Transformer モデルは AI システムの基盤です。「トランスフォーマーの仕組み」の核となる構造図は、すでに無数にあります。
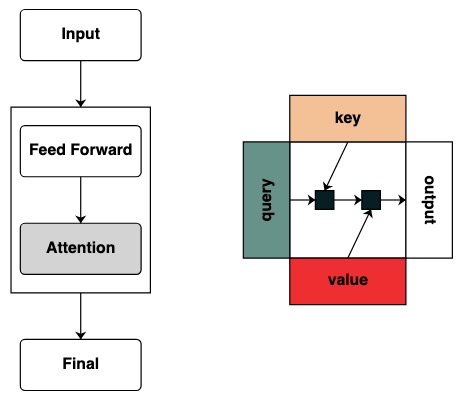
しかし、これらの図は、このモデルを計算するためのフレームワークを直感的に表したものではありません。研究者が Transformer の仕組みに関心を持っている場合、それがどのように機能するかについて直感を持つことは非常に役立ちます。
Thinking Like Transformersという論文では、Transformer クラスのコンピューティング フレームワークが提案されています。これは、Transformer の計算を直接計算して模倣します。RASPプログラミング言語を使用して、各プログラムは特別な Transformer にコンパイルされます。
このブログ投稿では、Python で RASP のバリアント (RASPy) を再現しました。言語はオリジナルとほぼ同じですが、興味深いと思われるいくつかの変更があります。著者の Gail Weiss の作品は、これらの言語を使用して、言語がどのように機能するかを理解するのに役立つ一連の興味深い適切な方法を提供しています。
!pip install git+https://github.com/srush/RASPy
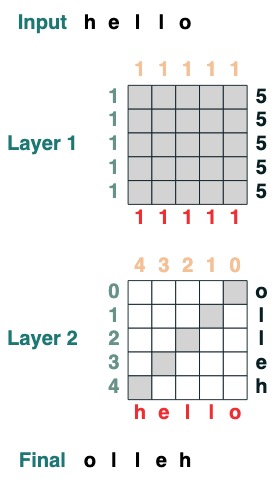
言語自体について説明する前に、Transformers を使用したコーディングがどのようなものかの例を見てみましょう。フリップを計算する、つまり入力シーケンスを逆にするコードを次に示します。コード自体は、2 つの Transformer レイヤーを使用して注意を適用し、数学的計算を行ってこの結果に到達します。
def flip():
length = (key(1) == query(1)).value(1)
flip = (key(length - indices - 1) == query(indices)).value(tokens)
return flip
flip()
記事ディレクトリ
- パート 1: コードとしてのトランスフォーマー
- パート II: Transformer を使用したプログラムの作成
コードとしてのトランスフォーマー
私たちの目標は、Transformer の表現を最小限に抑える一連の計算形式を定義することです。トランスフォーマーの各言語構造とそれに対応するものを類推して説明します。(公式言語仕様については、この記事の下部にある論文の全文へのリンクを参照してください)。
この言語の中核となる単位は、あるシーケンスを同じ長さの別のシーケンスに変換するシーケンス操作です。後で変換と呼びます。
入力
Transformer では、基本層はモデルへのフィードフォワード入力です。通常、この入力には生のトークンと位置情報が含まれます。
コードでは、トークンの機能は、モデルの後にトークンを返す最も単純な変換を表し、デフォルトの入力シーケンスは「hello」です。
tokens

変換で入力を変更したい場合は、input メソッドを使用して値を渡します。
tokens.input([5, 2, 4, 5, 2, 2])

トランスフォーマーとして、これらのシーケンスの位置を直接受け入れることはできません。しかし、場所の埋め込みをシミュレートするために、場所のインデックスを取得できます。
indices

sop = indices
sop.input("goodbye")

フィードフォワード ネットワーク
入力層を通過すると、フィードフォワード ネットワーク層に到達します。Transformer では、このステップで数学的演算をシーケンスの各要素に個別に適用します。
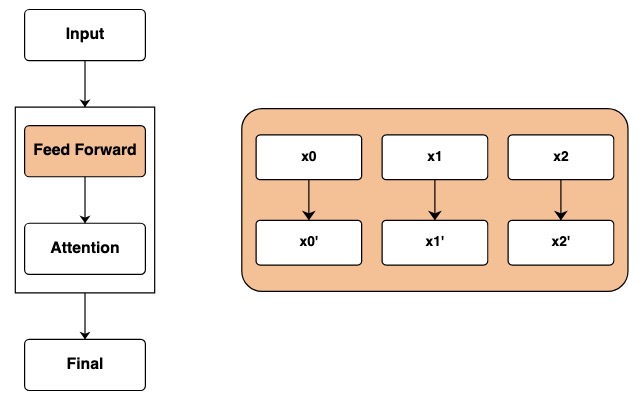
コードでは、変換を計算することでこのステップを表しています。シーケンスの各要素に対して、独立した数学演算が実行されます。
tokens == "l"

結果は、新しい入力が再構築されるとリファクタリングされて計算される新しい変換です。
model = tokens * 2 - 1
model.input([1, 2, 3, 5, 2])

この操作では、複数の変換を組み合わせることができます。たとえば、上記のトークンとインデックスを例にとると、Transformer をクラス化して、複数の情報を追跡できます。
model = tokens - 5 + indices
model.input([1, 2, 3, 5, 2])

(tokens == "l") | (indices == 1)

where同様ifの機能を持つ構造体を提供するなど、変換を簡単に記述できるようにするヘルパー関数をいくつか提供しています。
where((tokens == "h") | (tokens == "l"), tokens, "q")

map文字列を にint変換する。(使用できる単純なニューラル ネットワークによって計算される演算には注意が必要です)
atoi = tokens.map(lambda x: ord(x) - ord('0'))
atoi.input("31234")

関数 (関数) は、これらの変換のカスケードを簡単に説明できます。たとえば、以下は と atoi を適用して 2 を追加する操作です。
def atoi(seq=tokens):
return seq.map(lambda x: ord(x) - ord('0'))
op = (atoi(where(tokens == "-", "0", tokens)) + 2)
op.input("02-13")

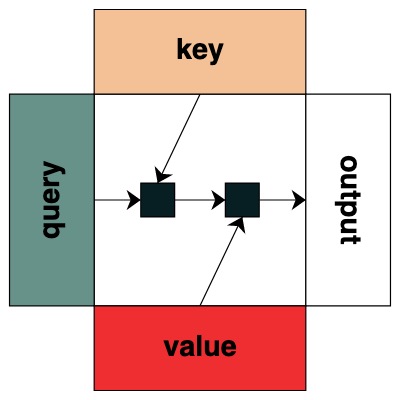
注意フィルター
注意メカニズムを適用し始めると、物事が面白くなり始めます。これにより、シーケンスのさまざまな要素間で情報を交換できます。
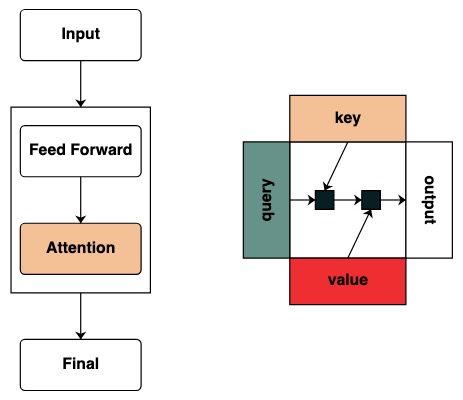
キーとクエリの概念を定義し始めます。キーとクエリは、上記の変換から直接作成できます。たとえば、キーを定義したい場合は、それを と呼びますkey。
key(tokens)

query同じ
query(tokens)

スカラーは または として使用keyできquery、基礎となるシーケンスの長さにブロードキャストします。
query(1)

キーとクエリの間に操作を適用するフィルターを作成します。これは、各クエリが関係するキーを示すバイナリ マトリックスに対応します。Transformers とは異なり、このアテンション マトリックスには重みが追加されません。
eq = (key(tokens) == query(tokens))
eq
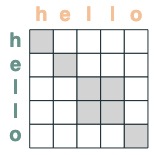
いくつかの例:
- セレクターの一致位置は 1 オフセットされます。
offset = (key(indices) == query(indices - 1))
offset
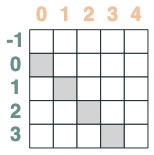
- キーがクエリより前のセレクタ:
before = key(indices) < query(indices)
before
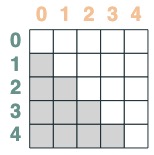
- キーがクエリより後のセレクター:
after = key(indices) > query(indices)
after
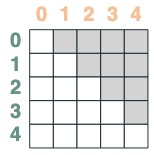
セレクターは、ブール演算を介して組み合わせることができます。たとえば、このセレクターは before と eq を組み合わせており、マトリックスにキーと値のペアを含めることでこれを示しています。
before & eq
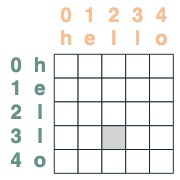
注意メカニズムを使用する
Attentionセレクターを指定すると、集計用の一連の値を提供できます。それらのセレクターによって選択された真理値を累積して集計します。
(注: 元の論文では、彼らは平均集計操作を使用し、平均集計が合計計算を表すことができる巧妙な構造を示しています。RASPy はデフォルトで累積を使用して、シンプルに保ち、断片化を回避します。実際、これは raspy が必要な層の数を過小評価する可能性があります。平均ベースのモデルでは、この数の 2 倍の層が必要になる場合があります)。
集計操作により、ヒストグラムなどの機能を計算できることに注意してください。
(key(tokens) == query(tokens)).value(1)
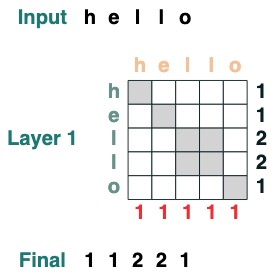
左側にクエリ、上部にキー、下部に値、右側に出力のグラフ構造を視覚的にたどります。
一部のアテンション メカニズム操作では、入力トークンさえ必要ありません。たとえば、シーケンスの長さを計算するには、「すべて選択」アテンション フィルターを作成し、それに値を割り当てます。
length = (key(1) == query(1)).value(1)
length = length.name("length")
length
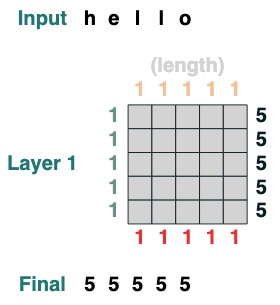
より複雑な例を以下に順を追って示します。(インタビューみたいな感じ)
シーケンスの隣接する値の合計を計算したいので、最初に切り捨てます。
WINDOW=3
s1 = (key(indices) >= query(indices - WINDOW + 1))
s1
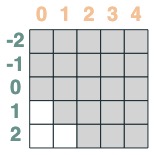
次に、逆方向に切り捨てます。
s2 = (key(indices) <= query(indices))
s2
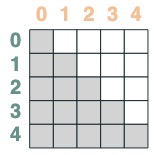
両方が交差します:
sel = s1 & s2
sel
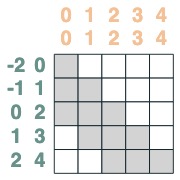
最終集計:
sum2 = sel.value(tokens)
sum2.input([1,3,2,2,2])
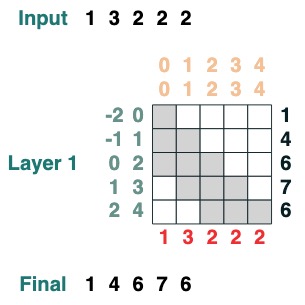
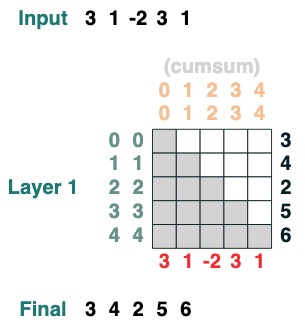
累積合計を計算できる例を次に示します。ここでは、デバッグに役立つように変換に名前を付ける機能を紹介します。
def cumsum(seq=tokens):
x = (before | (key(indices) == query(indices))).value(seq)
return x.name("cumsum")
cumsum().input([3, 1, -2, 3, 1])
層
この言語は、より複雑な変換のコンパイルをサポートしています。また、各操作を追跡してレイヤーを計算します。
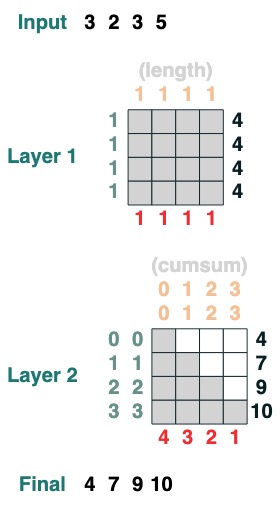
以下は 2 層変換の例です。最初の変換は長さの計算に対応し、2 番目の変換は累積和に対応します。
x = cumsum(length - indices)
x.input([3, 2, 3, 5])
変圧器を使ったプログラミング
このライブラリを使用すると、複雑なタスクを作成できます. Gail Weiss は、このステップを分解するための非常に難しい質問を私に与えました: 任意の長さの数値を追加する Transformer をロードできますか?
例: 文字列 "19492+23919" が与えられた場合、正しい出力をロードできますか?
自分で試してみたい場合は、自分で試すことができるバージョン。
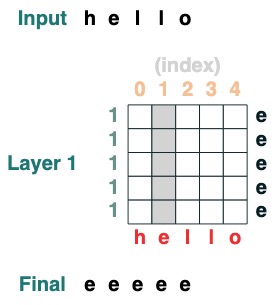
課題 1: 特定のインデックスを選択する
indexiの
def index(i, seq=tokens):
x = (key(indices) == query(i)).value(seq)
return x.name("index")
index(1)
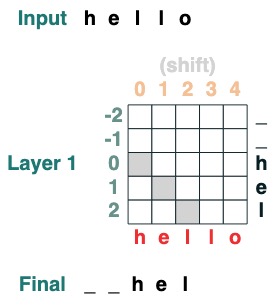
課題 2: コンバージョン
iすべてのトークンをpositionだけ右に移動します。
def shift(i=1, default="_", seq=tokens):
x = (key(indices) == query(indices-i)).value(seq, default)
return x.name("shift")
shift(2)
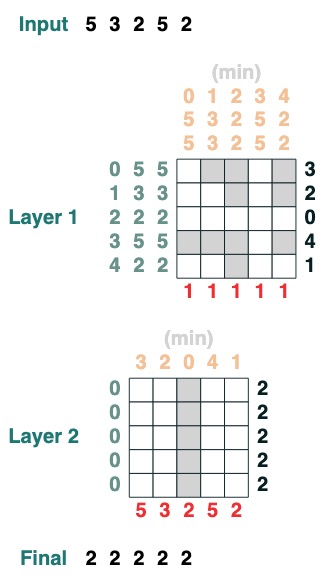
課題 3: 最小限に抑える
シーケンスの最小値を計算します。(このステップは難しくなります。私たちのバージョンでは 2 層のアテンション メカニズムを使用しています)
def minimum(seq=tokens):
sel1 = before & (key(seq) == query(seq))
sel2 = key(seq) < query(seq)
less = (sel1 | sel2).value(1)
x = (key(less) == query(0)).value(seq)
return x.name("min")
minimum()([5,3,2,5,2])
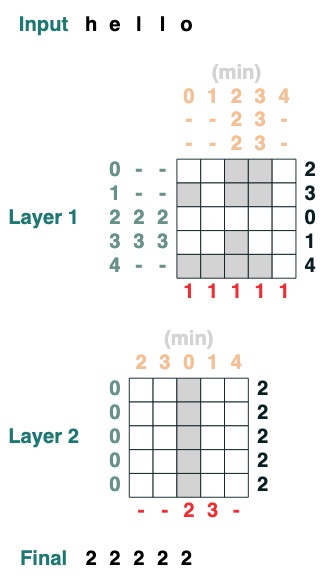
チャレンジ 4: 最初のインデックス
トークン q で最初のインデックスを計算する (2 層)
def first(q, seq=tokens):
return minimum(where(seq == q, indices, 99))
first("l")
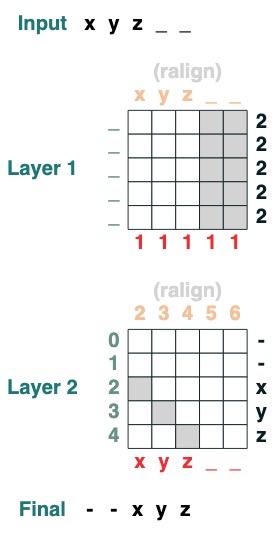
課題 5: 右揃え
パディング シーケンスを右揃えにします。例: " ralign().inputs('xyz___') ='—xyz'" (2 レイヤー)
def ralign(default="-", sop=tokens):
c = (key(sop) == query("_")).value(1)
x = (key(indices + c) == query(indices)).value(sop, default)
return x.name("ralign")
ralign()("xyz__")
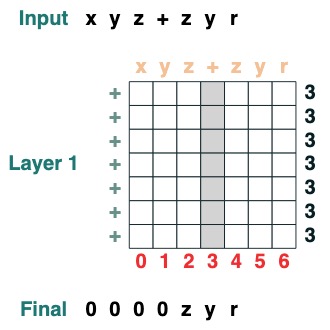
課題 6: 分離
シーケンスをトークン "v" で 2 つの部分に分割し、右揃え (2 レイヤー):
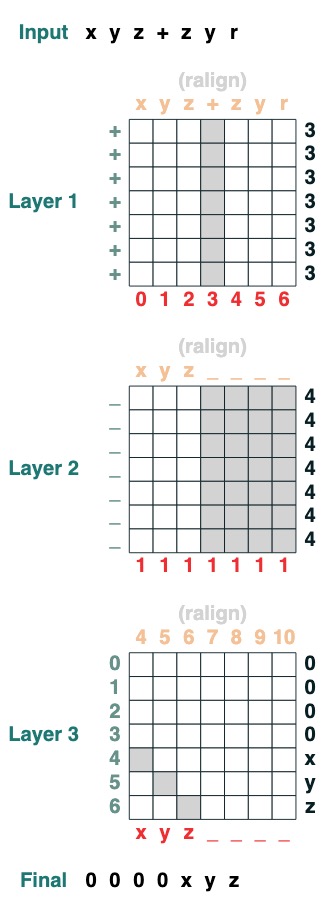
def split(v, i, sop=tokens):
mid = (key(sop) == query(v)).value(indices)
if i == 0:
x = ralign("0", where(indices < mid, sop, "_"))
return x
else:
x = where(indices > mid, sop, "0")
return x
split("+", 1)("xyz+zyr")
split("+", 0)("xyz+zyr")
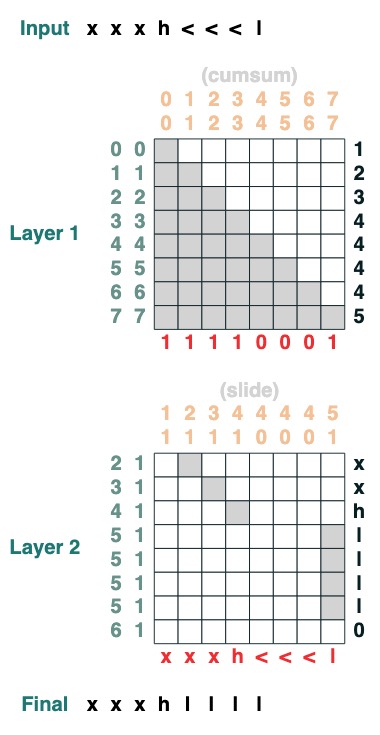
チャレンジ 7: スワイプ
特別なトークン "<" を最も近い "<" 値 (2 レベル) に置き換えます。
def slide(match, seq=tokens):
x = cumsum(match)
y = ((key(x) == query(x + 1)) & (key(match) == query(True))).value(seq)
seq = where(match, seq, y)
return seq.name("slide")
slide(tokens != "<").input("xxxh<<<l")
課題 8: 増やす
2 つの数値の加算を実行します。手順は次のとおりです。
add().input("683+345")
- 2 つの部分に分けます。プラスチックに変換します。参加する
「683+345」 => [0, 0, 0, 9, 12, 8]
- キャリー節を計算します。3 つの可能性: 1 は運ぶ、0 は運ばない、<多分運ぶ。
[0, 0, 0, 9, 12, 8] => 「00<100」
- スライディングキャリー係数
“00<100” => 001100"
- 完全加算
これらは 1 行のコードです。完全なシステムは 6 つの注意メカニズムです。(ゲイルは、十分に注意すれば5でできると言っていますが!)。
def add(sop=tokens):
# 0) Parse and add
x = atoi(split("+", 0, sop)) + atoi(split("+", 1, sop))
# 1) Check for carries
carry = shift(-1, "0", where(x > 9, "1", where(x == 9, "<", "0")))
# 2) In parallel, slide carries to their column
carries = atoi(slide(carry != "<", carry))
# 3) Add in carries.
return (x + carries) % 10
add()("683+345")
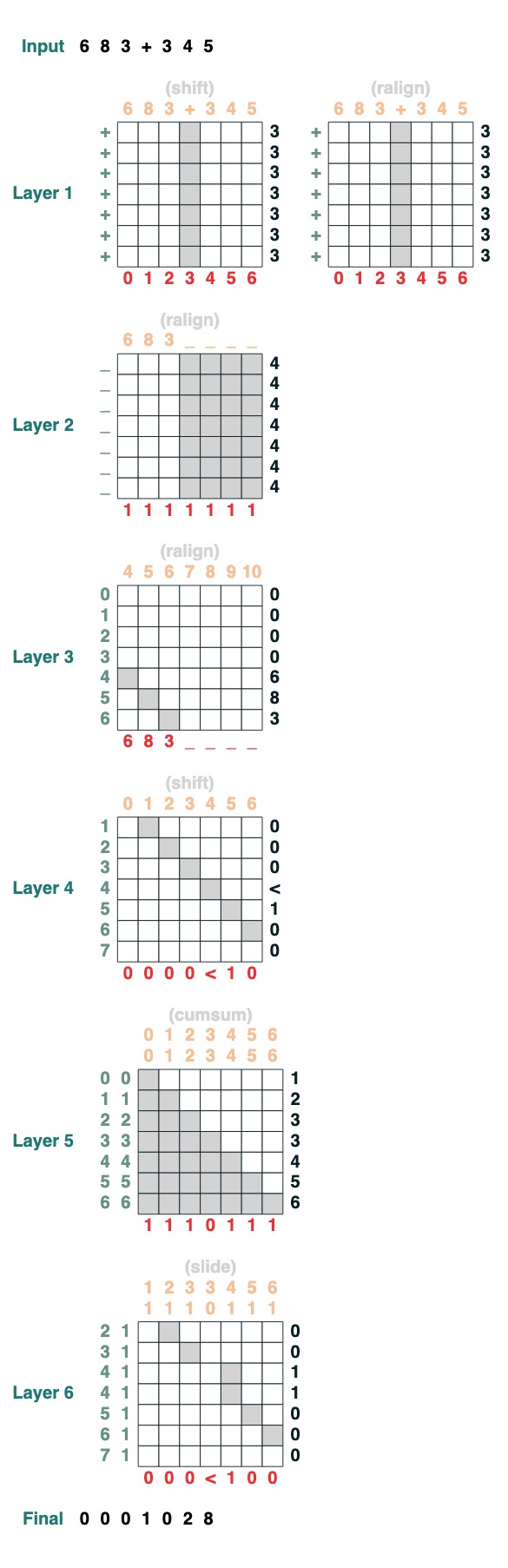
683 + 345
1028
完璧にできました!
参照とテキスト内リンク:
- このトピックに興味があり、詳細を知りたい場合は、次の論文をご覧ください: Thinking Like Transformers
- RASP言語の詳細を学びます
- "Formal Languages and Neural Networks" (FLaNN) に興味がある場合、または興味のある人を知っている場合は、オンライン。
- このブログ投稿には、ライブラリ、ノートブック、およびブログ投稿のコンテンツが含まれています
- このブログ投稿は、Sasha RushとGail Weissの共著です。
<時>
英語原文: Thinking Like Transformers
訳者:innovation64(リー・ヤン)