知虎:ダチョウ
役職:アリババアルゴリズムエンジニア
原文:https://zhuanlan.zhihu.com/p/620360553
2023 年に最もスワイプ画面が多いエントリと言うには、ChatGPT は他の追随を許しません。昨今のGPT-4の時点で、技術革新は学界から産業界、首都圏へと輪を壊す傾向を見せており、一般の人々の日常生活や仕事にも徐々に影響を与えています。
率直に言って、大規模な言語モデルの生成に関する作業については、この方向性が理想的な深層学習の追求であると考えて、長い間保守的な姿勢を保ってきました。道化師が実は私だった今、理想の状態を追い求め続けるからこそ、優秀な仕事は優秀な仕事と呼ばれているのかもしれません。
このシリーズでは、ChatGPT に関連するテクノロジについて説明します. 主な内容は 3 つの部分に分かれており、次の 3 つの記事にも分かれています:
1. 古典論文の精読 [this]: この記事を読むことで、ChatGPT 関連の古典論文の一般的な考え方と各時代の重要な結論を理解できます。
2. オープンソース実装技術 [すぐに]: ここ数か月で ChatGPT に従っているオープンソース ワーカーの主な方向性と方法を要約します。
3. 自然言語生成タスクの過去、現在、未来 [後で]: 大きな言語モデルに加えて、自然言語生成の「従来の」研究方向と将来の想像について話します。
関連技術の急速な発展により、3 つの部分の内容は定期的に更新されます。この記事は主に古典論文の最初の部分の研究用であり、関連する多くの作品があり(図に示すように)、それらを1つずつ読むのは現実的ではないため、この記事では最も持続可能なOpenAIシリーズを選択しますやGoogleシリーズ、最近比較的影響力の大きいLLaMA、そして最後にGLMやChatGLMなどの中国翻案の方が優れています。
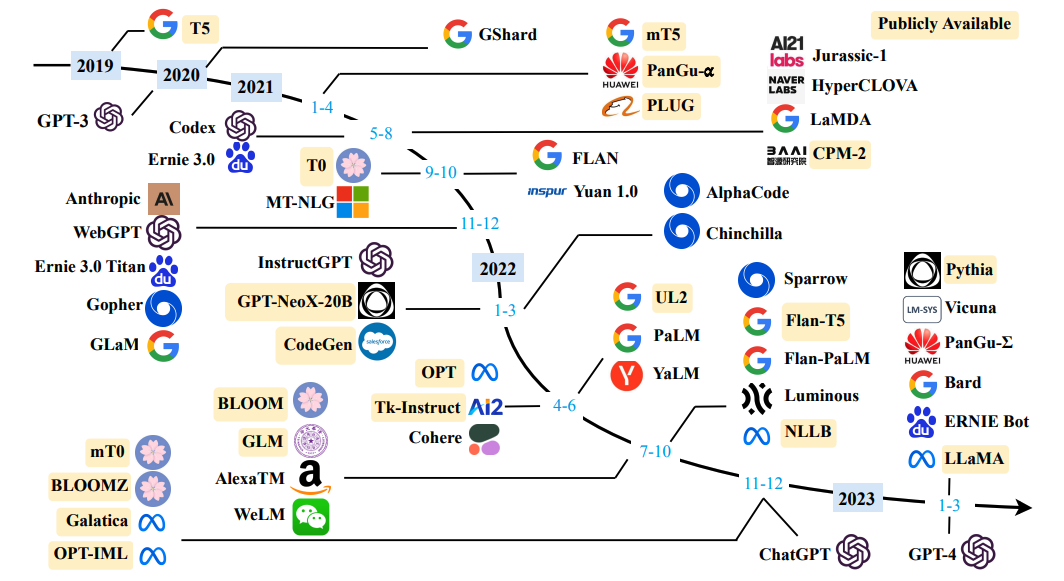
さらに、この記事を読むには、BERT と Transformer とは何か、Encoder-Decoder アーキテクチャとは何か、事前トレーニングと微調整とは何か、言語モデルとは何かなど、NLP の特定の基本概念が必要です。
OpenAIシリーズ
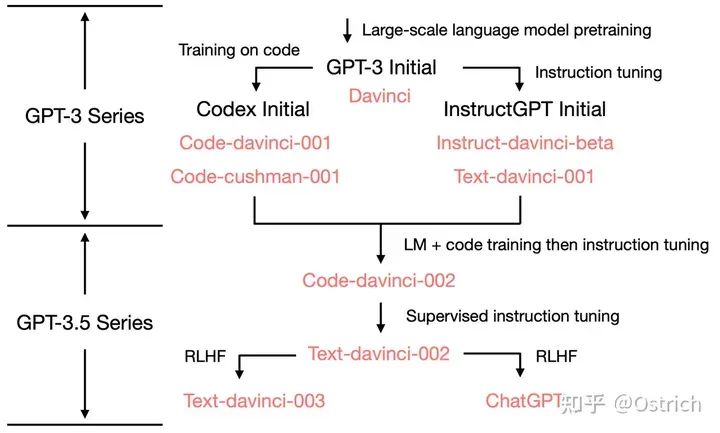
このセクションの目的は、OpenAI シリーズの論文を通じて ChatGPT の主な原則を読むことです. その高度な作業コンテキストは、次の図のように要約できます. 依存関係からさかのぼるには、Codex と instructGPT、GPT-3、GPT-2、GPT-1 を理解する必要があります。(GPT-4は当面GPT-3.5のPlus版と単純に捉え、マルチモーダルデータの処理能力を高めたものであり、詳細が公開され次第検討します。)
GPT-1
論文へのリンク: 「ジェネレーティブ プレトレーニングによる言語理解の向上」
モチベーション
タスクの目標は BERT と同じ (ただし BERT の前) 大規模なラベルなしデータを使用した事前トレーニングとダウンストリーム タスクの微調整により、従来の NLP タスクを解決し、教師ありタスクのデータ収集コストが高いという問題を軽減できることが期待されています。 . GPT-1 は pre-training-fine-tuning アーキテクチャを使用した最初の作業ではありませんが、関連するタスクに Transformer-Decoder を使用した非常に初期の作業でもあります。
プログラム概要
モデル構造:Transformerのデコーダー部分
トレーニング方法: 言語モデルの事前トレーニングのための自己回帰生成方法、下流タスクの微調整のための識別構造。
いくつかの詳細
事前トレーニング:
損失: ラベル付けされていないサンプル ライブラリをトークン シーケンス セット U = {u_1, ..., u_n} として表現し、次の尤度推定を最大化する、従来の言語モデルのトレーニング目標。つまり、段落の前のトークンから次のトークンを予測します。ここで、k はコンテキスト ウィンドウです。
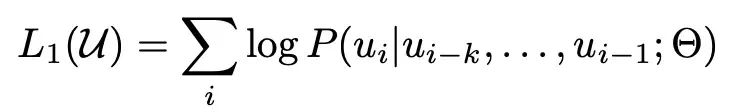
-
モデル: 多層 Transformer デコーダを使用して P をモデル化すると、単純化された式は次のように表されます。W_e はトークン埋め込み行列、W_p は位置ベクトル行列で、多層トランスフォーマー ブロックを通過し、最終的に各トークンはトランスフォーマー ブロックを介してエンコードされたベクトル h_n になり、最終的に線形層 + ソフトマックスを通過します。次のトークンの配布。
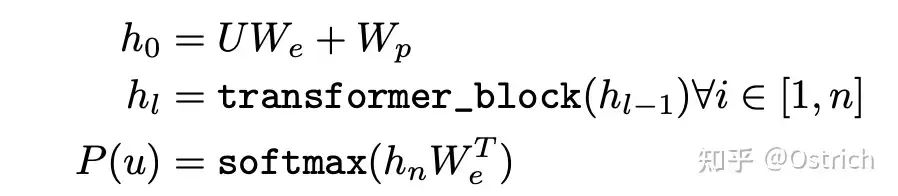
-
データ: 初期のデータはそれほど誇張されていません. GPT-1 の 2 つの主要なデータがあります。
BooksCorpus データセット: 7000 冊を超える未出版の本が含まれています。
1B 単語ベンチマーク (オプション)。
微調整:
モデルの修正: 入力の先頭 [Start] と末尾 [Extract] などに特殊なトークンを追加することで、末尾 [Extract] の隠れ層出力を全結合層に接続し、下流の分類やその他のバリアントをタスクが実行されます。写真のように:
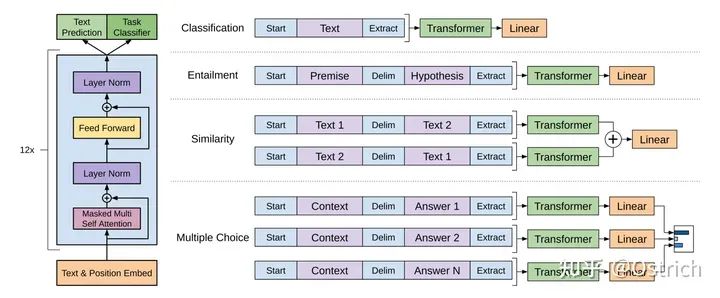
-
損失:
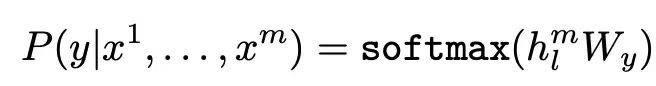
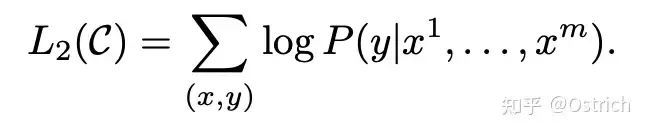
-
細部: 微調整の過程で、下流のタスク ターゲットに基づいて事前トレーニング ターゲットを追加すると、より良い結果が得られます。
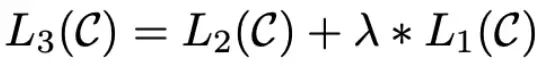
結果と考察
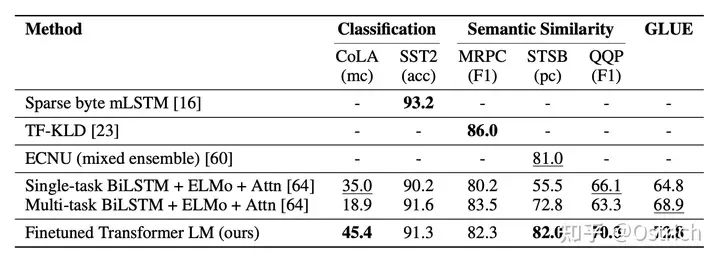
主な検証方法: この記事では主に、いくつかの古典的なタスク データ セットを通じて、ダウンストリーム タスクの効果を通じて戦略の有効性を検証します。結論として、図に示すように、分類ベースのデータセットを例にとると、多くのデータセットでまだ良い結果が得られています。この時点で比較項目にBERTの痕跡がないことがわかります。
GPT-2
論文へのリンク: 「Language Models are Unsupervised Multitask Learners」
モチベーション
GPT-1 の直後に BERT が登場し、リストのさまざまなタスクを実行しました。GPT-1 はモデルのサイズを大きくしようとしましたが、事前トレーニング + 微調整のトレーニング フレームワークの下では、同じパラメータ サイズの BERT にはまだ勝てませんでした; 研究は継続しなければならず、変更を試みる必要があります。ゲーム、Zero-Shotをセールスポイントとして使用し、効果は良好です.
プログラム概要
Zero-Shot を実現するための GPT-2 の方法は、現在では比較的単純なようです。すべての NLP タスクは p(output|input) のモデル化と見なされ、システムが十分な容量を持つモデルを使用して実装されている場合は、どのタスクを完了する必要があるかをモデルに伝える場合、モデリングの目標は p(output|input, task) として表すことができます。
統一された大規模モデルの選択については、ネットワーク構造は GPT-1 と同じであり、使用方法も非常に自然です。タスクと入力の両方が GPT への入力として自然言語を使用し、モデルは次の予測を続けます。可能な限り最大のトークンをステップバイステップで完了します。たとえば、翻訳タスク: モデルは「中国語を英語に翻訳してください。元のテキストは「I love deep learning」です」と入力し、モデルは「I love deep learning.」を出力します。もう 1 つの例は、読解タスクで、モデルは「質問に答えて、内容 'xxx'、質問 'xxx?'」を入力し、モデルは質問に対する回答を出力します。
そうです、初期の Prompting メソッドです (実際には、最も早いものではありません)。これの根拠は、トレーニング データ セットに Prompt 構造化コーパスが大量にあることにあります。これにより、モデルは同様のプロンプトに遭遇した後に何を生成する必要があるかを学習できます。

いくつかの詳細
トレーニング データ: マルチタスクの Zero-Shot をサポートするために、モデルはできるだけ多くの豊富なデータを参照する必要があり、データ収集の目的は同じです。主なポイントは次のとおりです。
オープン ソース Common Crawl、ネットワーク全体の Web ページ データ、データ セットは大きくて豊富ですが、品質の問題があるため、直接使用されません。
自己構築の WebText データセットと Web ページ データ, クリーンで高品質なものに焦点を当てる: 人によってフィルタリングされた Web ページのみを保持します, しかし、人によるフィルタリングのコストは非常に高くなります. ここでの方法は、Reddit プラットフォームに限ります. (国内の投稿バー、ソーシャル共有プラットフォームに似ています) ユーザーが共有するオフサイト リンクには、投稿に少なくとも 3 つのカルマ (いいね! に似ていますか?) が必要です。共有されているのは、興味深い、有用な、または興味深いコンテンツであることが多いと考えられます。
WebText は最終的に 4500w リンクを含み、後処理プロセス: 1. Web ページのコンテンツを抽出した後; 2. 2017 年以降のコンテンツを保持; 3. 重複排除; 4. 800w+ ドキュメント、約 40GB を取得するためのヒューリスティック クリーニング; 4. Wiki 百科事典を除外ドキュメント、下流のテスト データとの重複を避けるため (多くのテスト タスクには Wikipedia データが含まれているため、他のデータは重複しないため?)。
モデル: GPT 構造が使用されますが、モデル機能の入力エンコーディング、重みの初期化、辞書サイズ、入力長、バッチ サイズなどでいくつかの調整が行われ、主にアップグレードされます。
結論と考察
主な結論:
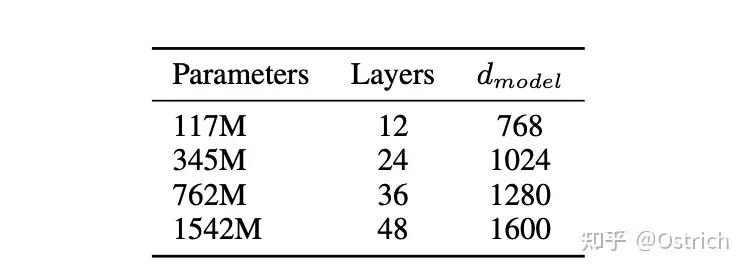
この記事では 4 つのサイズのモデルを試しました。そのうちの 117M は Bert-base (および GPT-1) に対応し、345M は Bert-large パラメーターに対応し、最大のモデルは 1542M (15 億パラメーター) です。
-
モデルの選択では、検証データとして WebText の 5% を使用します. 実験では、すべてのサイズのモデルがまだ適合していないことがわかりました. トレーニング時間が増加するにつれて、検証セットへの影響は引き続き改善される可能性があります.
もちろん、当時の最高の結果は、ほとんどの Zero-Shot タスク セットでも達成されました。
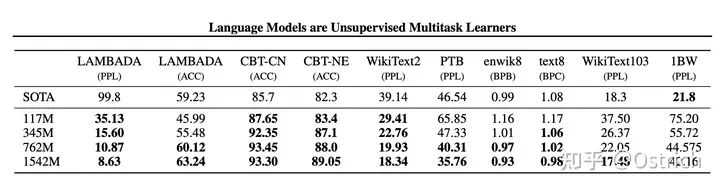
二次的な結論: ほとんどのタスクで、モデルの容量とコア インジケーターの関係は、モデルの容量が増加するにつれて、効果が引き続き強くなることがわかります。15億個のパラメータはボトルネックに達していないようです。つまり、モデルの容量を増やし続ければ、どの程度の効果が得られるかは非常に想像力に富んでいます。(奇跡を起こすためのフォローアップGPT-3もあります)
児童書テストのタスク:
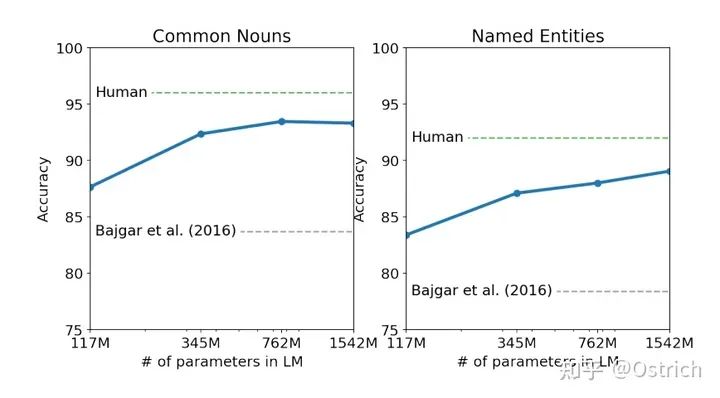
-
Winograd スキーマ チャレンジのタスク:

-
その他のゼロショット タスク
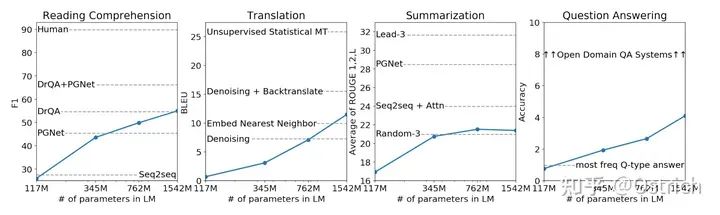
-
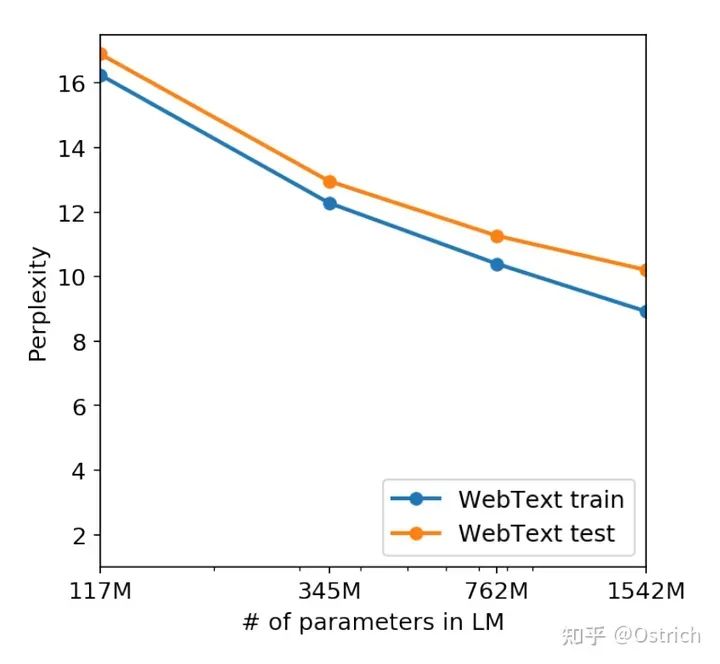
言語モデル事前学習セットと検証セットの効果(perplexity perplexityが小さいほど良い)
GPT-3
論文へのリンク: 「Language Models are Few-Shot Learners」
モチベーション
BERT が登場した後、事前トレーニング + 微調整アーキテクチャは驚くべき結果を達成しましたが (GPT シリーズは短期的には比較できません)、この微調整には多くの制限があります。
微調整にはより多くのドメイン データが必要であり、ラベル付けのコストは高く、いくつかの特別なタスク (エラー修正、書き込み、質疑応答など) はさらに困難です。
微調整は少量のデータでうまく機能しますが、過適合である可能性があります。多くのタスクは人間よりも優れていると言われていますが、実際のパフォーマンスは実際には誇張されています (モデルは知識と推論に基づいてタスクを実行せず、知的ではありません)。
人間の学習習慣と比較すると、人間が十分な知識を身に付けた後 (事前トレーニング)、タスクを実行するために大量の教師付きデータを参照する必要はなく (微調整に対応)、少数のみを参照する必要があります。サンプルの。
この記事では、現在、微調整は実際には効果がありませんが、非微調整を追求することにはまだ価値があると考えています。その方法は、GPT-2 の最終的な結論、より大きなモデル、より多くのデータ、およびより多くの情報 (インコンテキスト学習) を継続することです。
プログラム概要
主に GPT-2 との比較:
GPT-2 モデルとトレーニング方法に従って、モデル サイズは 175B にアップグレードされ (1750 億のパラメーターに対して 15 億)、この 175B モデルは GPT-3 と呼ばれます。
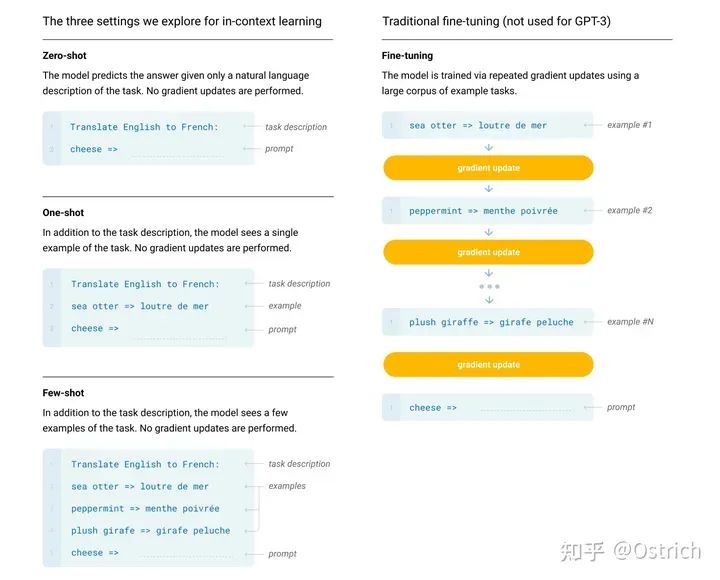
ダウンストリーム タスクの微調整を使用して効果を検証する BERT/GPT-1 モデルや、検証に Zero-Shot のみを使用する GPT-2 とは異なり、GPT-3 は主に In-Context 学習能力を検証します (罰金なしと見なされる場合があります)。 -tuning, no 勾配更新の方法は、プロンプトと入力としてのいくつかの例を通じて特定のタスクを完了する能力に依存します)。
GPT-3 は微調整ができないわけではなく、今後微調整のパフォーマンスを確認するためにいくつかの作業を行います (これは Codex、InstructGPT、および ChatGPT の作業です)。
いくつかの詳細
モデルのトレーニング方法: 前述のように、GPT-2 と比較してイノベーションはありません。つまり、より大きなモデル、より多くの豊富なデータ、より長いトレーニング時間、ゼロショットだけでなく、ワンショットとフューショットも含まれます。タスク (ここでの x-Shot はモデルを微調整するものではなく、いわゆる In-Context 学習であり、トレーニング前の段階で特別な操作はありません)。
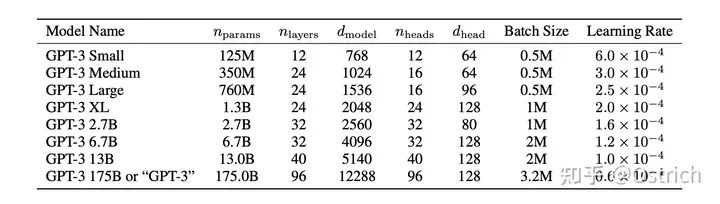
モデル: GPT-2 の構造を踏襲し、モデルの初期化、正規化、およびトークン化でいくつかの最適化が行われました. さらに、Sparse Transformer に似たいくつかの利点が "コピー" されました (要するに、検証済みで効果的ないくつかの操作同じ期間に追加されているか、自分で動作する小さな操作を確認してください)。モデル容量の効果を検証するために、記事ではさまざまなサイズのモデルをトレーニングしましたが、最大の 175B は GPT-3 と呼ばれていました。大規模なモデルをトレーニングするために、モデルの並列化と効率改善に関する作業も行いました (実際、この部分も重要ですが、拡張しませんでした)。同じ期間のいくつかの作業のモデル サイズ パラメーターとトレーニング リソースのオーバーヘッドの比較を図に示します。
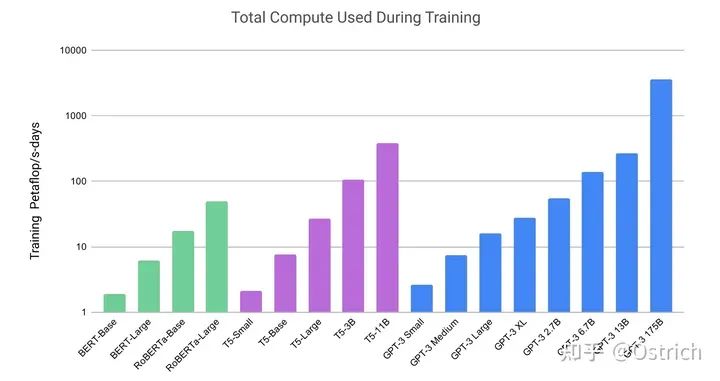
トレーニング データの準備:
この記事では、モデルが拡大された後、いくつかのダーティ データを導入することによる悪影響はそれほど大きくないことがわかりました。したがって、GPT-2 と比較して、GPT-3 は Common Crawl データセットの使用を開始しましたが、いくつかのクリーニング作業を行いました: 1. 高品質のデータセットに類似したコンテンツを保持します (いくつかの類似または差別的な方法を使用); 2. 重複除去;
最後に、クリーニングされた Common Crawl データを既存の高品質データ セットと組み合わせてトレーニング データ セットを取得し、それをさまざまな重みでサンプリングするために使用します。

モデルのトレーニング プロセス:
大規模なモデルにはより大きなバッチ サイズを使用できますが、必要な学習率は小さくなります。バッチ サイズは勾配のノイズ スケールに従って動的に調整されます。大規模モデルの OOM を防ぐために、モデルの並列処理の全範囲が使用されます。使用され、Microsoft はハードウェアとソフトウェアのサポートを提供します。
結論と考察
主な結論: さまざまなデータ セット、NLU 関連のタスクと比較して、全体的な効果は良好であり、GPT-3 のパフォーマンスは良好でした (一部のデータ セットは、教師あり微調整法を上回っていました); QA、翻訳、推論、およびその他のタスクでは、距離監視と微調整モデルの間のギャップは明らかであり、生成タスクは基本的に人間が区別するのが難しい場合があります。たとえば、いくつかの主要なタスク:
SuperGLUE: まずタスクを理解する
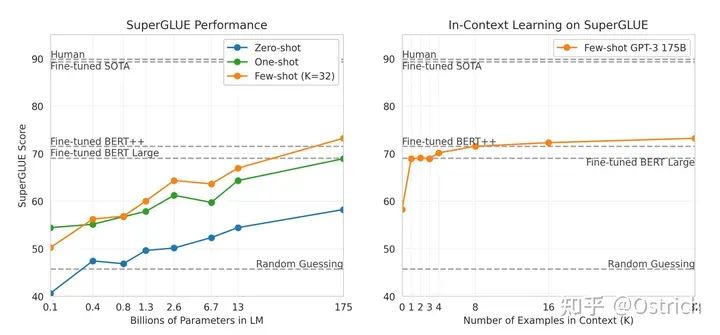
-
Winogrande: タスクベースの推論

-
TriviaQA: 読解タスクベース
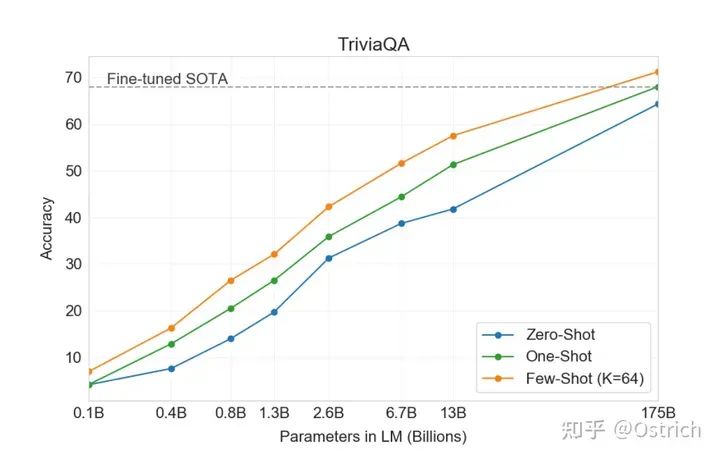
二次的な結論:
主な結論曲線から、少数ショットはゼロ ショットよりも優れていることが明確にわかり、モデルが大きいほど優れている (ナンセンス) 175B は限界に達していないようであり、その効果はより大きなモデルは引き続き上昇する可能性があります。
別のデータは、モデルが大きいほど損失削減の余地が大きいことを示しています.現在のバージョンの最大のモデルはまだ収束していません (黄色の曲線); 出力比率) は徐々に減少しています.
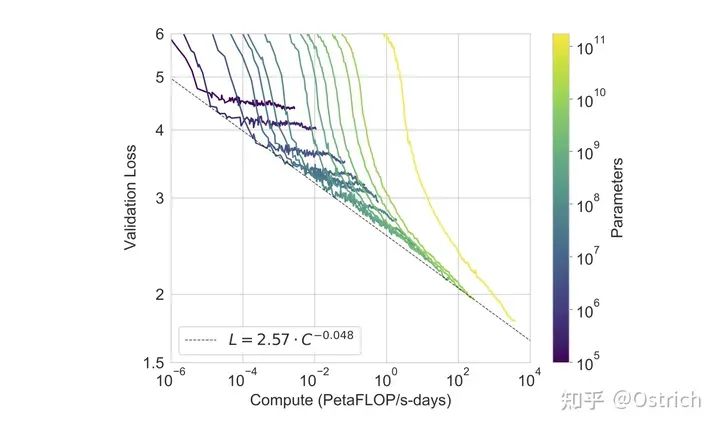
-
モデル生成効果は真偽の判別が難しいため、モデルの偏見、不道徳、不適切な使用についても記事で取り上げているため、オープンソース化しないことも決定しました (OpenAI は CloseAI の道を歩んでいます)。
コーデックス
論文へのリンク: 「コードでトレーニングされた大規模な言語モデルの評価」
モチベーション
GPT-3 ペーパーで述べたように、GPT は微調整できますが、それは将来行われる予定であり、Codex は微調整タスクの 1 つです。タスクは、コード生成の方向で GPT モデルの微調整を調査することであり、アプリケーションの方向の論文と見なすことができます。
プログラム概要
具体的には、Codex はコード コメントを使用してコードを生成します。トレーニング データは github から、主に Python 言語で取得されます。モデルの効果を検証するために、Codex は新しいデータ セット (164 個のオリジナル コードの質問、古典的なリートコードの質問とインタビューの質問の一部と見なすことができます) を作成し、生成されたコードの正確性を単体テストによって検証しました。
最終的に、Codex は 28% のテスト合格率を達成できます (GPT-3 は 0% しか解決できません); サンプリングを繰り返して複数の結果を生成できる場合は、100 を選択すると、70% の合格率を達成できます (考えてみてください)。あなたがどれだけ合格できるかについて)。いくつかの再ランク付け戦略の後、合格率は 80% 近くになります。
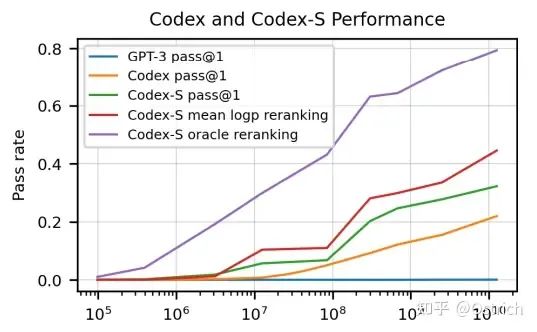
いくつかの詳細
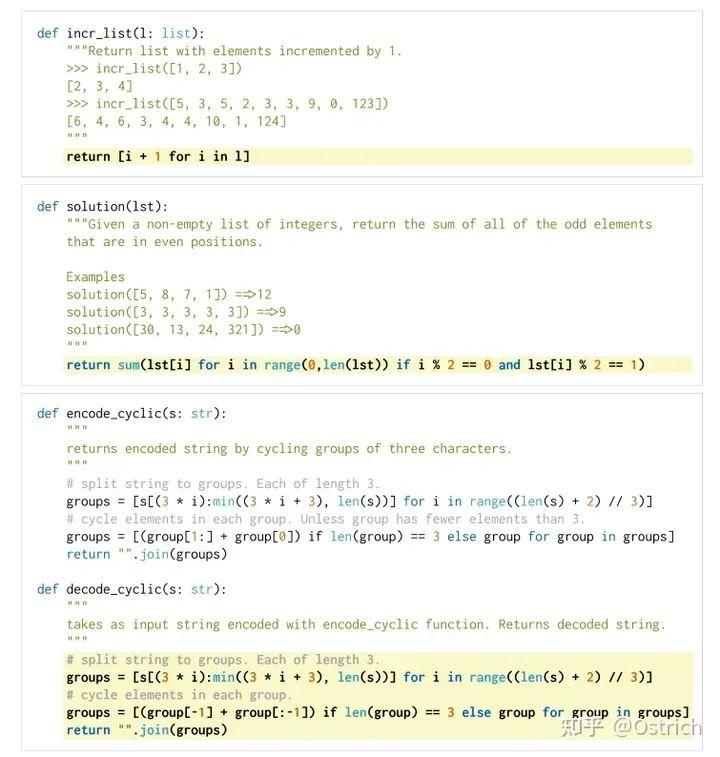
検証セットの準備: これまで評価コードによって生成される既製の検証セットがなかったため、記事では HumanEval を独自に設計しました。また、評価指標として pass@k を使用します (k 件の結果のうち 1 つでも合格であれば合格と見なされ、合格率が計算されます)。生成されたコードのセキュリティを制御できないことを考慮すると、サンドボックス環境で実行する必要があります (クラッシュしても問題ありません)。HumanEval のサンプル データは、コード コメントと標準的な回答を含めて次のとおりです。
トレーニング データ: 2020 年 5 月の時点で、179 GB の Python ファイルを含む 540 万の Github リポジトリが含まれ、ファイル サイズは 1 MB 未満です。いくつかのフィルタリングを行います。主なフィルタリング項目は自動的に生成されたコードであり、平均行の長さが 100 を超えている、行の最大長が 1000 を超えている、一定の割合の数値が含まれている、などです。最終的なデータセットのサイズは 159 GB です。
モデル: 生成タスクを考慮すると、GPT シリーズの事前トレーニング モデルを使用することが有益であるはずです. 13B GPT モデルは、微調整のためのメイン モデルとして選択されました. 事前トレーニング済みの GPT 微調整を使用することは、コード データを使用してゼロからトレーニングするよりも優れているわけではありません (データ量が十分に大きいためです) が、微調整を使用すると収束が速くなります。モデルの詳細:
パラメータ構成は GPT-3 と同様で、コード データの特性に基づいて、特別なトークナイザが作成され、最終的にトークンの 30% が削減されます; 特殊な停止文字 ('\nclass'、'\ndef'など) サンプル データ コードの整合性を確保するために使用されます。
結論と考察
主な結論:
さまざまなパラメーター調整とサンプル数は、生成されたコードの合格率に大きく影響します。
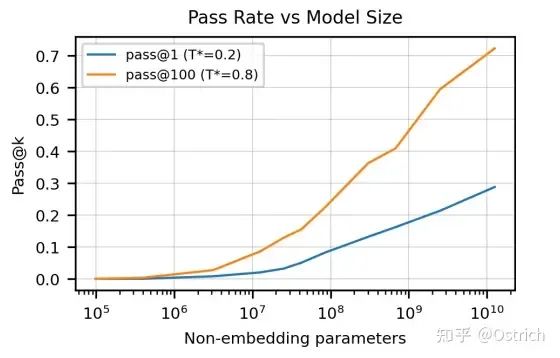
-
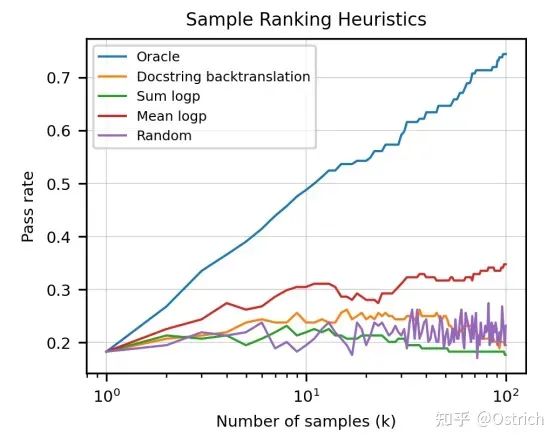
回答を 1 つだけ選択する場合は、最大平均対数確率などのモデル出力インジケーターを使用する方が無作為選択よりも優れている可能性があります。コード選択の事前知識を使用して単体テストを使用すると、最良の理論的結果が得られます (Oracle) 。
副次的な結論: 効果は悪くないので, 傾向としてモデルが大きいほど効果が向上するように思われる. 記事の最後に, マシンのコード記述能力 (自己最適化は最もひどい);さらに、コードに驚きはありません差別、道徳的偏見。(これはおそらく、コードによく言う人がいて、コードに Fxxk が付いていること、人のいるところに偏見があることが原因です)。
InstructGPT
論文へのリンク: 「人間のフィードバックで指示に従うための言語モデルのトレーニング」
モチベーション
ユーザーの指示と好みの回答を使用して GPT モデルを微調整し、モデルによって生成されるコンテンツがユーザーの意図とより一致し、より現実的で有用なものになるようにします (調整、調整プロセス)。これを行うための出発点は、古典的なアプリケーション シナリオに直面することです. ユーザーはコマンドに意図を宣言し、モデルが有用で無害なコンテンツを生成することを期待します. しかし、大量の Web ページ データでトレーニングされた大規模な言語モデル GPT はできません.この要求に直接対応するため、微調整が必要です。
プログラム概要
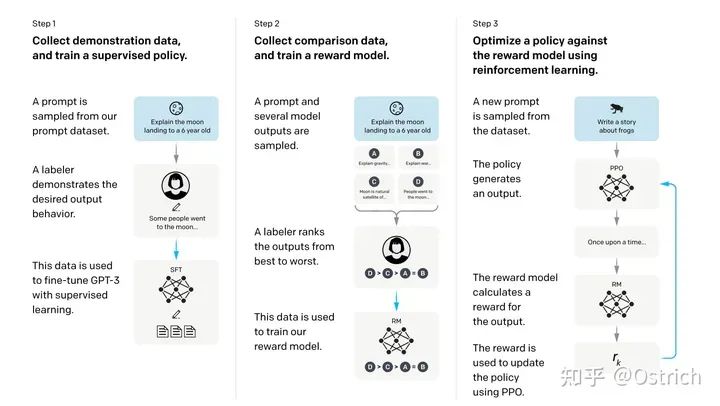
下の図に示すように、命令の微調整のプロセスは 3 つのステップ (RLHF、人間のフィードバックからの強化学習) に分けられます。
1. 一連のプロンプト (ソース アノテーターと OpenAI API 要求によって手書き) を準備します。この一連のプロンプトに対して、アノテーターは予想される回答を手書きで書き込み、このプロンプトと回答のデータを使用して GPT-3 生成モデルを微調整します。ここではこれを監視ポリシーと呼びます。
2. 微調整されたモデルを使用して、より多くのプロンプトに基づいて回答を生成します (1 つのプロンプトが回答を生成するために複数のサンプルを生成します). 現時点では、アウトソーシングは、生成されたコンテンツの相対的な順序をマークするだけで済みます; このマークされたデータを使用してトレーニングを行います報酬モデル (RM モデル)、入力プロンプトと回答、およびモデルはスコアを出力します (ここでも GPT モデルが使用されます)。
3. 強化学習の方法を使用して、より多くのプロンプトをサンプリングし、生成モデルのトレーニングを続けます。強化学習の報酬は、ステップ 2 でモデルによってスコア付けされます。
ステップ 2 と 3 は継続的な反復プロセスです。つまり、ステップ 3 でトレーニングされたより優れた生成モデル (ポリシー) を使用して、新しい RM モデル (つまり、ステップ 2 )、次に新しい生成モデルをトレーニングします (ステップ 3 に対応)。相対順序アノテーション データのほとんどはステップ 1 から取得され、一部はステップ 2 と 3 の反復から取得されます。
なお、この記事はこの方法を使った最初の作品ではなく、以前の記事「人間のフィードバックから要約することを学ぶ」もあり、同様の 3 ステップの方法でタスクを要約しています。一夜にしてではなく、作品の連続性を反映したOpenAIの作品でもあり、ひらめきは何かがあるというわけではありません。
いくつかの詳細
データ収集プロセス
コールド スタート段階: 手動でラベル付けされたプロンプトと回答のデータによってトレーニングされた InstructGPT の初期バージョンを監督します; 強化段階: 試用版のオンライン サービスを展開して、より多くの豊富な実際のユーザー プロンプトを収集します。この作業は、オンラインの正式な環境のサービス ユーザー データを使用しません。試用版のデータは、データのラベル付けとモデルのトレーニングに使用され、ユーザーにも事前に通知されます。
収集されたプロンプトは、最も長い共通プレフィックスに従って重複排除されます。
各ユーザーには、個々のユーザーの好みに対応するモデルを回避するための最大 200 のプロンプトがあります。トレーニング セット、検証セット、およびテスト セットには、同じユーザーは含まれません (ユーザー次元の一般化機能を強調します)。
プロンプトで個人のアイデンティティに関連する情報をフィルタリングすることは、モデルがユーザーの特性を学習するのを防ぐことにもなります。
初期バージョンの InstructGPT のトレーニング データは、アウトソーサーによって手書きされたプロンプトと回答でした. コールド スタート プロンプトには、1. タスクの豊富さを追求する一般的なタスクの質問、2. 同じタイプのプロンプトで複数のクエリと回答を書く、の 3 つのカテゴリがあります。 ; 3. 本物のユーザーからのプロンプト要求の模倣。
上記の操作の後、3 種類のデータが取得されます: 1. SFT データセット、トレーニング セット 13k プロンプト (API から、アノテーターによって手書き)、SFT モデルのトレーニングに使用; 2. RM データセット、トレーニング セット 33k プロンプト (API および手動ラベル生成モデルの出力回答のソートは、RM モデルのトレーニングに使用されます; 3. PPO データ セット、31k プロンプト (API からのみ)、手動ラベル付けは必要ありません。 RLHF の微調整に使用されます。
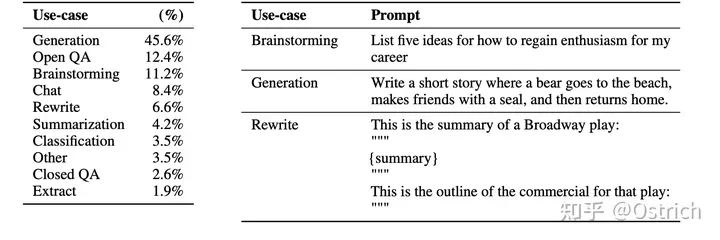
プロンプト機能:
実際のユーザーの迅速な指示タイプの分布とサンプルを図に示しますが、その96%は英語ですが、他の言語への一般化能力があることがわかります。
データ注釈の詳細 (これも重要であり、参照に値します):
40 人の請負業者からなる外部委託されたラベリング チームは、ラベリングの多様性を改善し、モデルがラベラーのスタイルに敏感になるのを防ぐことになっています。
アノテーターは、さまざまなグループ (宗教、性的指向、人種など) に敏感で、潜在的に有害なコンテンツを特定できるアノテーターを選別することを目的として、テスト (試験、性格テスト) を受けました。
アノテーターは、ユーザーの意図を正確に判断し、あいまいな意図をスキップできる必要があります。暗黙の意図を考慮し、潜在的で帰納的な罵り言葉、偏見、虚偽の情報を特定できる必要があります。
トレーニング フェーズと検証フェーズの意図の整合性には、わずかな矛盾があります。トレーニング フェーズでは、生成されたコンテンツの有用性が強調されますが、検証フェーズでは、コンテンツの真実性と無害性に焦点が当てられます。
ラベル付け工程では、アルゴリズム開発担当者とラベル付け担当者が密に連絡を取り合い、これを実現するために外部委託のラベル付け担当者のエントリープロセスが行われています(社会保険料を支払う必要がある場合があります=_=)。
ラベラーに対するモデルの一般化能力をテストするために、テスト ラベラーの一部 (差し出されたラベラー、実際のツール担当者、厳密) が確保されます. これらのラベラーによって生成されたデータはトレーニングには使用されず、これらの人員はトレーニングに使用されません。テストされていません。
ラベリング タスクは困難ですが、ラベラーのラベリングの一貫性は悪くありません.トレーニング ラベラーのラベリングの一貫性は 72.6 ± 1.5% であり、テスト ラベラーの一貫性は 77.3 ± 1.3% です.
モデルの実装: 3 つの部分を含む、トレーニング プロセスと同じ
教師あり微調整 (SFT): ラベラーによってマークされたデータを使用して、GPT モデルの教師あり微調整、16 エポックのトレーニング、および学習率の余弦減衰。モデルの選択には、検証セットの RM モデル スコア (鶏と卵) が使用されます。ここでの SFT モデルは、検証セットで 1 エポック後に過剰適合することに言及する価値がありますが、より多くのエポックを実行し続けることは、RM スコアと人間の好みにとって有益です。
報酬モデリング(RM):
モデル: 同じ SFT GPT モデル構造ですが、別の 6B がトレーニングされます (175B は不安定で、次の RL トレーニングには適していません)、入力はプロンプトと生成されたコンテンツであり、プーリングの後に完全な接続が続きます (おそらく)スカラー報酬ポイントを出力します。
損失関数は次のように表されます。
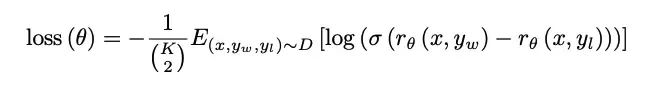
-
-
K はプロンプト モデルによって生成された回答の数であり、ラベラーは K 個のモデルを並べ替えます。K は 4 ~ 9 で、9 と 4 をマークするコストは似ています。
平均値が 0 になるように報酬を正規化するには、バイアスが必要です。これは、下流の RL が使用するのに便利です (ここでのバイアスは、RL のルーチン操作でもある reword の平均値にすることができます)。
強化学習 (RL)、2 つの実験モデル:
「PPO」モデル: 古典的な PPO アルゴリズム、オフライン RL アルゴリズムを直接使用します。目標は、オンライン モデルとオフライン モデルの KL 相違を考慮しながら、モデル フィードバックの報酬を最大化することです (ここでオフライン モデルはSFT モデル、およびオンライン モデルは、最適化されるターゲット モデルに対して、オンライン モデルのパラメーターが定期的にオフライン モデルに同期されます (RL に慣れていない場合は、その目的を簡単に理解できます); による報酬の出力モデルは RM によって採点されます。
「PPO-ptx」モデル: PPO+ 事前トレーニング ターゲット (このターゲットでは、パブリック NLP タスクの効果を考慮できることが検証されています)、最終的な最適化ターゲット、最大化:
-
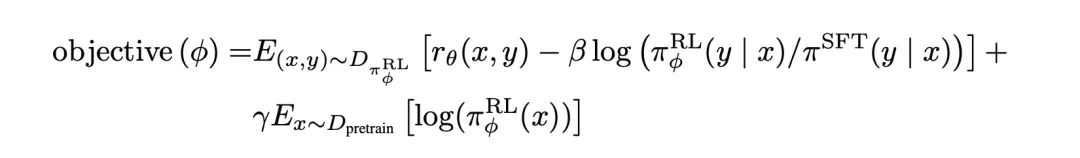
検証方法: 1. 生成された回答が人々に好まれるかどうか、2. 古典的な NLP タスクがどれだけうまく解決されているかという 2 つの側面でモデルの能力を評価します。
API リクエストでの迅速な検証効果:
実際の分布のダウンサンプリング プロンプトがテスト セットとして使用されます。
ベースラインとして 175B の SFT GPT-3 モデル。
アノテーターは、各モデルによって生成されたコンテンツを 1 ~ 7 個のいいね/認識のスコアで評価します。
認識の基本は、有益、誠実、無害であり、各次元には多くの詳細なルールがあります。
オープンソースの NLP データセットには、次の 2 つのカテゴリがあります。
データセットの安全性、信憑性、害、偏見を測定します。
読解、質問応答、要約など、従来の NLP タスク データセットのエントロピー ゼロ ショット結果。
結論と考察
主な結論:
API を介して取得したテスト セット プロンプトでは、RLHF がベースラインよりも優れていることが示されています。
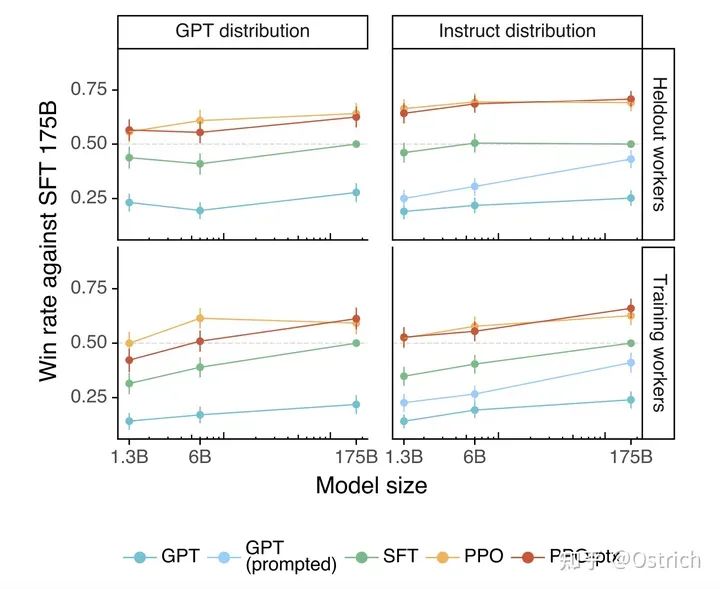
-
他のモデルと比較して、それも良いです:
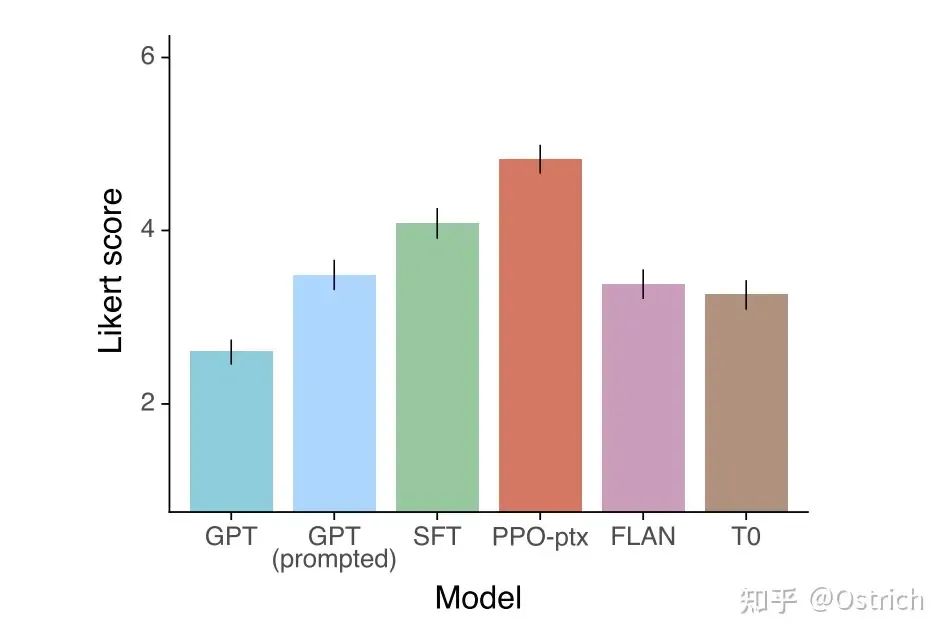
副次的な結論 (InstructGPT によって生成されたコンテンツの専門的な評価):
アノテーターは一般に、InstructGPT によって生成されたコンテンツが GPT-3 よりもはるかに優れていると考えています。
InstructGPT モデルによって生成されたコンテンツは、GPT-3 よりも事実に基づいています (事実の誤りが少ない)。
InstructGPT によって生成されたコンテンツは、GPT-3 よりも有害性が優れていますが、偏りはそれほど強くありません。
RLHFの微調整の過程で、「アライメント税」により、オープンソースNLPタスクのパフォーマンスが低下しましたが、言語モデルの事前トレーニングターゲットをRLHFに基づいて追加することができます。 (PPO-ptx) を考慮します。
InstructGPT モデルは、「ホールドアウト」アノテーターについても一般化を示しました。
パブリック NLP データセット タスクのパフォーマンスは、InstructGPT では追求されません (ChatGPT は追求されます)。
RLHF 微調整データセットの配布外の InstructGPT モデルのプロンプトも、優れた一般化機能を備えています。
InstructGPT で生成されたコンテンツには、まだいくつかの単純なエラーがあります。
チャットGPT
紙無し、公式ブログ:「https://openai.com/blog/chatgpt」
OpenAI は ChatGPT の詳細を開きませんでした. 2 つの一般的な方法の説明のみがあります. 概要には次のものが含まれます:
方法は InstructGPT とほぼ同じですが、データの収集方法が少し異なります。ChatGPT で使用される対話形式のデータ、つまり複数回のプロンプトとコンテキストのデータ、および InstructGPT のデータ セットも対話形式に変換されて一緒に使用されます。
RM モデルをトレーニングし、複数のモデルによって生成された結果を使用し、モデルによって生成されたコンテンツをランダムに選択し、アノテーターがコンテンツの品質に従って並べ替えられるようにし、RM モデルを使用して後続の PPO 微調整トレーニングを実行します。繰り返しますが、これは反復プロセスです。
これ以上の詳細はなくなりましたが、OpenAI の友人である Anthropic による論文 (創設者も OpenAI 出身です) から詳細を見ることができます。OpenAIの仕事の継続性から判断すると、会社を辞めた人も関連する仕事を続けるべきです。
Anthropic を読む前に、OpenAI の一連の作業概要を挿入し、ファイルとして保存します。上記の論文を読めば、この表の内容を大まかに理解できるはずです (参照)。
| 能力 | モデル名 | トレーニング方法 | OpenAI API |
| GPT-3以前 | |||
| 事前訓練 + バートのようなフィンチューン | GPT-1 | 言語モデリング + タスク微調整 | - |
| ジェネレーション+ゼロショットタスク | GPT-2 | 言語モデリング | - |
| GPT-3シリーズ | |||
| 生成+世界知識+文脈学習 | GPT-3 初期 | 言語モデリング | ダ・ヴィンチ |
| +人間の指示に従う+目に見えないタスクに一般化する | Instruct-GPT イニシャル | 命令チューニング | Davinci-Instruct-ベータ版 |
| +コード理解+コード生成 | コーデックスのイニシャル | コードのトレーニング | コード-クッシュマン-001 |
| GPT-3.5シリーズ | |||
| ++コード理解++コード生成++複雑な推論/思考の連鎖(なぜ?)+長期依存(おそらく) | GPT3.5シリーズで現行コーデックス最強モデル | テキスト + コードのトレーニング 命令のチューニング | Code-Davinci-002 (現在無料。現在 = 2022 年 12 月) |
| ++人間の指示に従う--コンテキスト学習--推論++ゼロショット生成 | Instruct-GPT supervisedTrade インコンテキスト学習によるゼロショット生成 | 教師あり命令のチューニング | テキスト-ダヴィンチ-002 |
| +人間の価値に従う+より詳細な生成+インコンテキスト学習+ゼロショット生成 | Instruct-GPT RLHF 002 よりも整合性が高く、パフォーマンスの低下が少ない | 命令チューニング w. RLHF | テキスト-ダヴィンチ-003 |
| ++人間の価値に従う++より詳細な生成++知識を超えた質問を拒否する(なぜ?) ++モデルダイアログのコンテキスト -- コンテキスト内学習 | ダイアログ履歴モデリングのための ChatGPT Trade in context learning | ダイアログのチューニング w. RLHF | - |
一部の大物が言ったように、ChatGPT にはイノベーションがなく、強力なモデルを作成するための一連の戦略の重ね合わせにすぎないというのは本当かもしれません。ChatGPT はエンジニアリングとアルゴリズムの組み合わせであると言う人もいます。とにかく、メソッドは本当にうまくいきます。
人類的クロード
参考文献リンク: 「人間のフィードバックからの強化学習による、有益で無害なアシスタントのトレーニング」
ChatGPT が登場して間もなく、Anthropic はすぐに Claude を立ち上げました。Claude は、メディア レベルで ChatGPT の最も強力な競争相手です。非常に迅速にフォローアップできるようにするには、それが同じ時期の作業である可能性が高い (またはそれよりも前であり、関連するワーキング ペーパーは数か月前です)。Anthropic は OpenAI の従業員が退職するスタートアップ企業であり、OpenAI の哲学の一部ではないと言われています (もしかしたら、オープンではなく、社会的責任?)。
いくつかの内部テストの結論: ChatGPT と比較して、Claude は潜在的に有害な問題を回避でき、コード生成がわずかに劣ります。一般的な Prompt も違いはありません。効果に関しては、ChatGPT はより機能的である可能性がありますが、Claude はより「無害」である (つまり、社会への潜在的な負の影響が少ない) ことは、参考文献のタイトルにも反映されています。
モチベーション
嗜好モデルと RLHF (ヒューマン フィードバック強化学習) を導入して大規模な言語モデルを微調整し (おそらく OpenAI からの脱却のため、GPT-3 については言及されていません)、便利で無害なパーソナル アシスタント (ChatGPT に似ています) を取得します。 ; このアラインメント (Alignment) の微調整により、事前にトレーニングされた言語モデルがほぼすべての NLP タスクで大幅に改善され、コーディング、要約、翻訳などの特定のタスク スキルを完了することができます。
プログラム概要
実際、この考え方は、3 段階の RLHF である InstructGPT の考え方に似ています。違いは、1. 反復オンライン モデル トレーニングが実行される: モデルと RL 戦略が毎週新しい手動フィードバック データで更新され、データとモデルが継続的に反復される; 2. 対話形式のデータが使用される; 3.モデルにもっと注意が払われます 役に立ち、無害です。
モデルと戦略の設計に加えて、この記事では RLHF の安定性に焦点を当て、モデルのキャリブレーション、ターゲットの競合、OOD (分布外) の識別などの問題も分析します。
目標の競合とは、有益と無害の間の目標の競合を指します。なぜなら、モデルがすべての質問に「わからない」と答えた場合、それは無害ですが、まったく役に立たないからです。
いくつかの詳細
ダイアログ設定データセット:
有用性と無害性の対話データ セットのバッチが収集され、対話注釈ページでアノテーターとさまざまな 52B 言語モデルとの間の相互作用によってデータ注釈が完成しました。図に示すように、ページに注釈を付けます。
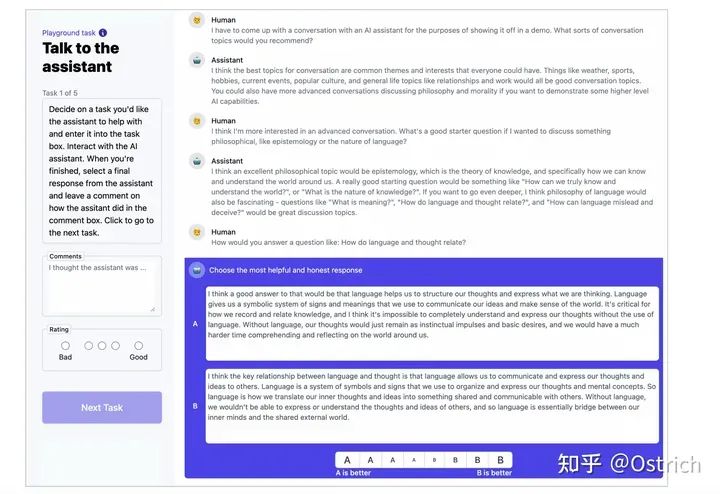
-
アノテーターは、対話型ページでモデルとオープンな対話を行ったり、助けを求めたり、指示を与えたり、有害なコンテンツを出力するようにモデルを誘導したりします (盗みを成功させる方法など)。モデルによって複数の回答が出力される場合、ラベラーは対話の各ラウンドでどちらがより有用で、どちらがより有害であるかをマークする必要があります。
3 つのデータが収集されました。1 つは初期モデル (SFT) から、もう 1 つは早期選好モデル (RM) サンプリングから、最後のデータは人間のフィードバックを伴うオンライン強化学習モデル (毎週更新) から収集されました。
オープンソースの 3 つのデータ: https://github.com/anthropics/hh-rlhf
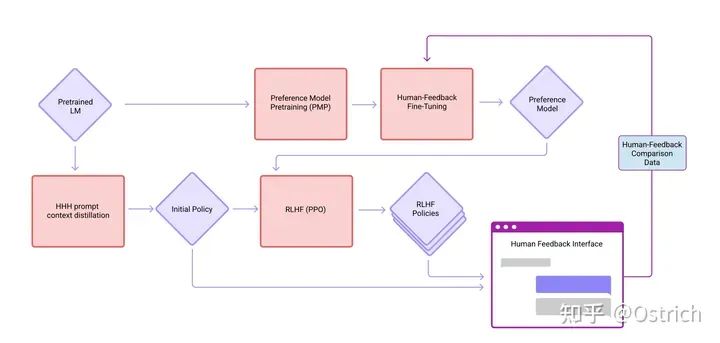
データ収集とモデルのトレーニング プロセス (中間に含まれる概念は、以前の論文を読んで理解する必要があります):
リャマとアルパカ
つまり、モデルはますます大きくなり、オープンソースはますます少なくなっています(実際、オープンソースだとほとんどの人がプレイできません)。まず、GPT-3 シリーズのモデルは非常に大きく、トレーニング モデルと推論モデルの両方に多数のグラフィックス カードが必要です。次に、GPT-3 で使用されるデータは公開されておらず、コンピューティングで再現することは困難です。そのため、自分でデータのディスクを作成する必要があります; GPT では、-3 以降の ChatGPT のクローズド ソースはさらにクローズドであり、商業的利益をさらに考慮する必要がある場合があります。
このような状況の中で、現場モデルの効率化とオープン化に関する研究がますます進んでおり、近い将来最も影響力のあるものは、Meta AI の LLama と、スタンフォードの LLama ベースの Alpaca です。前者は GPT の大規模言語モデルに似ており、後者は ChatGPT に似ています。
ラマ
论文:《LLaMA: Open and Efficient Foundation Language Models》
コード: https://github.com/facebookresearch/llama
モチベーション
大規模な言語モデルに関連する作業では、これまでの一般的な仮定は、モデルが大きいほど効果が高いというものでした。ただし、最近のいくつかの研究では、与えられたコンピューティング リソースの前提の下で、最大のモデルではなく、より多くのデータを含む比較的小さなモデルによって最良の効果が得られることが示されています。後者は、推論または微調整の段階でより使いやすく、より優れた追求です。
それに対応して、このホワイト ペーパーの作業は、モデルのバッチをトレーニングすることであり、これにより、より良い結果とより低い予測コストが実現されます。この効果を実現する 1 つの方法は、モデルがより多くのトークンを認識できるようにすることです。これらのトレーニング済みモデルは LLama です。
プログラム概要
ラマの考え方は比較的単純で、動機に大まかに盛り込まれています。この作品のその他の特徴は、次のように簡単に要約できます。
7B から 65B までのモデルを提供し、13B モデルの効果は GPT-3 (175B) を超えることができ、65B モデルの効果は Google の PaLM (540B) に近いです。
トレーニング モデルは、オープン ソース データ セット、数兆のトークンのみを使用します。
複数のタスクが SOTA 上にあり、モデルの重みはすべてオープン ソースです。
いくつかの詳細
訓練用データセット(主に英語なので中国語や中国語の微調整効果が気になる)
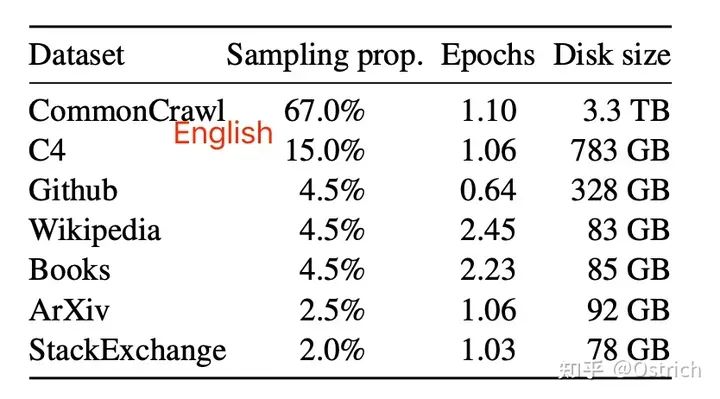
モデル容量の概要

モデル構造:
GPT と同様に、これは Transformer Decoder アーキテクチャでもあり、効果的であることが検証されているさまざまな小さな最適化 (Pre-Normalization、SwiGLU アクティベーション関数、Rotary Embedding、AdamW オプティマイザーなど) を使用します。同時に、モデルの実装やモデルの並列最適化など、いくつかのトレーニング効率の最適化が行われました。
トレーニング プロセス: 7B および 13B モデルは 1T トークンでトレーニングされ、33B および 65B モデルは 1.4T トークンでトレーニングされます。
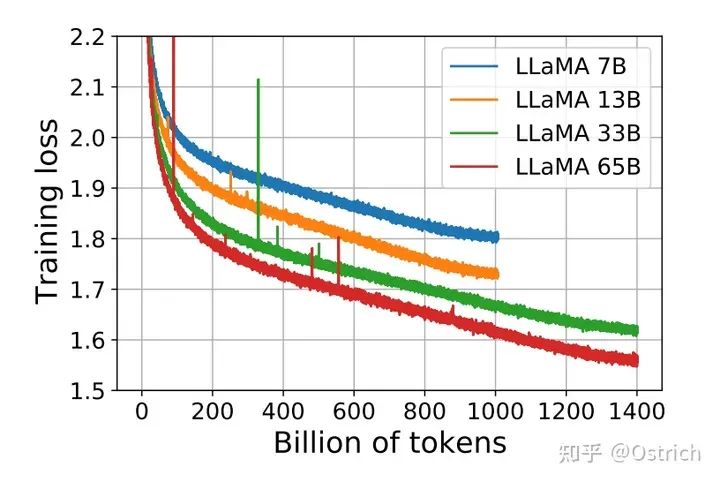
結論と考察
LLama は GPT に対してベンチマークされ、主に Zero-Shot および Few-Shot タスクで検証されましたが、同時に、命令の微調整が現在人気のあるアプリケーションの 1 つであることを考慮して、命令の微調整タスクでも検証されています。
ゼロショット
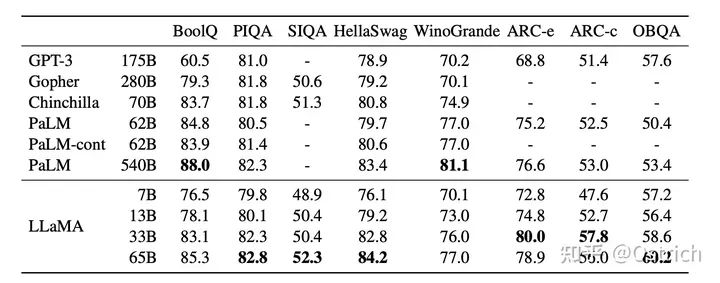
-
少数ショット
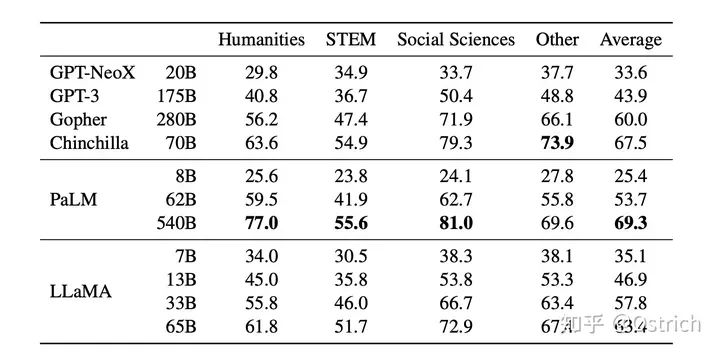
-
命令の微調整 (主に Google の Flan シリーズとの比較):
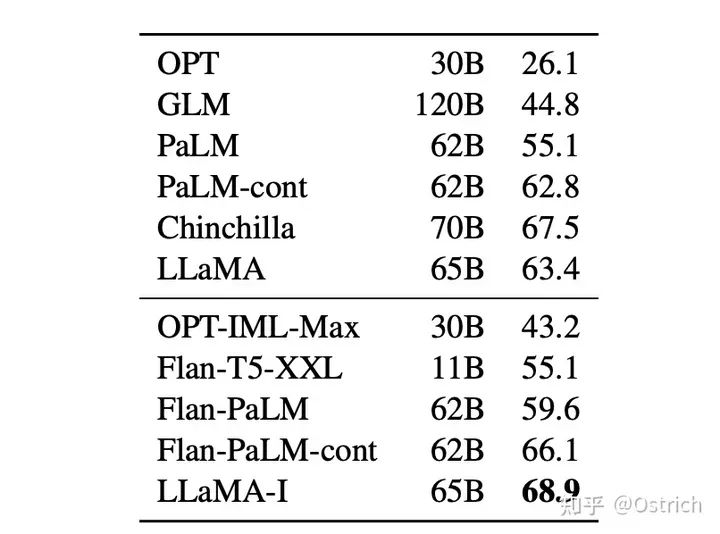
アルパカ
記事: https://crfm.stanford.edu/2023/03/13/alpaca.html
コード: https://github.com/tatsu-lab/stanford_alpaca
モチベーション
先に見たように、GPT-3.5、ChatGPT、Claude、Bing Chat などの命令微調整モデルは優れていることが確認されていますが、虚偽のコンテンツ、偏見、悪意などの問題は依然として存在します。これらの問題の解決を早めるためには、学者 (貧しい教師、学生、企業) が研究に参加する必要がありますが、GPT-3.5 モデルは大規模でクローズド ソースです。
LLama は少し前にリリースされ、希望を与えてくれました。したがって、アルパカ モデルは、LLama に基づいて命令を微調整することによって得られました.効果は GPT-3.5 と同様であり、単純で再現のコストが低くなります.
プログラム概要
貧困者による命令の微調整には、2 つの前提条件が必要です: 1. 小さいパラメーターと優れた効果を備えた事前トレーニング済みの言語モデル、2. 高品質の命令トレーニング データ。
これらの 2 つの前提条件は現在、簡単に満たされているようです: 1. LLama モデル 7B モデルが受け入れられる; 2. 既存の強力な言語モデルを使用してトレーニング データを自動生成できる (プロンプトを準備し、GPT-3.5 シリーズの OpenAI API を呼び出す)。
いくつかの詳細
トレーニング方法: 命令の微調整方法を使用して LLama 7B モデルでトレーニングします。トレーニング データのサイズは 52,000 で、ソースは OpenAI GPT-3.5 API の呼び出しです (500 ドルの費用がかかります)。微調整プロセスはトレーニングされます。 80G A100s グラフィックス カード 8 枚で 3 時間 (クラウド コンピューティング サービスを使用すると、100 ドルかかります)。トレーニング プロセスを図に示します。
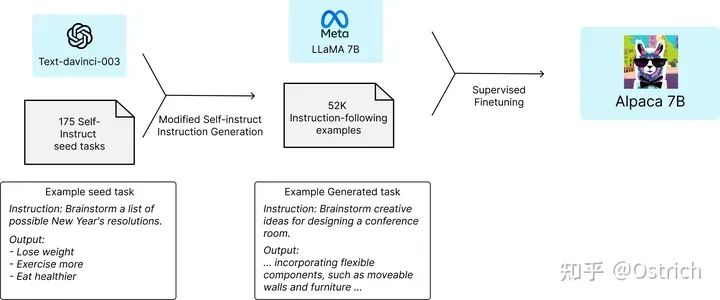
結論と考察
現在公開中: テスト デモ、トレーニング データ セット、トレーニング データ生成プロセス、トレーニング コード; 事前トレーニング済みの重みは将来的に公開されます (いくつかの外部要因が考慮される場合があります)。
デモ: 誰もがアルパカを試すためのインタラクティブなデモ。
データ:アルパカを微調整するために使用される 52K のデモンストレーション。
データ生成プロセス: データを生成するためのコード。
トレーニング コード: Hugging Face API を使用してモデルを微調整するため。
将来の可能性のある方向性 (推論能力の最適化は含まれません。おそらくこれらは金持ちに任せるべきです):
モデルの検証: HELM (言語モデルの全体論的評価) から始まるモデルのより体系的かつ厳密な評価により、モデルの生成とそのコマンド能力を検証します。
モデルのセキュリティ: モデルのリスクのより包括的な評価。
モデルの理解 (解釈可能): 研究モデルは何を学習したか? ベースモデルの選択の知識は何ですか?モデル パラメーターを増やすと何がもたらされますか? 最も重要なコマンド データは何ですか? データを収集する他の方法はありますか?
GLM と ChatGLM
LLama は優れていますが、より多くの英語のデータ セットを使用しますが、中国語ではうまく機能しません。同様に、命令を微調整した後、上限は中国のシーンで比較的低くなるはずです。そのため、中国語では独自の研究の方向性が必要であり、現在比較的影響力の強いオープンソース版は、清華のGLMやChatGLMです。
GLM や ChatGLM に関する紹介は数多くありますが、以下は内容の一部を抜粋して簡単に理解するためのものです。
GLM
紙:
《GLM: Autoregressive Blank Infilling による一般言語モデルの事前学習》
《GLM-130B: オープンなバイリンガル事前訓練モデル》
プログラム概要
GLM-130B は、GPT-3 に続く清華の大言語モデルの方向への試みです。BERT、GPT-3、および T5 のアーキテクチャとは異なり、GLM-130B は複数の目的関数を持つ自己回帰事前トレーニング モデルです。
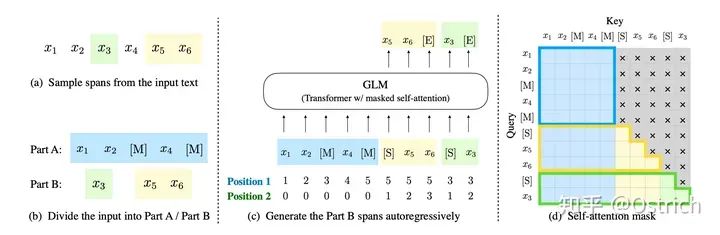
いくつかの詳細
2022 年 8 月にオープンする GLM-130B には、いくつかのユニークな利点があります。
バイリンガル: 中国語と英語の両方をサポートします。
高精度 (英語): GPT-3 175B (API: davinci、ベース モデル)、OPT-175B、および BLOOM-176B よりも、英語の公開自然言語リスト LAMBADA、MMLU、および Big-bench-lite より優れています。
高精度 (中国語): 7 つのゼロサンプル CLUE データセットと 5 つのゼロサンプル FewCLUE データセットで、ERNIE TITAN 3.0 260B および YUAN 1.0-245B よりも大幅に優れています。
高速推論: 最初の INT4 量子化された 1000 億モデルは、4 カード 3090 または 8 カード 2080Ti サーバーによる高速でほとんど損失のない推論をサポートします。
再現性: すべての結果 (30 以上のタスク) は、オープン ソース コードとモデル パラメーターを使用して再現可能です。
クロスプラットフォーム: 国内の Haiguang DCU、Huawei Ascend 910 および Shenwei プロセッサ、および米国の Nvidia チップでのトレーニングと推論をサポートします。
ChatGLM
記事: https://chatglm.cn/blog
コード: https://github.com/THUDM/ChatGLM-6B
プログラム紹介
ChatGLMは、ChatGPTの設計思想を参考に、1000億のベースモデルGLM-130Bにコードの事前学習を注入し、Supervised Fine-Tuningなどの技術により人間の意図の整合を実現します。
コミュニティと共に大規模モデル技術の開発を促進するために、Tsinghua は ChatGLM-6B モデルもオープンソース化しました。ChatGLM-6B は、62 億のパラメーターを持つ中国語と英語のバイリンガル言語モデルです。ChatGLM(http://chatglm.cn)と同じ技術を用いて、ChatGLM-6Bは中国語の質疑応答と対話機能を持ち、2080Ti1台で推論をサポートします。
いくつかの詳細
ChatGLM-6B には次の機能があります。
十分な中国語と英語のバイリンガル事前トレーニング: ChatGLM-6B は、中国語と英語の 1:1 の比率で 1T トークンをトレーニングし、バイリンガル能力を備えています。
最適化されたモデル アーキテクチャとサイズ: GLM-130B トレーニングの経験に基づいて、2 次元 RoPE 位置エンコーディングの実装が改訂され、従来の FFN 構造が使用されます。6B (62 億) のパラメータ サイズにより、研究者や個々の開発者が ChatGLM-6B を自分で微調整して展開することも可能になります。
より低い展開しきい値: FP16 の半精度では、ChatGLM-6B は推論のために少なくとも 13GB のビデオ メモリを必要とします.モデルの量子化技術と組み合わせると、この要件はさらに 10GB (INT8) および 6GB (INT4) に削減され、ChatGLM-6B になります。コンシューマー グレードのグラフィックス カードに展開可能。
より長いシーケンス長: ChatGLM-6B は、GLM-10B (シーケンス長 1024) と比較して、シーケンス長が 2048 で、より長い会話とアプリケーションをサポートします。
人間の意図の調整トレーニング: 教師あり微調整、フィードバック ブートストラップ、人間のフィードバックからの強化学習、およびその他の方法を使用して、モデルが最初に人間の指示意図を理解できるようにします。出力形式は表示に便利なマークダウンです。
したがって、ChatGLM-6B は、特定の条件下でより優れた対話および質問応答機能を備えています。ChatGLM-6B には、かなりの数の既知の制限と欠陥もあります。
小さいモデル容量: 6B の小さい容量は、比較的弱いモデル記憶と言語能力を決定します。ChatGLM-6B は、多くの事実に関する知識タスクに直面したときに誤った情報を生成する可能性があり、論理的な問題 (数学、プログラミングなど) を解決することも得意ではありません。
有害な指示または偏ったコンテンツを生成する可能性があります: ChatGLM-6B は、最初は人間の意図に沿った言語モデルにすぎず、有害な偏ったコンテンツを生成する可能性があります。
弱いマルチラウンド対話能力: ChatGLM-6B のコンテキスト理解能力は十分ではありません. 長い応答生成とマルチラウンド対話シナリオに直面すると、コンテキストの損失と理解エラーが発生する可能性があります.
不十分な英語能力: トレーニング中に使用される指示のほとんどは中国語であり、指示のごく一部のみが英語で記載されています。そのため、英語の指示を使用する場合、応答の品質が中国語の指示ほど良くないか、中国語の指示の下での応答と矛盾することさえあります。
誤解を招く: ChatGLM-6B の「自己認識」には問題があり、簡単に誤解されて虚偽の発言をする可能性があります。たとえば、モデルの現在のバージョンが間違っていると、自己認識が逸脱します。モデルは、約 1 兆個の識別子 (トークン) のバイリンガル事前トレーニング、命令の微調整、ヒューマン フィードバック強化学習 (RLHF) を経ていますが、モデルの容量が小さいため、特定の命令の下で悪影響を与える可能性があります。 . 誤解を招く内容。
まとめ
この時点では、作業負荷はまだ低く、執筆は吐き出されています. Google シリーズのいくつかの仕事は、別の記事で完了する必要があります. OpenAI の仕事と同様に、Google も GPT-3 や InstructGPT のベンチマークなどのモデルを作成しており、T5 シリーズの Encoder-Decoder 構造の大規模な言語モデルも含まれており、単なるフォローではありません。
一方、3 月と 4 月には多数のオープンソース ワーカーも花開き、トレーニング データ、モデル、トレーニング メソッドの探索とオープン ソース化など、ChatGPT の適用方向で多くの探索作業が行われました。トレーニングの効率化の方向では、ChatGLM+Lora、LLama+Lora なども登場し、トレーニング コストをさらに削減しています。
この部分の内容も後ほどまとめて紹介・更新していきますので、この間にさらに優れた作品が誕生することを楽しみにしています。記事の内容に誤りがありましたら、訂正や差し替えも大歓迎です〜。
参考内容:
この記事は、多くの論文、ブログ、および「Li Mu で AI を学習する」での関連論文の紹介を参照しています. 一部のコンテンツと図の参照リンクは次のとおりです.
1、https://crfm.stanford.edu/2023/03/13/alpaca.html
2、https://chatglm.cn/ブログ
3、https://crfm.stanford.edu/2023/03/13/alpaca.html
4、https://space.bilibili.com/1567748478/channel/collectiondetail?sid=32744
5、大規模言語モデルの調査
NLP グループに入ります —> NLP 交換グループに参加します(remark nips/emnlp/nlpcc が対応する貢献グループに入ります)
自然言語処理NLPの日々の質の高い論文の解釈、関連する生の情報、AIアルゴリズムの位置付けなどの最新情報を引き続き公開します。
惑星に参加すると、次のものが得られます。
1. 毎日3 ~ 5 個の最新かつ最高品質の用紙速度測定値を更新します。数秒で、論文の概要、一般的な内容、研究の方向性、pdf のダウンロードなど、論文の一般的な内容を把握できます。
2. 最新の入門および上級学習教材。機械学習、深層学習、NLP などの分野を含みます。
3. NLP 指示の特定の下位区分には、感情分析、関係抽出、ナレッジ グラフ、構文分析、意味分析、機械翻訳、人間とコンピューターの対話、テキスト生成、名前付きエンティティの認識、参照解決、大規模言語モデルが含まれますが、これらに限定されません。、ゼロサンプル学習、スモールサンプル学習、コード生成、マルチモダリティ、知識蒸留、モデル圧縮、AIGC、PyTorch、TensorFlow など。
4. NLP、サーチ、昇進・昇格、CVなどのAI職の1日1~3件の募集情報。模擬面接も可能です。
