記事ディレクトリ
1. ブルームフィルターとは
ブルームフィルター(Bloom Filter)は、1970年にBloomによって提案されました。これは実際には長いバイナリ ベクトルと一連のランダム マッピング関数です。ブルーム フィルターを使用すると、要素がセット内にあるかどうかを取得できます。一般的なアルゴリズムに比べてスペース効率やクエリ時間が大幅に優れていることが利点ですが、一定の割合で誤認識が発生し、削除が困難であることが欠点です。
上記の文はブルームフィルターとは何かをより包括的に説明していますが、それでも理解できない場合は、ブルームフィルターを集合コレクションとして理解すると、addで要素を追加し、containsで要素を含むかどうかを判断できます。 。この記事ではブルーム フィルターと Redis を組み合わせて説明しているため、Redis の Set データ構造の類似性を理解しやすくなっており、Redis のブルーム フィルターで使用される命令は Set コレクション (後で説明します) と非常に似ています。 。
ブルーム フィルターを学ぶ前に、その長所と短所について話しておく必要があります。なぜなら、私たちは良いものだけを望んでいるからです。
-
ブルームフィルターの利点:
- 時間計算量は低く、要素の追加とクエリの時間計算量は O(N) です (N はハッシュ関数の数で、通常は比較的小さいです)。
- 強力な機密性、ブルームフィルターは要素自体を保存しません
- 保存スペースが小さいため、特定の誤った判断が許容される場合、ブルーム フィルターは非常にスペースを節約できます (Set コレクションなどの他のデータ構造と比較して)
-
ブルームフィルターの欠点:
- 一定の誤検知率はありますが、パラメータを調整することで低減できます。
- 要素自体を取得できません
- 要素を削除するのが難しい
2. ブルームフィルターの利用シーン
ブルーム フィルターは、「何かが存在してはいけない、または存在する可能性がある」ことを示します。つまり、ブルーム フィルターがその数値が存在しないと判断した場合、それは存在するはずがなく、ブルーム フィルターがその番号は存在しない可能性があると判断したことになります。 (誤った判断については後述します)、この機能を使用して存在するかどうかを判断すると、多くの興味深いことができます。
解决Redis缓存穿透问题(面试重点)- メール フィルタリング。ブルーム フィルタを使用してメール ブラックリスト フィルタリングを実行します。
- クローラー URL をフィルターすると、クロールされた URL は再度クロールされなくなります。
- ニュースで推奨されたものが推奨されなくなる問題を解決しました (Douyin でスワイプされたものと同様に、下にスライドしてスワイプされなくなります)
- HBase\RocksDB\LevelDB などのデータベースには、データが存在するかどうかを判断するために使用されるブルーム フィルターが組み込まれており、データベースの IO リクエストを削減できます。
3. ブルームフィルターの原理
3.1 データ構造
ブルーム フィルター これは実際には長いバイナリ ベクトルと一連のランダム マッピング関数です。Redis でのブルーム フィルターの実装を例にとると、Redis でのブルーム フィルターの最下層は、大きなビット配列 (バイナリ配列) + 複数の不偏ハッシュ関数です。
大きなビット配列 (バイナリ配列):

複数の不偏ハッシュ関数:
不偏ハッシュ関数は、要素のハッシュ値をより均一に計算でき、計算された要素の添字をビット配列に均等にマッピングできるハッシュ関数です。
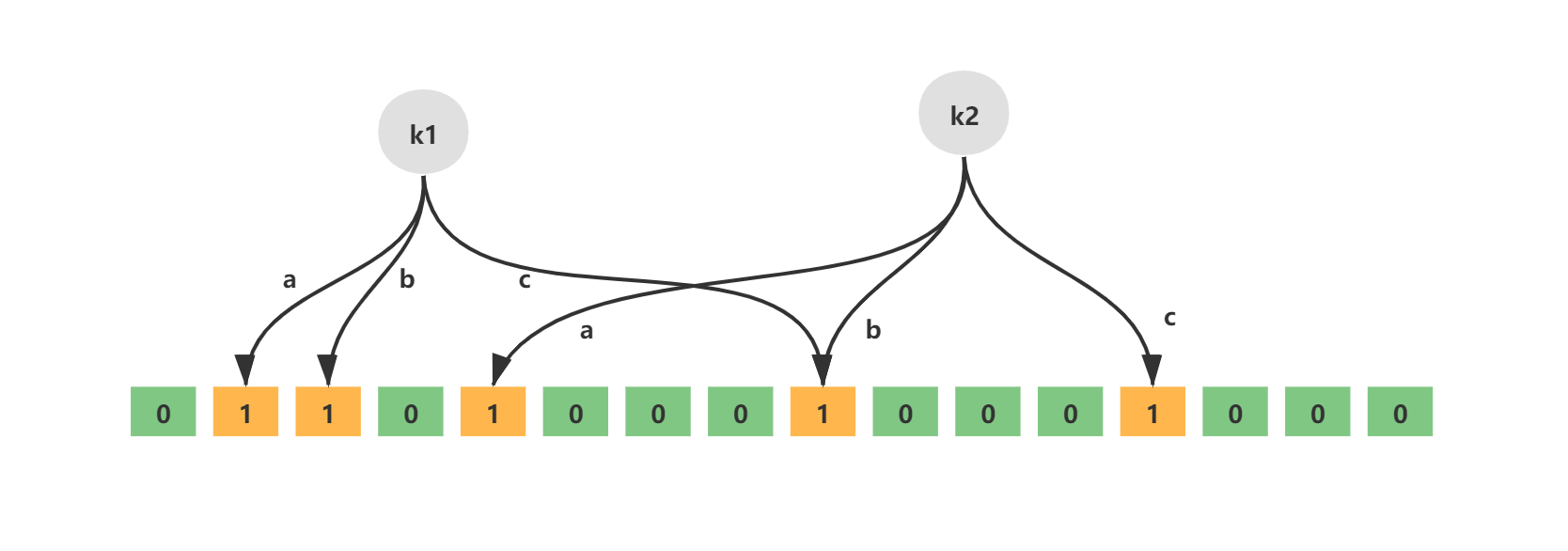
以下は単純なブルーム フィルターの概略図です。k1 と k2 は追加された要素を表し、a、b、c は不偏ハッシュ関数、最下層はバイナリ配列です。
3.2 空間コンピューティング
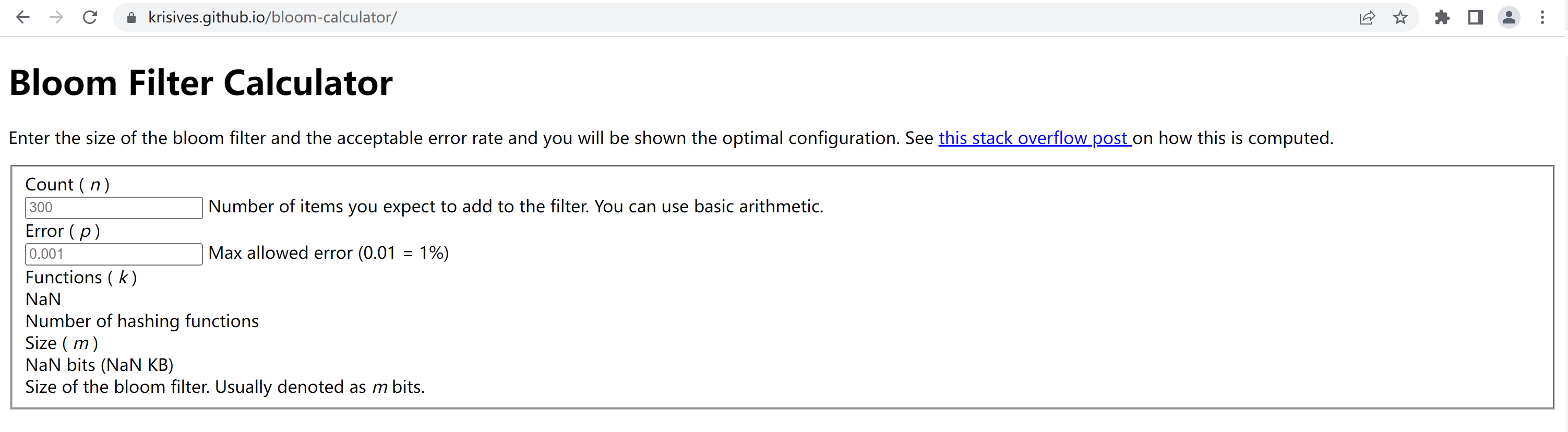
ブルームフィルタに要素を追加する前に、まずブルームフィルタの空間、つまり上記のバイナリ配列を初期化し、不偏ハッシュ関数の数を計算する必要があります。ブルーム フィルターは、追加されることが期待される要素のサイズ n と演算のエラー率 f という 2 つのパラメーターを提供します。ブルーム フィルターには、これら 2 つのパラメーターに基づいてバイナリ配列のサイズ l と不偏ハッシュ関数の数 k を計算するアルゴリズムがあります。
それらの間の関係は比較的単純です。
- エラー率が低いほどビット配列が長くなり、制御が占める面積が大きくなります。
- エラー率が低いほど、より不偏なハッシュ関数が使用され、計算時間が長くなります。
次のアドレスは、無料のオンライン ブルーム フィルターをオンラインで計算するための URL です。
https://krisives.github.io/bloom-calculator/
3.3 要素の追加
ブルーム フィルターに要素を追加するには、追加されたキーを k 不偏ハッシュ関数に従って計算して複数のハッシュ値を取得する必要があります。その後、配列の長さをモジュロして配列添字の位置を取得し、対応する値を取得します。配列の添字の位置が 1 に設定されます
- K 個のハッシュ値は、k 個の不偏ハッシュ関数を計算して取得されます
- モジュール配列の長さを順番に取得して、配列インデックスを取得します。
- 計算された配列インデックスの添字位置データを 1 に変更します
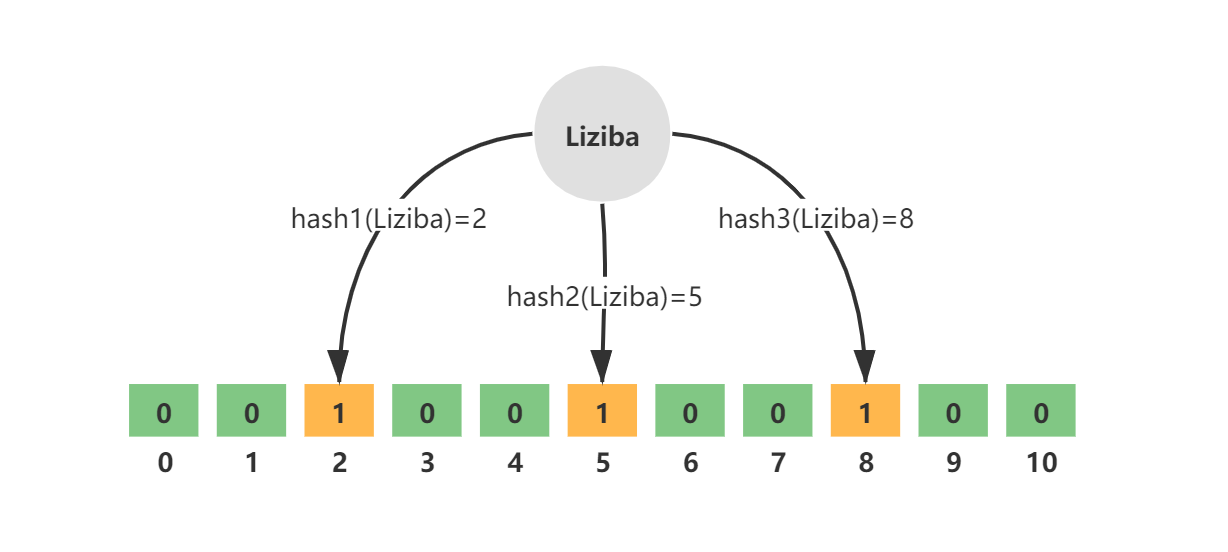
たとえば、key = Liziba、不偏ハッシュ関数の数 k=3、それぞれ hash1、hash2、および hash3 です。3 つのハッシュ関数の計算後、3 つの配列添字値が取得され、それらの値は 1 に変更されます。
図に示すように:
3.4 クエリ要素
ブルーム フィルターの最大の用途は、何かが存在してはならない、または存在する可能性があると判断することです。これは要素をクエリした結果です。要素をクエリするプロセスは次のとおりです。
- K 個のハッシュ値は、k 個の不偏ハッシュ関数を計算して取得されます
- モジュール配列の長さを順番に取得して、配列インデックスを取得します。
- インデックスの値がすべて 1 かどうかを判断し、すべて 1 の場合は存在します (この存在は誤判断の可能性があります)、0 がある場合は存在してはなりません
誤判定については、実は非常にわかりやすいのですが、どんなに優れたハッシュ関数であっても、ハッシュの衝突を完全に避けることはできません。つまり、計算されたハッシュ値が同じ要素が複数存在する可能性があるため、モジュロ配列の長さを取得してから求めます。配列のインデックスも同じです。これが誤った判断の原因です。例えば、Li ZibaとLi Ziqiのハッシュ値を剰余した後に得られる配列のインデックスは1ですが、実際にはここにはLi Zibaしかいないため、この時点でLi Ziqiがここにいるかどうかを判断すると、誤った判断が発生します。が発生します!したがって、ブルームフィルターの最大の欠点は誤判定ですが、要素の有無を判定する原理さえ知っていれば理解するのは簡単です!
3.5 要素の変更
いいえ
3.6 要素の削除
ブルーム フィルターは要素の削除をあまりサポートしていませんが、現在、要素の削除をサポートする特定のブルーム フィルターのバリアントがいくつかあります。削除があまりサポートされていない理由については、実際には非常に簡単に理解できます。ハッシュの競合が存在する必要があり、削除は非常に困難である必要があります。
4. Redis はブルームフィルターを統合します
4.1 バージョン要件
- 推奨バージョンは 6.x、最小バージョンは 4.x です。次のコマンドでバージョンを確認できます。
redis-server -v

- プラグインのインストールについては、インターネットのほとんどが v1.1.1 を推奨しています。この記事が書かれた時点では、v2.2.6 はすでにリリース バージョンでした。ユーザーは自分で機能を選択でき、アップグレードする必要はありません。)
v1.1.1
https://github.com/RedisLabsModules/rebloom/archive/v1.1.1.tar.gz
v2.2.6
https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
4.2 インストールとコンパイル
以下のインストールはすべて指定されたディレクトリで完了し、ソフトウェアのインストールと管理に適切な統合ディレクトリを選択できます。
4.2.1 プラグインの圧縮パッケージをダウンロードする
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.6.tar.gz
4.2.2 減圧
tar -zxvf v2.2.6.tar.gz
4.2.3 プラグインのコンパイル
cd RedisBloom-2.2.6/
make
コンパイルが成功すると、redisbloom.so ファイルが表示され
ます。
4.3 Redis の統合
4.3.1 Redis設定ファイルの変更
- redis.conf 構成ファイルに RedisBloom などの redisbloom.so ファイルのアドレスを追加します。
- クラスターの場合、redisbloom.so ファイルのアドレスを各構成ファイルに追加する必要があります
- 追加後に Redis を再起動する必要がある
loadmodule /usr/local/soft/RedisBloom-2.2.6/redisbloom.so
loadmodule の設定項目は redis.conf 設定ファイルにあらかじめ設定されており、ここで直接変更でき、その後の変更がより便利になります。

- 保存して終了した後は、必ず Redis を再起動してください。
4.3.2 テストが成功したかどうか
Redis 統合ブルーム フィルターの主な手順は次のとおりです。
- bf.add は要素を追加します
- bf.exists は要素が存在するかどうかを判断します
- bf.madd は複数の要素を追加します
- bf.mexists は複数の要素が存在するかどうかを判断します
クライアントを接続してテストします。コマンドが有効であれば、統合が成功したことが証明されます。

以下の状況(エラー)ERR 不明なコマンドが発生した場合は、以下の方法で確認できます。
- Redis インスタンスをシャットダウンし、インスタンスを再起動して、再度テストします。
- 構成ファイルが正しい redisbloom.so ファイル アドレスで構成されているかどうかを確認します
- Redisのバージョンが低すぎるかどうかを確認してください

5. Redis でのブルーム フィルター命令の使用
5.1 bf.add
bf.add は単一の要素を追加することを意味し、追加が成功した場合は 1 を返します。
127.0.0.1:6379> bf.add name liziba
(integer) 1

5.2 BF.マッド
bf.madd は複数の要素を追加することを意味します
127.0.0.1:6379> bf.madd name liziqi lizijiu lizishi
1) (integer) 1
2) (integer) 1
3) (integer) 1
5.3 BF.存在
bf.exists は要素が存在するかどうかを判断し、存在する場合は 1 を返し、存在しない場合は 0 を返します。
127.0.0.1:6379> bf.mexists name liziba
1) (integer) 1

5.4 bf.mexists
bf.mexists は、複数の要素が存在するかどうかを判断し、存在する場合は 1 を返し、存在しない場合は 0 を返すことを意味します。
127.0.0.1:6379> bf.mexists name liziqi lizijiu liziliu
1) (integer) 1
2) (integer) 1
3) (integer) 0

6. Java ローカル メモリはブルーム フィルターを使用します
ブルーム フィルタを使用する方法は数多くあり、多くの大物が独自にブルーム フィルタを作成しています。ここで使用するのは、Google guava パッケージに実装されているブルーム フィルタです。この方法でブルーム フィルタはローカル メモリに実装されます。
6.1 pom 依存関係の導入
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
6.2 テストコードの作成
package com.lizba.bf;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* <p>
* 布隆过滤器测试代码
* </p>
*
*/
public class BloomFilterTest {
/** 预计插入的数据 */
private static Integer expectedInsertions = 10000000;
/** 误判率 */
private static Double fpp = 0.01;
/** 布隆过滤器 */
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), expectedInsertions, fpp);
public static void main(String[] args) {
// 插入 1千万数据
for (int i = 0; i < expectedInsertions; i++) {
bloomFilter.put(i);
}
// 用1千万数据测试误判率
int count = 0;
for (int i = expectedInsertions; i < expectedInsertions *2; i++) {
if (bloomFilter.mightContain(i)) {
count++;
}
}
System.out.println("一共误判了:" + count);
}
}
6.3 テスト結果
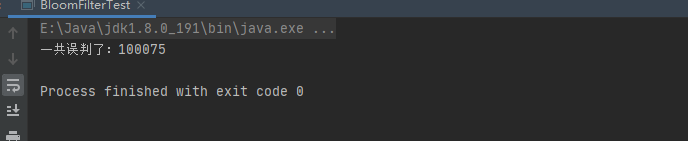
誤判定は 100,075 件あり、これは ExpectedInsertions (1,000 万) の約 0.01 であり、設定した fpp = 0.01 に非常に近い値です。
6.4 パラメータの説明
guava パッケージの BloomFilter ソース コードでは、BloomFilter オブジェクトの構築に 4 つのパラメーターがあります。
- Funnel funnel: Funnels クラスによって指定されるデータ型
- long ExpectedInsertions: 挿入されると予想される値の数
- fpp: エラー率
- BloomFilter.Strategy: ハッシュ アルゴリズム
6.5 fpp&expectedInsertions
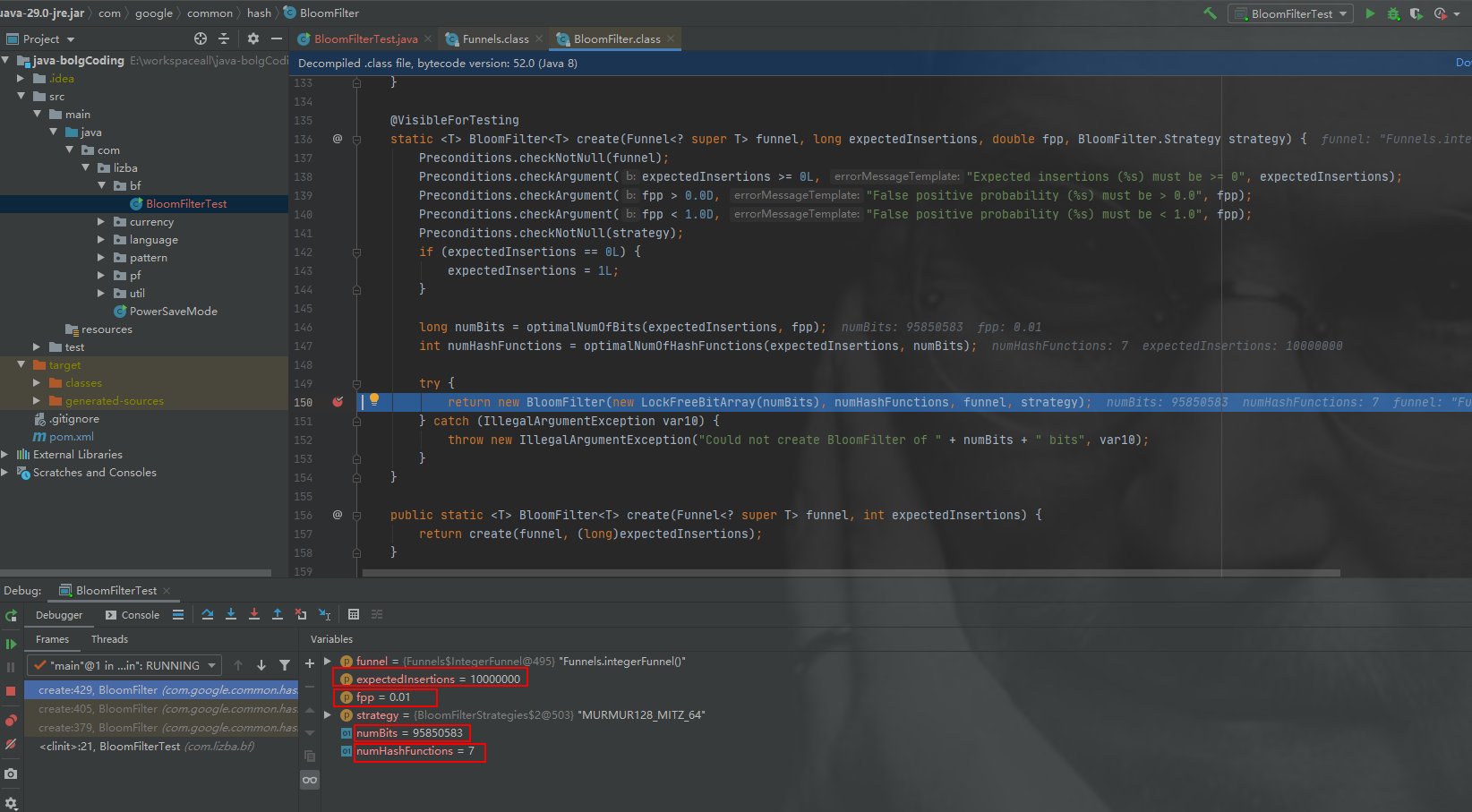
- ExpectedInsertions=10000000&&fpp=0.01 の場合、ビット配列のサイズ numBits=95850583、ハッシュ関数の数 numHashFunctions=7
-
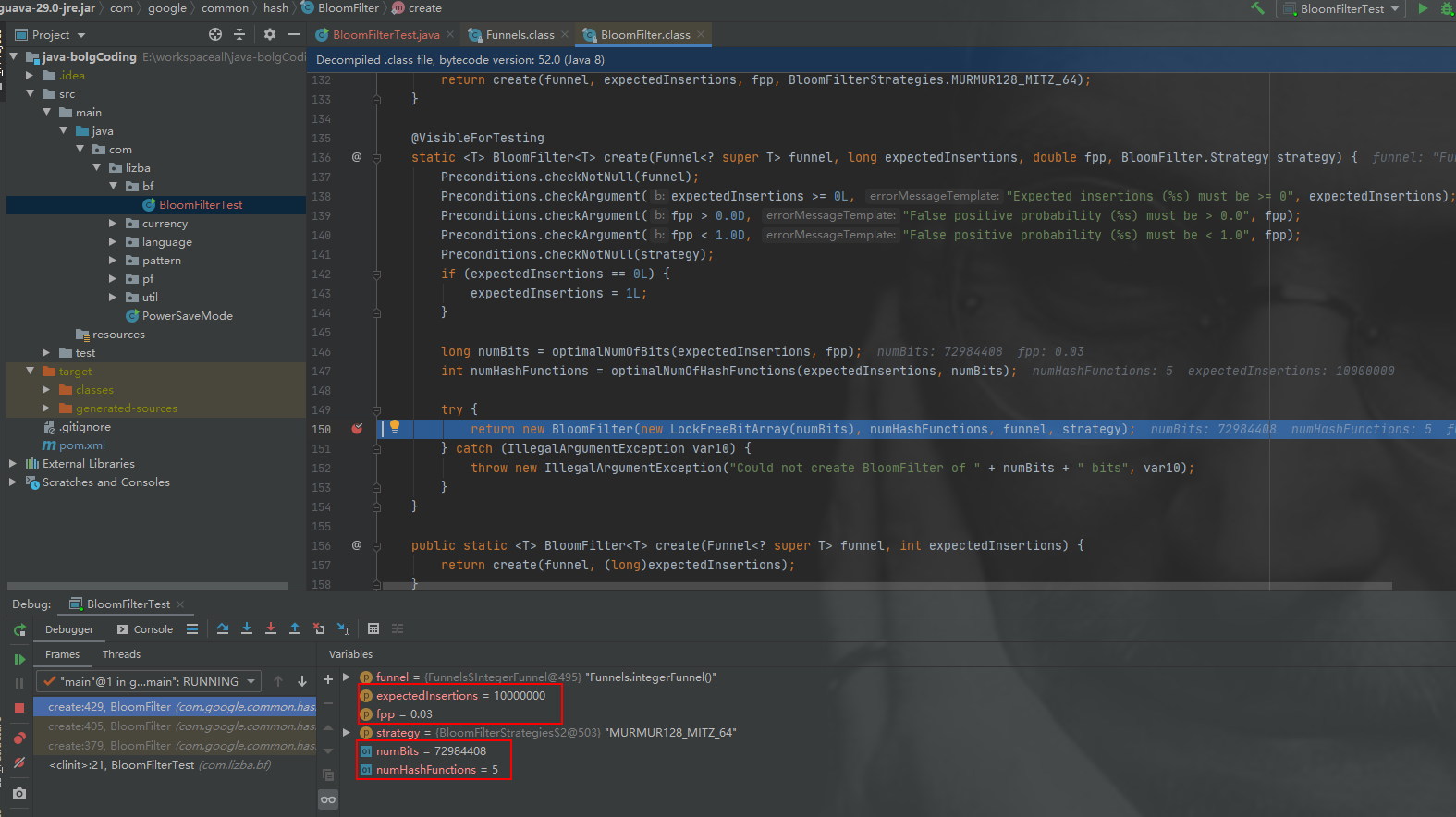
ExpectedInsertions=10000000&&fpp=0.03、ビット配列のサイズ numBits=72984408、ハッシュ関数の数 numHashFunctions=5 の場合
-
ExpectedInsertions=100000&&fpp=0.03、ビット配列のサイズ numBits=729844、ハッシュ関数の数 numHashFunctions=5 の場合

上記の 3 つのテストに基づいて、次の結論を導き出すことができます。
- 期待される挿入値の数が一定の場合、偏差値fppが小さいほどビット配列が大きくなり、ハッシュ関数の数が多くなります。
- 偏差値が変わらない場合、挿入数はより多くなり、ビット配列はより大きくなり、ハッシュ関数は変化しないことが予想されます (この結論は、によって実装されたブルーム フィルターのアルゴリズムとのみ一致していることに注意してください) Guava、すべてのアルゴリズムではない これが結論です。私は多くのテストを行ってきましたが、fpp が同じであれば numHashFunctions が変わらないのは事実です。)
7. Java 統合 Redis はブルーム フィルターを使用します
Redis はキャッシュの内訳についてよく質問されます。より良い解決策はブルーム フィルターを使用することであり、空のオブジェクトを使用して問題を解決することもありますが、最良の方法は間違いなくブルーム フィルターです。ブルーム フィルターを使用すると、要素が存在するかどうかを判断し、クエリを回避できます。キャッシュやデータベースに存在しないデータにアクセスすることもあります。次のコードでは、bloomFilter.contains(xxx) を渡すだけで済みますが、ここで示しているのは依然として誤検知率です。
7.1 pom 依存関係の導入
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.0</version>
</dependency>
7.2 テストコードの作成
package com.lizba.bf;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
/**
* <p>
* Java集成Redis使用布隆过滤器防止缓存穿透方案
* </p>
*
*/
public class RedisBloomFilterTest {
/** 预计插入的数据 */
private static Integer expectedInsertions = 10000;
/** 误判率 */
private static Double fpp = 0.01;
public static void main(String[] args) {
// Redis连接配置,无密码
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.211.108:6379");
// config.useSingleServer().setPassword("123456");
// 初始化布隆过滤器
RedissonClient client = Redisson.create(config);
RBloomFilter<Object> bloomFilter = client.getBloomFilter("user");
bloomFilter.tryInit(expectedInsertions, fpp);
// 布隆过滤器增加元素
for (Integer i = 0; i < expectedInsertions; i++) {
bloomFilter.add(i);
}
// 统计元素
int count = 0;
for (int i = expectedInsertions; i < expectedInsertions*2; i++) {
if (bloomFilter.contains(i)) {
count++;
}
}
System.out.println("误判次数" + count);
}
}
7.3 テスト結果
