実際の水環境の分析では、分析や判断を容易にするために、サンプリングデータを視覚化する必要がある場合がよくあります。
chatgpt を使用すると、このタスクをより迅速かつ適切に完了することができます。
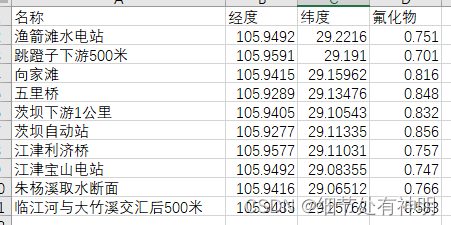
監視データは次のとおりです。
chatgpt にデータを直接送信する
要件を提示します。詳細なほど良いです。

彼は答えて、結果を返します。
import pandas as pd
import folium
from folium.plugins import HeatMap
# 创建坐标轴数据表格
data = {"Name": ["YuJianTan", "TiaoDengZi", "XiangJiaTan", "WuLiQiao", "CiBa", "CiBaAuto", "LiJiQiao", "BaoShan", "ZhuYangXi", "LinJiangHe"],
"Lat": [29.22159555, 29.19100425, 29.15961747, 29.13475581, 29.10543124, 29.1133509, 29.11030903, 29.08354826, 29.06511879, 29.25768],
"Lon": [105.9492021, 105.9590533, 105.9415321, 105.928865, 105.940524, 105.9277196, 105.9577255, 105.949189, 105.9416183, 105.94348],
"Fluoride": [0.751, 0.701, 0.816, 0.848, 0.832, 0.856, 0.757, 0.747, 0.766, 0.583]}
df = pd.DataFrame(data)
# 绘制热力图
m = folium.Map(location=[df["Lat"].mean(), df["Lon"].mean()], zoom_start=13)
heat_data = [[row["Lat"], row["Lon"], row["Fluoride"]] for index, row in df.iterrows()]
HeatMap(heat_data).add_to(m)
# 绘制平滑曲线
locs = df[["Lat", "Lon"]].values.tolist()
fluorides = df["Fluoride"].values.tolist()
from scipy.interpolate import interp1d
import numpy as np
x_min = min(df["Lat"].min(), df["Lon"].min())
x_max = max(df["Lat"].max(), df["Lon"].max())
f = interp1d(np.linspace(x_min, x_max, len(fluorides)), fluorides, kind="cubic")
xs = np.linspace(x_min, x_max, 100)
ys = f(xs)
coords = [[y, x] for y, x in zip(xs, ys)]
folium.PolyLine(coords, color="blue", weight=4).add_to(m)
m
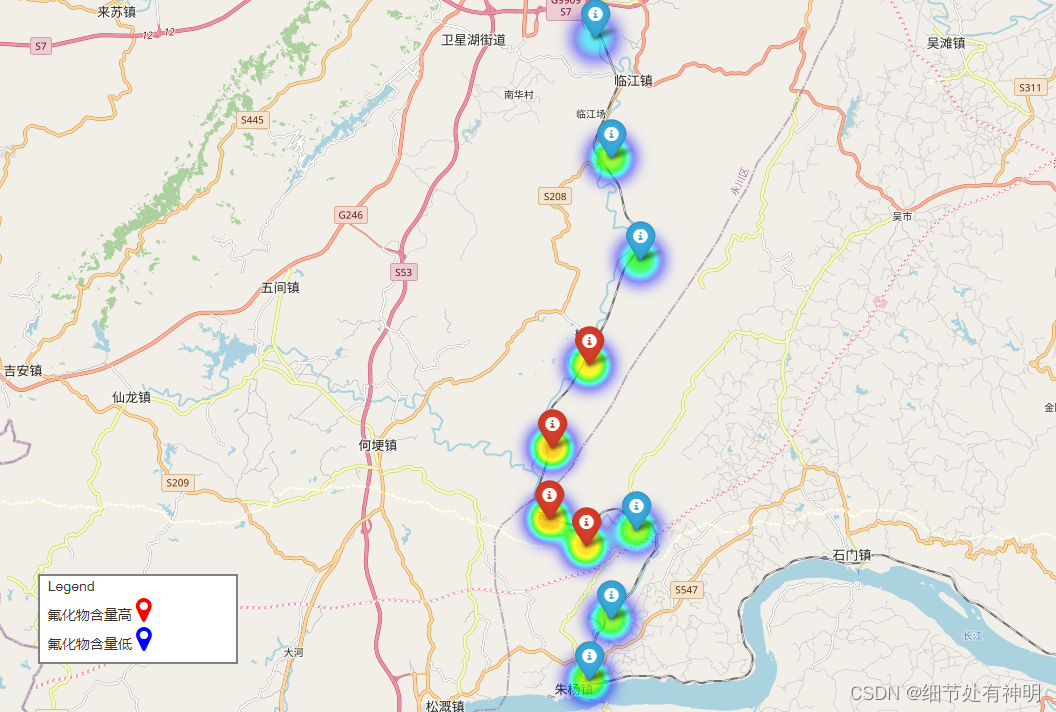
結果は完璧ではありませんが、改良を続けることができます。全体的なエクスペリエンスは非常にスムーズで、多くの時間を節約できます。
あとでさらにまとめることで、作業効率が大幅にアップします。