目次
1. 理論的根拠
顔認識技術は、セキュリティ、金融、医療などの分野で広く使われている技術で、顔画像から人物の身元情報を識別することができます。2D-LDA (二次元線形判別分析) は、一般的に使用される特徴抽出手法であり、異なる次元の特徴を抽出できるため、認識率が向上します。本稿では、2D-LDA特徴抽出に基づく顔認識アルゴリズムとその認識率曲線について、数式と実装手順の2つの側面から詳しく紹介します。
1.1 LDA 特徴抽出
2D-LDA 特徴抽出を紹介する前に、LDA 特徴抽出について確認してみましょう。LDA 特徴抽出は一般的に使用される分類方法であり、データの分類情報を保持しながらデータの次元を削減することで分類精度を向上させます。
$n$ 個のサンプルで構成されるデータセット $X={x_1,x_2,...,x_n}$ があり、各サンプルには $d$ 次元の特徴とカテゴリ ラベル $y_i$ があるとします。私たちの目標は、このデータは $k$ 次元に設定されているため、次元を削減したデータにより、同じカテゴリ内の距離を最小化しながら、異なるカテゴリ間の距離を最大化できます。2 つの行列 $S_w$ と $S_b$ の固有値を分解して固有ベクトル行列 $W$ を取得し、各サンプル $x_i$ に変換行列 $W$ を乗算して、次元削減されたサンプル $ を取得できます。 y_i =W^Tx_i$。LDA の数式は次のとおりです。
各カテゴリの平均を計算します:
$$\overline{x}i=\frac{1}{n_i}\sum{j=1}^{n_i}x_{ij},\quad i=1,2,.. .,c$$
このうち、$c$ はカテゴリの数、$n_i$ は $i$ 番目のカテゴリのサンプル数です。
母集団の平均値を計算します:
$$\overline{x}=\frac{1}{n}\sum_{i=1}^c\sum_{j=1}^{n_i}x_{ij}$$
このうち、$n$ はサンプルの総数です。
クラス内散布行列 $S_w$ を計算します:
$$S_w=\sum_{i=1}^c\sum_{j=1}^{n_i}(x_{ij}-\overline{x}i)(x { ij}-\overline{x}_i)^T$$
クラス間散布行列 $S_b$ を計算します:
$$S_b=\sum_{i=1}^c n_i(\overline{x}_i-\overline{x})(\overline{x}_i-\overline{ x })^T$$
行列 $S_w^{-1}S_b$ に対して固有値分解を実行します:
$$S_w^{-1}S_b=V\Lambda V^T$$
このうち、$V$ は固有ベクトル行列、$\Lambda$ は固有値対角行列です。
最大の $k$ 固有ベクトルを取得します:
$$W=[v_1,v_2,...,v_k]$$
各サンプルを変換します:
$$y_i=W^Tx_i$$
このうち、$k$ は次元削減後の次元、$y_i$ は次元削減後のサンプルベクトルです。
1.2 2D-LDA 特徴抽出
2D-LDA 特徴抽出は LDA の拡張であり、異なる次元の特徴を抽出して認識率を向上させることができます。LDA とは異なり、2D-LDA は散乱行列を 2 方向に固有値分解し、それぞれ異なる特徴次元に対応する異なる固有ベクトル行列 $W_1$ と $W_2$ を取得します。具体的な数式は次のとおりです。
各カテゴリの平均を計算します:
$$\overline{x}i=\frac{1}{n_i}\sum{j=1}^{n_i}x_{ij},\quad i=1,2,.. .,c$$
このうち、$c$ はカテゴリの数、$n_i$ は $i$ 番目のカテゴリのサンプル数です。
母集団の平均値を計算します:
$$\overline{x}=\frac{1}{n}\sum_{i=1}^c\sum_{j=1}^{n_i}x_{ij}$$
このうち、$n$ はサンプルの総数です。
クラス内散布行列 $S_w$ を計算します:
$$S_w=\sum_{i=1}^c\sum_{j=1}^{n_i}(x_{ij}-\overline{x}i)(x { ij}-\overline{x}_i)^T$$
クラス間散布行列 $S_b$ を計算します:
$$S_b=\sum_{i=1}^c n_i(\overline{x}_i-\overline{x})(\overline{x}_i-\overline{ x })^T$$
行列 $S_w$ と $S_b$ の固有値をそれぞれ分解します:
$$S_w=V_1\Lambda_1 V_1^T,\quad S_b=V_2\Lambda_2 V_2^T$$
このうち、$V_1$ と $V_2$ はそれぞれ固有ベクトル行列、$\Lambda_1$ と $\Lambda_2$ はそれぞれ固有値対角行列です。
最大の $k_1$ 特徴ベクトルを取得します:
$$W_1=[v_{11},v_{12},...,v_{1k_1}]$$
最大の $k_2$ 特徴ベクトルを取得します:
$$W_2=[v_{21},v_{22},...,v_{2k_2}]$$
このうち、$k_1$、$k_2$はそれぞれ次元削減後の次元、$W_1$、$W_2$はそれぞれ固有ベクトル行列です。
各サンプルを変換します:
$$y_{i1}=W_1^Tx_i,\quad y_{i2}=W_2^Tx_i$$
このうち $y_{i1}$ と $y_{i2}$ はそれぞれ次元削減後のサンプルベクトルです。
1.3 実装手順
上記の数式に基づいて、2D-LDA に基づく顔認識アルゴリズムを実装できます。具体的な手順は次のとおりです。
データセットの準備: 顔画像データセットを収集して整理し、各人物の画像を一定の比率に従ってトレーニング セットとテスト セットに分割します。
データ前処理: 認識率を向上させるために、顔検出、顔の位置調整、画像強調などを含む各画像を前処理します。
特徴抽出: 各トレーニング サンプルに対して特徴抽出を実行して、次元を削減したサンプル ベクトル $y_{i1}$ および $y_{i2}$ を取得します。
トレーニング モデル: 次元を削減したサンプル ベクトルをトレーニング用の分類モデルに入力し、分類器を取得します。
テスト モデル: テスト セット内の各サンプルを予測し、予測精度を計算し、認識率曲線を描画します。
パラメータの調整: 認識率曲線に従って、モデルのパラメータを調整して認識率を向上させます。
認識率曲線
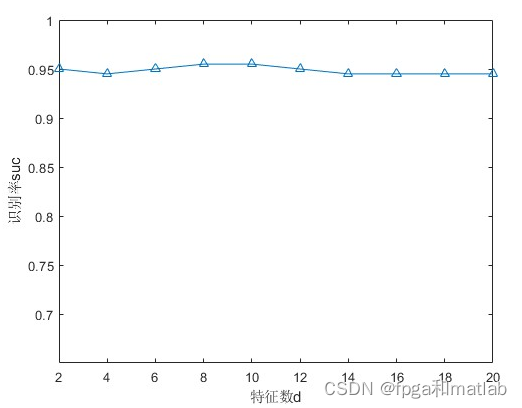
認識率曲線は、顔認識アルゴリズムのパフォーマンスを評価する一般的な方法であり、アルゴリズムの認識効果を直感的に反映できます。2D-LDA に基づく顔認識アルゴリズムでは、さまざまな次元で認識率曲線を描くことでアルゴリズムの性能を評価できます。
認識率曲線を描くための具体的な手順は次のとおりです。
データセットをトレーニングセットとテストセットに分割し、データの 70% をトレーニングに使用し、データの 30% をテストに使用するなど、一定の比率で分割します。
トレーニング セット内の各サンプルに対して特徴抽出が実行され、次元が削減されたサンプル ベクトル $y_{i1}$ および $y_{i2}$ が取得されます。
次元を削減したサンプル ベクトルをトレーニング用の分類モデルに入力して、分類器を取得します。
テスト セット内の各サンプルを予測し、予測精度を計算します。異なる次元 $k_1$ と $k_2$ ごとに、上記の手順を繰り返して、対応する認識率を取得します。
2. コアプログラム
...........................................................................
height = 112;
width = 92;
%%%%%%%%%%%%%%训练样本Xtrain%%%%%%%%%%
for i=1:nclass
for j = 1:neachtrain
Xtrain(:,(i-1)*neachtrain+j) = facedatabase(:,(i-1)*(nsmpaleeachclass)+j*2-1);
end
end
%%%%%%%%%%%%%%测试样本Xtest,一列表示一幅图像%%%%%%%%%%
for i=1:nclass
for j = 1:neachtest
Xtest(:,(i-1)*neachtest+j) = facedatabase(:,(i-1)*(nsmpaleeachclass)+j*2);
end
end
for i=1:neachtrain*nclass
trainSample{i}=reshape(Xtrain(:,i), height, width);
end
%总训练样本数neachtrain*nclass
for i=1:neachtest*nclass
testSample{i}=reshape(Xtest(:,i), height, width);
end
%总测试样本数neachtrain*nclass
[vec, val] = tdfda(trainSample, nclass);%调用tdfda,输入训练样本和类别数,返回降序排列的 特征值和特征向量
for d=2:2:20
for i=1:neachtrain*nclass
newTrainSample{i} = trainSample{i}*vec(:,1:d);
newTestSample{i} = testSample{i}*vec(:,1:d);
newXtrain(i,:) = reshape(newTrainSample{i}, 1, height*d);%每幅图像展开成一行 新的特征表示
newXtest(i,:) = reshape(newTestSample{i}, 1, height*d);
end
%re_im{d/5} = uint8(newTrainSample{1}*vec(:,1:d)');
tic%启动计时器
classification=classif(newXtrain', newXtest');%调用classification,输入训练矩阵和测试矩阵,返回类别
size(classification);
suc(d/2) = success(classification, neachtrain, neachtest);%调用success,返回识别率suc(d/2)
t(d/2)=toc;%关闭计时器
clear newTrainSample newTestSample newXtrain newXtest;
end
%%%%%%%%%%%%%%%%%%%%%%显示%%%%%%%%%%%%%%%%%%%%%
disp('对应不同特征数d的识别率:');
suc
disp('对应不同特征数d的识别耗时:');
t
%%%%%%%%%%%%%%%%%%%%画图%%%%%%%%%%%%%%%%%%%%%%%%
box
axis([2 20 0.65 1.00]);
set(gca,'Xtick',[2:2:20],'ytick',[0.7:0.05:1.00]);
ylabel('识别率suc');
xlabel('特征数d');
hold on;
plot(2:2:20,suc,'-^')
up21483. シミュレーションの結論