mysql-client で次のヘルプ コマンドを実行すると、さらにヘルプが表示されます。
help create table1 基本概念
Doris では、データはテーブルの形式で論理的に記述されます。
1.1 行と列
テーブルには、行 (Row) と列 (Column) が含まれます。行は、ユーザー データの行です。列は、データ行のさまざまなフィールドを説明するために使用されます。
列は、キーと値の 2 つのカテゴリに分けることができます。ビジネスの観点からは、キーと値はそれぞれディメンション列とインジケーター列に対応できます。集約モデルの観点から、同じキー列を持つ行は 1 つの行に集約されます。Value列の集計方法は、テーブル作成時にユーザーが指定します。その他の集約モデルの概要については、Doris データ モデルを参照してください:データ モデル、ロールアップ、プレフィックス インデックス · apache/doris Wiki · GitHub
1.2 タブレットとパーティション
Doris のストレージ エンジンでは、ユーザー データは複数のデータ フラグメント (データ バケットとも呼ばれるタブレット) に水平方向に分割されます。各タブレットには、複数行のデータが含まれています。各タブレットのデータ間に交差はなく、物理的に独立して保存されます。
複数のタブレットは、論理的に異なるパーティション (Partition) に属します。タブレットは 1 つのパーティションのみに属します。また、パーティションには複数のタブレットが含まれます。タブレットは物理的に独立して収納されているため、パーティションも物理的に独立していると見なすことができます。タブレットは、データの移動や複製などの操作のための最小の物理ストレージ ユニットです。
複数のパーティションがテーブルを形成します。パーティションは、最小の論理的な管理単位と見なすことができます。データのインポートと削除は、1 つのパーティションに対してのみ行うことも、1 つのパーティションに対してのみ行うこともできます。
2 建表(Create Table)
CREATE TABLE コマンドを使用して、テーブル (テーブル) を作成します。より詳細なパラメーターを表示できます。
HELP CREATE TABLE;最初のスイッチ データベース:
USE test_db;Doris のテーブル作成は同期コマンドであり、コマンドは正常に返されます。これは、テーブルが正常に構築されたことを意味します。
HELP CREATE TABLE を渡すことができます。詳細なヘルプを表示します。
例:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...]
[, index_definition1[, ndex_definition12,]])
[ENGINE = [olap|mysql|broker|hive]]
[key_desc]
[COMMENT "table comment"];
[partition_desc]
[distribution_desc]
[rollup_index]
[PROPERTIES ("key"="value", ...)]
[BROKER PROPERTIES ("key"="value", ...)]2.1 フィールドタイプ
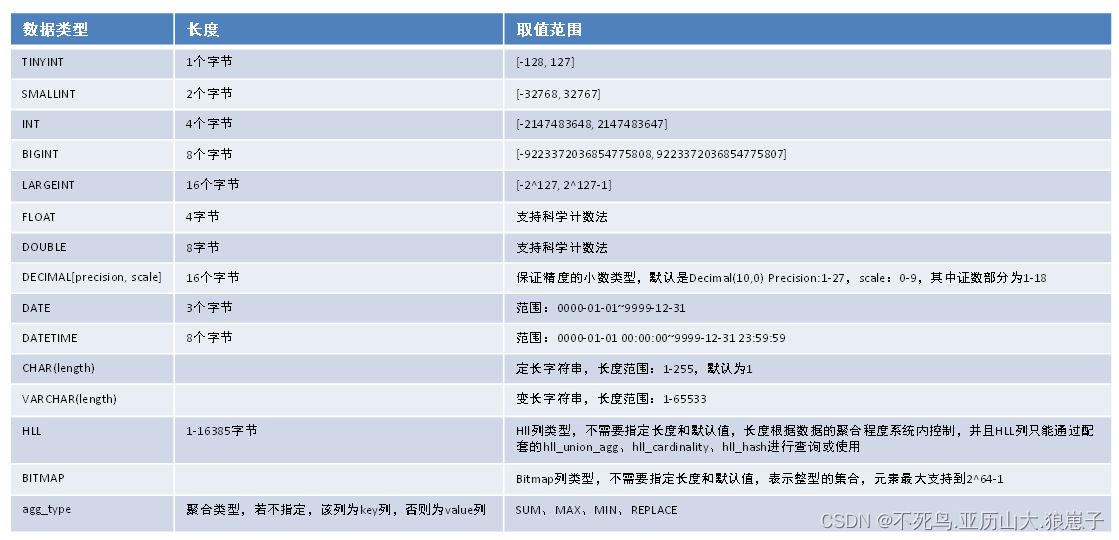
- TINYINT データ型
長さ: 1 バイトの長さの符号付き整数。
範囲: [-128, 127]
変換: Doris は、型をより大きな整数型または浮動小数点型に自動的に変換できます。CAST() 関数を使用して CHAR に変換します。
例:
select cast(100 as char); - SMALLINT データ型
長さ: 2 バイトの長さの符号付き整数。
範囲: [-32768, 32767]
変換: Doris は、型をより大きな整数型または浮動小数点型に自動的に変換できます。CAST() 関数を使用して、TINYINT、CHAR に変換します。
例:
select cast(10000 as char);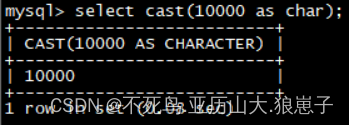
select cast(10000 as tinyint);
- INT データ型
長さ: 4 バイトの長さの符号付き整数。
範囲: [-2147483648, 2147483647]
変換: Doris は、型をより大きな整数型または浮動小数点型に自動的に変換できます。CAST() 関数を使用して、TINYINT、SMALLINT、CHAR に変換します。
例:
select cast(111111111 as char);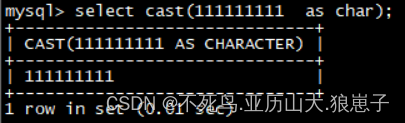
- BIGINT データ型
長さ: 8 バイトの長さの符号付き整数。
範囲: [-9223372036854775808, 9223372036854775807]
変換: Doris は、型をより大きな整数型または浮動小数点型に自動的に変換できます。CAST() 関数を使用して、TINYINT、SMALLINT、INT、CHAR に変換します。
例:
select cast(9223372036854775807 as char);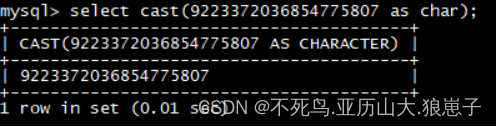
- LARGEINT データ型
長さ: 16 バイトの長さの符号付き整数。
範囲: [-2^127, 2^127-1]
変換: Doris は、この型を浮動小数点型に自動的に変換できます。CAST() 関数を使用して、TINYINT、SMALLINT、INT、BIGINT、CHAR に変換します。
例:
select cast(922337203685477582342342 as double);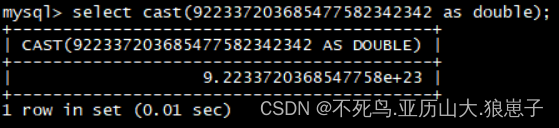
- FLOAT データ型
長さ: 4 バイトの長さの浮動小数点型。
範囲: -3.40E+38 ~ +3.40E+38.
変換: Doris は FLOAT 型を DOUBLE 型に自動的に変換します。ユーザーは CAST() を使用して、TINYINT、SMALLINT、INT、BIGINT、STRING、TIMESTAMP に変換できます。
- DOUBLE データ型
長さ: 長さが 8 バイトの浮動小数点型。
範囲: -1.79E+308 ~ +1.79E+308.
変換: Doris は DOUBLE 型を他の型に自動的に変換しません。ユーザーは CAST() を使用して、TINYINT、SMALLINT、INT、BIGINT、STRING、TIMESTAMP に変換できます。ユーザーは、指数表記を使用して DOUBLE 型を記述したり、STRING 変換によって取得したりできます。
- DECIMAL データ型
10進数[M, D]
精度が保証された 10 進数型。M は有効数字の合計数を表し、D は小数点以下の最大桁数を表します。M の範囲は [1,27] で、D の範囲は [1,9] です. さらに、M は D の値以上でなければなりません. デフォルト値は 10 進数 [10,0] です。
精度: 1 ~ 27
スケール: 0 ~ 9
lDATE データ型
範囲: [0000-01-01~9999-12-31]。デフォルトの印刷形式は「YYYY-MM-DD」です。
- 日時データ型
範囲: [0000-01-01 00:00:00~9999-12-31 23:59:59]。デフォルトの印刷形式は「YYYY-MM-DD HH:MM:SS」です。
- CHAR データ型
範囲: char[(長さ)]、固定長の文字列、長さの範囲は 1 から 255 で、デフォルトは 1 です。
変換: ユーザーは、CAST 関数を使用して、CHAR 型を TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DOUBLE、DATE、または DATETIME に変換できます。
例:
select cast(1234 as bigint);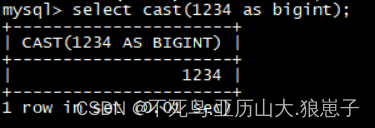
- VARCHAR データ型
範囲: char(長さ)、可変長文字列、長さの範囲は 1 ~ 65535。
変換: ユーザーは、CAST 関数を使用して、CHAR 型を TINYINT、SMALLINT、INT、BIGINT、LARGEINT、DOUBLE、DATE、または DATETIME に変換できます。
例:
select cast('2011-01-01' as date);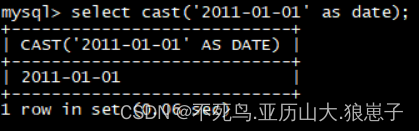
select cast('2011-01-01' as datetime);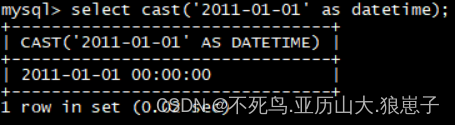
select cast(3423 as bigint);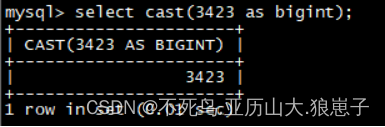
- HLL データ型
範囲: 文字 (長さ)、長さの範囲は 1 ~ 16385。ユーザーは長さとデフォルト値を指定する必要はありません。長さはデータの集約度に応じてシステム内で制御されます。HLL 列は、一致する hll_union_agg、hll_cardinality、hll_hash を介してのみ照会または使用できます。
3 データ分割
Doris は、単一パーティションと複合パーティションという 2 つのテーブル構築方法をサポートしています。
シングル パーティションとは、データがパーティション分割されていないことを意味し、データは HASH、つまりバケットによってのみ分散されます。
複合パーティション:
- 最初のレベルはパーティション、パーティションと呼ばれます。ユーザーは、ディメンション列をパーティション列として指定し (現在、整数型と時間型の列のみがサポートされています)、各パーティションの値の範囲を指定できます。
- 2 番目のレベルは、分散、つまりバケット化と呼ばれます。ユーザーは、1 つ以上のディメンション列とバケット数を指定して、データに対して HASH 分散を実行できます。
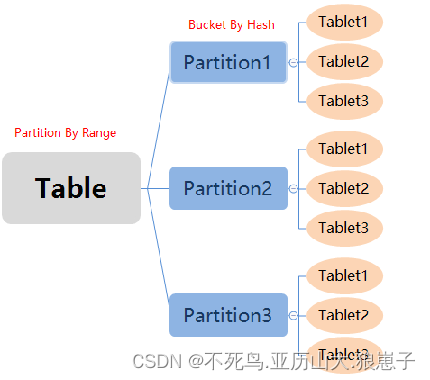
Doris のストレージ エンジン ルール:
- ユーザーデータは、まずいくつかのパーティションに分割されます (Partition) 通常、分割ルールは、時間など、ユーザーが指定したパーティション列に従って範囲を分割します。
- 各パーティションでは、データはハッシュ方式に従ってさらにバケットに分割されます.バケット化ルールは、ユーザーが指定したバケット化列の値を見つけ、バケット化する前にハッシュを実行することです. 各バケットはデータ シャード (タブレット) であり、データ分割の最小の論理単位でもあります。
- パーティションは、最小の論理的な管理単位と見なすことができます。データのインポートと削除は、1 つのパーティションに対してのみ行うことも、1 つのパーティションに対してのみ行うこともできます。
- タブレット ダイレクト データには交差がなく、独立して格納されます。タブレットは、データの移動や複製などの操作を行うための最小の物理ストレージ ユニットでもあります。
3.1 単一パーティションでテーブルを作成する
table1 という名前の論理テーブルを作成します。バケット リストは siteid で、バケットの数は 10 です。
このテーブルのスキーマは次のとおりです。
- siteid: タイプは INT (4 バイト)、デフォルト値は 10 です
- citycode: タイプは SMALLINT (2 バイト)
- ユーザー名: タイプは VARCHAR、最大長は 32、デフォルト値は空の文字列です
- pv: タイプは BIGINT (8 バイト) で、デフォルト値は 0 です; これはインジケーター列であり、Doris はインジケーター列に対して内部的に集計操作を実行し、この列の集計方法は合計 (SUM) です。
CREATE TABLE table1
(
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, citycode, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "1");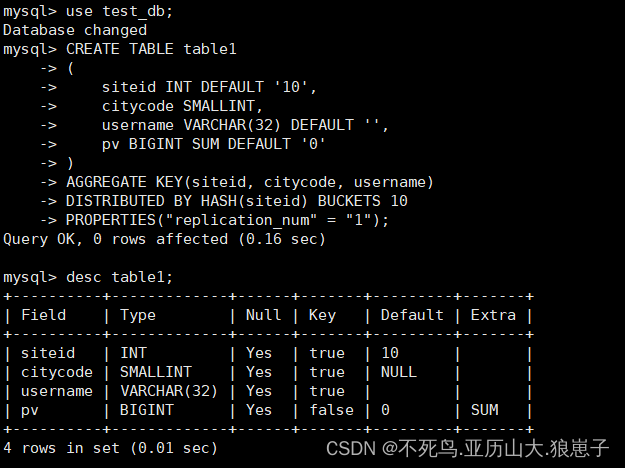
さまざまなデータ インポート要件に適応するために、Doris システムには 6 つの異なるインポート方法が用意されています。各インポート方法は、さまざまなデータ ソースをサポートし、さまざまな使用方法 (非同期および同期) を備えています。
すべてのインポート方法が csv データ形式をサポートしています。その中で、Broker ロードは parquet および orc データ形式もサポートしています。
- ストリーム負荷
ユーザーは HTTP プロトコルを介してリクエストを送信し、生データを使用してインポートを作成します。主に、ローカル ファイルまたはデータ ストリームから Doris にデータをすばやくインポートするために使用されます。import コマンドは、インポート結果を同期的に返します。
- 入れる
MySQL の Insert ステートメントと同様に、Doris は INSERT INTO tbl SELECT ...; Doris テーブルからデータを読み取り、それを別のテーブルにインポートする方法を提供します。または、INSERT INTO tbl VALUES(...); を介して単一のデータを挿入します。
- ブローカー負荷
Broker プロセスを介して外部データ ソース (HDFS など) にアクセスして読み取り、それらを Doris にインポートします。ユーザーが Mysql プロトコルを介してインポート ジョブを送信すると、非同期で実行されます。SHOW LOAD コマンドでインポート結果を表示します。
- マルチロード
ユーザーは、HTTP プロトコルを介して複数のインポート ジョブを送信します。マルチ ロードは、複数のインポート ジョブのアトミックな効果を保証できます。
- 日常の負荷
ユーザーは、MySQL プロトコルを介して定期的なインポート ジョブを送信し、常駐スレッドを生成し、データ ソース (Kafka など) からデータを継続的に読み取り、それを Doris にインポートします。
- S3 プロトコルを介して直接インポートする
ユーザーは S3 プロトコルを介してデータを直接インポートします。使用方法は Broker Load と同様です。
データの挿入:
ストリームロード方法:
curl --location-trusted -u root:123456 -H "label:table1_20210210" -H "column_separator:," -T table1_data http://node01:8030/api/test_db/table1/_stream_load 例:
table1_data を table1 にインポート: vim table1_data
10,101,jim,2
11,101,grace,2
12,102,tom,2
13,102,bush,3
14,103,helen,3curl --location-trusted -u root:123456 -H "label:table1_20210210" -H "column_separator:," -T table1_data http://192.168.222.143:8030/api/test_db/table1/_stream_load
select * from table1;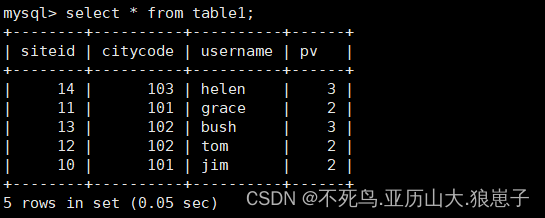
挿入方法:
ステートメントを直接実行する
insert into table1 values(1,1,'user1',10);
insert into table1 values(1,1,'user1',10);
insert into table1 values(1,2,'user1',10);

注: siteid=1 citycode=1 username=user1 のデータ集計は 20 であることがわかります。
3.2 複合パーティションテーブルの作成
table2 という名前の論理テーブルを作成します
このテーブルのスキーマは次のとおりです。
- event_day: タイプは DATE、デフォルト値なし
- siteid: タイプは INT (4 バイト)、デフォルト値は 10 です
- citycode: タイプは SMALLINT (2 バイト)
- ユーザー名: タイプは VARCHAR、最大長は 32、デフォルト値は空の文字列です
- pv: タイプは BIGINT (8 バイト) で、デフォルト値は 0 です; これはインジケーター列であり、Doris はインジケーター列に対して内部的に集計操作を実行し、この列の集計方法は合計 (SUM) です。
CREATE TABLE table2
(
event_day DATE,
siteid INT DEFAULT '10',
citycode SMALLINT,
username VARCHAR(32) DEFAULT '',
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(event_day, siteid, citycode, username)
PARTITION BY RANGE(event_day)
(
PARTITION p202006 VALUES LESS THAN ('2020-07-01'),
PARTITION p202007 VALUES LESS THAN ('2020-08-01'),
PARTITION p202008 VALUES LESS THAN ('2020-09-01')
)
DISTRIBUTED BY HASH(siteid) BUCKETS 10
PROPERTIES("replication_num" = "3");
event_day 列をパーティション列として使用して、p202106、p202107、p202108 の 3 つのパーティションを作成します。各パーティションはハッシュ バケットにサイト ID を使用し、バケットの数は 10 です。
- p202106: 範囲は [最小、2021-07-01)
- p202107: 範囲は [2021-07-01, 2021-08-01) です
- p202108: 範囲は [2021-08-01, 2020-09-01)
間隔は左が閉じていて右が開いていることに注意してください
データのインポート:
table2_data を table2 にインポート: vim table2_data
2021-06-03|9|1|jack|3
2021-06-10|10|2|rose|2
2021-07-03|11|1|jim|2
2021-07-05|12|1|grace|2
2021-07-12|13|2|tom|2
2021-08-15|14|3|bush|3
2021-08-12|15|3|helen|3
curl --location-trusted -u root:123456 -H "label:table2_20200707" -H "column_separator:|" -T table2_data http://192.168.222.143:8030/api/test_db/table2/_stream_load
次のシナリオでは、複合パーティションをお勧めします
- 順序付けされた値を持つ時間ディメンションまたは同様のディメンションがあり、そのようなディメンション列はパーティション列として使用できます。パーティションの粒度は、インポート頻度、パーティションのデータ量などに基づいて評価できます。
- 履歴データの削除要件: 履歴データを削除する必要がある場合 (たとえば、過去 N 日間のデータのみを保持するなど)。複合パーティションでは、履歴パーティションを削除することでこれを実現できます。指定したパーティションで DELETE ステートメントを送信して、データを削除することもできます。
- データの偏りの問題を解決します。各パーティションは個別にバケット数を指定できます。たとえば、日ごとにパーティション分割する場合、データ量が毎日大きく変動する場合、パーティション内のバケット数を指定することで、データを異なるパーティションに合理的に分割できます。バケット列の識別。
4 パーティションとバケットの数とデータ量に関する提案
- テーブル内のタブレットの総数は (パーティション番号 * バケット番号) と等しくなります。
- テーブル内のタブレットの数は、容量の拡張に関係なく、クラスター全体のディスクの数よりもわずかに多くすることをお勧めします。
- 理論上、タブレット1台のデータ量に上限・下限はありませんが、1G~10Gの範囲内であることが推奨されます。1 つのタブレットのデータ量が小さすぎると、データの集約効果が低くなり、メタデータ管理の負担が大きくなります。データ量が多すぎると、移行とコピーの完了につながりません。また、スキーマの変更またはロールアップ操作の失敗を再試行するコストが増加します (これらの操作の失敗の再試行の粒度は、タブレット)。
- タブレットのデータ量の原則と量の原則が矛盾する場合は、データ量の原則を優先することをお勧めします。
- テーブルを作成するとき、各パーティションのバケット数は一律に指定されます。ただし、動的にパーティションを追加する場合 (ADD PARTITION)、新しいパーティションのバケット数を個別に指定できます。この機能を使用すると、データの縮小または拡大に簡単に対処できます。
- パーティション内のバケット数は、一度指定すると変更できません。そのため、Bucket の数を決定する際には、クラスタの拡張を事前に考慮する必要があります。たとえば、現在ホストが 3 つしかなく、各ホストに 1 つのディスクがあるとします。バケット数が 3 以下しか設定されていない場合、後でマシンを追加しても同時実行性は向上しません。
- 例を挙げると、10 個の BE があり、各 BE に 1 つのディスクがあるとします。テーブルの合計サイズが 500MB の場合、4 ~ 8 個のフラグメントが考えられます。5GB:8~16枚。50GB: 32. 500GB: 分割することをお勧めします。各パーティションのサイズは約 50GB で、各パーティションには 16 ~ 32 個のフラグメントがあります。5TB: 分割することをお勧めします。各パーティションのサイズは約 50GB で、各パーティションには 16 ~ 32 個のフラグメントがあります。
注: テーブルのデータ ボリュームは、show data コマンドを使用して表示できます。結果は、テーブルのデータ ボリュームであるレプリカの数で割られます。