1. データ構造
1.1. 基本概念
データ構造とは、データの集合とデータ間の関係です。コンピューターがデータを保存および整理する方法です。物を保管するためのさまざまな箱のようなものです。さまざまなものがさまざまな箱に詰められ、役割を果たします。半分の労力で2倍の成果が得られる効果、
1.2 データ構造の分類
論理構造に従って、コレクション、線形、ツリー、グラフ、
論理構造: データとデータの間の接続をデータの論理構造といいます。
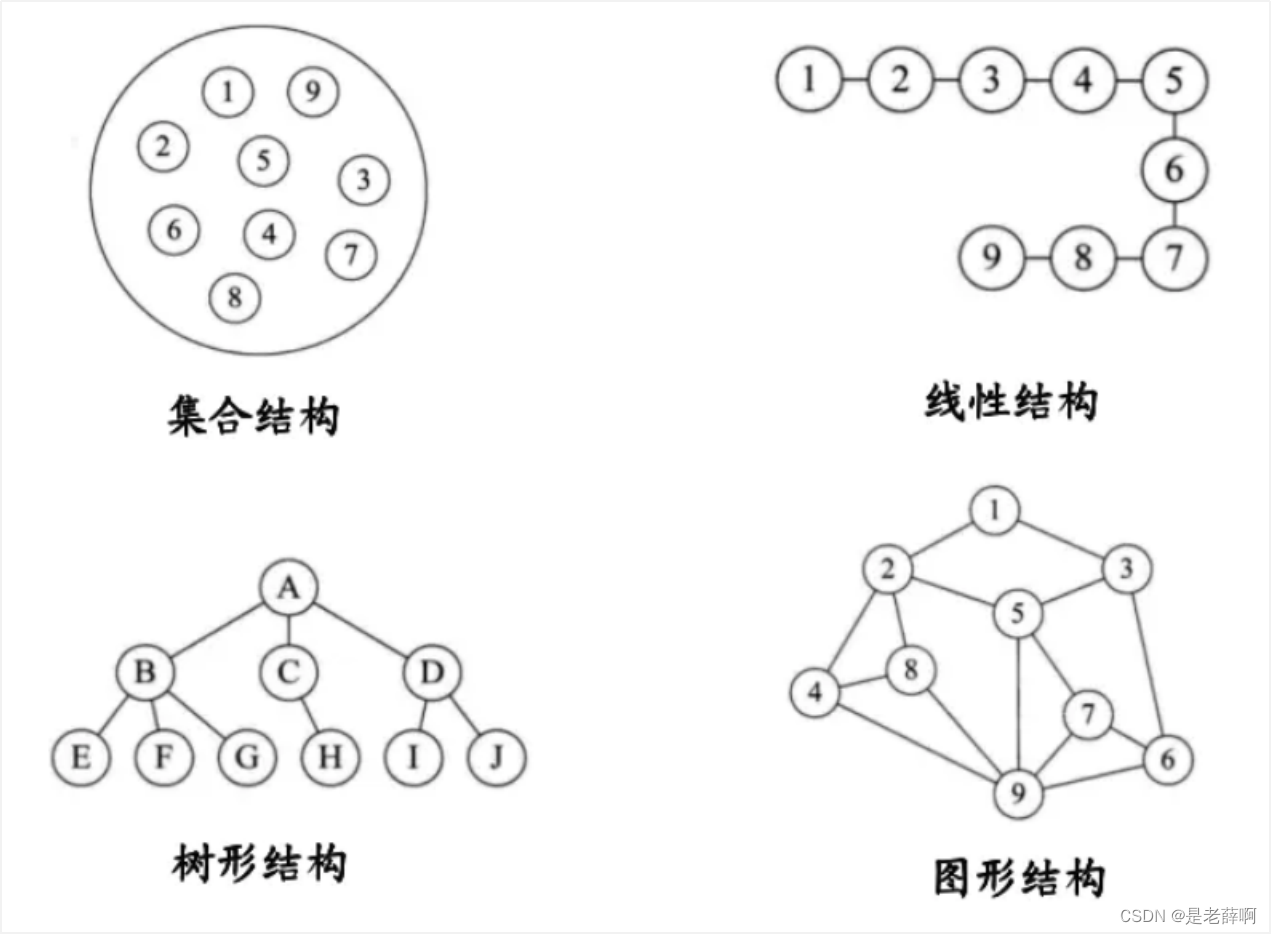
セット構造: データはすべて同じ場所に配置され、データ間には関連性がありません。ちょうどバスに乗るのと同じで、バスの乗客はセットです。
線形構造: この構造内のデータ間には 1 対 1 の関係があり、核酸を作成するために列に並ぶのと同じように、1 対 1 であり、それらの間には逐次的な関係があります。
ツリー構造: この構造内のデータには 1 対多の関係があり、学校の教師と同じように、教師が生徒のクラスを教えます。
グラフィカル構造: この構造内のデータには多対多の関係があり、ちょうど人が複数の ID を持つことができ、1 つの ID を複数の人が同時に所有できるのと同じです。
1.3 物理構造の分類
物理構造に従って、シーケンシャルストレージ構造、リンクストレージ構造、データインデックスストレージ構造、データハッシュストレージ構造(ハッシュ)に分けられます。
物理構造: コンピュータに保存されているデータの論理構造をデータの物理構造といいます。
A-- 順次ストレージ構造: コンピュータに保存される場合、コンピュータに保存された各データ要素を保存するための連続したメモリ空間になります。
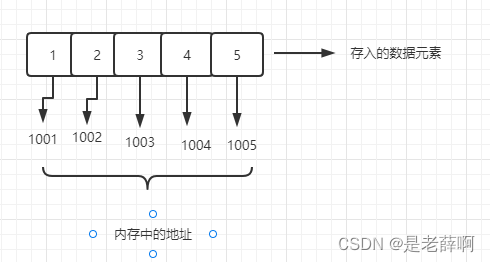
利点: メモリのアドレスのみが分かるため、ランダムアクセスが可能
不十分: 挿入と削除が非効率で、サイズが固定されています。
代表: 配列
B - リンクされたストレージ構造: コンピュータに保存されると、配置された各要素の位置はメモリ内で互いに隣接し、また互いに隣接します。
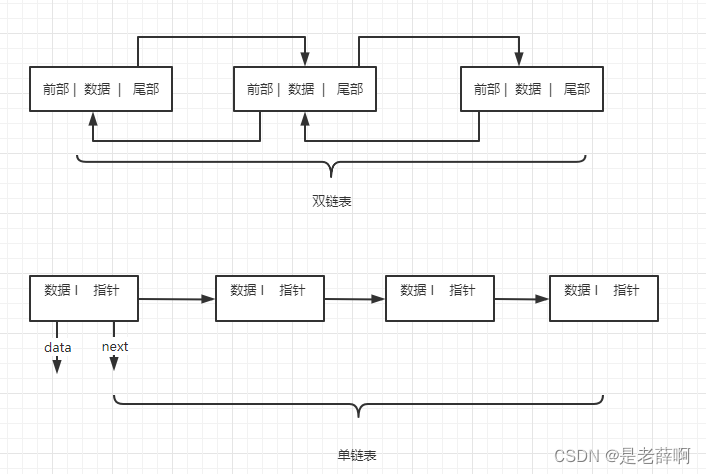
利点: サイズの動的拡張、高い挿入および削除効率
短所: ランダムアクセス、クエリ効率の低さ、断片化を起こしやすい、メモリ管理にはあまり優しくない
代表者:リンクリスト
C--データインデックス格納構造: 名前が示すように、インデックスを付けることであり、対応するインデックスが示す位置にインデックスを使用してデータを配置します。たとえば、図書館に行って本を探すときなどです。 、本の検索カードが与えられます (どの層またはどのレベルですか? 個別)。
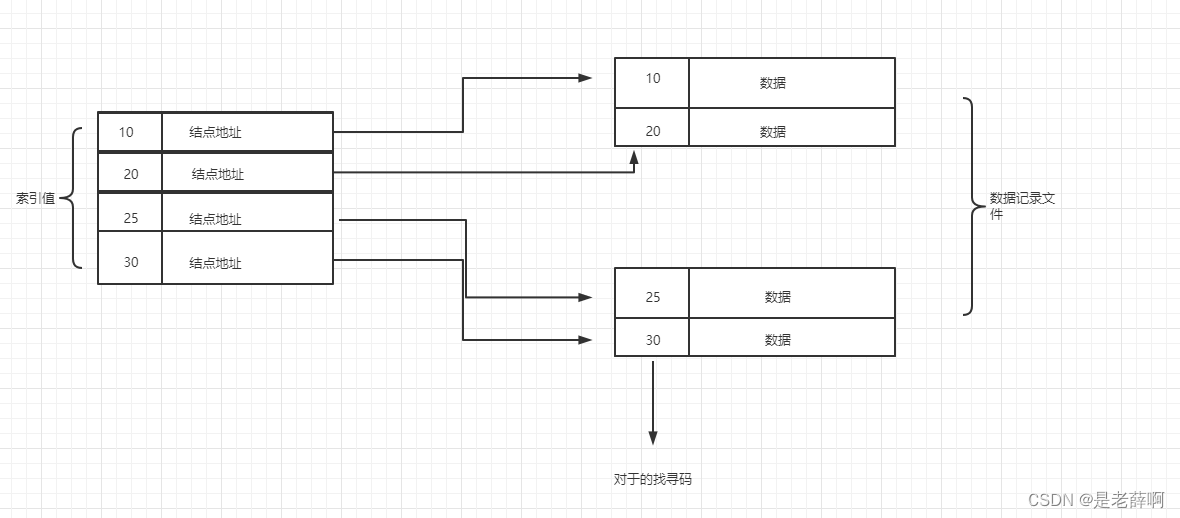
このピクチャはスパース インデックス (つまり、ノードのグループがインデックス テーブル内の検索コード項目に対応する) であり、それ以外の場合はデンス インデックスです。
長所: 高速な検索
短所: 冗長インデックステーブルが追加されるため、より多くのストレージスペースが必要になります。
D--データハッシュストレージ構造(ハッシュストレージ):関数を通じてデータを別の値に変換します。この値はコンピュータ上のこのデータのアドレス値であり、この関数はハッシュ関数であり、変換されたデータが配置される場所ですリストです
利点: これは配列に似ていますが、クエリ速度は配列よりも高速です。
不十分: ランダムアクセス、順番に検索するのが難しい
2. 共通のデータ構造
2.1 コレクションの構造
セット、ハッシュセット ツリーセット
2.2 線形構造
配列、スタック (FIFO)、キュー (FIFO)、文字列、リスト
2.3 ツリー構造
1. 木とは何ですか?
1 つ以上のノードで構成され、ルート ノードの形式のデータ構造が存在します。
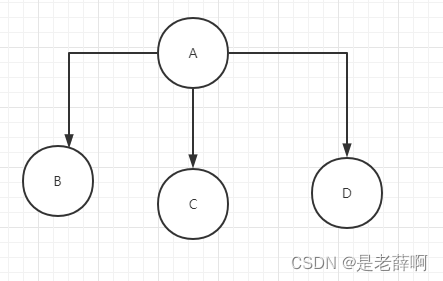
A: ルートノードです
B、C、D: A の子ノードですが、兄弟ノードであり、BCD の下に子ノードはありません (リーフ ノードとも呼ばれます)。
2. 二分木とは何ですか?
つまり、ツリー内の各ノードの次数は 2 を超えません (つまり、それぞれに 2 つの子があります)。
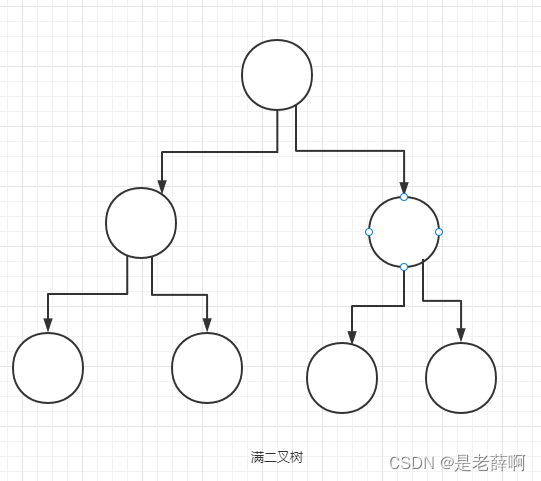
完全なバイナリ ツリー (両側が完全)
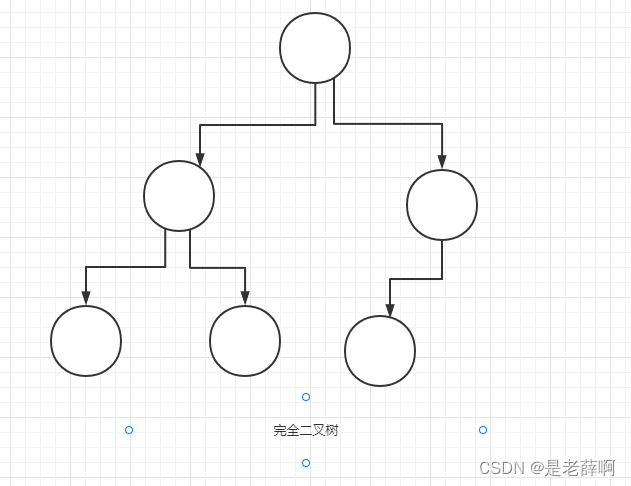
完全な二分木 (次の条件を満たす: 1. 最後の層を除いて、もう 1 つは完全な二分木である、2. 最後の層のノードは左から右に順番に分散される)
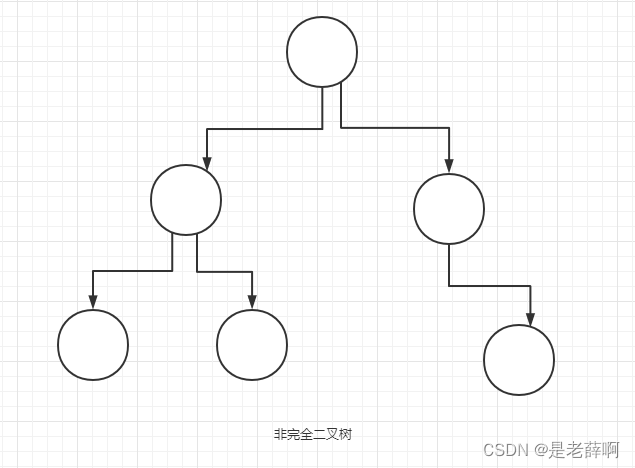
安全でないバイナリ ツリー (なし)
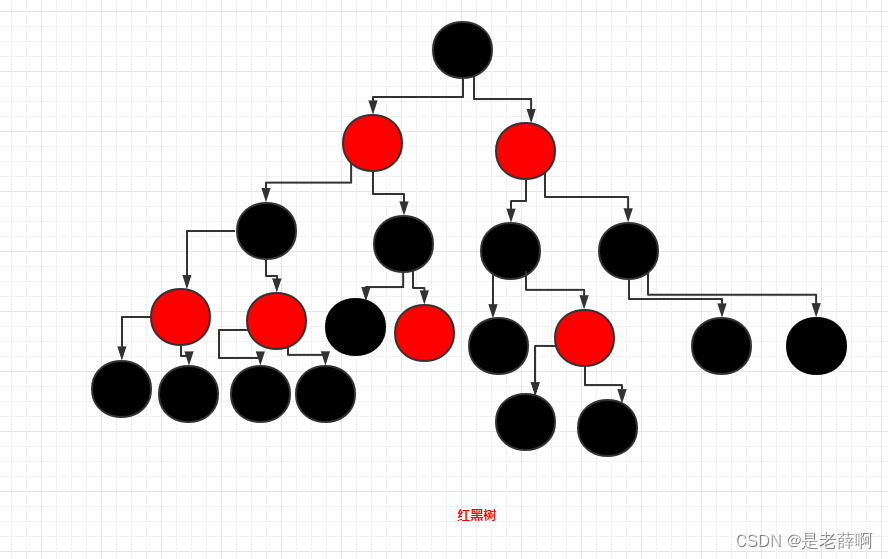
赤黒の木:
特徴: 1. ルートノードは黒です 2. 葉ノードは黒です 3. 赤の隣は黒でなければなりません 4. ルートノードから始まる両側の線の黒は同じです
赤黒ツリーも二分木に属し、色を回転させて変更することでバランスを確保します。
代表的なもの:JavaのTreeSetとTreeMapの最下層
3.BツリーとB+ツリー
B ツリーは、マルチフォーク ツリー (ツリー レベルが高くなりすぎてディスク IO、読み取りと書き込みが頻繁に発生することを避けるため) であり、バランスの取れたツリーです。
特徴: 1. 各ノードには 2 つ以上のストアがあります
2. データはノードに保存され、データは繰り返し保存されません。
3. B ツリーは比較的短く、IO 回数が少ないほど、検索パフォーマンスが向上します。
B+ ツリーはB ツリーを拡張したもので、内部ノードにはアドレスのみが記録され、データは葉ノードに格納されます。リーフ ノードには、リーフ ノードを接続する二重リンク リストがあります。クエリ効率は比較的高く、ツリーの高さはわずか 3 層です
代表: mysql は B+ ツリーを使用します
3. アルゴリズム
3.1 アルゴリズムとは何ですか?
これは問題を解決するためのステップです。一般に、これはインターフェイスの効率を最適化するために使用できます。たとえば、ステップ数が減れば、それに応じてリターン効率も高くなります。
3.2 アルゴリズムの複雑さ
アルゴリズムが時間計算量と空間計算量にどのように基づいているかを説明する
時間計算量: 時間周波数、定数次数 O(1)、対数次数 O(log2n)、線形次数 O(n) を含みます。。。待って
スペースの複雑さ: プロセスの実行中にアルゴリズムが一時的に占有するストレージスペースのサイズの尺度です。
例: 私たちが知っているキャッシュは時間のための空間です
3.3 一般的なアルゴリズム
A--ハッシュ アルゴリズム: 任意の長さのデータを指定すると、ハッシュ アルゴリズムを通じてそれを固定長に変換します (ただし、変換された値は一貫しているように見え、ハッシュの衝突が発生する可能性があります)
例: MD5 SHA-1 など。
B--再帰: それ自体を呼び出します。条件に達すると、このループから飛び出します。そうでない場合は、呼び出しを続けます。
注: 必ず終了してください。終了しないと、コンピュータが GG になります。
C--ソート: 以下のようなさまざまなソート方法があります。
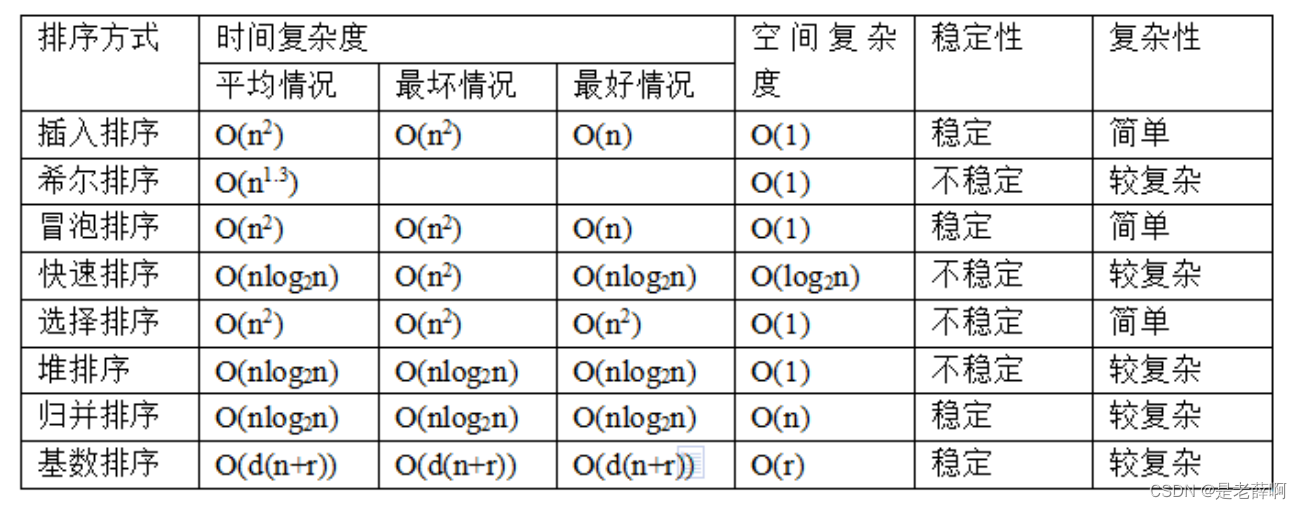
以下では Java でのソートについて説明します。
キーワード: Arrays.sort (要素 <47、挿入ソートを使用、要素 <286 はクイックソートを使用)
キーワード: Arrars.aslist (自然な順序に従って昇順に並べ替えます)
Java で実際にかかる時間は一部の関数を使用するだけであり、それを解決するためにメソッドが呼び出されます。
10 の古典的なアルゴリズムの詳細かつ詳細な研究については、次の記事をご覧ください。
https://www.runoob.com/w3cnote/ten-sorting-algorithm.html
アルゴリズムについては一般的な理解しかありません。この章はアルゴリズムについての浅い研究と理解です。もちろん、これらはアルゴリズムの氷山の一角にすぎません。
勉強と交換へようこそ、欠点を指摘してください、気に入ったら、いいね+ブックマークしてください、ありがとうございます