目次
序文
数学モデリングの準備をしましょう! まずは相関分析から始めましょう!
1. 基本概念と両者の適用範囲の比較
1. 相関分析とは
相関分析とは、2 つの要素の近さを測定するために、相関関係のある 2 つ以上の 変数要素を分析することを指します。相関分析を実行するには、相関要素間に特定の関連性または確率が存在する必要があります。
2. 相関係数とは何ですか
相関係数は、 2 つの変数間の線形相関の程度を反映する指標です。
- ピアソン相関: 2 つの連続確率変数間の相関係数を測定するために使用されます。
- スピアマン相関係数 (スピアマン相関): 元のデータのランク順序に従って解決されるランク相関係数。ランク変数間のピアソン相関係数とも呼ばれます。
(まだ解明されていないケンダル相関係数もあります)
上記 2 つの係数は、2 つの変数間の変化傾向の方向と程度を表し、値の範囲は [-1, 1] です。1に近い場合は両者に強い正の相関があることを意味し、-1に近い場合は強い負の相関があることを意味し、値が0に近い場合は相関が強いことを意味します。は非常に低いです。
3. 適用範囲の比較
スピアマン相関係数とピアソン相関係数の選択:
1.連続データ、正規分布、線形関係の場合、ピアソン相関係数を使用するのが最も適切です。スピアマン相関係数も使用できますが、効率はピアソンほど高くありません。相関係数。
2. 上記 3 つの条件が満たされる場合にのみピアソン相関係数が使用され、そうでない場合はスピアマン相関係数が使用されます。
3.シーケンスデータ間ではスピアマン相関係数のみが使用され、ピアソン相関係数は使用できません。
注: (1) 順序データとは、観測されたオブジェクトのレベルと順序関係のみを反映するデータを指します。順序スケールの測定によって形成され、カテゴリーとして表現され、分類することができます。品質に属します。データ。
たとえば、成績がランク付けされると、ランクに基づいて計算を行うのは意味がありません。順序データの最も重要な意味は、データ セット内の論理順序を表します。(2) スピアマン相関係数はピアソン相関係数に比べて適用条件が広く、単調関係
(一次関数、指数関数、対数関数など) を満たすデータであれば使用可能です。
2. 相関係数
1. ピアソン相関
2 つの変数が正規連続変数であり、それらの間に線形関係がある場合、ピアソンを使用して相関係数を計算できます。値の範囲は [-1,1] です。次のように計算されます。

正式には確率論で習う相関係数のことです。
可変相関強度:
| 関連性 | 強い相関関係 | 強い相関関係 | 中等度の関連性 | 弱い相関 | 相関が非常に弱い、または相関がない |
| 相関係数の絶対値 | 0.8——1 | 0.6——0.8 | 0.4——0.6 | 0.2——0.4 | 0——0.2 |
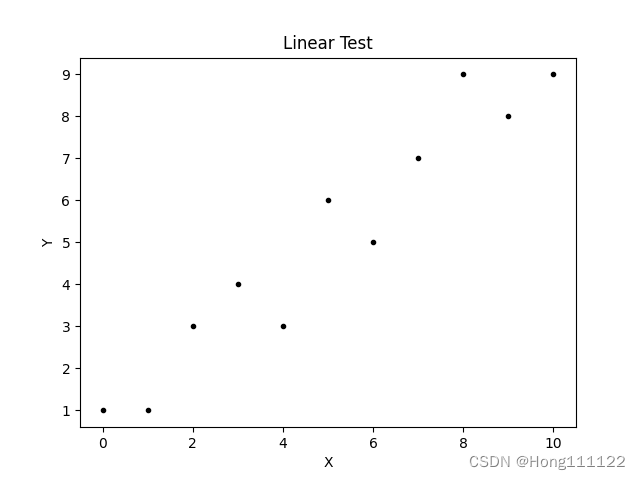
1. 直線性テスト
一般に、散布図は直線性テストに使用されます。
import numpy as np
from matplotlib import pyplot as plt
def linear_test():
#为显示线性关系手动输入的数据
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
y = np.array([1, 1, 3, 4, 3, 6, 5, 7, 9, 8, 9])
fig = plt.figure()
ax1 = fig.add_subplot(1, 1, 1)
ax1.set_title('Linear Test')
ax1.set_xlabel('X')
ax1.set_ylabel('Y')
ax1.scatter(x, y, c='k', marker='.')
plt.savefig('linear_test.png')
linear_test()
2. 正規性テスト
ここではscipyモジュールのkstestメソッドが使用されており、具体的なコードは次のとおりです。
def normal_test():
data = np.array([1, 2, 5, 4, 4, 6, 7, 3, 9, 5, 4, 7, 1, 2, 9])
u = data.mean()
std = data.std()
result = stats.kstest(data, 'norm', (u, std))
print(result)結果: KstestResult(統計 = 0.12726344134326134、pvalue = 0.9427504251048978)
結果は 2 つの値を返します: 統計量 → D 値、pvalue → P 値
H0: サンプルは H1 を満たします: サンプルはp 値 > 0.05
を満たさず、H0 を受け入れ、データは正規分布します。
3. 相関係数を求める
上記の検証がすべて成功した場合、ピアソン相関係数が相関分析に使用されます。
import pandas as pd
# 读取数据
df = pd.read_excel('spearman_data.xlsx')
df = pd.DataFrame(df)
# print(df)
# 生成相关性矩阵
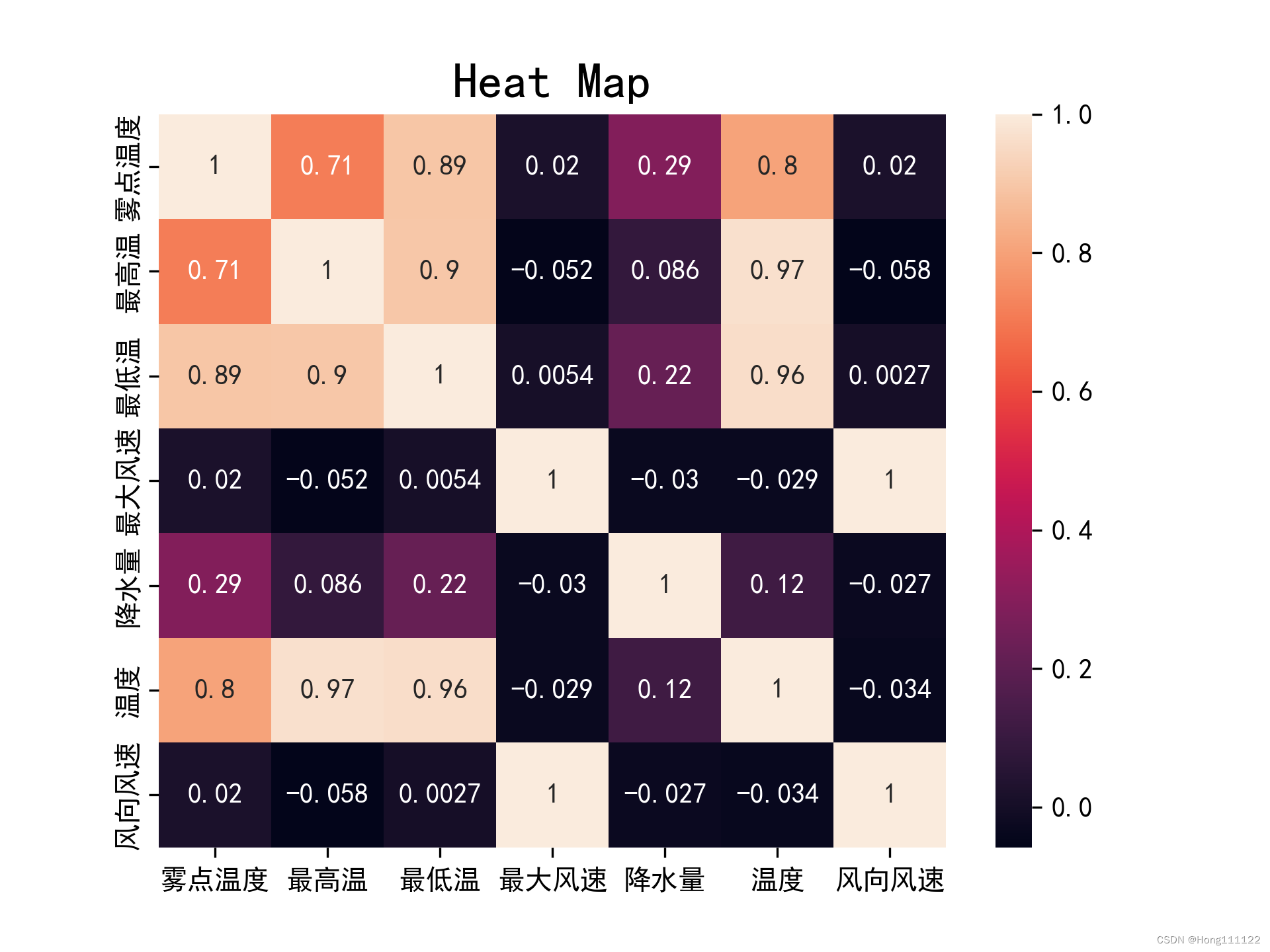
rho = df.corr(method='pearson')
print(rho)
生成された相関係数行列を視覚化します(ヒート マップを生成します)。
def heatmapplot():
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
sns.heatmap(rho, annot=True)
plt.title('Heat Map', fontsize=18)
plt.savefig('heatmap1.png', dpi=300)
2. スピアマン相関
1.順位相関係数
順位相関係数 (順位相関係数) は、順位相関係数とも呼ばれ、2 つの確率変数の変化傾向の方向と強さの関係を反映します。 各要素のサンプル値。順位相関の度合いを反映する統計分析指標であり、順位相関分析の手法としては、スピアマン相関係数やケンドール順位相関係数などがよく使われます。主にデータ分析に使用されます。スピアマン相関係数は、ランク変数間のピアソン相関係数として定義されました。
2. 利用条件
- データが非線形または非正規である
- 少なくとも 1 つのデータ セットは、ランキング、順位などのグレード タイプです。
- データに外れ値または間違った値がありますが、スピアマン相関係数はランキングに基づいて計算されるため、外れ値にはあまり敏感ではなく、実際の値の差は計算結果に直接影響しません。
3. 相関係数を求める
より一般的で簡単な計算式は次のとおりです。
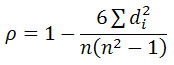
i番目のデータペアのランキング値の差を示します
- n 観測されたサンプルの総数
Python を使用して解決することは上記と同様です (metho = 'spearman')
3. 結果の比較
2 つの相関係数のヒート マップ比較:
ピアソン:
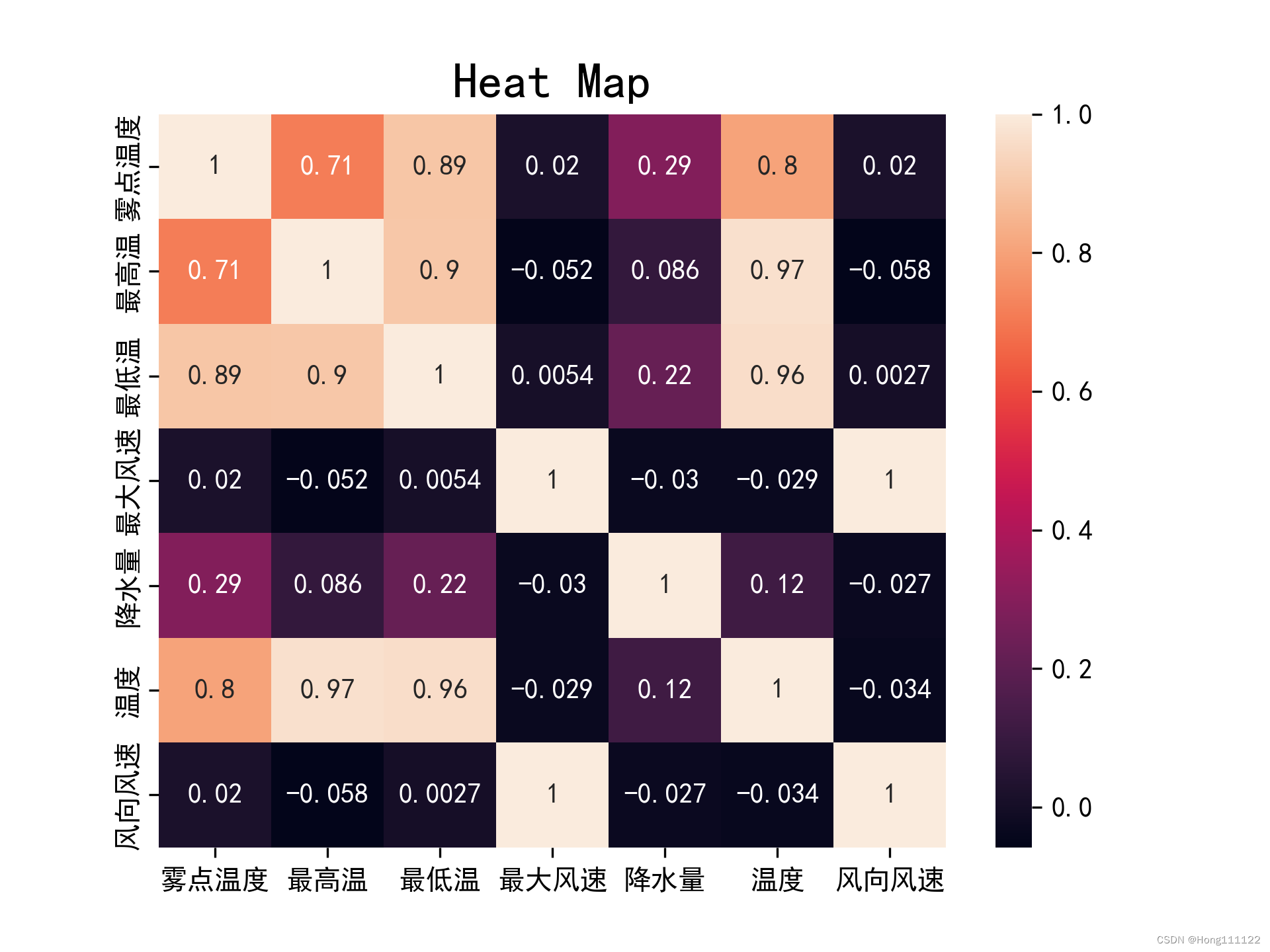
槍兵:
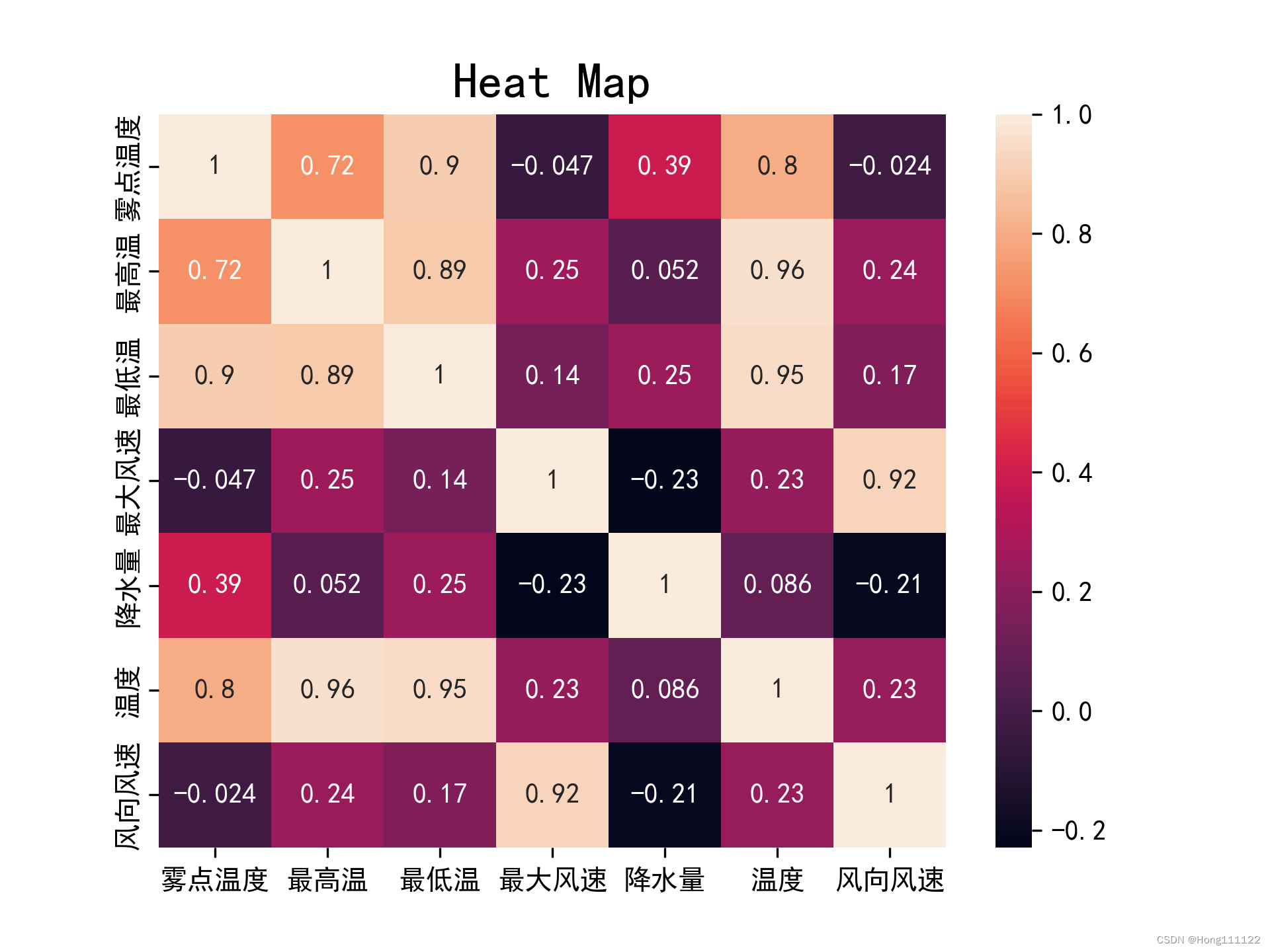
同じグループのデータについて、正規性および線形性テストの条件下では、ピアソンによって得られた結果は、スピアマンによって得られた結果よりも正確かつ厳密であることがわかります。
要約する
勉強ノートを書くのは初めてなので、間違いがあればご指摘いただけると幸いです。
皆さん、親指を立ててください。
それが最初にリリースされ、後で有意性検定が補足されます。