これでデータと予算が揃い、大規模なモデルのトレーニングを開始する準備ができたとします.スキルを披露すると、「1日で長安のすべての花を見る」ことはすぐにできそうです.角…ちょっと待って!トレーニングはこの2つの単語の発音ほど単純ではありません.BLOOMのトレーニングを見ると参考になるかもしれません.
近年、言語モデルがどんどん大きくなっていくのが当たり前になってきました。人々は通常、これらの大規模モデル自体の情報が研究のために公開されていないと批判しますが、大規模モデルのトレーニング技術の背後にある知識にはほとんど注意が払われていません。この記事では、 1,760 億個のパラメーターを持つ言語モデルBLOOMを例に、そのようなモデルをトレーニングするためのソフトウェアおよびハードウェア エンジニアリングと技術的なポイントを明らかにし、大規模モデルのトレーニング テクノロジの議論を促進することを目的としています。
まず、1,760 億個のパラメーター モデルをトレーニングするという驚異的な偉業を達成することを可能にした、または後援してくださった企業、個人、およびグループに感謝したいと思います。
次に、ハードウェア構成と主要な技術コンポーネントについて説明します。

プロジェクトの概要は次のとおりです。
| ハードウェア | 384 個の 80GB A100 GPU |
| ソフトウェア | メガトロン-ディープスピード |
| モデル アーキテクチャ | GPT3に基づく |
| データセット | 59 の言語で 3,500 億語 |
| トレーニングの時間 | 3.5ヶ月 |
スタッフ構成
このプロジェクトは、世界最大の多言語モデルの森に立つモデルをトレーニングするだけでなく、誰でも利用可能 トレーニング結果へのパブリック アクセスは、ほとんどの人の夢を実現します。
この記事では、モデル トレーニングのエンジニアリング面に焦点を当てます。BLOOM の背後にあるテクノロジの最も重要な部分のいくつかは、専門知識を共有し、コーディングとトレーニングを支援してくれる人々や企業です。
主に 6 つのグループに感謝する必要があります。
- HuggingFace の BigScience チームは、6 人以上のフルタイムの従業員をトレーニングの研究と運営に専念させ、ジャン ゼイのコンピューター以外のすべてのインフラストラクチャを提供または払い戻しました。
- DeepSpeed を開発し、後に Megatron-LM と統合した Microsoft DeepSpeed チームの開発者は、プロジェクトの要件を調査するのに数週間を費やし、トレーニングの前とトレーニング中に多くの実用的なアドバイスを提供しました。
- Megatron-LM を開発した NVIDIA Megatron-LM チームは、私たちの多くの質問に喜んで答え、最高の使用法に関するアドバイスを提供してくれました。
- Jean Zay スーパーコンピューターを管理する IDRIS/GENCI チームは、このプロジェクトに多大な計算能力と強力なシステム管理サポートを提供しました。
- PyTorch チームは、残りのソフトウェアのベースとなる強力なフレームワークを作成し、トレーニングの準備、いくつかのバグの修正、および依存する PyTorch コンポーネントのトレーニングの使いやすさの改善において非常に協力的でした。
- BigScience エンジニアリング ワーキング グループ ボランティア
プロジェクトのエンジニアリング面に貢献した優秀な人々の名前をすべて挙げるのは難しいので、Hugging Face 以外で、過去 14 か月にわたってプロジェクトのエンジニアリングの基礎を築いた主要な人々の名前をいくつか挙げておきます。
Olatunji Ruwase、Deepak Narayanan、Jeff Rasley、Jared Casper、Samyam Rajbhandari、Rémi Lacroix
また、従業員がこのプロジェクトに貢献することを許可したすべての企業にも感謝します。
概要
BLOOM のモデル アーキテクチャは GPT3 と非常によく似ていますが、いくつかの改善点があります。これについては、このホワイト ペーパーで後述します。
このモデルは、GENCI が管理し、フランス国立科学研究センター (CNRS) の国立コンピューティング センターである IDRIS にインストールされた、フランス政府が資金提供したスーパーコンピューター、ジャン ゼイでトレーニングされました。トレーニングに必要な計算能力は、GENCI によってこのプロジェクトに惜しみなく寄付されています (寄付番号 2021-A0101012475)。
トレーニング ハードウェア:
- GPU: 384 NVIDIA A100 80GB GPU (48 ノード) + 32 スペア GPU
- ノードあたり 8 つの GPU、4 つの NVLink カード間相互接続、4 つの OmniPath リンク
- CPU: AMD EPYC 7543 32 コア プロセッサ
- CPUメモリ:ノードあたり512GB
- GPU メモリ: ノードあたり 640 GB
- ノード間接続: Omni-Path Architecture (OPA) ネットワーク カードが使用され、ネットワーク トポロジはノンブロッキング ファット ツリー
- NCCL - 通信ネットワーク: 完全に専用のサブネットワーク
- ディスク IO ネットワーク: 他のノードおよびユーザーと共有される GPFS
チェックポイント:
- 主なチェックポイント
- 各チェックポイントには、精度が fp32 のオプティマイザー状態と精度が bf16+fp32 の重みが含まれており、2.3TB のストレージ スペースを占有します。bf16 の重量だけを保存すると、329GB のストレージ スペースしか占有されません。
データセット:
- 1.5 TB の大幅に重複排除およびクリーンアップされた 46 言語のテキストを 350B トークンに変換
- モデルの語彙には 250,680 個のトークンが含まれています
- 詳細については、The BigScience Corpus A 1.6TB Composite Multilingual Datasetを参照してください。
176B BLOOM モデルのトレーニングは、2022 年 3 月から 7 月までに約 3.5 か月 (約 100 万計算時間) かかりました。
メガトロン-ディープスピード
176B BLOOM モデルは、次の 2 つの主要な手法を組み合わせたMegatron-DeepSpeedを使用してトレーニングされます。
- メガトロンディープスピード:
- DeepSpeedは、分散トレーニングをシンプルかつ効率的かつ効果的にするディープ ラーニング最適化ライブラリです。
- Megatron-LM は、NVIDIA の応用深層学習研究チームによって開発された、大規模で強力なトランスフォーマー モデル フレームワークです。
DeepSpeed チームは、DeepSpeed ライブラリの ZeRO シャーディングと Pipeline Parallelism を Megatron-LM の Tensor Parallelism と組み合わせることで、3D 並列ベースのスキームを開発しました。各コンポーネントの詳細については、以下の表を参照してください。
BigScience のMegatron-DeepSpeed は、元のMegatron-DeepSpeedコード ベースに基づいており、かなりの数のコードが追加されていることに注意してください。
次の表は、BLOOM のトレーニング時に使用する 2 つのフレームワークのそれぞれのコンポーネントを示しています。
| コンポーネント | ディープスピード | メガトロンLM |
|---|---|---|
| ゼロデータパラレル | はい | |
| テンソル並列 | はい | |
| パイプライン パラレル | はい | |
| BF16 オプティマイザー | はい | |
| CUDA 融合カーネル関数 | はい | |
| データローダー | はい |
Megatron-LM と DeepSpeed の両方がパイプライン化された並列処理と BF16 オプティマイザの実装を持っていることに注意してください。ただし、ZeRO に統合されているため、DeepSpeed の実装を使用します。
Megatron-DeepSpeed は 3D 並列処理を実現し、大規模なモデルを非常に効率的な方法でトレーニングできるようにします。3D コンポーネントとは何かについて簡単に説明しましょう。
- データ並列処理 (DP) - 同じセットアップとモデルが複数回複製され、それぞれに異なるデータのコピーが毎回供給されます。処理は並行して行われ、各トレーニング ステップの最後にすべての共有が同期されます。
- Tensor Parallelism (TP) - 各テンソルはチャンクに分割されるため、テンソル全体が単一の GPU に存在するのではなく、テンソルの各スライスが割り当てられた GPU に存在します。処理中、各シャードは別々の GPU で個別に並列処理され、結果はステップの最後に同期されます。これは、水平に行われるため、水平並列処理と呼ばれます。
- Pipeline Parallelism (PP) - モデルは、1 つ以上のモデル レイヤーのみが 1 つの GPU に配置されるように、複数の GPU にわたって垂直方向に (レイヤーごとに) 分割されます。各 GPU は、パイプラインのさまざまなステージを並行して処理し、バッチの一部を処理します。
- Zero Redundancy Optimizer (ZeRO) - TP と同様にテンソル シャーディングも実行しますが、テンソル全体が順方向または逆方向の計算に間に合うように再構築されるため、モデルの変更は必要ありません。また、限られた GPU メモリを補うために、さまざまなオフロード手法もサポートしています。
データ並列処理
数個の GPU しか持たないほとんどのユーザーは、DistributedDataParallel対応するPyTorch ドキュメントである (DDP) に精通しているでしょう。このアプローチでは、モデルは各 GPU に完全にレプリケートされ、すべてのモデルは反復ごとに状態を相互に同期します。この方法では、より多くの GPU リソースを投資することで、トレーニングを高速化し、問題を解決できます。ただし、モデルが単一の GPU に適合する場合にのみ機能するという制限があります。
ゼロデータパラレル
次の図は、ZeRO データの並列処理をうまく表しています (この)。
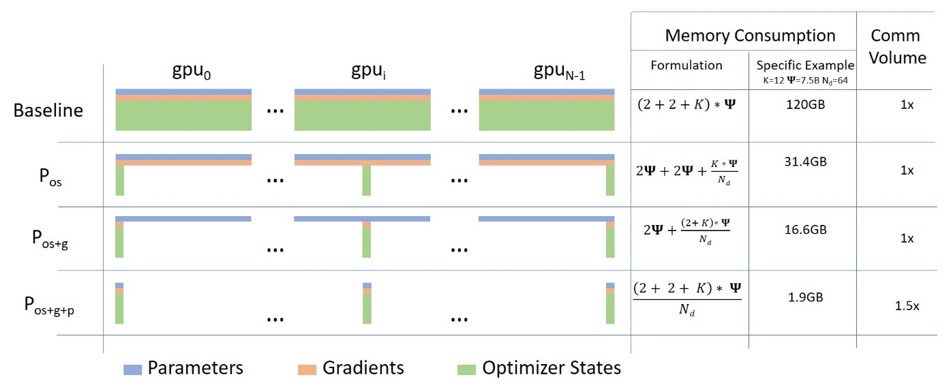
割と背が高くて、理解に集中するのは難しいかもしれませんが、実はコンセプトはとてもシンプルです。これは、各 GPU が完全なモデル パラメーター、勾配、およびオプティマイザーの状態をレプリケートする代わりに、各 GPU がその一部のみを格納することを除いて、通常の DDP です。後続の実行中に、特定のレイヤーの完全なレイヤー パラメーターが必要な場合、すべての GPU が同期して、欠落しているピースを相互に提供します。それ以上のものはありません。
このコンポーネントは DeepSpeed によって実装されます。
テンソル並列
Tensor Parallelism (TP) では、各 GPU は tensor の一部のみを処理し、集計操作は特定の演算子が完全な tensor を必要とする場合にのみトリガーされます。
このセクションでは、 Megatron-LMの論文Efficient Large-Scale Language Model Training on GPU Clustersの概念と図を使用します。
Transformer クラス モデルの主なモジュールは次のとおりです。完全に接続された層nn.Linearとそれに続く非線形活性化層GeLU。
メガトロンの論文の表記法に従って、内積部分を次のように書くことができますY = GeLU (XA)。 ここでX、 と はY入力ベクトルと出力ベクトル、Aは重み行列です。
行列の形式で表現すると、行列の乗算を複数の GPU に分割する方法を簡単に確認できます。
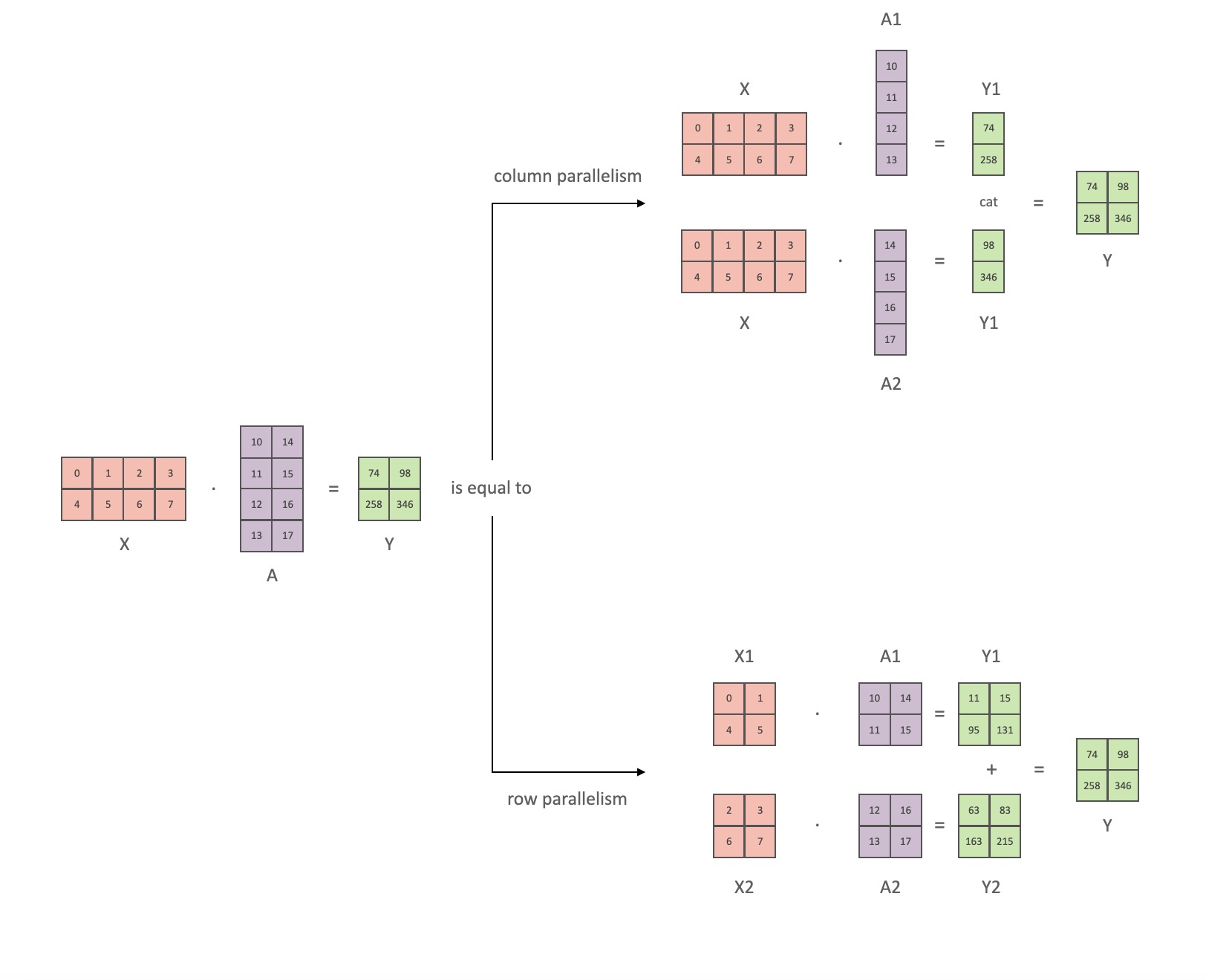
重み行列を列ごとAにNGPU に分割し、行列の乗算を並列XA_1にと、独立して供給できる出力ベクトルにXA_nなります。NY_1、Y_2、…… 、 Y_nGeLU
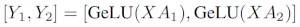
Y行列は列ごとに分割されるため、後続の GEMM に対して行単位の分割スキームを選択できることに注意してください。これにより、追加の通信なしで前のレイヤーの GeLU の出力を直接取得できます。
この原則を使用して、各拆列 - 拆行シーケンス。Megatron-LM の論文の著者は、これについて素晴らしい説明を提供しています。
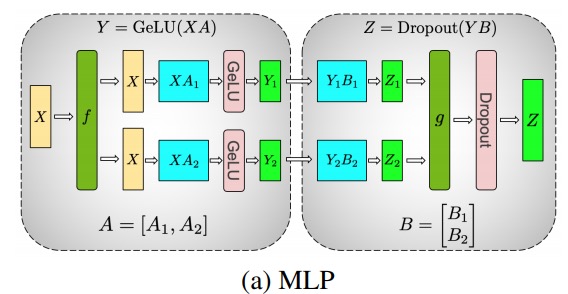
ここfでフォワード パスの恒等演算子とバックワード パスの all reduce と、gフォワード パスの all reduce とバックワード パスの恒等演算子です。
マルチヘッドアテンションレイヤーの並列化は、複数の独立したヘッドにより本質的に並列であるため、さらに簡単です!
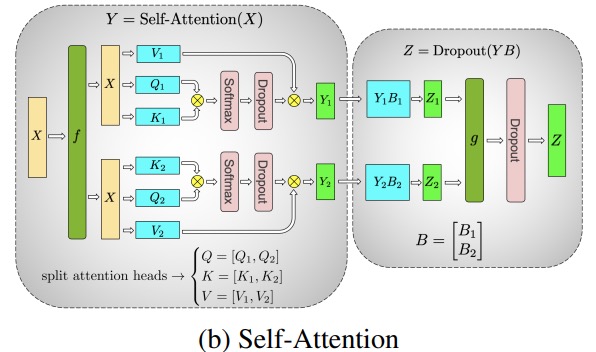
特別な考慮事項: フォワード パスとバックワード パスのレイヤーごとに 2 つの all-reduce があるため、TP にはデバイス間の非常に高速な相互接続が必要です。したがって、非常に高速なネットワークを使用している場合を除き、複数のノードで TP を実行することはお勧めしません。BLOOM をトレーニングするためのハードウェア構成では、ノード間の速度は PCIe よりもはるかに低速です。実際、ノードに 4 つの GPU がある場合、最大 TP 次数 4 の方が適切です。TP 度 8 が必要な場合は、少なくとも 8 つの GPU を備えたノードを使用する必要があります。
このコンポーネントは Megatron-LM によって実装されます。Megatron-LM は最近、テンソル並列機能を拡張し、LayerNorm などの前述のセグメンテーション アルゴリズムを使用するのが困難な演算子のシーケンス並列処理の機能を追加しました。「大規模なトランスフォーマー モデルにおける活性化の再計算の削減」の論文では、この手法の詳細が説明されています。シーケンス並列処理は BLOOM のトレーニング後に開発されたため、BLOOM はこの手法を使用せずにトレーニングされました。
パイプライン パラレル
ナイーブ パイプライン並列処理 (ナイーブ PP) は、モデル レイヤーをグループで複数の GPU に分散し、1 つの大きな複合 GPU であるかのように GPU から GPU にデータを移動するだけです。メカニズムは比較的単純です。メソッドを使用して、.to()目的のと、データがこれらのレイヤーに出入りするたびに、レイヤーはデータをレイヤーと同じデバイスに切り替え、残りは同じままです。
ほとんどのモデルのトポロジをどのように描画するかを覚えていれば、実際にはモデルのレイヤーを垂直に分割するため、これは実際には垂直モデルの並列処理です。たとえば、下の画像が 8 層モデルを示している場合:
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
GPU0 GPU1
GPU0 にレイヤ 0 ~ 3 を配置し、GPU1 にレイヤ 4 ~ 7 を配置して、それを垂直に 2 つの部分に分割します。
これで、レイヤー 0 からレイヤー 1、レイヤー 1 からレイヤー 2、レイヤー 2 からレイヤー 3 にデータが渡されるときは、単一の GPU での通常のフォワード パスと同じです。しかし、レイヤー 3 からレイヤー 4 にデータを渡す必要がある場合、データを GPU0 から GPU1 に転送する必要があるため、通信オーバーヘッドが発生します。参加している GPU が同じ計算ノード (同じ物理マシンなど) にある場合、転送は非常に高速ですが、GPU が異なる計算ノード (複数のマシンなど) にある場合、通信オーバーヘッドははるかに大きくなる可能性があります。
その後、レイヤー 4 から 5 から 6 から 7 は再び通常のモデルのようになり、レイヤー 7 が完了すると、通常、データをラベルのあるレイヤー 0 に送り返す (またはラベルを最後のレイヤーに送る) 必要があります。これで損失を計算でき、オプティマイザを使用してパラメータを更新できます。
質問:
- この方法が単純な? また、その欠点は何ですか? 主な理由は、このスキームでは常に 1 つを除くすべての GPU がアイドル状態になっているためです。したがって、4 つの GPU を使用すると、1 つの GPU のメモリ量がほぼ 4 倍になり、他のリソース (コンピューティングなど) はほとんど役に立たなくなります。デバイス間でデータをコピーするオーバーヘッドを追加します。したがって、単純なパイプラインを使用して 4 つの 6GB カードを並列に使用すると、データ転送のオーバーヘッドがないため、より高速にトレーニングされる 1 つの 24GB カードと同じサイズのモデルを保持できます。ただし、たとえば、40GB のカードがあり、45GB のモデルを実行する必要がある場合は、40GB のカードを 4 枚使用できます (ビデオ メモリを必要とするグラデーションとオプティマイザーの状態があるため、これで十分です)。
- 埋め込みを共有するには、GPU 間でコピーを行ったり来たりする必要がある場合があります。私たちが使用するパイプライン化された並列処理 (PP) は、上記の単純な PP とほぼ同じですが、受信バッチをマイクロバッチに分割し、異なる GPU が同時に計算プロセスに参加できるようにするパイプラインを人為的に作成することで、GPU のアイドリング問題を解決します。
下の図はGPipe paperからのもので、上の部分は単純な PP スキームを表し、下の部分は PP メソッドを表しています。

図の下半分から、PP のデッド ゾーンが少ない (GPU がアイドル状態であることを意味する)、つまり「気泡」が少ないことが簡単にわかります。
図の 2 つのスキームの並列度は 4 です。つまり、パイプラインは 4 つの GPU で構成されています。したがって、F0、F1、F2、および F3 の 4 つの順方向パスと、B3、B2、B1、および B0 の逆方向パスがあります。
PP は、 と呼ばれる、調整するための新しいハイパーパラメーターを導入します块 (chunks)。同じパイプ レベルを介して連続して送信されるデータ ブロックの数を定義します。たとえば、図の下半分には が表示されていますchunks = 4。GPU0 は、チャンク 0、1、2、および 3 (F0,0、F0,1、F0,2、F0,3) で同じフォワード パスを実行し、GPU0 が再び作業を開始する前に、他の GPU が作業を完了するまで待機します。ブロック 3、2、1、および 0 の逆方向パス (B0,3、B0,2、B0,1、B0,0)。
これは概念的に勾配累積ステップ (GAS) と同じであることに注意してください。PyTorch はそれを呼び出し块、DeepSpeed はそれを呼び出しますGAS。
块PP では、マイクロバッチ (MBS) の概念が導入されているためです。DP はグローバル バッチ サイズを小さなバッチ サイズに分割するため、DP 次数が 4 の場合、グローバル バッチ サイズ 1024 は 4 つの小さなバッチ サイズに分割され、各小さなバッチ サイズは 256 (1024/4) になります。块数 (または GAS) が 32 の場合、最終的にマイクロ バッチ サイズは 8 (256/32) になります。各チューブ ステージは、一度に 1 つのマイクロ バッチを処理します。
DP+PP 設定のグローバル バッチ サイズを計算する式はmbs * chunks * dp_degree( 8 * 32 * 4 = 1024) です。
戻って、もう一度写真を見てみましょう。
ナイーブ PP を使用するchunks=1と、非常に非効率的なナイーブ PP になります。また、块数値が、マイクロバッチのサイズが小さくなり、おそらくあまり効率的ではありません。したがって、GPU を最も効率的に使用する块数値。
グラフは、最後のステージがパイプラインの終了を待たforwardなければならないため、並列化できない「デッド」タイム バブルがあることを示しています。backward次に、参加しているすべての GPU が高い同時使用率を達成できるように最適な块数実際にはバブルの数を最小限に抑えることに変わります。
このスケジューリング メカニズムは と呼ばれます全前全后。その他のオプションとして、 TandemとInterleaved Tandem があります。
Megatron-LM と DeepSpeed の両方に PP プロトコルの独自の実装がありますが、Megatron-DeepSpeed は DeepSpeed の他の機能と統合されているため、DeepSpeed 実装を使用します。
ここでのもう 1 つの重要な問題は、単語埋め込み行列のサイズです。一般に、単語埋め込み行列は変換ブロックよりも少ないメモリを必要としますが、250k ボキャブラリを持つ BLOOM の場合、変換ブロックの場合はわずか 4.9 GB であるのに対し、埋め込み層は bf16 重みに 7.2 GB を必要とします。そのため、Megatron-Deepspeed に埋め込み層を変換ブロックとして扱わせる必要がありました。そのため、72 ステージのパイプラインがあり、そのうち 2 つは埋め込み専用です (最初と最後)。これにより、GPU のメモリ消費のバランスをとることができます。これを行わないと、最初と最後のステージで大量の GPU メモリが消費され、GPU メモリの使用量の 95% が非常に少なくなるため、トレーニングは非常に非効率的になります。
DP+PP
以下に示すように、 DeepSpeed Pipeline Parallel Tutorialには、DP と PP を組み合わせる方法を示す図があります。
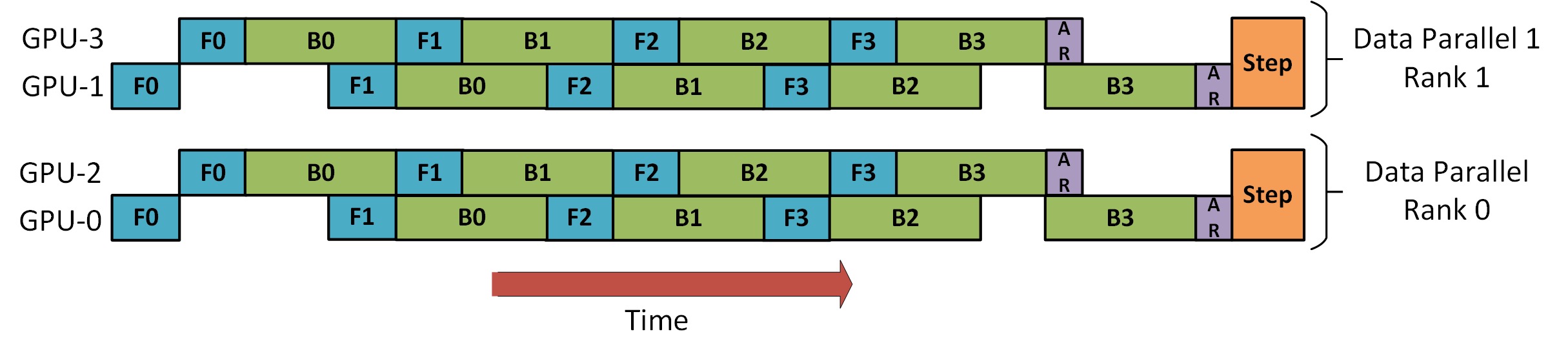
ここで理解しておくべき重要なことは、DP ランク 0 は GPU2 を認識できず、DP ランク 1 は GPU3 を認識できないということです。DP の場合、GPU 0 と 1 のみがあり、データはそれらに供給されます。GPU0 は PP を使用して、その負荷の一部を GPU2 に「密かに」オフロードします。同様に、GPU1 も GPU3 から支援を受けます。
次元ごとに少なくとも 2 つの GPU が必要なため、ここでは少なくとも 4 つの GPU が必要です。
DP+PP+TP
より効率的なトレーニングのために、下の図に示すように、3D 並列処理と呼ばれる PP、TP、および DP を組み合わせることができます。
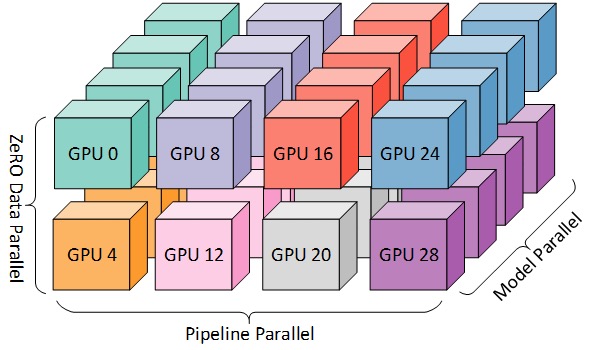
この図は、ブログ投稿3D Parallelism: Scaling to Trillion Parameter Modelsからのもので、これも良い記事です。
次元ごとに少なくとも 2 つの GPU が必要なため、完全な 3D 並列処理には少なくとも 8 つの GPU が必要です。
ゼロDP+PP+TP
DeepSpeed の主な機能の 1 つは、セクション [ZeRO データ パラレル] (#ZeRO- データ パラレル) で説明した DP の超スケーラブルな拡張バージョンである ZeRO です。通常は独立した機能であり、PP や TP は必要ありません。ただし、PP、TPと組み合わせることもできます。
ZeRO-DP を PP (したがって TP) と組み合わせると、通常、ZeRO フェーズ 1 のみが有効になり、オプティマイザーの状態のみが分割されます。ZeRO ステージ 2 では勾配もシャーディングされ、ステージ 3 ではモデルの重みもシャーディングされます。
パイプライン並列処理で ZeRO ステージ 2 を使用することは理論的には可能ですが、パフォーマンスに悪影響を与える可能性があります。各マイクロバッチには、シャーディングの前に勾配を集約するための追加の reduce-scatter 通信が必要です。これにより、重大な通信オーバーヘッドが追加される可能性があります。パイプラインの並列性に応じて、小さなマイクロ バッチを使用し、演算強度 (マイクロ バッチ サイズ) とパイプライン バブルの最小化 (マイクロ バッチの数) の間のトレードオフに焦点を当てます。したがって、通信オーバーヘッドが増加すると、パイプラインの並列処理が損なわれます。
また、PPのため、レイヤーの数は通常よりも少ないため、あまりメモリを節約できません。PP は勾配サイズを縮小した1/PPため、これに基づく勾配スライスは、純粋な DP と比較してメモリをあまり節約しません。
ZeRO ステージ 3 を使用してこのサイズのモデルをトレーニングすることもできますが、DeepSpeed 3D よりも多くの通信を並行して必要とします。1 年前、私たちの環境を注意深く評価した結果、Megatron-DeepSpeed 3D 並列処理が最高のパフォーマンスを発揮することがわかりました。それ以来、ZeRO Phase 3 のパフォーマンスは大幅に改善されており、今日再評価するなら、おそらく Phase 3 を選択するでしょう。
BF16 オプティマイザー
FP16 を使用して巨大な LLM モデルをトレーニングすることはできません。
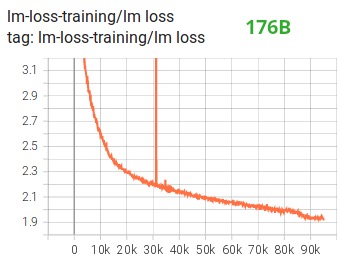
Tensorboardからわかるように、完全に失敗した 104B モデルのトレーニングに数か月を費やすことで、これを実証しました。絶えず発散する lm-loss と戦う過程で、私たちは多くのことを学びました。
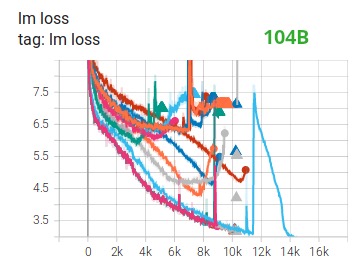
530B モデルをトレーニングした後、Megatron-LM チームと DeepSpeed チームからも同じ提案を受けました。最近リリースされたOPT-175Bも、FP16 で非常にハードなトレーニングを行ったと報告しています。
そのため、1 月に、BF16 フォーマットをサポートする A100 でトレーニングすることを知っていました。Olatunji Ruwase は、BLOOM をトレーニングするための「BF16Optimizer」を開発しました。
このデータ形式に慣れていない場合は、ビット。BF16 形式の鍵は、FP32 と同じ数の指数を持っているため、オーバーフローしませんが、FP16 はしばしばオーバーフローします! FP16 の最大値の範囲は 64k で、小さい数値のみ乗算できます。たとえば250*250=62500、 を実行できますが、 を実行しようとすると255*255=65025、オーバーフローが発生します。これが、トレーニングの問題の主な原因です。これは、ウェイトを小さく保つ必要があることを意味します。損失スケーリングと呼ばれる手法はこの問題を軽減するのに役立ちますが、モデルが非常に大きくなると、FP16 の狭い範囲が依然として問題になる可能性があります。
BF16にはこの問題はありません。簡単に実行できます10_000*10_000=100_000_000。まったく問題ありません。
もちろん、BF16 と FP16 は同じサイズの 2 バイトであるため、フリー ランチはありません。また、BF16 を使用する場合のトレードオフは、精度が非常に低いことです。ただし、トレーニングで使用した確率的勾配降下法とその変形は覚えておく必要があります。この方法は、スタガリングに少し似ています。このステップで完璧な方向が見つからなくても大丈夫です。次のステップで修正します。ステップオウン。
BF16 または FP16 を使用するかどうかにかかわらず、常に FP32 にある重みのコピーがあります - これはオプティマイザによって更新されるものです。したがって、16 ビット形式は計算にのみ使用され、オプティマイザーは FP32 の重みを完全な精度で更新し、次の反復のためにそれらを 16 ビット形式に変換します。
すべての PyTorch コンポーネントは、FP32 で累積を実行するように更新されているため、精度が失われることはありません。
重要な問題は、各マイクロバッチによって処理される勾配が累積されるため、パイプライン並列処理の主な機能の 1 つである勾配累積です。トレーニングの精度のために FP32 で勾配累積を実装することは重要であり、これはまさにBF16Optimizer行われたこと。
他の改善点の中でも特に、BF16 混合精度トレーニングを使用すると、潜在的な悪夢が比較的スムーズなプロセスに変わったと考えられます。これは、次の lm 損失プロットで確認できます。
CUDA 融合カーネル関数
GPU は主に 2 つのことを行います。ビデオメモリにデータを書き込んだり、ビデオメモリからデータを読み込んだり、そのデータに対して計算を実行したりできます。GPU がデータの読み取りと書き込みでビジー状態の場合、GPU のコンピューティング ユニットはアイドル状態になります。GPU を効率的に利用したい場合は、アイドル時間を最小限に抑えたいと考えています。
カーネル関数は、特定の PyTorch 操作を実装する一連の命令です。たとえば、 を呼び出すtorch.addと、 PyTorch スケジューラを通過します。これは、入力テンソルの値とその他の変数に基づいて実行するコードを決定し、最終的にそれを実行します。CUDA カーネルは CUDA を使用してこれらのコードを実装するため、NVIDIA GPU でのみ実行されます。
ここで、GPU を使用して を計算するc = torch.add (a, b); e = torch.max ([c,d])場合、通常、PyTorch は 2 つの別個のカーネルを起動します。1 つはとaの加算を行い、もう 1 つは両方。この場合、GPUはビデオ メモリから合計をフェッチし、加算を実行してから、結果をビデオ メモリに書き戻します。次に、操作を取得して実行し、結果をビデオ メモリに再度書き込みます。bcdabcdmax
これら 2 つの操作を融合する場合、つまり「融合カーネル関数」に入れ、そのカーネルを起動する場合、c中間結果をビデオ メモリに書き込むのではなく、GPU レジスタに保持しd。最終的な計算。これにより、多くのオーバーヘッドが節約され、GPU のアイドリングが防止されるため、操作全体がはるかに効率的になります。
Fusion カーネル関数はまさにそれを行います。これらは主に、複数の個別の計算とビデオ メモリとの間のデータ移動を、データ移動がほとんどない融合計算に置き換えます。さらに、一部のフュージョン カーネルは演算を数学的に変換して、計算の特定の組み合わせをより高速に実行できるようにします。
BLOOM を迅速かつ効率的にトレーニングするには、Megatron-LM が提供するいくつかのカスタム CUDA 融合カーネル関数を使用する必要があります。特に、LayerNorm フュージョン カーネルと、フュージョン スケーリング、マスキング、およびソフトマックス操作のさまざまな組み合わせ用のカーネルがあります。Bias Add は、PyTorch の JIT 関数を通じて GeLU にも統合されています。これらの操作はすべてメモリにバインドされているため、それらを融合して、各ビデオ メモリの読み取り後の計算量を最大化することが重要です。したがって、たとえば、ボトルネックがメモリにある GeLU 操作を実行中に Bias Add を実行しても、実行時間は増加しません。これらのカーネル関数はMegatron-LM コード ライブラリにあります。
データセット
Megatron-LM のもう 1 つの重要な機能は、効率的なデータ ローダーです。最初のトレーニングが開始される前に、各データセットの各サンプルは固定シーケンス長 (BLOOM は 2048) のサンプルに分割され、各サンプルに番号を付けるためのインデックスが作成されます。トレーニング ハイパーパラメータに基づいて、各データセットが参加する必要があるエポックの数を決定し、これに基づいてサンプル インデックスの順序付きリストを作成し、それをシャッフルします。たとえば、データセットに 2 エポックのトレーニングが必要な 10 個のサンプルがある場合、システムは最初にサンプル インデックスを[0, ..., 9, 0, ..., 9]順番シャッフルして、データセットの最終的なグローバル順序を作成します。これは、トレーニングがデータセット全体を単純に反復して繰り返すのではなく、別のサンプルを確認する前に同じサンプルを 2 回確認することを意味することに注意してください。ただし、トレーニングの最後に、モデルは各サンプルを 2 回しか確認しません。これにより、トレーニング全体でスムーズなトレーニング曲線を確保できます。元のデータセットの各サンプルのオフセットを含むこれらのインデックスは、トレーニングが開始されるたびに再計算されないようにファイルに保存されます。最後に、これらのデータセットのいくつかを異なる重みでブレンドして、トレーニングに使用する最終データにすることができます。
LayerNorm を埋め込む
104B モデルの発散を防ぐための取り組みにおいて、最初の単語埋め込み層の後に LayerNorm を追加すると、トレーニングがより安定することがわかりました。
この洞察は、均一な xavier 関数で初期化された LayerNorm を使用した通常の埋め込みである操作を持つbitsandbytesStableEmbeddingの実験から得られます。
ロケーションコード
論文「Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation」に基づいて、通常の位置埋め込みを AliBi に置き換えます。これにより、モデルのトレーニングに使用される入力シーケンスよりも長い入力シーケンスの外挿が可能になります。したがって、長さ 2048 のシーケンスでトレーニングしても、モデルは推論中により長いシーケンスを処理できます。
トレーニングの難しさ
アーキテクチャ、ハードウェア、ソフトウェアが整ったので、2022 年 3 月初旬にトレーニングを開始することができました。しかし、それ以来、すべてが順風満帆だったわけではありません。このセクションでは、遭遇した主な障害のいくつかについて説明します。
トレーニングが始まる前に、理解しなければならない多くの質問があります。特に、小規模ではなく 48 ノードでトレーニングを開始した後にのみ発生したいくつかの問題が見つかりました。たとえば、フレームワークがハングしないようにするCUDA_LAUNCH_BLOCKING=1には、オプティマイザ グループをより小さなグループに分割する必要があります。そうしないと、フレームワークが再びハングします。これらの詳細については、事前トレーニング クロニクルを参照してください。
トレーニング中に発生する主なタイプの問題は、ハードウェア障害です。これは約 400 個の GPU を備えた新しいクラスターであるため、平均して 1 週間に 1 ~ 2 個の GPU 障害が発生しています。3 時間 (100 回の繰り返し) ごとにチェックポイントを保存します。その結果、ハードウェアのクラッシュにより、週平均 1.5 時間のトレーニングが失われています。次に、Jean Zay システム管理者が障害のある GPU を交換し、ノードを復元します。それまでの間、予備のノードを利用できます。
また、PyTorch のデッドロック バグに関連するものや、ディスク容量不足が原因で、5 時間から 10 時間のダウンタイムが何度も発生するさまざまな問題がありました。詳細に興味がある場合は、トレーニング。
このダウンタイムはすべて、このモデルのトレーニングの実現可能性分析で計画されており、それに応じてモデルが消費する適切なモデル サイズとデータ量を選択しました。そのため、これらのダウンタイムの問題があっても、推定時間内にトレーニングを完了することができました. 前述のとおり、完了するまでに約 100 万時間の計算時間が必要です。
もう 1 つの問題は、SLURM がグループで使用するように設計されていないことです。SLURM ジョブは 1 人のユーザーによって所有されており、それらが存在しない場合、グループの他のメンバーは実行中のジョブに対して何もできません。プロセスを開始したユーザーがいなくても、グループ内の他のユーザーが現在のプロセスを終了できるようにする終了スキームがあります。これは、問題の 90% でうまく機能します。SLURM 設計者がこれを読んだ場合は、Unix グループの概念を追加して、グループが SLURM ジョブを所有できるようにしてください。
トレーニングは 24 時間年中無休で行われているため、電話をかけてくれる人が必要ですが、ヨーロッパとカナダの西海岸にスタッフがいるので、誰かがポケットベルを運ぶ必要はなく、お互いをバックアップするのが得意です。もちろん、週末のトレーニングは見守る必要があります。ハードウェア クラッシュからの自動復旧など、ほとんどのことは自動化されていますが、それでも人間の介入が必要になる場合があります。
結論は
トレーニングで最も困難でストレスのかかる部分は、トレーニング開始の 2 か月前です。できるだけ早くトレーニングを開始する必要があり、リソースによって割り当てられた時間が限られているため、ギリギリまで A100 にアクセスできませんでした。土壇場で書かれBF16Optimizerたことを。前のセクションで述べたように、小規模ではなく、48 ノードでトレーニングを開始した後にのみ出現した新しい問題を発見しました。
しかし、それを整理すると、トレーニング自体は驚くほどスムーズに進み、大きな問題は発生しませんでした。ほとんどの場合、見ているのは私たちの 1 人だけで、トラブルシューティングに関与するのは数人だけです。トレーニング中に発生したほとんどのニーズに迅速に対応してくれたジャン・ゼイの経営陣からは、多大なサポートがありました。
全体として、それは非常に強烈でしたが、やりがいのある経験でした.
大規模な言語モデルのトレーニングは依然として困難な作業ですが、この手法を構築して公開することで、他の人が私たちの経験から学ぶことができることを願っています.
リソース
重要なリンク
論文・記事
この記事ですべてを詳細に説明することは不可能です。ここで紹介する手法が好奇心を刺激し、さらに詳しく知りたいと思われる場合は、次の論文をお読みください。
メガトロン-LM:
ディープスピード:
- ZeRO: 1 兆個のパラメーター モデルのトレーニングに向けたメモリの最適化
- ゼロ オフロード: 10 億規模のモデル トレーニングの民主化
- ZeRO-Infinity: 極端なスケールのディープ ラーニングのために GPU メモリの壁を破る
- DeepSpeed: 誰もが利用できる超大規模モデル トレーニング
Megatron-LM と Deepspeedeed の組み合わせ:
アリバイ:
- トレイン ショート、テスト ロング: 線形バイアスによる注意により、入力長の外挿が可能
- GPU 時間が 100 万時間ある場合、どの言語モデルをトレーニングすればよいでしょうか? - 最終的に ALiBi を選択するに至った実験が見つかります。
ビットNバイト:
- ブロック単位の量子化による 8 ビット オプティマイザ(この論文では埋め込み LaynerNorm を使用しましたが、論文の他の部分とその手法も非常に優れています。8 ビット オプティマイザを使用しなかった唯一の理由は、既に使用したことです)オプティマイザのメモリを節約するための DeepSpeed-ZeRO)。
ブログ投稿ありがとう
良い質問をし、記事の読みやすさの改善に協力してくれた次の人々に感謝します (アルファベット順):
- ブリトニー・ミュラー
- ダウエ・キエラ
- ジャレッド・キャスパー
- ジェフ・ラスリー
- ジュリアン・ローネイ
- レアンドロ・フォン・ウェラ
- オマール・サンセヴィエロ
- ステファン・シュヴェーターと
- トーマス・ワン。
この記事のチャートは、主に Chunte Lee によって作成されました。
元の英語のテキスト: https://hf.co/blog/bloom-megatron-deepspeed
原作者:スタス・ベクマン
翻訳者: インテルの深層学習エンジニアである Matrix Yao (Yao Weifeng) は、さまざまなモーダル データへのトランスフォーマー ファミリー モデルの適用と、大規模モデルのトレーニングと推論に取り組んでいます。
校正と植字:zhongdongy (Adong)