こんにちは, この号はニューラル ネットワーク内のリカレント ニューラル ネットワークのケースをもたらします. 双方向 LSTM モデルに基づいて, テキスト分類タスクが完了しました. データ セットは kaggle から取得され, 映画レビューのテキスト分類が実行されます.
映画のレビューには、好き嫌いなどの豊かな感情が含まれている場合があります。感情分析はテキスト分類問題です。つまり、特定のテキスト情報によって表現される感情がポジティブな感情に属するかネガティブな感情に属するかを判断するために使用されます。
このプラクティスでは、IMDB 映画レビュー データセットを使用して、双方向 LSTM を使用して映画レビューの感情分析を実行します。
記事ディレクトリ
1. データ処理
IMDB 映画レビュー データセットは、映画レビューに関する古典的なバイナリ分類データセットです。IMDB はスコアに応じて肯定的なレビューと否定的なレビューを除外します. スコアが 7 \ge 7 ≥ 7 の場合, 肯定的なレビューと見なされます. スコアが 4 \le4 ≤ 4 の場合, 否定的なレビューと見なされます. . データセットにはトレーニングセットとテストセットのデータがそれぞれ25,000個含まれており、各データは映画に対するユーザーの実際の評価と、この映画に対する視聴者の感情的傾向の一部です.ディレクトリ構造は次のとおりです.
├── train/
├── neg # 消极数据
├── pos # 积极数据
├── unsup # 无标签数据
├── test/
├── neg # 消极数据
├── pos # 积极数据
test/neg ディレクトリにある映画のレビュー データを選択します。内容は次のとおりです。
「Cover Girl」は、その代表曲「Long Ago and Far Away」を除いて、記憶に残るものはまったくない、つやのない第二次世界大戦のミュージカルです。
LSTM モデルはテキスト データを直接処理することはできず、テキスト内の単語を単語埋め込みと呼ばれるベクトル表現に変換する必要があります。変換効率を向上させるために、通常、テキストの各単語は事前にデジタル ID に変換され、その後、セクション 1 で紹介した方法を使用してベクトル変換が実行されます。そのため、テキスト内の各単語を辞書内のシリアル ID に変換するための辞書 (Vocabulary) を用意する必要があります。同時に、未知の単語を表す特別な単語 [UNK] を設定する必要があります。テキストを処理する際、語彙にない単語に遭遇すると、常に [UNK] として処理されます。
1.1 データ読み込み
元のトレーニングセットとテストセットのデータはそれぞれ 25,000 個あります.このセクションでは、元のテストセットを 2 つの部分に分割し、それぞれを検証セットとテストセットとして使用し、./datasetディレクトリに格納します。次のコードを使用して、データをメモリにロードできます。
import os
# 加载数据集
def load_imdb_data(path):
assert os.path.exists(path)
trainset, devset, testset = [], [], []
with open(os.path.join(path, "train.txt"), "r") as fr:
for line in fr:
sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1)
trainset.append((sentence, sentence_label))
with open(os.path.join(path, "dev.txt"), "r") as fr:
for line in fr:
sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1)
devset.append((sentence, sentence_label))
with open(os.path.join(path, "test.txt"), "r") as fr:
for line in fr:
sentence_label, sentence = line.strip().lower().split("\t", maxsplit=1)
testset.append((sentence, sentence_label))
return trainset, devset, testset
# 加载IMDB数据集
train_data, dev_data, test_data = load_imdb_data("./dataset/")
# 打印一下加载后的数据样式
print(train_data[4])
(「現代の苦闘している都市でのアフリカ系アメリカ人の女性スクルージの前提はインスピレーションを受けましたが、この映画には他に何もありません。ここで、スクルージさんは、大部分が貧困層で従業員と顧客を利用するけちな銀行家です。住んでいる黒い近所. 関係者の善意に疑いの余地はありません. 問題の一部は、物語のルーツがこの映画の都会的な設定にうまく翻訳されていないことであり、スクリプトは更新作業に失敗しています. , 分かち合いと与えることについての絶え間ないメッセージが際限なく繰り返されるため、映画が見慣れた終わりに達する前に、観客はそれに飽きてしまいます. これはいつやめるべきか分からないメッセージ映画です. tyson は緊張しすぎて台詞がわかりにくいところがあります。チャールズ・ディケンズの小説は何度も翻案されているため、非常に関連性の高いメッセージにもかかわらず、新鮮で関連性のあるものにするのに苦労しています。」, '0')
出力結果から、読み込まれた各サンプルには、テキスト文字列とラベルの 2 つの部分が含まれます。
1.2 Dataset クラスの構築
まず、paddle.io.DataSet クラスから継承するデータ管理用の IMDBDataset クラスを作成します。
ここでの入力はテキストシーケンスなので、各単語を語彙内の単語の通し番号 ID に変換し、語彙 ID に従ってこれらの単語に対応する単語ベクトルをクエリする必要があります。セクション 6.1. デジタル ベクトル化の操作では、単語ベクトルを取得した後、後続の計算のためにモデルに入力されます。これは、IMDBDataset クラスの words_to_id メソッドを使用して行うことができます。具体的には、語彙 word2id_dict を使用して、シーケンス内の各単語を対応する番号にマップします。これは、さらに単語ベクトルに変換するのに便利です。シーケンス内の単語が語彙に含まれていない場合、その単語はデフォルトで [UNK] に置き換えられます。words_to_id メソッドは、変換に図 6.14 のようなハッシュ テーブルを使用します。
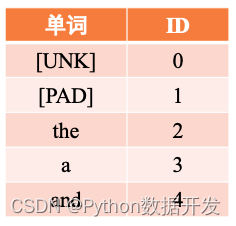
図 6.14 word2id 単語テーブルの例
コードは次のように実装されます。
import paddle
import paddle.nn as nn
from paddle.io import Dataset
from utils.data import load_vocab
class IMDBDataset(Dataset):
def __init__(self, examples, word2id_dict):
super(IMDBDataset, self).__init__()
# 词典,用于将单词转为字典索引的数字
self.word2id_dict = word2id_dict
# 加载后的数据集
self.examples = self.words_to_id(examples)
def words_to_id(self, examples):
tmp_examples = []
for idx, example in enumerate(examples):
seq, label = example
# 将单词映射为字典索引的ID, 对于词典中没有的单词用[UNK]对应的ID进行替代
seq = [self.word2id_dict.get(word, self.word2id_dict['[UNK]']) for word in seq.split(" ")]
label = int(label)
tmp_examples.append([seq, label])
return tmp_examples
def __getitem__(self, idx):
seq, label = self.examples[idx]
return seq, label
def __len__(self):
return len(self.examples)
# 加载词表
word2id_dict= load_vocab("./dataset/vocab.txt")
# 实例化Dataset
train_set = IMDBDataset(train_data, word2id_dict)
dev_set = IMDBDataset(dev_data, word2id_dict)
test_set = IMDBDataset(test_data, word2id_dict)
print('训练集样本数:', len(train_set))
print('样本示例:', train_set[4])
トレーニングセットのサンプル数: 25000
サンプル 例: ([2, 976, 5, 32, 6860, 618, 7673, 8, 2, 13073, 2525, 724, 14, 22837, 18, 164, 416, 8, 10, 24、701、611、1743、7673、7、3、56391、21652、36、271、3495、5、2、11373、4、13244、8、2、2157、350、4、328、4118、12、 48810、52、7、60、860、43、2、56、4393、5、2、89、4152、182、5、2、461、7、11、7321、7730、86、7931、107、72、 2、2830、1165、5、10、151、4、2、272、1003、6、91、2、10491、912、826、2、1750、889、43、6723、4、647、7、2535、 38、39222、2、357、398、1505、5、12、107、179、2、20、4279、83、1163、692、10、7、3、889、24、11、141、118、50、 6、28642、8、2、490、1469、2、1039、98975、24541、344、32、2074、11852、1683、4、29、286、478、22、823、6、5222、2、1490、 6893、883、41、71、3254、38、100、1021、44、3、1700、6、8768、12、8、3、108、11、146、12、1761、4、92295、8、2641、 5、83、49、3866、5352]、0)
1.3 DataLoader のカプセル化
Dataset クラスを構築した後、バッチ データ反復用の対応する DataLoader を構築します。前の章の DataLoader とは異なり、ここの DataLoader は次の 2 つの関数を導入する必要があります。
- 長さの制限: 一部のデータが長すぎて全体的なトレーニング効果に影響を与えないように、シーケンスの長さを特定の範囲内に制御する必要があります。
- 長さのパディング: 通常、ニューラル ネットワーク モデルでは、同じバッチ内のデータのシーケンスの長さが同じである必要がありますが、バッチ処理の場合、通常、異なる長さのシーケンスが同じバッチに配置されるため、シーケンスをパディングする必要があります。
長さの制限については、max_seq_len パラメーターを使用して、長すぎるテキストを切り捨てます。
長さのパディングでは、最初にデータのバッチ内のシーケンスの最大長をカウントし、特別な意味を持たないいくつかのプレースホルダー [PAD] で短いシーケンスを埋め、バッチの最大長まで長さをパディングします。同じバッチのデータを規則的にすることができます。たとえば、次の 2 つの文があるとします。
- 文 1: この映画はくだらないものでした。
- 句子2: 劇場に行く途中で渋滞に巻き込まれた.
上記の 2 つの文を完成させて、次のようにします。
- 句子1: この映画はくだらない [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
- 句子2: 劇場に行く途中で渋滞に巻き込まれた
具体的には、このセクションでは、データを切り捨てて埋めるための collate_fn 関数を定義します. この関数は、コールバック関数として DataLoader に渡すことができます. データのバッチを返す前に、DataLoader はこの関数を呼び出してデータを処理し、処理されたシーケンス データを返します。対応するラベル。
さらに、短いシーケンスを [PAD] プレースホルダーで埋めた後、テキスト分類タスクが実行されると、デフォルトでは [PAD] 位置は必要ないため、変数 seq_lens を使用して非テキストの真の長さを表す必要があります。 - [PAD] シーケンスの位置。seq_lens は、collate_fn 関数がバッチ データを処理するときに取得して返すことができます。RunnerV3 クラスはデフォルトで入力データとラベル情報に従ってデータを取得するため、RunnerV3 がデータを解析しやすくするために、入力データとしてシーケンス データとシーケンス長をタプルとして返す必要があることに注意してください。
コードは次のように実装されます。
from functools import partial
def collate_fn(batch_data, pad_val=0, max_seq_len=256):
seqs, seq_lens, labels = [], [], []
max_len = 0
for example in batch_data:
seq, label = example
# 对数据序列进行截断
seq = seq[:max_seq_len]
# 对数据截断并保存于seqs中
seqs.append(seq)
seq_lens.append(len(seq))
labels.append(label)
# 保存序列最大长度
max_len = max(max_len, len(seq))
# 对数据序列进行填充至最大长度
for i in range(len(seqs)):
seqs[i] = seqs[i] + [pad_val] * (max_len - len(seqs[i]))
return (paddle.to_tensor(seqs), paddle.to_tensor(seq_lens)), paddle.to_tensor(labels)
collate_fn 関数の機能をテストするためにデータのバッチをカスタマイズしましょう. ここでは max_seq_len が 5 であると仮定し、シーケンス長がそれぞれ 6 と 3 の 2 つのデータを定義し、それらを collate_fn 関数に渡します。
max_seq_len = 5
batch_data = [[[1, 2, 3, 4, 5, 6], 1], [[2,4,6], 0]]
(seqs, seq_lens), labels = collate_fn(batch_data, pad_val=word2id_dict["[PAD]"], max_seq_len=max_seq_len)
print("seqs: ", seqs)
print("seq_lens: ", seq_lens)
print("labels: ", labels)
seqs: Tensor(shape=[2, 5], dtype=int64, place=CPUPlace, stop_gradient=True,
[[1, 2, 3, 4, 5],
[2, 4, 6, 0, 0]])
seq_lens: Tensor(shape=[2], dtype=int64, place=CPUPlace, stop_gradient=True,
[5, 3])
ラベル: Tensor(shape=[2], dtype=int64, place=CPUPlace, stop_gradient=True,
[1, 0])
元のシーケンスの長さ 6 のシーケンスは 5 に切り捨てられ、元のシーケンスの長さ 3 のシーケンスは 5 にパディングされ、非[PAD]シーケンス長が返されることがわかります。
次に、コールバック関数として collate_fn を DataLoader に渡します.データのバッチが返されると、collate_fn 関数を介してデータのバッチを処理できます。ここで、collate_fn 関数のキーワード パラメータが部分関数を介して設定され、新しい関数オブジェクトが collate_fn として返されることに注意してください。
DataLoader を使用してバッチでデータを反復処理する場合、最後のバッチのデータ サンプルの数が、batch_size を設定するのに十分でない場合があります. パラメータ drop_last を使用して、最後のバッチのデータを破棄するかどうかを決定できます.
max_seq_len = 256
batch_size = 128
collate_fn = partial(collate_fn, pad_val=word2id_dict["[PAD]"], max_seq_len=max_seq_len)
train_loader = paddle.io.DataLoader(train_set, batch_size=batch_size, shuffle=True, drop_last=False, collate_fn=collate_fn)
dev_loader = paddle.io.DataLoader(dev_set, batch_size=batch_size, shuffle=False, drop_last=False, collate_fn=collate_fn)
test_loader = paddle.io.DataLoader(test_set, batch_size=batch_size, shuffle=False, drop_last=False, collate_fn=collate_fn)
2. モデル構築
このプラクティスのモデル全体の構造を図 6.15 に示します。
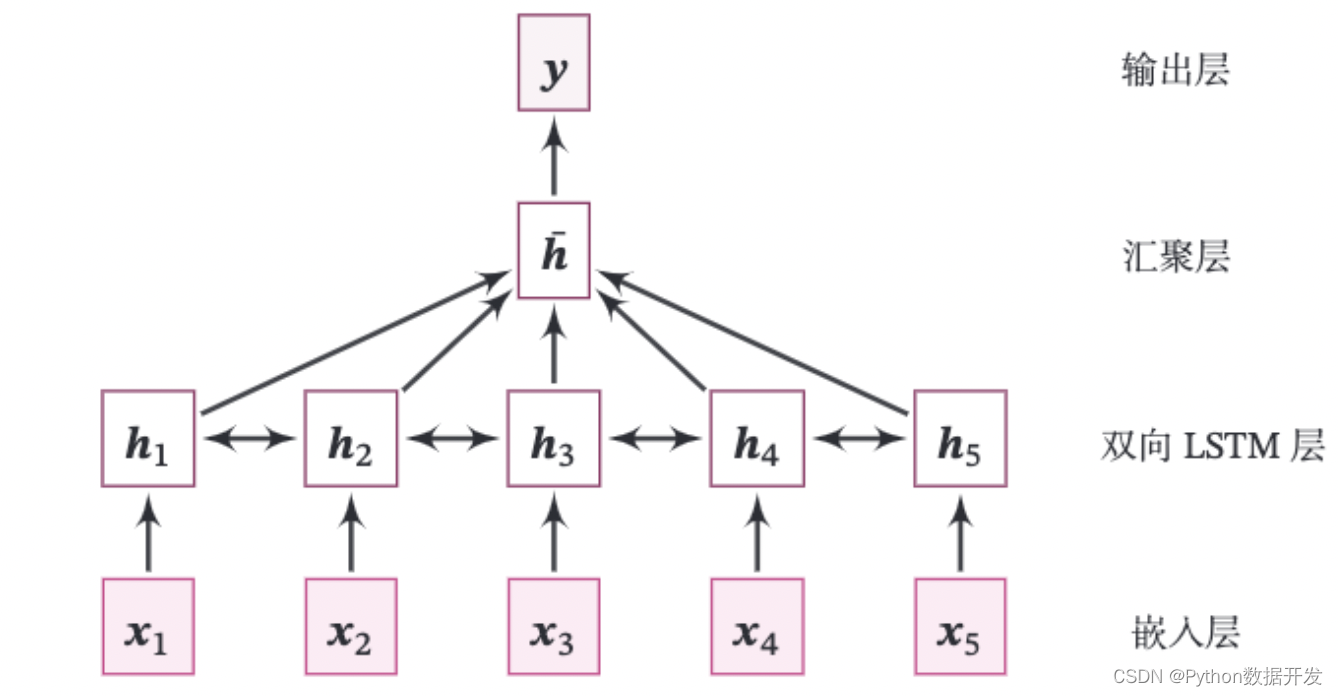
図 6.15 双方向 LSTM に基づくテキスト分類モデルの構造
次の部分で構成されます。
(1) 埋め込み層: 入力シーケンスの数値をベクトル化します。つまり、各数値をベクトルにマップします。これは、パドル API: paddle.nn.Embedding を使用して直接行われます。
class paddle.nn.Embedding(num_embeddings, embedded_dim, padding_idx=なし, sparse=False, weight_attr=なし, name=なし)
API には 2 つの重要なパラメーターがあります。num_embeddings は、使用する埋め込みの数を示します。embedded_dim は、埋め込みベクトルの次元を表します。
paddle.nn.Embedding は、[num_embeddings, embedded_dim] に従って、2 次元の埋め込み行列を自動的に構築します。パラメーター padding_idx は、シーケンスを完了するために使用されるプレースホルダー [PAD] に対応する語彙 ID を参照します. トレーニング プロセス中にこの ID が検出されると、そのパラメーターと対応する勾配は 0 で埋められます. 実装を簡単にするために、通常は [PAD] を語彙の最初に置きます。つまり、対応する ID は 0 です。
(2) 双方向 LSTM レイヤー: 一連のベクトルを受け取り、再帰ユニットをそれぞれ順方向と逆方向で更新します。ここでは、パドル API: paddle.nn.LSTM を直接使用して完了します。LSTM を定義するときにパラメータ方向を双方向に設定するだけでよく、双方向 LSTM を直接使用できます。
考察: 双方向 LSTM を実装する場合、シーケンス補完を実行する必要があるため、逆 LSTM を計算するときに、プレースホルダー [PAD] が LSTM パラメータ勾配の更新に影響するかどうか。もしそうなら、どのように影響を取り除くのですか?
注: 双方向 LSTM を実装するために paddle.nn.LSTM を呼び出す場合、データのバッチの実際の長さを渡すことができます。 [PAD] ] position はゼロ ベクトルを返します。
(3) 集約層: 双方向 LSTM 層のすべての位置での隠れ状態は、文全体の表現として平均化されます。
(4) 出力層: 出力層、出力分類の確率。ここで直接 paddle.nn.Linear を呼び出して完了できます。
ハンズオン演習 6.5 : セクション 6.3.1.1 の LSTM 演算子を改善して、1 つのバッチで異なる長さのシーケンス サンプルをサポートします。
上記モデルの埋め込み層、双方向 LSTM 層、線形層はすべて Paddle API を直接呼び出すことで実装できますが、ここでは集約層演算子のみを実装する必要があります。フライング パドルの組み込み LSTM は、バッチ データの真の長さを渡した後、[PAD] 位置にゼロ ベクトルを返しますが、アグリゲーション レイヤーと、シーケンス データ、このセクションでは、アグリゲーション レイヤーの実装では、[PAD] 位置がマスクされます。
集約層演算子
プーリング層演算子は、文全体の表現として、双方向 LSTM 層のすべての位置で隠れ状態を平均化します。Here we implement the AveragePooling operator for the aggregate of hidden states. まず、シーケンス長ベクトルを使用してマスク (Mask) 行列を生成し、これを使用してテキスト シーケンス内の [PAD] 位置のベクトルをマスクします。シーケンスのベクトルが追加されます. 次に、平均を取ります. コードは次のように実装されます。
上記のモジュールを組み合わせると、コードの実装は次のようになります。
class AveragePooling(nn.Layer):
def __init__(self):
super(AveragePooling, self).__init__()
def forward(self, sequence_output, sequence_length):
sequence_length = paddle.cast(sequence_length.unsqueeze(-1), dtype="float32")
# 根据sequence_length生成mask矩阵,用于对Padding位置的信息进行mask
max_len = sequence_output.shape[1]
mask = paddle.arange(max_len) < sequence_length
mask = paddle.cast(mask, dtype="float32").unsqueeze(-1)
# 对序列中paddling部分进行mask
sequence_output = paddle.multiply(sequence_output, mask)
# 对序列中的向量取均值
batch_mean_hidden = paddle.divide(paddle.sum(sequence_output, axis=1), sequence_length)
return batch_mean_hidden
モデル概要
上記の演算子は集約され、最終的な分類モデルに結合されます。コードは次のように実装されます。
class Model_BiLSTM_FC(nn.Layer):
def __init__(self, num_embeddings, input_size, hidden_size, num_classes=2):
super(Model_BiLSTM_FC, self).__init__()
# 词典大小
self.num_embeddings = num_embeddings
# 单词向量的维度
self.input_size = input_size
# LSTM隐藏单元数量
self.hidden_size = hidden_size
# 情感分类类别数量
self.num_classes = num_classes
# 实例化嵌入层
self.embedding_layer = nn.Embedding(num_embeddings, input_size, padding_idx=0)
# 实例化LSTM层
self.lstm_layer = nn.LSTM(input_size, hidden_size, direction="bidirectional")
# 实例化聚合层
self.average_layer = AveragePooling()
# 实例化输出层
self.output_layer = nn.Linear(hidden_size * 2, num_classes)
def forward(self, inputs):
# 对模型输入拆分为序列数据和mask
input_ids, sequence_length = inputs
# 获取词向量
inputs_emb = self.embedding_layer(input_ids)
# 使用lstm处理数据
sequence_output, _ = self.lstm_layer(inputs_emb, sequence_length=sequence_length)
# 使用聚合层聚合sequence_output
batch_mean_hidden = self.average_layer(sequence_output, sequence_length)
# 输出文本分类logits
logits = self.output_layer(batch_mean_hidden)
return logits
3. モデルトレーニング
このセクションは、トレーニング用の RunnerV3 に基づいています. まず、モデルのトレーニング用のハイパーパラメーターを指定し、次にモデル、オプティマイザー、損失関数、および評価指標を設定します. 損失関数が使用されpaddle.nn.CrossEntropyLoss、損失関数は内部softmaxで予測結果を計算します. . デジタル予測モデル 出力層の出力は、logitsソフトマックスを使用して正規化する必要はありません. ランナーの関連コンポーネントを定義した後、モデルのトレーニングを実行できます. コードは次のように実装されます。
import time
import random
import numpy as np
from nndl import Accuracy, RunnerV3
np.random.seed(0)
random.seed(0)
paddle.seed(0)
# 指定训练轮次
num_epochs = 3
# 指定学习率
learning_rate = 0.001
# 指定embedding的数量为词表长度
num_embeddings = len(word2id_dict)
# embedding向量的维度
input_size = 256
# LSTM网络隐状态向量的维度
hidden_size = 256
# 实例化模型
model = Model_BiLSTM_FC(num_embeddings, input_size, hidden_size)
# 指定优化器
optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, beta1=0.9, beta2=0.999, parameters= model.parameters())
# 指定损失函数
loss_fn = paddle.nn.CrossEntropyLoss()
# 指定评估指标
metric = Accuracy()
# 实例化Runner
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 模型训练
start_time = time.time()
runner.train(train_loader, dev_loader, num_epochs=num_epochs, eval_steps=10, log_steps=10, save_path="./checkpoints/best.pdparams")
end_time = time.time()
print("time: ", (end_time-start_time))
[トレーニング] エポック: 0/3、ステップ: 0/588、損失: 0.69294
トレーニング セットと検証セットの損失画像と、トレーニング中の検証セットの精度画像をプロットします。
from nndl import plot_training_loss_acc
# 图像名字
fig_name = "./images/6.16.pdf"
# sample_step: 训练损失的采样step,即每隔多少个点选择1个点绘制
# loss_legend_loc: loss 图像的图例放置位置
# acc_legend_loc: acc 图像的图例放置位置
plot_training_loss_acc(runner, fig_name, fig_size=(16,6), sample_step=10, loss_legend_loc="lower left", acc_legend_loc="lower right")
図 6.16 は、トレーニング中のテキスト分類モデルの損失曲線と検証セットでの精度曲線を示しています. 損失イメージでは、実線はトレーニング セットでの損失の変化を表し、破線は検証での損失の変化を表します.トレーニング プロセスが進行するにつれて、トレーニング セットの損失が減少し続け、約 200 ステップ後に検証セットの損失が増加し始めることがわかります.これは、トレーニング プロセス中にオーバーフィッティングが発生したためです.トレーニング プロセス中にそれを保存することを選択できます. 検証セットで最高のパフォーマンスを持つモデルは、この問題を解決します. 精度曲線からわかるように、最初に検証セットでの精度率が大幅に増加し、次に約 200 ステップ後、精度率は向上せず、オーバーフィッティングが原因である 要因の組み合わせにより、検証セットの精度はわずかに低下します。
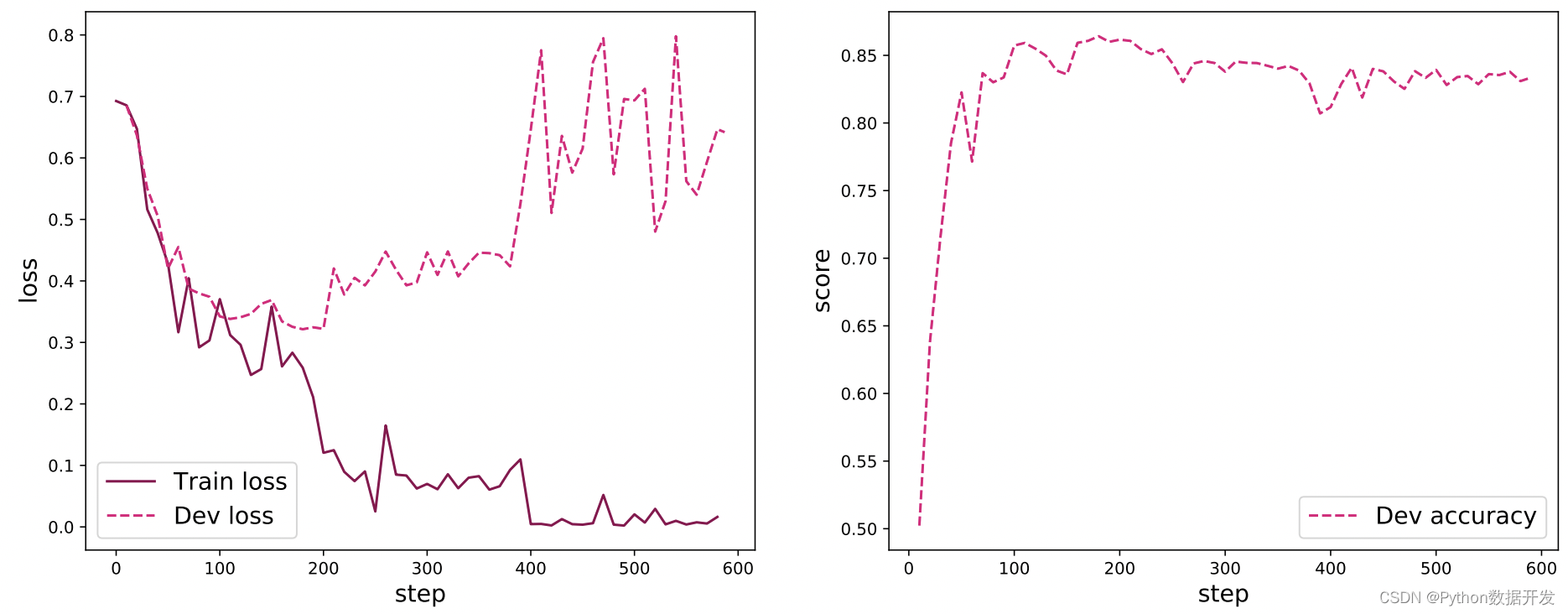
図 6.16 テキスト分類モデルの学習損失の変化図
4. モデル評価
トレーニング中に最高のパフォーマンスを発揮したモデルをロードしてから、テスト セットをテストに使用します。
model_path = "./checkpoints/best.pdparams"
runner.load_model(model_path)
accuracy, _ = runner.evaluate(test_loader)
print(f"Evaluate on test set, Accuracy: {
accuracy:.5f}")
5. モデル予測
任意の文が与えられた場合、トレーニング済みのモデルを使用して、文に含まれる感情の極性を予測します。
id2label={
0:"消极情绪", 1:"积极情绪"}
text = "this movie is so great. I watched it three times already"
# 处理单条文本
sentence = text.split(" ")
words = [word2id_dict[word] if word in word2id_dict else word2id_dict['[UNK]'] for word in sentence]
words = words[:max_seq_len]
sequence_length = paddle.to_tensor([len(words)], dtype="int64")
words = paddle.to_tensor(words, dtype="int64").unsqueeze(0)
# 使用模型进行预测
logits = runner.predict((words, sequence_length))
max_label_id = paddle.argmax(logits, axis=-1).numpy()[0]
pred_label = id2label[max_label_id]
print("Label: ", pred_label)
6. まとめ
この章では、実践を通じて、再帰型ニューラル ネットワークの基本概念、ネットワーク構造、および長期的な依存関係の理解を深めます。数値総和タスクを構築し、SRN および LSTM モデルを手動で実装して、数値総和タスクでの記憶能力を比較します。実践的な部分では、テキスト分類タスクに双方向 LSTM モデルを利用します: IMDB ムービー レビュー感情分析、および埋め込みレイヤーを介してテキスト データをベクトル表現に変換する方法を学習します。