序文
前回の記事では、InnoDB ストレージ エンジンの B+ ツリー インデックスについて詳しく説明しましたが、次の結論を知っておく必要があります。
-
各インデックスは B+ ツリーに対応し、B+ ツリーはいくつかの階層に分かれており、最下位の階層がリーフ ノード、残りが内部ノード (非リーフ ノード) になります。すべてのユーザー レコードは B+ ツリーのリーフ ノードに保存され、すべてのディレクトリ エントリ レコードは内部ノードに保存されます。
-
InnoDB ストレージ エンジンは主キーのクラスター化インデックスを自動的に作成し (そうでない場合は自動的に追加されます)、クラスター化インデックスのリーフ ノードには完全なユーザー レコードが含まれます。
-
関心のある列に対してセカンダリ インデックスを作成できます。セカンダリ インデックスのリーフ ノードに含まれるユーザー レコードは、インデックス列 + 主キーで構成されているため、セカンダリ インデックスを通じて完全なユーザー レコードを検索したい場合は、テーブルに戻る必要があります。つまり、セカンダリ インデックスを通じて主キー値が見つかった後、完全なユーザー レコードがクラスター化インデックスで検索されます。
-
B+ ツリー内のノードの各層は、インデックス列の値の小さい順から大きい順にソートされて二重リンク リストが形成され、各ページのレコード (ユーザー レコードまたはディレクトリ エントリ レコード) が次に従ってソートされます。インデックス列の値を小さいものから大きいものまで大規模な連続グループが単一リンク リストを形成します。結合インデックスの場合、ページとレコードはまず結合インデックスの前の列に従って並べ替えられ、列の値が同じ場合は結合インデックスの後ろの列に従って並べ替えられます。
-
インデックスによるレコードの検索は、B+ ツリーのルート ノードから開始され、階層ごとに下方向に検索されます。各ページはインデックス列の値に従ってページ ディレクトリ (ページ ディレクトリ) を確立するため、これらのページ内の検索は非常に高速です。
上記の結論に疑問がある場合は、最初に前の内容に戻って読むことをお勧めします。B+ ツリーの原理を理解した後、この章ではインデックスをより効果的に使用する方法を説明します。
B+ツリーインデックス[電車経由]
1. インデックス作成のコスト
インデックスは良いものですが、ランダムに構築することはできません。インデックスをより効果的に使用する方法を学ぶ前に、スペースと時間が遅くなるインデックスの使用コストを理解しましょう。
-
スペースコスト
これは明らかです。インデックスが作成されるたびに、そのインデックス用に B+ ツリーを構築する必要があります。各 B+ ツリーの各ノードはデータ ページです。デフォルトでは、ページは 16KB の記憶領域を占有します。大きな B+ ツリー ツリーは次のもので構成されます。多くのデータ ページがあり、大きなストレージ スペースになります。
-
時間コスト
テーブル内のデータを追加、削除、または変更するたびに、各 B+ ツリー インデックスを変更する必要があります。そして、B+ ツリーの各レベルのノードがインデックス列の値に従って小さいものから大きいものまでソートされ、二重リンク リストを形成すると述べました。リーフ ノードのレコードであっても、内部ノードのレコードであっても (つまり、ユーザー レコードであってもディレクトリ エントリ レコードであっても)、一方向リンク リストはインデックス列値の順序で形成されます。小さいものから大きいものまで。追加、削除、および変更操作によってノードとレコードの順序が損なわれる可能性があるため、ストレージ エンジンは、ノードとレコードの順序を維持するために、レコードのシフト、ページ分割、ページのリサイクルなどの操作を実行するために追加の時間を必要とします。多数のインデックスを構築する場合、各インデックスに対応する B+ ツリーは関連するメンテナンス操作を実行する必要がありますが、これによりパフォーマンスが妨げられることはありませんか? したがって、各テーブルに構築されるインデックスが増えるほど、より多くの記憶領域が占有され、レコードの追加、削除、変更時のパフォーマンスが低下します。優れた少数のインデックスを構築するには、まずこれらのインデックスが機能する条件を学ぶ必要があります。
2. B+ツリーの適用条件
まず第一に、B+ ツリー インデックスは万能薬ではありません。すべてのクエリが構築したインデックスを使用するわけではありません。以下では、クエリに B+ ツリー インデックスを使用するいくつかの状況を紹介します。まず、demo7いくつかの基本情報を保存するテーブルを作成します。
mysql> drop table if exists demo7;
Query OK, 0 rows affected (0.01 sec)
mysql> create table demo7(
c1 int not null auto_increment,
c2 varchar(11) not null,
c3 varchar(11) not null,
c4 char(11) not null,
c5 varchar(11) not null,
primary key(c1), key idx_c2_c3_c4(c2,c3,c4)
);
Query OK, 0 rows affected (0.03 sec)
insert into demo7(c2,c3,c4,c5) values('a','a','a','d');
insert into demo7(c2,c3,c4,c5) values('a','ab','a','d');
insert into demo7(c2,c3,c4,c5) values('a','a','ab','d');
insert into demo7(c2,c3,c4,c5) values('ab','ab','ab','d');
insert into demo7(c2,c3,c4,c5) values('ab','abc','ab','d');
insert into demo7(c2,c3,c4,c5) values('ab','ab','abc','d');
insert into demo7(c2,c3,c4,c5) values('abc','abc','abc','d');
insert into demo7(c2,c3,c4,c5) values('abc','abcd','abc','d');
insert into demo7(c2,c3,c4,c5) values('abc','abc','abcd','d');
insert into demo7(c2,c3,c4,c5) values('abcd','abcd','abcd','d');
insert into demo7(c2,c3,c4,c5) values('abcd','abcde','abcd','d');
insert into demo7(c2,c3,c4,c5) values('abcd','abcd','abcde','d');
このテーブルについて知っておく必要があることは次のとおりです。
mysql> show index from demo7;
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
| demo7 | 0 | PRIMARY | 1 | c1 | A | 12 | NULL | NULL | | BTREE | | | YES | NULL |
| demo7 | 1 | idx_c2_c3_c4 | 1 | c2 | A | 4 | NULL | NULL | | BTREE | | | YES | NULL |
| demo7 | 1 | idx_c2_c3_c4 | 2 | c3 | A | 8 | NULL | NULL | | BTREE | | | YES | NULL |
| demo7 | 1 | idx_c2_c3_c4 | 3 | c4 | A | 12 | NULL | NULL | | BTREE | | | YES | NULL |
+-------+------------+--------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+
4 rows in set (0.01 sec)
- テーブルの主キーは
c1自己増加する整数を格納する列であるため、InnoDB ストレージ エンジンは id 列のクラスター化インデックスを自動的に作成します。 - さらに、
idx_c2_c3_c43 つの列で構成される結合インデックスであるセカンダリ インデックスを定義します。c2したがって、このインデックスに対応する B+ ツリーのリーフ ノードに格納されるユーザー レコードは、 、c3、c4主キー ID の値の3 つの列値のみを保存でき、国の列値は保存されません。
これら 2 つの点から、テーブル内のインデックスと同じ数の B+ ツリーがあり、demo7クラスター化インデックスとテーブルのインデックスに対してidx_c2_c3_c42 つの B+ ツリーが構築されていることが再度わかります。以下に下位インデックスの模式図を描きますidx_c2_c3_c4が、InnoDBのB+ツリーインデックスの原理をマスターしているため、絵をわかりやすくするために、記録されている付加情報など不要な部分を省略して描画しています。ページ番号など内部ノードのエントリレコードのページ番号情報を矢印で置き換えますレコード構造では、、、、の4つの列の実データ値のみが予約されているので、概略図は次c2のようなものです。c3c4c1
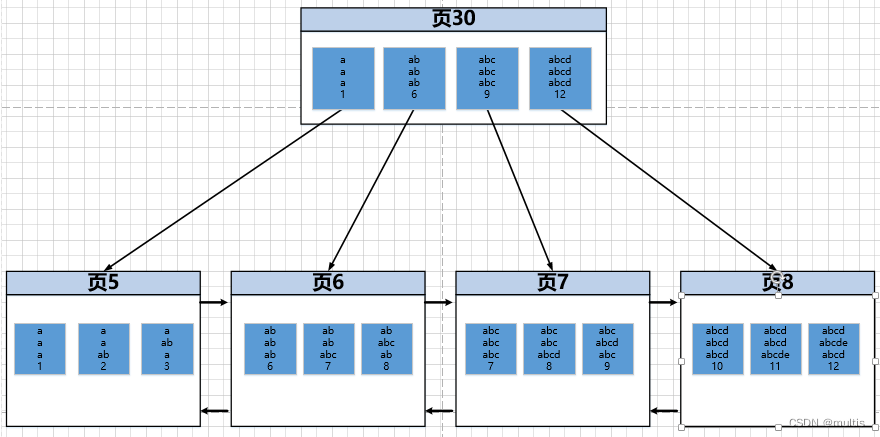
内部ノードにはディレクトリ エントリ レコードが保存され、リーフ ノードにはユーザー レコードが保存されることがわかります (クラスタ化インデックスではないため、ユーザー レコードは不完全で列の値がありません)。図から、インデックスがページとレコードに対応していることがわかりますc5。idx_c2_c3_c4B+ ツリーでは次のようにソートされます。
- 最初に
c2列の値で並べ替えます c2列の値が同じ場合、列の値c3で並べ替えます。c3列の値も同じ場合は、c4列の値でソートします
この並べ替えは非常に重要です。ページとレコードが並べ替えられているため、二分法ですばやく見つけて検索できます。以下の内容を理解するには、この図を参照してください。
2.1 完全値マッチング
検索条件の列がインデックス列と一致する場合、次のように完全値一致になります。
select * from demo7 where c2='a' and c3='a' and c4= 'ab';
構築したインデックスに含まれる 3 つの列がidx_c2_c3_c4、このクエリ ステートメントに表示されます。そのプロセスを想像できます。
- B+ ツリーのデータ ページとレコードは最初に
c2列の値に従って並べ替えられるため、c2列値aのレコード位置がすぐに特定されます。 c2同じ列を持つレコードでは、c3列の値でソートするため、c2列の値を持つレコードでは、列の値を持つレコードをaすばやく定義します。c3‘a’- 残念ながら、
c2とc3列の値が同じである場合、レコードはc4列の値に従って並べ替えられるため、結合インデックスの 3 つの列すべてが使用される可能性があります。
まだ疑問があるかもしれませんが、where 句内のいくつかの検索条件はクエリ結果に影響しますか? つまり、 の交換とこれらの検索されたいくつかの列が実行プロセスに影響を与えると言えるのでしょc2うc3かc4? たとえば、次のように書きます。
select * from demo7 where c4='ab' and c3= 'a' and c2='a' ;
答えは「いいえ」です。MySQL にはクエリ オプティマイザーと呼ばれるコンポーネントがあり、これらの検索条件を分析し、最初に使用する検索条件と、使用できるインデックス カラムの順序に従ってどの検索条件を使用するかを決定します。後で学ぶ
2.2 左の列を一致させる
実際、検索ステートメントには結合インデックス内のすべての列を含める必要はなく、次のステートメントのように左側の列のみを含めます。
select * from demo7 where c2='abc' ;
または、左側に複数の列を含めます。
select * from demo7 where c2='abcd' and c3='abcde';
では、なぜ左側の列が検索条件に表示されなければならないので、この B+ ツリー インデックスも使用できるのでしょうか。たとえば、次のステートメントは B+ ツリー インデックスを使用しません?
select * from demo7 where c3='abcde' ;
はい、実際には使用されません。B+ ツリーのデータ ページとレコードはc2最初に列の値に従って並べ替えられ、その列はc2列の値が同じ場合の並べ替えに使用されます。 、異なる列値を持つレコードでは値が順序付けされていない可能性があります。しかし、ここでは列をスキップして列の値に基づいて直接検索しますが、これは不可能です。そのため、列の値のみを使用して B+ ツリー インデックスを検索したい場合はどうすればよいでしょうか? これは扱いが簡単で、列に B+ ツリー インデックスを作成できます。c3c2c3c2C3c3c3
ただし、特に注意が必要なのは、結合インデックスにできるだけ多くの列を使用する場合、検索条件の各列は結合インデックスの左から連続した列である必要があることです。たとえば、検索条件に合計のみがあり、中間のものが存在しない場合、idx_c2_c3_c4ジョイント インデックス内の列の定義順序は、次のようになります。c2c3c4c2c4c3
select * from demo7 where c2 = 'abcd' and c4='abcde';
このように、同じ値c2を持つレコードは最初に値の値に従ってソートされ、同じ値を持つレコードはソートされるため、列のインデックスのみが使用でき、 とc3のインデックスは使用c4できません。値に従って。c2c3c3c4
2.3 列プレフィックスの一致
特定の列のインデックス付けとは、その列の値を使用して対応する B+ ツリー レコードをソートすることを意味すると前述しましたが、たとえば、demo7テーブルに設定されたジョイント インデックスは、idx_c2_c3_c4最初に c2 列の値をソートするため、このジョイントの配置はインデックスに対応する B+ ツリー内のレコードの名前列は次のようになります。
a
a
a
ab
ab
ab
abc
abc
abc
abcd
abcd
abcd
文字列の並べ替えの本質は、どの文字列が大きいか、どの文字列が小さいかを比較することです。文字列のサイズの比較には、前に説明した列の文字セットと比較規則が使用されます。ここで、一般的な比較ルールは文字のサイズを 1 つずつ比較することであることに注意してください。つまり、2 つの文字列のサイズを比較するプロセスは実際には次のようになります。
- まず文字列の最初の文字を比較し、最初の文字が小さい文字列の方が小さくなります。
- 2 つの文字列の最初の文字が同じである場合は、2 番目の文字を比較し、2 番目の文字が小さい文字列の方が小さくなります。
- 2 つの文字列の 2 番目の文字も同じである場合は、3 番目の文字を比較し、以下同様に続きます。
したがって、ソートされた文字列列には実際には次の特性があります。
- まず、文字列の最初の文字でソートします。
- 最初の文字が同じ場合は、2 番目の文字に従ってソートします。
- 2 番目の文字が同じ場合は、3 番目の文字に従って並べ替えます。
つまり、これらの文字列の最初の n 文字、つまりプレフィックスはすべてソートされているため、文字列型のインデックス列の場合、プレフィックスを照合するだけでレコードをすぐに見つけることができます
。名前が「a」で始まるクエリ レコードの場合は、次のようなクエリ ステートメントを作成できます。
select * from demo7 where c2 like 'a%'
ただし、サフィックスまたは中間の特定の文字列のみが指定されている場合は、次のように注意する必要があります。
select * from Demon7 where c2 like '%b%'
MySQL は、'a' があるため、レコードの位置をすぐに見つけることができません。文字列の途中 '文字列はソートされていないため、テーブル全体をスキャンすることしかできません。
2.4 一致範囲の値
idx_c2_c3_c4 インデックスの B+ ツリー図を見ると、すべてのレコードがインデックス列の値に従って小さいものから大きいものまで並べ替えられているため、インデックス列の値が範囲内にあるレコードを見つけるのに非常に便利です。一定の範囲。たとえば、次のクエリ ステートメントは次のとおりです。
select * from demo7 where c2 > 'a' and < 'abcd';
B+ ツリー内のデータ ページとレコードは最初に c2 列によって並べ替えられるため、上記のクエリ プロセスは実際には次のようになります。
- c2 値が a であるレコードを検索します。
- c2 値が abcd であるレコードを検索します。
すべてのレコードはリンクリスト(レコード間はシングルリンクリスト、データページ間はダブルリンクリスト)で接続されているため、それらの間のレコードを簡単に取り出すことができ、これらのレコードの主キー値を取得することができます。見つかった後、クラスター化インデックスのテーブルに戻って完全なレコードを見つけます。ただし、結合範囲検索を使用する場合に注意が必要で、複数の列を同時に範囲検索する場合、インデックスの左端の列を範囲検索する場合のみB+ツリーインデックスを使用できます。例えば:
select * from demo7 where c2 > 'a' and < 'abcd' and c3 > 'a';
上記のクエリは 2 つの部分に分けることができます。
- c2 の範囲に条件 c2 > 'a' および c2 < 'abcd' を使用すると、検索結果には異なる c2 値を持つ複数のレコードが含まれる可能性があります。
- 異なる c2 値を持つレコードは、引き続き c3 > 'a' 条件によってフィルタリングされます。
このように、結合インデックス idx_c2_c3_c4 では、c2 列の一部のみを使用できますが、c3 列の一部は使用できません。これは、c2 列の値のみが c3 列の値でソートできるためです。このクエリは c2 を渡します。範囲検索のレコードは c3 カラムに従ってソートされていない可能性があるため、検索条件に c3 カラムを指定して検索を続ける場合、B+ ツリー インデックスは使用されません。
2.5 ある列に完全に一致し、別の列に範囲が一致する
同じジョイント インデックスの場合、複数の列の範囲検索に使用できるのは左端のインデックス列のみですが、左の列が完全検索の場合は、右の列を範囲検索に使用できます。次に例を示します。
select * from demo7 where c2='a' and c3 > 'a' and c3 <'ab' and c4>'a'
このクエリの条件は 3 つの部分に分けることができます。
- c2 = 'a'、列 c1 で正確な検索を実行します。もちろん、B+ ツリー インデックスを使用できます。
- c3 > 'a' および c3 < 'ab'、c2 列は完全検索であるため、c2 = 'a' 条件で検索した結果の c2 値はすべて同じとなり、ソートされます。 c3値によると。したがって、このとき、c3列の範囲検索にはB+ツリーインデックスが使用できます。
- c4 > 'a'、c3 の範囲で検索されたレコードの c3 の値は異なる可能性があるため、この条件では B+ ツリー インデックスを使用できなくなり、前のステップのクエリで取得されたレコードのみを走査できます。
同様に、次のクエリでもこの idx_c2_c3_c4 結合インデックスを使用する場合があります。
select * from demo7 where c2='a' and c3= 'a' and c4>'a'
2.6 ソート用
クエリ ステートメントを作成する場合、多くの場合、order by ステートメントを通じて特定のルールに従ってクエリされたレコードを並べ替える必要があります。通常の状況では、レコードをメモリにロードすることしかできず、その後、クイック ソート、マージ ソートなどの一部のソート アルゴリズムがこれらのレコードをメモリ内でソートします。そのため、クエリの結果セットが大きすぎて読み込めない場合があります。メモリ内で並べ替えを実行できない場合は、ディスク領域を一時的に使用して中間結果を保存し、並べ替え操作の完了後に並べ替えられた結果セットをクライアントに返すことができます。mysqlでは、このメモリ上またはディスク上でのソート方法を総称してファイルソート(英語名:filesort)と呼びます。飛行機とカタツムリのようなものです)。ただし、order by 句でインデックス列を使用する場合は、次のような単純なクエリ ステートメントのように、メモリまたはハードウェアでの並べ替えの手順を省略できます。
select * from demo7 order by c2,c3,c4 limit 10;
このクエリの結果セットは、まず c2 の値に従って並べ替える必要があり、c2 の記録された値が同じ場合は c3 に従って並べ替える必要があり、c3 の値が同じ場合は、 c4に従ってソートする必要があります。私たちが構築した idx_c2_c3_c4 インデックスの概略図をご覧ください。b+ ツリー インデックス自体は上記のルールに従ってソートされているため、データはインデックスから直接抽出され、テーブル リターン操作が実行されてインデックスが削除されます。インデックスに含まれていない列だけで十分です。単純ですよね?はい、インデックスはとても素晴らしいです。
2.6.1 結合インデックスを使用したソートに関する考慮事項
結合インデックスには注意が必要な問題があります。order by 句の後ろの列の順序も、インデックス列の順序で指定する必要があります。order by c4、c3、および c2 の順序が指定されている場合、次のようになります。この逆の順序でインデックスを使用できない理由については、上記で詳しく述べたので、ここでは詳しく説明しません。
同様に、order by c2、order by c2、c3 は、インデックスの左列と一致する形式で B+ ツリー インデックスの一部を使用できます。ジョイント インデックスの左側の列の値が定数である場合、次のように、後の列を並べ替えに使用することもできます。
select * from demo7 where c2 ='a' order by c3,c4 limit 10;
このクエリは、何度も述べていますが、c2 列に同じ値を持つレコードが c3 と c4 に従ってソートされるため、ジョイント インデックスを使用してソートできます。
2.6.2 インデックスをソートに使用できない状況
asc と desc の混合使用
結合インデックスを使用して並べ替えるシナリオでは、各並べ替え列の並べ替え順序が同じである必要があります。つまり、各列が asc ルールによって並べ替えられるか、すべての列が desc ルールによって並べ替えられるかのいずれかです。
ヒント:
orde by 句の後の列に asc または desc が追加されていない場合、デフォルトでは asc ソート規則に従ってソートされます。つまり、昇順でソートされます。
なんでこんな変なルールがあるんですか?これは、idx_c2_c3_c4 ジョイント インデックスに記録されている構造を遡って考える必要があります。
- まず、記録された列 c2 の値に従って昇順にソートします。
- c2列に記録された値が同じ場合は、c3列の値に従って昇順に並べ替えます。
- c3列に記録された値が同じ場合は、c4列の値に従って昇順に並べ替えます。
クエリ内の各ソート列のソート順序が一貫している場合、たとえば、次の 2 つのケースが考えられます。
order by c2, c3 limit 10
この場合、インデックスの左端から右に向かって 10 レコードを読み取るだけです。order by c2 desc, c3 desc limit 10
この場合、インデックスの右端から左に向かって 10 レコードを読み取るだけです。ただし、クエリを最初に列 c2 に従って昇順で並べ替える必要があり、次に列 c3 に従って降順で並べ替える必要がある場合、たとえば次のようなクエリ ステートメントが必要です。したがって、インデックス ソートが使用される場合、プロセスは次のようになります。
select * from demo7 order by c2,c3 desc limit 10;
- まずインデックスの左端から列 c2 の最小値を決定し、次に列 c2 がこの値に等しいレコードをすべて検索し、次に列 c2 がこの値に等しい右端のレコードから左に 10 個のレコードを検索します。
- 列 c2 に最小値に等しいレコードが 10 件未満の場合は、右に進み、c2 で 2 番目に小さい値を持つレコードを検索し、10 件のレコードが見つかるまで上記のプロセスを繰り返します。
- 要はインデックスを効率的に利用できないということですが、インデックスからデータを取得するにはより複雑なアルゴリズムが必要となり、ファイルを直接ソートするよりも高速ではありません。ジョイントインデックスは一貫している必要があります。
非ソートに使用されるインデックス列が where 句に表示されます。
where 句のソートに使用されないインデックス列がある場合でも、ソートではインデックスは使用されません。次に例を示します。
select * from demo7 where c5 = 'a' order by c2 limit 10;
このクエリでは、検索条件 c5='a' を満たすレコードの抽出とソートのみが可能であり、インデックスは使用できません。次のクエリとの違いに注意してください。
select * from demo7 where c2='a' order by c3,c4 limit 10;
このクエリには検索条件もありますが、c2 = 'a' はインデックス idx_c2_c3_c4 を使用でき、フィルタリング後の残りのレコードは引き続き c3 列と c4 列に従って並べ替えられるため、インデックスを並べ替えに使用できます。
ソートされた列には、同じインデックスにない列が含まれています
並べ替えに使用される複数の列がインデックスにない場合があります。この場合、インデックスは並べ替えに使用できません。次に例を示します。
select * from demo7 order by c2,c5 limit 10;
c2 と c5 は結合インデックスの列に属していないため、インデックスをソートに使用できません。
列の並べ替えには複雑な式が使用されます
並べ替え操作にインデックスを使用する場合は、インデックス列が変更された形式ではなく、別の列の形式で表示されるようにする必要があります。次に例を示します。
select * from demo7 order by upper(c2) limit 10;
upper 関数で変更された列は別個の列ではないため、インデックスを使用して並べ替えることはできません。
グループ分け用
テーブル内の一部の情報の統計を容易にするために、テーブル内のレコードを特定の列に従ってグループ化する場合があります。たとえば、以下のグループ クエリ:
select c2,c3,c4,count(*) from demo7 group by c2,c3,c4
このクエリ ステートメントは、次の 3 つのグループ化操作を実行するのと同等です。
- まず、c2 値に従ってレコードをグループ化し、同じ c2 値を持つすべてのレコードを 1 つのグループに分割します。
- c2 の値が同じ各グループ内のレコードを c3 の値に応じてグループ化し、c3 の値が同じであるレコードを小さなグループにまとめると、大きなグループが多数の小さなグループに分割されたように見えます。
- 次に、前のステップで生成された小さなグループを c4 の値に従って小さなグループに分割します。これにより、レコードが最初に 1 つの大きなグループに分割され、次に大きなグループがいくつかの小さなグループに分割され、次にいくつかの小さなグループに分割されたように見えます。グループ グループはさらに多くのサブグループに分割されます。
次に、それらの小グループを数えます。たとえば、クエリ ステートメントでは、各小グループに含まれるレコードの数を数えます。インデックスがない場合は、すべてのグループ化プロセスをメモリ内に実装する必要があります。インデックスがある場合は、グループ化の順序が b+ ツリーのインデックス列の順序と一致することがあり、b+ ツリーのインデックスは次のようになります。インデックス列に従ってソートされているので、グループ化に b+ ツリー インデックスを直接使用できるので、これは適切ではないでしょうか。
ソートに b+ ツリー インデックスを使用するのと同じです。グループ化列の順序もインデックス列の順序と一致している必要があります。そうでない場合は、インデックス列の左側の列のみをグループ化に使用できます。
3. 返品にかかる費用
上記の説明は返品フォームという言葉をざっと流し読みしたもので、よく理解していないかもしれませんが、以下で詳しく説明します。引き続き idx_c2_c3_c4 インデックスを例として使用します。次のクエリを参照してください
。
select * from demo7 where c2>'a' and c2<'abcde';
idx_c2_c3_c4 インデックスを使用してクエリを実行する場合、次の 2 つの手順に分けることができます。
- インデックスidx_c2_c3_c4に対応するb+ツリーから、c2値がaからabcdeまでのユーザーレコードを取り出します。
- インデックス idx_c2_c3_c4 に対応する b+ ツリー ユーザー レコードには c2、c3、c4、および c1 の 4 つのフィールドのみが含まれており、クエリ リストは * であるため、テーブル内のすべてのフィールドをクエリする必要があることを意味します。つまり、c5 フィールドはクエリする必要があります。も含まれます。このとき、前のステップで取得した各レコードの c1 フィールドから、クラスタード インデックスに対応する b+ ツリー内の完全なユーザー レコードを見つける必要があります。これは通常、テーブルにコールバックされ、完全なユーザー レコード クエリを実行したユーザーに返されます。
インデックス idx_c2_c3_c4 に対応する b+ ツリー内のレコードは、最初に c2 列の値に従ってソートされるため、ディスク内の a から abcde までの値を持つレコードのストレージは、1 つ以上のデータ ページに接続されて分散されます。これらの接続されたレコードをディスクから素早く読み取ることができます。この読み取り方法はシーケンシャル I/O とも呼ばれます。手順 1 で取得したレコードの c1 フィールドの値によっては接続されていない場合があり、クラスター化インデックス内のレコードは c1 (つまり主キー) の順序に従って配置されるため、これらに従ってクラスターへの不連続な c1 値クラスターインデックス内の完全なユーザーレコードへのアクセスは、異なるデータページに分散される可能性があるため、完全なユーザーレコードを読み取るには、より多くのデータページへのアクセスが必要になる場合がありますこの読み取り方法は、ランダム I/O とも呼ばれます。一般に、シーケンシャル i/o はランダム i/o よりもはるかにパフォーマンスが高いため、ステップ 1 は迅速に実行されますが、ステップ 2 は遅くなります。したがって、インデックス idx_c2_c3_c4 を使用するこのクエリには、次の 2 つの特徴があります。
- 2 つの b+ ツリー インデックス、1 つのセカンダリ インデックス、1 つのクラスター化インデックスが使用されます。
- セカンダリ インデックスへのアクセスにはシーケンシャル I/O が使用され、クラスター化インデックスへのアクセスにはランダム I/O が使用されます。
テーブルに返す必要があるレコードが増えると、セカンダリ インデックスを使用するパフォーマンスが低下し、一部のクエリではセカンダリ インデックスよりもテーブル全体のスキャンを使用することになります。たとえば、c2 値が a ~ abcde の間にあるユーザー レコードの数がレコード総数の 90% 以上を占め、idx_c2_c3_c4 インデックスが使用されている場合は、c1 値の 90% 以上を返す必要があります。これはありがたいことではありませんか? クラスタ化インデックスを直接スキャン (つまり、テーブル全体のスキャン) するほうがよいでしょう。
では、クエリの実行にフル テーブル スキャン方式を使用するのはどのような場合で、セカンダリ インデックス + テーブルを返す方式を使用するのはどのような場合でしょうか? これが、伝説的なクエリ オプティマイザーの機能です。クエリ オプティマイザーは、テーブル内の
レコード、これらの統計データを使用して、クエリに従ってテーブルに返す必要があるレコードの数を計算します。テーブル内のレコードが多いほど、フル テーブル スキャンを使用する傾向が高く、逆も同様で、セカンダリ インデックス + テーブルを返す傾向があります。もちろん、オプティマイザが行う分析はそれだけではありませんが、大まかにはこのようなプロセスになります。一般に、クエリによって取得されるレコードの数を制限すると、オプティマイザはセカンダリ インデックス + クエリのためにテーブルに戻るという方法を選択する傾向が強くなります。これは、テーブルに返されるレコードが少ないほど、パフォーマンスが向上するためです。上記のクエリは次のように書き換えることができます。
select * from demo7 where c2>'a' and c2<'abcde' limit 10;
オプティマイザがセカンダリ インデックスと戻りテーブルを使用してクエリを実行しやすくするために、制限 10 のクエリが追加されました。
ソート要件のあるクエリの場合、前述のフル テーブル スキャンまたはセカンダリ インデックス + テーブル リターンによるクエリの条件も有効です。たとえば、次のクエリ:
select * from demo7 order by c2,c3,c4;
クエリ リストは * であるため、並べ替えにセカンダリ インデックスを使用する場合は、並べ替えられたすべてのセカンダリ インデックス レコードをテーブルに返す必要があります。この操作のコストは、クラスタード インデックスを直接走査してファイルを並べ替える場合よりも低くなります。 (filesort) 低いため、オプティマイザはクエリを実行するために完全なテーブル スキャンを使用する傾向があります。次のような制限ステートメントを追加すると、次のようになります。
select * from demo7 order by c2,c3,c4 limit 10;
この方法では、テーブルに返す必要があるレコードがほとんどなくなり、オプティマイザはセカンダリ インデックスとテーブルへの戻りを使用してクエリを実行する傾向があります。
カバーインデックス
テーブルの戻り操作によって引き起こされるパフォーマンスの低下を完全に回避するには、クエリ リストにインデックス列のみを含めることをお勧めします。次に例を示します。
select c2,c3,c4 from demo7 where c2 >'a' and c2 < 'abcde';
3 つのインデックス列 c2、c3、c4 の値のみをクエリするため、idx_c2_c3_c4 インデックスを通じて結果を取得した後、クラスター化インデックス内のレコードの残りの列を検索する必要はありません。 、c5 列の値を保存します。戻りテーブル操作によって引き起こされるパフォーマンスの損失は排除されます。インデックスの使用のみが必要なこの種のクエリをインデックス カバレッジと呼びます。並べ替え操作では、次のクエリのように、クエリにカバリング インデックス方式を使用することも優先されます。
select c2,c3,c4 from demo7 order by c2,c3,c4;
このクエリにはlimitステートメントはありませんが、カバーインデックスが使用されるため、クエリオプティマイザはテーブルに戻らずに、並べ替えにidx_c2_c3_c4インデックスを直接使用します。
もちろん、ビジネスでインデックス以外の列をクエリする必要がある場合でも、ビジネス ニーズを確認することが重要です。ただし、クエリ リストとして * 記号を使用することを強くお勧めしません。クエリする必要がある列を順番にマークすることをお勧めします。
4. インデックスの選び方
上記では、idx_c2_c3_c4 インデックスを例に、インデックスの適用条件について詳しく説明しましたが、以下では、インデックスを構築するときやクエリ文を記述するときに注意すべき事項について説明します。
4.1 検索、並べ替え、グループ化に使用する列のみにインデックスを作成する
つまり、where 句に出現する列、join ステートメントの結合列、または order by 句または group by 句に出現する列のインデックスのみを作成します。クエリ リストに表示される列にはインデックスを付ける必要はありません。
select c3,c5 from demo7 where name= 'abcd';
クエリ リスト内の c3 と c5 のような 2 つの列にはインデックスを作成する必要はありません。where 句に表示される c2 列のインデックスを作成するだけで済みます。
4.2 列のカーディナリティを考慮する
列のカーディナリティとは、列内の固有のデータの数を指します。たとえば、列には 2,5,8,2,5,8,2,5,8 という値が含まれています。レコードは 9 つありますが、列の底は 3 です。つまり、一定数のレコード行の場合、列のカーディナリティが大きいほど、列内の値はより分散し、列のカーディナリティが小さいほど、値はより集中します。コラムで。この列のカーディナリティ インデックスは非常に重要であり、インデックスを効果的に使用できるかどうかに直接影響します。列のカーディナリティが 1、つまり列に記録されているすべての値が同じであると仮定すると、すべての値が同じであるため、列のインデックスを作成しても無駄です。ソートできず、クイック検索も実行できず、セカンダリ インデックスのある列に重複する値が多数あり、このセカンダリ インデックスを使用して見つかったレコードをテーブルに返す必要がある場合、パフォーマンスの損失が大きくなります。 。したがって、結論は次のとおりです。カーディナリティが大きい列に対してインデックスを構築するのが最善であり、カーディナリティが大きすぎる列に対してインデックスを構築すると、効果が良くない可能性があります。
4.3 インデックス列の種類はできるだけ小さくする必要があります
テーブルの構造を定義する際には、列の型を明示的に指定する必要がありますが、整数型を例にとると、tinyint、mediumint、int、bigint などの型があり、それらが占有する記憶領域は順に増加していきます。ここで言う型サイズとは、この型で表されるデータ範囲のサイズを指します。表現できる整数の範囲も、当然、順次増加します。整数列にインデックスを付けたい場合は、表現の整数範囲が許す限り、インデックス列でより小さい型を使用するようにしてください。たとえば、 int を使用します。bigint は使用しません。mediumint を使用できる場合は、int を使用しないでください。これは次の理由からです。
- データ型が小さいほど、クエリ中の比較操作が速くなります (これは CPU レベルでのものです)。
- データ型が小さいほど、インデックスが占有するストレージ領域が少なくなり、より多くのレコードをデータ ページに配置できるため、ディスク I/O によって引き起こされるパフォーマンスの損失が軽減され、より多くのデータ ページを保存できるようになります。メモリを使用して読み取りと書き込みの効率を高速化します。
この提案は、主キー値がクラスター化インデックスに保存されるだけでなく、レコードの主キー値も他のすべてのセカンダリ インデックスのノードに保存されるため、テーブルの主キーにより適しています。主キーは小さいデータ型に適しています。これは、より多くのストレージ領域を節約し、より効率的な I/O を意味します。
4.4 インデックス付き文字列値のプレフィックス
文字列は実際には複数の文字で構成されていることがわかっていますが、MySQL に文字列を格納するために utf8 文字セットを使用すると、1 文字をエンコードするのに 1 ~ 3 バイトかかります。文字列が非常に長いと仮定すると、文字列を保存するには多くの記憶領域が必要になります。この文字列列のインデックスを作成する必要がある場合、対応する B+ ツリーに 2 つの問題があることを意味します。
- B+ ツリー インデックス内のレコードには、列の完全な文字列を格納する必要があり、文字列が長ければ長いほど、インデックスで占有される記憶領域が大きくなります。
- B+ ツリー インデックスのインデックス列に格納されている文字列が非常に長い場合、文字列の比較に時間がかかります。
インデックス列の文字列プレフィックスは実際にはソートされていると前述しました。そのため、インデックス設計者は、文字列の最初の数文字のみにインデックスを付けるケースを提案しました。つまり、2 次インデックスのレコードでは、最初の文字だけを保持します。文字列の数文字。このようにして、レコードの検索時にレコードの位置を正確に特定することはできませんが、対応するプレフィックスの位置を特定することができ、その後、レコードの主キー値に従って完全な文字列値をテーブルにチェックバックすることができます。同じプレフィックスを持つレコードを比較して比較します。この方法では、文字列の最初の数文字のエンコーディングのみが B+ ツリーに保存されるため、スペースが節約されるだけでなく、文字列の比較時間が短縮され、おそらくソートの問題も解決できるでしょう。たとえば、テーブルを構築しています。このステートメントでは、次のように name 列の最初の 10 文字のみにインデックスが付けられます。
create table demo7(
c1 int not null auto_increment,
c2 varchar(11) not null,
c3 varchar(11) not null,
c4 char(11) not null,
c5 varchar(11) not null,
primary key(c1), key idx_c2_c3_c4(c2(10),c3,c4)
);
c2(10) は、確立された B+ ツリー インデックスでレコードの最初の 10 文字のエンコーディングのみが予約されることを意味します。文字列値のプレフィックスのみにインデックスを作成するこの戦略は、特に文字列型を格納できる場合に強く推奨されます。たくさんのキャラクターがいます。
ソートにおけるインデックス列プレフィックスの影響
たとえば、インデックス列プレフィックスが使用されている場合、列 c2 の最初の 10 文字のみがセカンダリ インデックスに配置される場合、次のクエリは少し厄介になる可能性があります。
select * from demo7 order by name limit 10;
セカンダリ インデックスには完全な c2 列情報が含まれていないため、最初の 10 文字が同じで、後の 10 文字が異なるレコードを並べ替えることはできません。つまり、インデックス列プレフィックスを使用する方法ではインデックス ソートの使用をサポートできません。 、ファイルの並べ替えのみ。
4.5 比較式でインデックス列を単独で使用する
テーブルに整数列 my_col があり、この列のインデックスを構築したとします。以下の 2 つの where 句は同じセマンティクスを持ちますが、効率が異なります。
- ここで、my_col * 2 < 4
- ここで、my_col < 4/2
最初の where 句の my_col 列は、別個の列の形式ではなく、my_col * 2 のような式の形式で表示されます。ストレージ エンジンはすべてのレコードを順番に走査し、この式の計算値を取得します。
is は 4 未満ではないため、この場合、my_col 列用に構築された b+ ツリー インデックスは使用できません。ただし、2 番目の where 句の my_col 列は別の列として表示されないため、
b+ ツリー インデックスを直接使用できます。
したがって、結論は次のとおりです。インデックス列が比較式の別の列の形式で表示されず、式または関数呼び出しの形式で表示される場合、インデックスは使用されません。
4.6 主キーの挿入順序
InnoDB ストレージ エンジンを使用するテーブルの場合、インデックスを明示的に作成しない場合、テーブル内のデータは実際にはクラスター化インデックスのリーフ ノードに格納されることがわかっています。レコードはデータ
ページに保存され、データ ページとレコードはレコードの主キー値の小さいものから大きいものの順に並べ替えられるため、挿入するレコードの主キー値が増加すると、データ ページ全体がいっぱいになったら、次のデータ ページに切り替えて挿入を続行します。挿入する主キーの値が大きいか小さい場合は、さらに面倒になります。特定のデータ ページがいっぱいで、そこに主キーが格納されています。キーの値は 1 ~ 100 であり、主キーの値が 100 未満のレコードを挿入します。現在のページを 2 つのページに分割し、一部を移動する必要があります。このページのレコードを新しく作成したページにコピーします。ページ分割とレコードシフトとは何を意味しますか? 意味: パフォーマンスの低下! したがって、このような不必要なパフォーマンスの低下を可能な限り回避したい場合は、そのようなパフォーマンスの低下が発生しないように、挿入されたレコードの主キーの値を順番に増やすことが最善です。したがって、主キーに auto_increment を持たせ、テーブル自体の主キーを手動で挿入するのではなく、ストレージ エンジンに生成させることをお勧めします。たとえば、demo7 テーブルを次のように定義できます。
create table demo7(
c1 int not null auto_increment,
c2 varchar(11) not null,
c3 varchar(11) not null,
c4 char(11) not null,
c5 varchar(11) not null,
primary key(c1), key idx_c2_c3_c4(c2(10),c3,c4)
);
カスタム主キー列 ID には auto_increment 属性があり、レコードの挿入時にストレージ エンジンが自動インクリメントされた主キー値を自動的に入力します。
4.7 冗長インデックスと重複インデックス
場合によっては、意図的または非意図的に同じ列に複数のインデックスを作成する学生もいます。たとえば、次のようなテーブル作成ステートメントを作成します。
create table demo7(
c1 int not null auto_increment,
c2 varchar(11) not null,
c3 varchar(11) not null,
c4 char(11) not null,
c5 varchar(11) not null,
primary key(c1),
key idx_c2_c3_c4(c2(10),c3,c4),
key idx_c2(c2(10))
);
c2 列は idx_c2_c3_c4 インデックスを使用して迅速に検索できることがわかっており、c2 列専用のインデックスを作成することは冗長インデックスとみなされます。このインデックスを維持するとメンテナンス コストが増加するだけで、検索にはメリットがありません。
別のケースでは、たとえば次のように、列にインデックスを繰り返し作成することがあります。
create table demo7(
c1 int primary key,
c2 int,
unique uidx_c1 (c1),
index idx_c1 (c1)
);
c1 は主キーであるだけでなく、一意のインデックスとして定義し、その共通インデックスも定義していることがわかりますが、主キー自体がクラスター化インデックスを生成するため、定義した一意のインデックスと共通のインデックスが繰り返されます。避けるべき状況。
要約する
以上はB+ツリーインデックスを作成・利用する際の注意点ですが、最適化方法や注意点については後ほど紹介していきますので、ご期待ください。このエピソードの内容を要約すると次のようになります。
- B+ ツリー インデックスにはスペースと時間のコストがかかるため、何もすることがない場合はインデックスを構築しないでください
- B+ ツリー インデックスは次の状況に適しています。
- 完全な値の一致
- 左の列と一致する
- 範囲値の一致
- 1 つの列に正確に一致し、範囲は別の列に一致します
- 仕分け用
- グループ分け用
- インデックスを使用する場合は、次の点に注意する必要があります。
- 検索、並べ替え、またはグループ化に使用される列のみにインデックスを付けます。
- カーディナリティが大きい列のインデックスを作成する
- インデックス列のタイプはできるだけ小さくする必要があります
- 文字列値のプレフィックスのみにインデックスを付けることが可能
- インデックスは、比較式内にインデックス列が単独で出現する場合にのみ適用できます。
- クラスター化インデックスでのページ分割とレコード シフトの発生を最小限に抑えるために、主キーに auto_increment 属性を持たせることをお勧めします。
- テーブル上の重複インデックスと冗長インデックスを見つけて削除します。
- テーブルに戻ることによるパフォーマンスの低下を避けるために、クエリにはカバリング インデックスを使用するようにしてください。
今日の勉強はこれで終わりです、あなたが壊れない自分になれることを願っています
~~~
先を見据えて点と点を結ぶことはできません。過去を振り返って接続することしかできません。したがって、点と点が何らかの形であなたの将来につながると信じなければなりません。あなたは何かを信頼しなければなりません - 自分の直感、運命、人生、カルマ、何でも。このアプローチは私を決して失望させず、私の人生に大きな変化をもたらしました
私のコンテンツがあなたのお役に立てましたら、どうぞ点赞、、、創作は簡単ではありません、皆さんのサポートが私が頑張れる原動力です评论收藏
