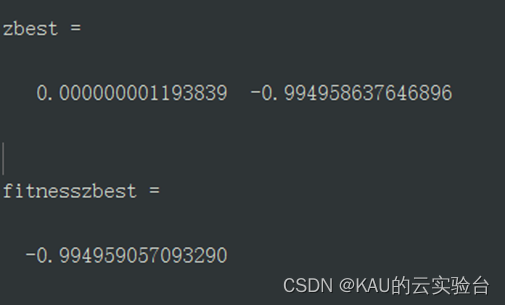
明らかに、PSO は局所最適に囚われており、局所解から抜け出すのは困難です。適応型カオス粒子群アルゴリズムのパフォーマンスが向上しました。
05 ソースコード取得
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
https://mbd.pub/o/bread/ZJqbmpdv
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
この記事が役に立ったり、インスピレーションを与えたりした場合は、右下隅の「いいね! (ง •̀_•́)ง」をクリックしてください (クリックする必要はありません)。カスタマイズが必要な場合は、プライベート メッセージを送信できます。著者。