" データ分析では、データの本質的な法則を分析するために、ノイズ干渉を可能な限り排除する必要があります。ノイズ干渉を排除する一般的な方法の 1 つは、直線、放物線、および複数の曲線を使用してデータ フィッティングを行うことです。データモデル。データを当てはめます。」
この記事では主に最小二乗法に基づく直線フィッティングの原理について説明し、これに基づいて最小二乗法とRANSACアルゴリズムを組み合わせた直線フィッティングアルゴリズムを紹介します。
01
—
最小二乗法による直線フィッティングの原理
最小二乗直線フィッティングの中心的な考え方は、すべてのサンプル値とそれに対応するモデル値の間の差の二乗の合計が目的関数として使用され、目的関数の値が最小値に達したときに、の場合、モデルはすべてのサンプルに適合していると見なされます。
微分値が 0 のとき関数は極値を取得することがわかっているので、各パラメーターについて目的関数の偏微分値を求め、その偏微分値を 0 に設定することで各パラメーターを解くことができます。偏微分値が 0 のときに得られるパラメータが最小二乗法の解となります。
次に、最小二乗直線フィッティングの計算式を導いてみましょう。
n 個の点 (x i , y i ) (0≤i<n)があり、それらのフィッティング ラインが Y=ax+b であると仮定すると、各 x iのフィッティング値は Y i = ax i +b となります。したがって、目的関数は次のようになります。
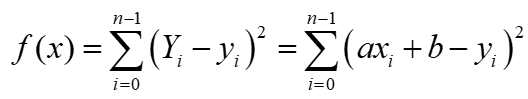
私たちの目標は、f(x) が最小値に達するときの a および b パラメーターを見つけることです。次に、a と b の f(x) の偏導関数をそれぞれ求めます。
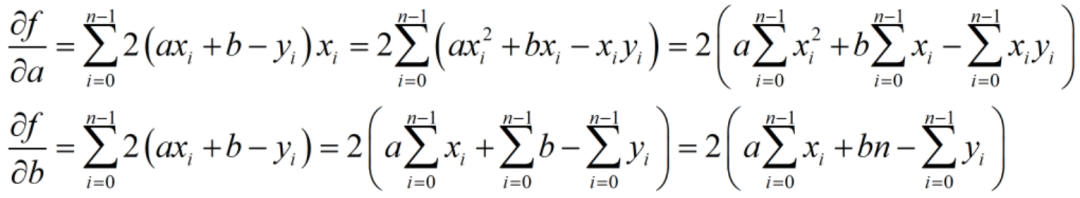
上記の偏導関数を 0 として、2 つの変数の線形方程式系を取得します。
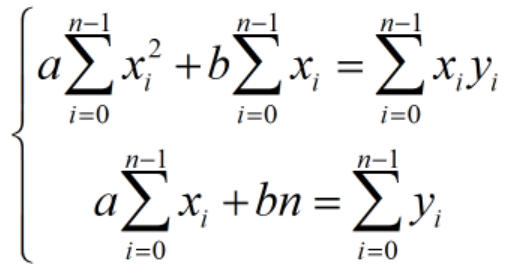
覚えて:
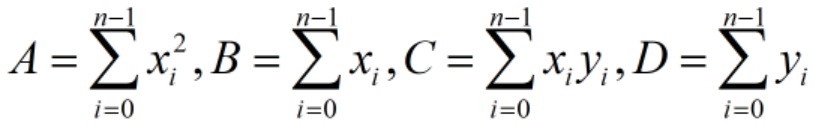
したがって、次のとおりです。
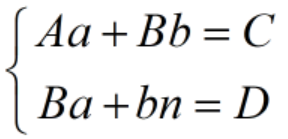
上記の方程式を解いて、必要な直線近似パラメーターである a と b を取得します。
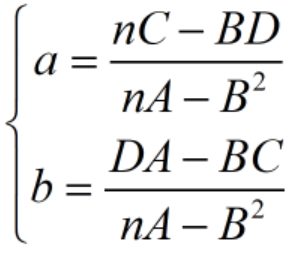
コード:
//y=ax+b
void lineplofit(vector<Point2f>& points_list, int points_num, float* a, float* b)
{
float sum_x2 = 0.0;
float sum_y = 0.0;
float sum_x = 0.0;
float sum_xy = 0.0;
int num = points_num;
int i;
for (i = 0; i < num; ++i)
{
sum_x2 += points_list[i].x * points_list[i].x;
sum_y += points_list[i].y;
sum_x += points_list[i].x;
sum_xy += points_list[i].x * points_list[i].y;
}
float tmp = num * sum_x2 - sum_x * sum_x;
if (abs(tmp) > 0.000001f)
{
*a = (num * sum_xy - sum_x * sum_y) / tmp;
*b = (sum_x2 * sum_y - sum_x * sum_xy) / tmp;
}
else
{
*a = 0;
*b = 0;
}
}02
—
最小二乗法とRANSACアルゴリズムに基づく直線フィッティングの原理
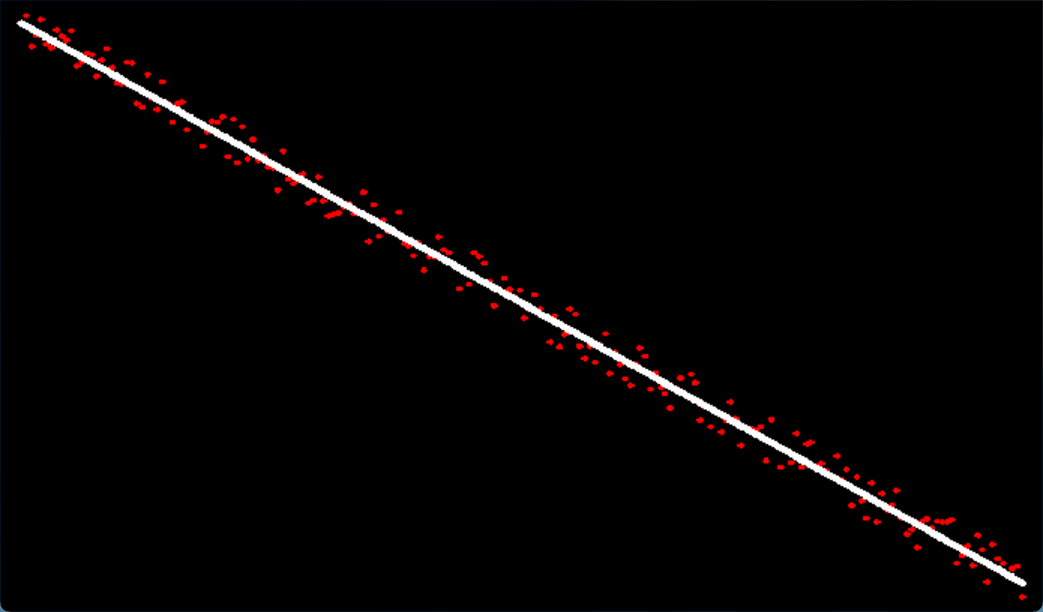
前の章で紹介した最小二乗ライン フィッティング アルゴリズムでは、すべてのサンプル ポイントが計算に関与します。ただし、実際の適用プロセスでは、ノイズの存在により、一部のサンプル ポイントが他のほとんどのポイントから遠く離れていることがよくあります。これらのポイントは、通常、外れ値と呼ばれます。外れ値も直線フィッティング操作に関与する場合、フィッティングは結果は比較的悪くなり、大きな誤差が生じます。以下に示すように:

上記の状況と同様に、直線を当てはめる前に外れ値を除去する必要があります。そうしないと大きな誤差が生じます。RANSAC アルゴリズムは、外れ値サンプル点を除去するための古典的なアルゴリズムです。
RANSAC アルゴリズムを紹介する前に、まず内部点と外部点の意味について説明します。モデルからの距離が設定されたしきい値よりも小さいサンプル点は内部点と呼ばれ、逆も同様で、モデルからの距離が設定されたしきい値よりも小さいサンプル点は内部点と呼ばれます。設定した閾値以上の点を外部点(外側点、つまり上記の外れ値)と呼びます。たとえば、しきい値が 5 に設定されている場合、点から線までの距離が 2 の場合、2 は 5 より小さいため、その点は内側の点になりますが、点から線までの距離が 8 の場合は、重要なのは、外れ値の場合は 8 が 5 よりも大きいためです。
以下に RANSAC のプロセスと原理を説明します。このアルゴリズムは複数のサイクルを繰り返すプロセスです。複数のサイクル中に、最大数のインライアを持つインライアのセットが記録され、最後に最大のインライア数を持つインライア ポイントのセットが記録されます。は、フィッティング モデルを推定するために使用されます。
履歴内のインライアの最大セットが MaxInline で、インライアの数が MaxM であると仮定します。
1. まず、必要に応じてターゲットモデルを設定します直線フィッティングの場合はモデルは y=ax+b、二次曲線フィッティングの場合はモデルは y=ax 2 +bx+ c、はアフィン変換フィッティングです モデルは 2*3 アフィン変換行列です......
2. すべてのサンプル点からモデル パラメーターを計算するために必要なサンプル点の「最小数」をランダムに選択します。「最小数」を n と仮定します。モデルが異なれば n の値も異なります。直線フィッティングの場合、n になります。 = 2. 二次曲線フィッティングの場合は n=3、アフィン変換フィッティングの場合は n=3....
3. 前のステップでランダムに選択した n 個のサンプル点を使用して、モデル パラメーターを計算します。直線フィッティングの場合は a、b を見つけます。二次曲線フィッティングの場合は、a、b、c を見つけます。アフィン変換フィッティングを行ってから、2*3 行列の 6 つのパラメーターを見つけます...
4. 各点について、モデルまでの距離を計算し、その距離が閾値未満であればその点はインライン点であると判断してインラインセット Inline に追加し、それ以外の場合はアウトセットセットに追加します。同時にインラインポイント m と過去最大インラインポイント MaxM を比較し、m>MaxM の場合は MaxM=m および MaxInline=Inline を実行します。
5. MaxM がサンプル総数の特定の割合 (80% など) を超えているかどうか、またはサイクル数が設定された最大サイクル数に達しているかどうかを判断します。MaxM がサンプル総数の特定の割合を超えておらず、サイクル数が最大サイクル数に達していない場合は、上記のステップ 2 に戻って再度開始し、それ以外の場合はサイクルを停止します。
6. MaxM≥n が満たされるかどうかを判断し、満たされる場合は、MaxInline セット内の点を使用して近似モデルを推定します。そうでない場合は、RANSAC アルゴリズムが失敗するとみなします。
上記の手順では、サンプル点からモデルまでの距離を計算する必要がありますが、距離の計算方法はモデルによって異なります。直線モデルの場合は、点 (x 0 ,y 0 )から線 y=ax+b までの垂直距離を直接計算します。
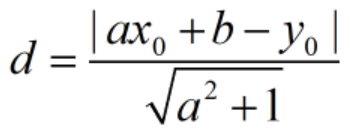
内部点を判定するための距離閾値は、外れ値を除去する効果を高めるために適切な値に設定する必要があるため、異なる閾値を複数回試すことができます。この論文では、最小距離 MinD 間の比例ギャップに従って、 α の設定は 0 ~ 1 の比例値 α 設定に変換され、設定範囲が狭くなるため、適切なしきい値を見つけるのが容易になります。
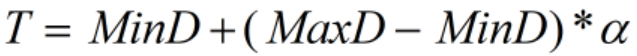
コード:
#define RANSAC_K 2
//获取0~n-1范围内的num个随机数
static void GetRansacRandomNum(int n, int num, int p[])
{
int i = 0, j;
int r = rand() % n;
p[0] = r;
i++;
while (1)
{
int status = 1;
r = rand() % n;
for (j = 0; j < i; j++)
{
if (p[j] == r)
{
status = 0;
break;
}
}
if (status == 1)
{
p[i] = r;
i++;
}
if (i == num)
break;
}
}
void RansacPolyfitLine(vector<Point2f> p, int iter_num, float alpha, float* a, float* b)
{
int r_idx[RANSAC_K];
vector<Point2f> pick_p;
srand((unsigned)time(NULL));
int max_inline_num = 0;
vector<Point2f> inline_p;
vector<Point2f> max_inline_p;
vector<float> d_list;
int n = p.size();
for (int i = 0; i < iter_num; i++) //总共迭代iter_num次
{
GetRansacRandomNum(n, RANSAC_K, r_idx); //生成RANSAC_K个不重复的0~n-1的随机数
pick_p.clear();
//随机选择2个点
for (int j = 0; j < RANSAC_K; j++)
{
pick_p.push_back(p[r_idx[j]]);
}
float aa = 0, bb = 0;
//使用以上随机选择的两个点来计算一条直线
lineplofit(pick_p, RANSAC_K, &aa, &bb);
float mind = 99999999.9f;
float maxd = -99999999.9f;
d_list.clear();
//计算所有点到以上计算直线的距离,并记录最大最小距离
for (int j = 0; j < n; j++)
{
float d = abs(aa * p[j].x - p[j].y + bb) / sqrtf(aa * aa + 1.0f);
d_list.push_back(d);
mind = MIN(mind, d);
maxd = MAX(maxd, d);
}
//根据0~1的α值和最大最小距离计算阈值
float threld = mind + (maxd - mind) * alpha;
inline_p.clear();
for (int j = 0; j < n; j++)
{
//判断如果点距离小于阈值则将该点加入内点集合
if (d_list[j] < threld)
{
inline_p.push_back(p[j]);
}
}
//判断如果以上内点集合的点数大于历史最大内点数,则替换历史最大内点数集合
if (max_inline_num < inline_p.size())
{
max_inline_num = inline_p.size();
max_inline_p.swap(inline_p);
}
}
//判断如果历史最大内点数大于等于2,则使用历史最大内点数集合来计算直线
if (max_inline_num >= RANSAC_K)
{
lineplofit(max_inline_p, max_inline_p.size(), a, b);
}
else //否则RANSAC算法失败
{
*a = 0;
*b = 0;
}
}03
—
直線フィッティング結果
外れ値がほとんどない場合、最小二乗ライン フィッティング アルゴリズムは、最小二乗法と RANSAC を組み合わせたライン フィッティング アルゴリズムに似ています。下の図に示すように、青い線は最小二乗ライン フィッティング アルゴリズムの結果であり、緑色のラインは最小二乗ライン フィッティング アルゴリズムの結果です。直線は最小値の組み合わせです。二次関数と RANSAC の直線フィッティング アルゴリズムの結果、2 つの直線は基本的に一致します。
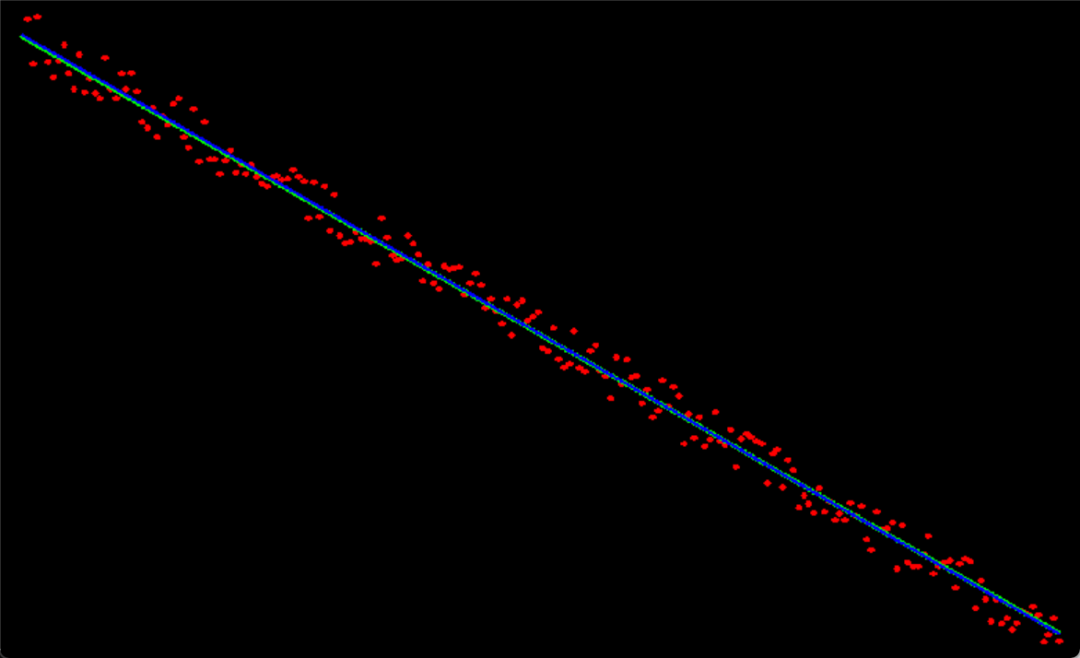
外れ値が多い場合、最小二乗ライン フィッティング アルゴリズムの結果には大きな偏差が生じます (青色の線) が、最小二乗法および RANSAC と組み合わせたライン フィッティング アルゴリズムでは偏差が大きくなりません (緑色の線)。
04
—
余談
個人的には公式アカウントを上手く作って拡張していくのが本当に難しくて、以前疲れていたのと仕事が忙しかったので長い間公式アカウントを更新していませんでした。公式アカウントは長らく更新していませんでしたが、こうして次々と人の役に立てることがとても嬉しくて、更新を続けることにしました。自分自身を要約し、他の人を助ける。
これをご覧になった方、私の記事が役に立つと思われる方は、より多くの困っている人が見てもらえるよう、宣伝・再投稿にご協力ください。あなたの肯定が私が更新を続ける最大の動機です!
QRコードをスキャンしてこのWeChat公式アカウントをフォローしてください。さらにエキサイティングなコンテンツが随時更新されるので、お楽しみに~