1.インデックスなしで検索
SELECT [列名列表] FROM 表名 WHERE 列名 = xxx;
1.ページ内を検索
現在、テーブルにレコードが少ないと仮定すると、すべてのレコードを1ページに保存できます。異なる検索条件に応じて、次の2つのケースに分けることができます。
- 主キーで検索
- 他の列で検索
2.多くのページで検索
ほとんどの場合、テーブルに保存されるレコードは非常に大きく、これらのレコードを保存するには多くのデータページが必要です。多くのページにわたるレコードの検索は、次の2つのステップに分けることができます。
- レコードが配置されているページに移動します。
- それが配置されているページから対応するレコードを見つけます。
主キー列または他の列の値に基づくかどうかにかかわらず、インデックスがない場合、レコードが配置されているページをすばやく見つけることができないため、最初のページから二重にリンクされたリストを下に移動することしかできません。各ページで、指定されたレコードを検索します。テーブルに多数のレコードがある場合、この検索効率は非常に低くなります。
二、索引
最初にテーブルを作成します。
CREATE TABLE index_demo(
c1 INT,
c2 INT,
c3 CHAR(1),
PRIMARY KEY(c1)
) ROW_FORMAT = Compact;
このテーブルの行形式は次のとおりです
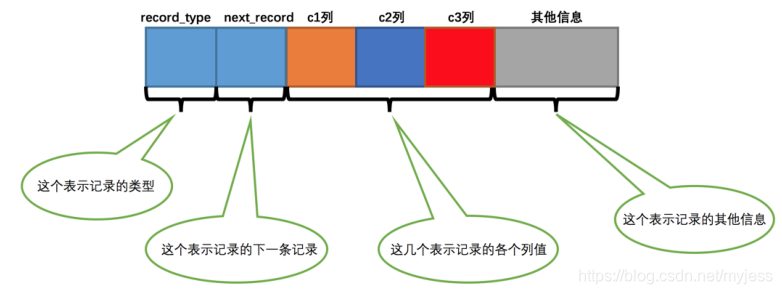
。record_type:レコードのタイプを示します。通常のレコードの場合は0、ディレクトリエントリレコードの場合は1、最小レコードの場合は2、最大レコードの場合は3
next_record:このレコードを基準にした次のアドレスのアドレスオフセットを示します。(わかりやすくするために、次の図では矢印を使用して次のレコードが誰であるかを示しています。)
ページにいくつかのレコードを置くことは次のとおりです。
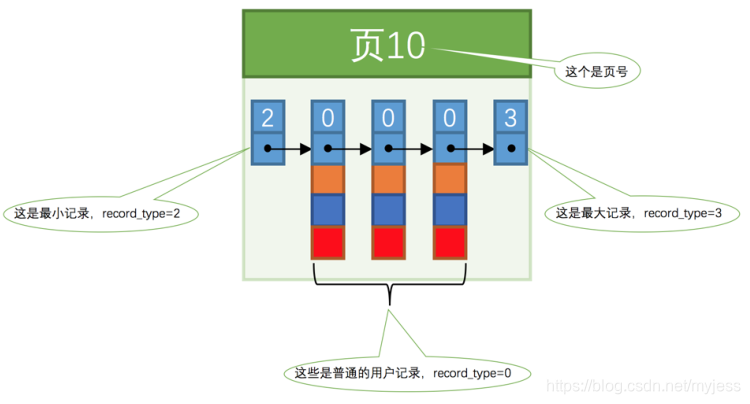
1.単純な索引付けスキーム
各ページのレコードは不規則であるため、検索条件が一致するレコードがわからないため、すべてのデータページを順番にトラバースする必要があります。
検索する必要のあるレコードのデータページをすばやく見つけたい場合は、データページ用に別のディレクトリを作成できます。確立されたディレクトリは主に以下を満たします。
- 次のデータページのユーザーレコードの主キー値は、前のページのユーザーレコードの主キー値よりも大きくする必要があります(各データページに最大3つのレコードを保存できると仮定)。
INSERT INTO index_demo VALUES(1, 4, 'u'), (3, 9, 'd'), (5, 3, 'y');
Query OK, 3 rows affected (0.01 sec)
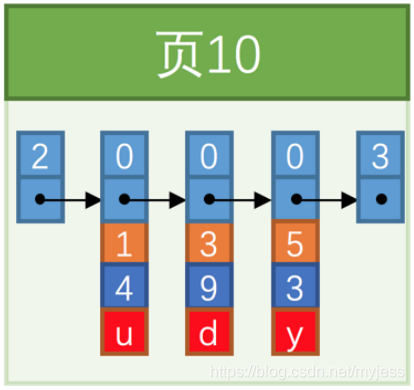
次に、別のレコードを挿入しましょう。
INSERT INTO index_demo VALUES(4, 4, 'a');
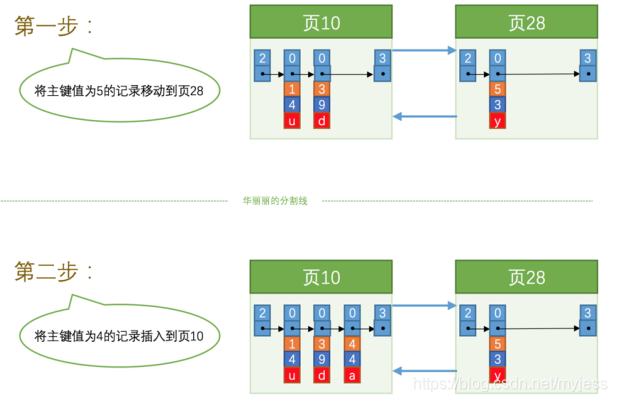
ページ10は最大3つのレコードしか保持できないため、新しいページを割り当てる必要があります。
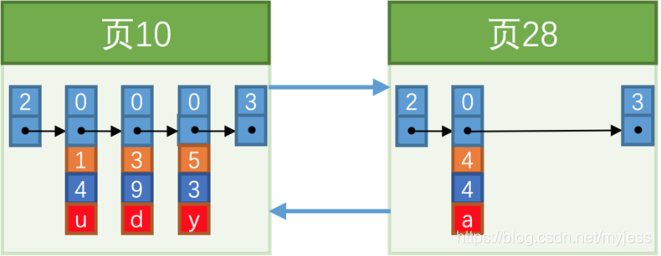
新しく割り当てられたデータページの数は連続していない可能性があります。つまり、使用するページがストレージスペース内で隣り合っていない可能性があります。前のページと次のページの番号を維持することによってのみ、リンクリストの関係を確立します。
10ページのユーザーレコードの最大主キー値は5であり、28ページのレコードの主キー値は4です。これは、5> 4であるため、次のユーザーレコードの主キー値と一致しません。データページは、前のページのユーザーレコードの主キー値の要件よりも大きくする必要があるため、主キー値が4のレコードを挿入する場合は、レコードの移動、つまりレコードを伴う必要があります。主キーの値が5のレコードは28ページに移動され、次にレコードが移動されます。主キーの値が4のレコードがページ10に挿入されます。
このプロセスはページ分割と呼ばれます。
- すべてのページのディレクトリエントリを作成します。
データページの数が連続していない可能性があるため、index_demoテーブルに多くのレコードを挿入した後、次のような効果があります
。主キーの値。これらのレコードが配置されているページについては、それらのディレクトリを作成する必要があり、各ページはディレクトリエントリに対応しています。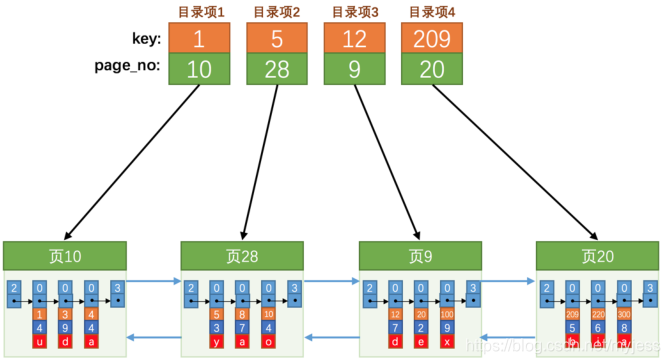
いくつかのディレクトリエントリを入れる必要があります物理メモリ上の連続ストレージ、それらを配列に配置するなど、主キー値に基づいてレコードをすばやく見つけることができます。
データページの単純なディレクトリが作成されます。このディレクトリには、インデックスと呼ばれるエイリアスがあります。
2.InnoDBのインデックススキーム
上記が単純なインデックススキームと呼ばれる理由は、主キー値に基づいて検索するときに二分法を使用して特定のディレクトリアイテムをすばやく見つけるために、すべてのディレクトリエントリを物理メモリに連続して格納できると想定しているためです。いくつかの質問:
- InnoDBは、ストレージスペースを管理するための基本単位としてページを使用します。つまり、最大16KBの連続ストレージスペースを保証できます。テーブル内のレコード数が増えると、すべてを置くために非常に大きな連続ストレージスペースが必要になります。ディレクトリ項目。これは、レコード数が非常に多いテーブルには実用的ではありません
。 - レコードを追加または削除することがよくあります。28ページですべてのレコードを削除し、28ページが存在する必要がない場合、つまり、ディレクトリエントリ2が存在する必要がなく、ディレクトリエントリが必要であるとします。2以降のディレクトリ項目は次のとおりです。前方に移動した。
したがって、以前にユーザーレコードを保存したデータページを再利用してディレクトリアイテムを保存できます。ユーザーレコードと区別するために、ディレクトリアイテムを表すために使用されるこれらのレコードを次のように呼び出します。ディレクトリエントリレコード。
InnoDBは、レコードが通常のユーザーレコードであるかディレクトリエントリレコードであるかをどのように区別しますか?
- レコードヘッダー情報のrecord_type属性を介して
0:通常のユーザーレコード1:ディレクトリエントリレコード2:最小レコード3:最大レコード
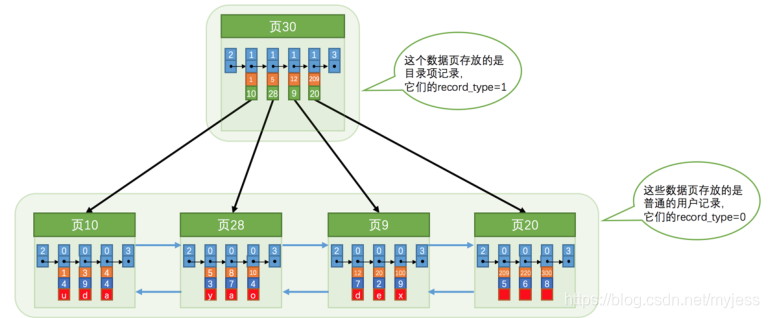
ディレクトリエントリレコードと通常のユーザーレコードの違い:
- ディレクトリエントリレコードのrecord_type値は1であり、通常のユーザーレコードのrecord_type値は0です。
- カタログアイテムレコードには、主キー値とページ番号の2つの列しかありませんが、通常のユーザーレコードの列はユーザーによって定義され、多くの列と、InnoDB自体によって追加された非表示の列が含まれる場合があります。
- レコードヘッダー情報にはmin_rec_mask属性があります。ディレクトリエントリレコードを格納するページで主キー値が最小のディレクトリエントリレコードのみがmin_rec_mask値1を持ち、他のレコードのmin_rec_mask値は0です。
したがって、主キー値に基づいてレコードを検索する手順は、大きく次の2つの手順に分けることができます。
- まず、ディレクトリエントリレコードが保存されているページ(30ページ)に移動して、対応するディレクトリエントリを二分法ですばやく見つけます。12<20 <209であるため、対応するレコードが配置されているページは9ページです。
- 次に、ユーザーレコードが保存されている9ページに移動し、二分法に従って主キー値が20のユーザーレコードをすばやく見つけます。
Q:ディレクトリエントリレコードには、主キーの値と対応するページ番号のみが格納されていると言われていますが、これはユーザーレコードに必要なストレージスペースよりもはるかに小さいですが、ページのサイズはわずか16KBであり、保存できるディレクトリエントリレコードも限られています。データが多すぎるため、1つのデータページではすべてのディレクトリエントリレコードを保存できません。どうすればよいですか。
A:ディレクトリエントリレコードを保存するページをもう1つ追加します
ディレクトリエントリレコードを格納するページは最大4つのディレクトリエントリレコードしか格納できないと想定します。ディレクトリエントリレコードを格納する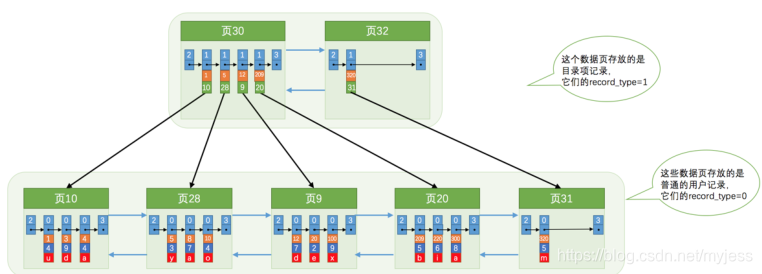
ページが複数あるため、主キー値に基づいてユーザーレコードを検索する場合は、およそ3つのステップが必要です。
- カタログエントリレコードページを特定します。
- ユーザーレコードが実際に配置されているページは、ディレクトリエントリレコードページによって決定されます。
- 実際のユーザーレコードが保存されているページで特定のレコードを見つけます。
質問:ステップ1では、カタログアイテムのレコードを格納するページを見つける必要がありますが、これらのページはストレージスペース内で隣り合っていない可能性があります。テーブルに大量のデータがある場合、カタログアイテムレコードを保存する主キー値に基づいてディレクトリアイテムレコードを保存しているページをすばやく見つけるにはどうすればよいですか?
A:次に、ディレクトリエントリレコードを格納するこれらのページに対して、より高いレベルのディレクトリが生成されます。
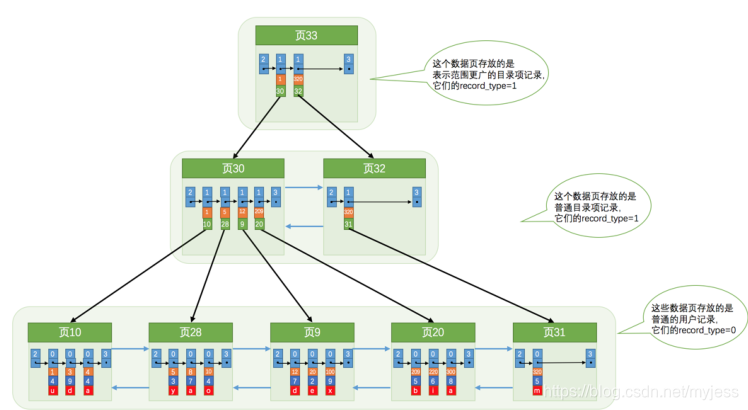
このグラフはB+ツリーであることがわかりました。
ユーザーレコードを格納するデータページであろうと、ディレクトリエントリレコードを格納するデータページであろうと、B +ツリーデータ構造に格納するため、これらのデータページノードとも呼ばれます。
図からわかるように、実際のユーザーレコード実際、これらはすべてB +ツリーの最下位ノードに格納されます。これらのノードはリーフノードとも呼ばれます。ディレクトリアイテムの格納に使用される残りのノードは、非リーフノードと呼ばれます。B+ツリーの最上位ノードもルートノードと呼ばれます。
- InnoDBでは、最下層、つまりユーザーレコードを格納する層が0番目の層であると規定されており、順番に追加されます。
- 通常の状況では、使用するB+ツリーは4層を超えることはありません。
- 主キー値を使用してレコードを検索するには、最大4ページ以内で検索する必要があります(3つのディレクトリアイテムページとユーザーレコードページを検索します)。各ページにページディレクトリページディレクトリがあるため)。二分法により、ページをすばやく配置して記録することもできます。
1.クラスター化されたインデックス
以前に紹介したB+ツリーは、それ自体がディレクトリ、またはインデックス自体です。2つの機能があります。
- レコードの主キー値のサイズを使用して、レコードとページを並べ替えます。これには、次の3つの意味があります。
- ページ内のレコードは、主キーのサイズに従って単一リンクリストに配置されます。
- ユーザーレコードを格納する各ページも、ページ内のユーザーレコードの主キーのサイズに応じて、二重にリンクされたリストに配置されます。
- ディレクトリエントリレコードを格納するページはさまざまなレベルに分割され、同じレベルのページも、ページ内のディレクトリエントリレコードの主キーのサイズに応じて、二重にリンクされたリストに配置されます。
- B +ツリーのリーフノードには、完全なユーザーレコードが格納されます。
- 完全なユーザーレコードとは、すべての列の値(非表示の列を含む)がこのレコードに保存されることを意味します。
これらの2つのプロパティを持つB+ツリーを次のように呼びます。クラスター化されたインデックス、すべての完全なユーザーレコードは、このクラスター化インデックスのリーフノードに保存されます。このクラスター化インデックスでは、MySQLステートメントでINDEXステートメントを明示的に使用して作成する必要はありません。InnoDBストレージエンジンがクラスター化インデックスを自動的に作成します。
InnoDBストレージエンジンでは、クラスター化インデックスはデータのストレージ方法です(すべてのユーザーレコードはリーフノードに格納されます)。つまり、いわゆるインデックスはデータであり、データはインデックスです。
2.セカンダリインデックス
B +ツリーのデータは主キーで並べ替えられるため、クラスター化インデックスは、検索条件が主キー値である場合にのみ機能します。他の列を検索条件として使用したい場合はどうなりますか?
さらにいくつかのB+ツリーを構築でき、さまざまなB+ツリーのデータはさまざまな並べ替えルールを使用します。たとえば、c2列のサイズをデータページとページ内のレコードの並べ替えルールとして使用し、図に示すようにB+ツリーを構築します。
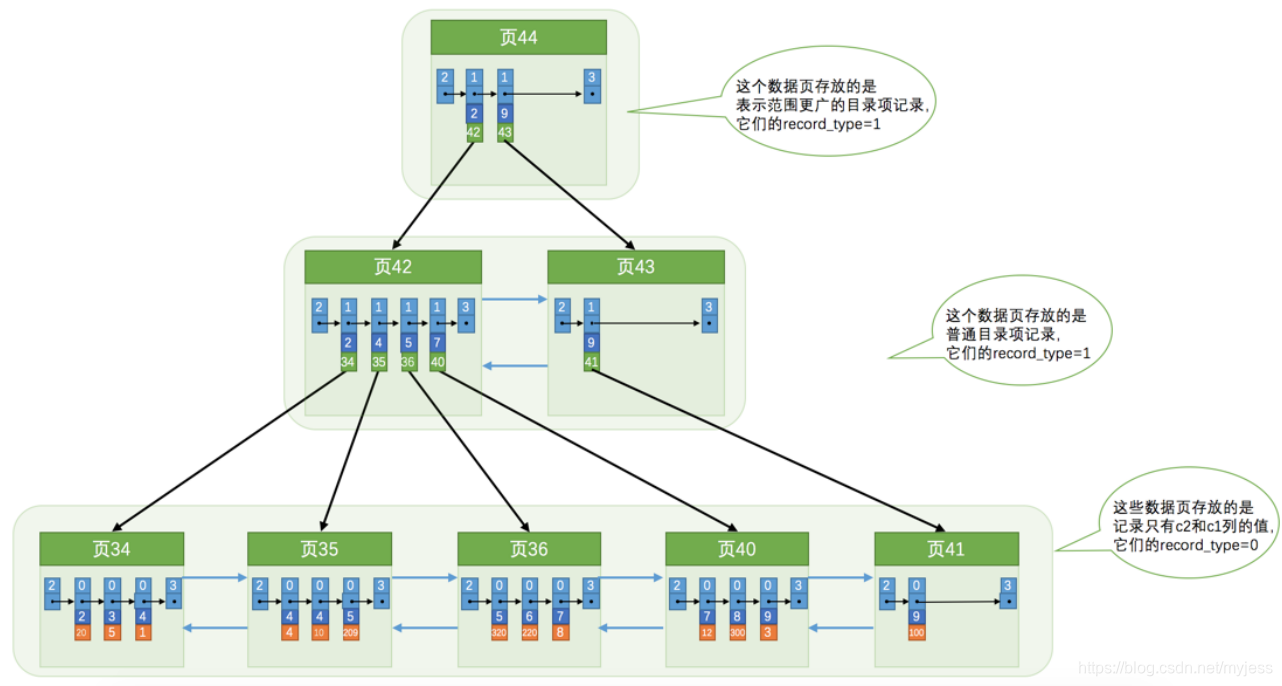
このB+ツリーは、上記で紹介したクラスター化インデックスとは異なります。 :
- レコードc2列のサイズを使用して、レコードとページを並べ替えます。これには、次の3つの意味があります。
- ページ内のレコードは、c2列のサイズに従って単一リンクリストに配置されます。
- ユーザーレコードを格納する各ページも、ページに記録されているc2列のサイズに応じて二重リンクリストに配置されます。
- ディレクトリエントリレコードを格納するページは異なるレベルに分割され、同じレベルのページも、ページ内のディレクトリエントリレコードのc2列のサイズに応じて二重リンクリストに配置されます。
- B +ツリーのリーフノードには完全なユーザーレコードは保存されませんが、2つの列c2列+主キーの値のみが保存されます。
- カタログエントリレコードは、主キー+ページ番号の組み合わせではなく、列c2+ページ番号の組み合わせになります。
ユーザーレコードを検索する場合、リーフノードにはc2列と主キー列しか格納されないため、主キー値に従ってクラスター化インデックスで完全なユーザーレコードを再度検索する必要があります。このプロセスはリターンテーブルと呼ばれます。
Q:完全なユーザーレコードをリーフノードに直接配置してみませんか?
A:リーフノードに完全なユーザーレコードを格納するためにテーブルを返す必要はありませんが、これはB +ツリーが構築されるたびにすべてのユーザーレコードをコピーすることと同じであり、ストレージスペースの浪費です。したがって、非主キー列に基づくこのB +ツリーでは、完全なユーザーレコードを見つけるためにテーブルの戻り操作が必要になるため、このB+ツリーも呼び出されます。二次インデックスまたはセカンダリインデックス。
C2列のサイズをB+ツリーの照合として使用しているため、このB+ツリーをc2列のインデックスとも呼びます。
3.ジョイントインデックス
複数の列のサイズを同時に並べ替えルールとして使用することもできます。つまり、同時に複数の列のインデックスを作成することもできます。たとえば、c2とのサイズに従ってB+ツリーを並べ替えます。 2つの意味を含むc3列:
- まず、列c2に従って各レコードとページを並べ替えます。
- レコードのc2列が同じ場合、c3列はソートに使用されます
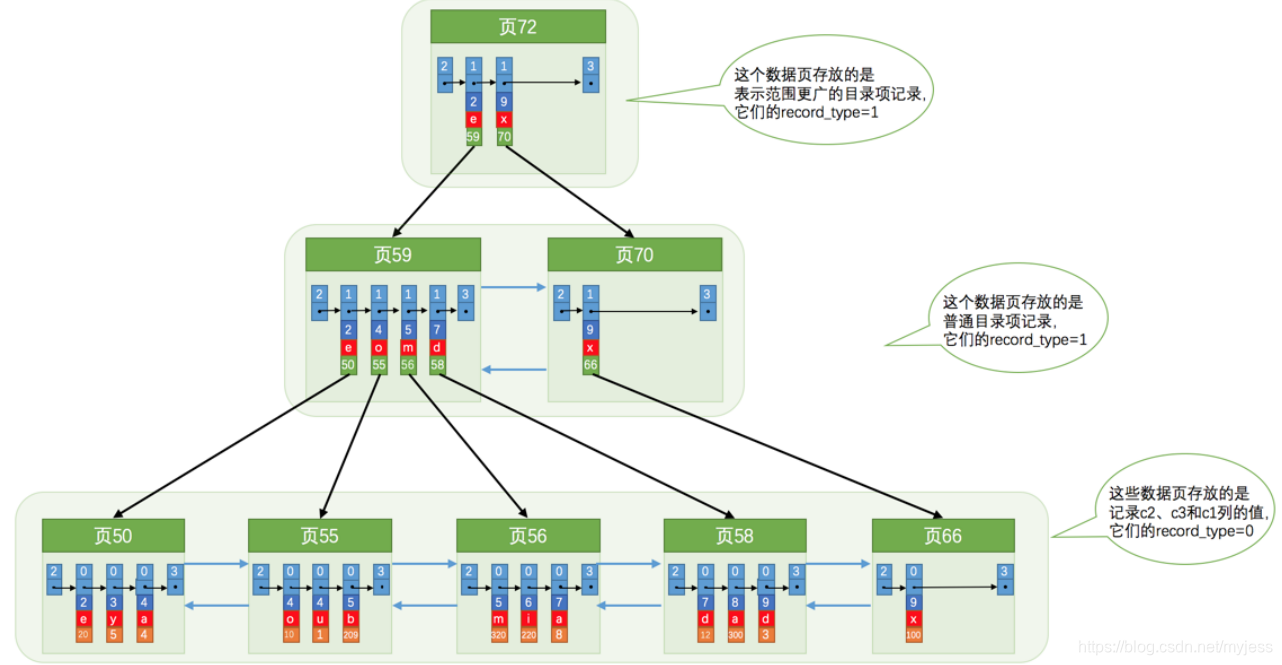
- 各レコードは、最初にc2列の値に従ってソートされます。レコードのc2列が同じである場合は、c3列の値に従ってソートされます。
- B +ツリーのリーフノードのユーザーレコードは、列c2、c3、および主キーc1で構成されます。
照合と呼ばれるc2列とc3列のサイズで構築されたB+ツリージョイントインデックス、これは本質的にセカンダリインデックスです。その意味は、列c2とc3に別々に索引を付けるステートメントとは異なります。
- ジョイントインデックスを作成すると、上記のようにB+ツリーのみが作成されます。
- 列c2とc3にそれぞれインデックスを付けると、照合ルールとしてそれぞれ列c2とc3のサイズを持つ2つのB+ツリーが作成されます。
3.注意が必要な事項
以前にB+ツリーインデックスが導入されたとき、理解しやすいように、ユーザーレコードを格納するリーフノードが最初に描画され、次にディレクトリエントリレコードを格納する内部ノードが描画されますが、実際には、B+ツリーの形成プロセスです。以下のとおりであります:
- テーブルに対してB+ツリーインデックスが作成されると(クラスター化インデックスは人為的に作成されないため、デフォルトで存在します)、このインデックスに対してルートノードページが作成されます。最初にテーブルにデータがない場合、各B+ツリーインデックスに対応するルートノードにはユーザーレコードもディレクトリエントリレコードもありません。
- ユーザーレコードをテーブルに挿入するときは、最初にこのルートノードにユーザーレコードを保存します。
- ルートノードの空き容量がなくなったら、引き続きレコードを挿入します。このとき、ルートノードのすべてのレコードがページaなどの新しく割り当てられたページにコピーされ、ページ分割操作が実行されます。この新しいページは、ページbなどの別の新しいページを取得します。このとき、新しく挿入されたレコードは、キー値(つまり、クラスター化インデックスのプライマリキー値、セカンダリインデックスの対応するインデックス列の値)のサイズに応じてページaまたはページに割り当てられます。ルートノードがアップグレードされます。カタログエントリレコードを保存するためのページ。
B +ツリーインデックスのルートノードは、その誕生以来移動しません。このように、テーブルにインデックスを作成する限り、そのルートノードのページ番号がどこかに記録され、InnoDBストレージエンジンがこのインデックスを使用する必要があるときはいつでも、その固定からルートノードを取り出しますこのインデックスにアクセスするためのページ番号を配置します。
B +ツリーインデックスの内部ノードのディレクトリエントリに記録されるコンテンツは、インデックス列とページ番号の組み合わせですが、この組み合わせはセカンダリインデックスでは少し不正確です。B +ツリーの同じレベルにあるノードのディレクトリエントリレコードが、ページ番号フィールドを除いて一意であることを確認する必要があります。
したがって、セカンダリインデックスの内部ノードのディレクトリエントリによって記録されるコンテンツは、実際には次の3つの部分で構成されます。
- インデックス列の値
- 主キー値
- ページ番号
InnoDBでは、インデックスはデータです。つまり、クラスター化インデックスのB +ツリーのリーフノードには、すでにすべての完全なユーザーレコードが含まれています。MyISAMインデックススキームもツリー構造を使用しますが、インデックスとデータを組み合わせて保存します。
第4に、MySQLでインデックスを作成および削除します
InnoDBとMyISAMは、UNIQUEとして宣言された主キーまたは列のB +ツリーインデックスを自動的に作成しますが、他の列のインデックスを作成する場合は、明示的に指定する必要があります。
#创建
CREATE TALBE 表名 (
各种列的信息 ··· ,
[KEY|INDEX] 索引名 (需要被索引的单个列或多个列)
)
ALTER TABLE 表名 ADD [INDEX|KEY] 索引名 (需要被索引的单个列或多个列);
ALTER TABLE 表名 DROP [INDEX|KEY] 索引名;
#删除
ALTER TABLE 表名 DROP INDEX 索引名;
たとえば、index_demoテーブルを作成するときにc2列とc3列にジョイントインデックスを追加する場合は、次のようにテーブル作成ステートメントを記述できます。
CREATE TABLE index_demo(
c1 INT,
c2 INT,
c3 CHAR(1),
PRIMARY KEY(c1),
INDEX idx_c2_c3 (c2, c3)
);