
マルチサンプルドロップアウトはドロップアウトの変形であり、この方法は通常のドロップアウトよりも一般化能力が高く、同時にモデルのトレーニング時間を短縮できます。XMuli-sampleDropoutは、トレーニングセットと検証セットのエラー率と損失を減らすこともできます。ペーパー番号arXIV:1905.09788,2019を参照してください。
1説明例
この例では、Muli-sampleDropoutメソッドを使用して、グラフ畳み込みモデルのトレーニング時間を短縮します。
1.1マルチサンプルドロップアウト方式/マルチサンプルジョイントドロップアウト
最適化は、Dropoutが破棄するノードをランダムに選択する部分で実行されます。つまり、Dropoutによってランダムに選択されたノードのグループは、ランダムに選択された複数のノードのグループになり、ノードの各グループの結果とバックプロパゲーションの損失値は次のようになります。計算されます。最後に、図9-19に示すように、複数のグループの計算された損失値が平均化されて、ネットワークの更新に使用される最終的な損失値が取得されます。
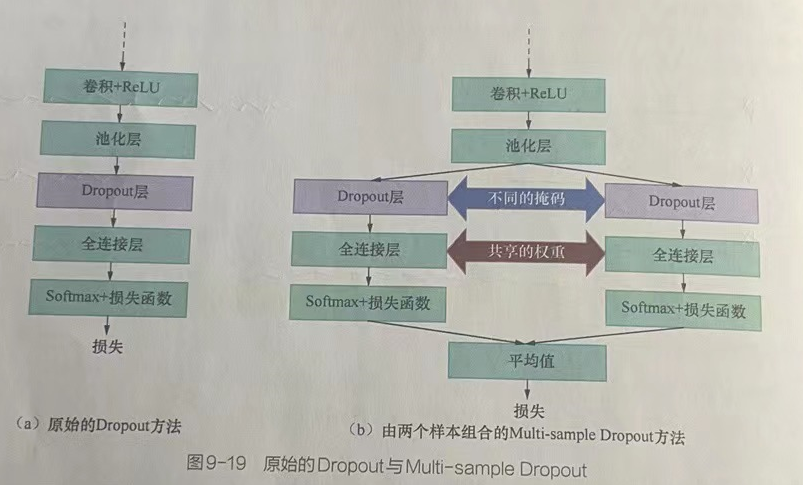
Multi-sampleDropoutは、2セットの異なるマスクを使用して、Dropoutレイヤーでトレーニングする2セットのノードを選択します。このアプローチは、ネットワークレイヤーがサンプルを一度だけ実行するのと同じですが、複数の結果を出力し、複数のトレーニングを実行します。したがって、トレーニングの反復回数を大幅に減らすことができます。
1.1.2機能
深いニューラルネットワークでは、ドロップアウト層の前の畳み込み層で非常に多くの操作が発生し、Muitiサンプルドロップアウトはこれらの計算を繰り返さないため、マルチサンプルドロップアウトは各反復の計算コストにほとんど影響しません。トレーニングを大幅にスピードアップできます。
2コードの実装
2コードの記述
2.1コードコンバット:基本モジュールを紹介し、実行環境をセットアップします----Cora_GNN.py(パート1)
from pathlib import Path # 引入提升路径的兼容性
# 引入矩阵运算的相关库
import numpy as np
import pandas as pd
from scipy.sparse import coo_matrix,csr_matrix,diags,eye
# 引入深度学习框架库
import torch
from torch import nn
import torch.nn.functional as F
# 引入绘图库
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 1.1 导入基础模块,并设置运行环境
# 输出计算资源情况
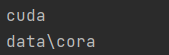
device = torch.device('cuda')if torch.cuda.is_available() else torch.device('cpu')
print(device) # 输出 cuda
# 输出样本路径
path = Path('./data/cora')
print(path) # 输出 cuda出力結果:
2.2コードの実装:紙のデータの読み取りと解析----Cora_GNN.py(パート2)
# 1.2 读取并解析论文数据
# 读取论文内容数据,将其转化为数据
paper_features_label = np.genfromtxt(path/'cora.content',dtype=np.str_) # 使用Path对象的路径构造,实例化的内容为cora.content。path/'cora.content'表示路径为'data/cora/cora.content'的字符串
print(paper_features_label,np.shape(paper_features_label)) # 打印数据集内容与数据的形状
# 取出数据集中的第一列:论文ID
papers = paper_features_label[:,0].astype(np.int32)
print("论文ID序列:",papers) # 输出所有论文ID
# 论文重新编号,并将其映射到论文ID中,实现论文的统一管理
paper2idx = {k:v for v,k in enumerate(papers)}
# 将数据中间部分的字标签取出,转化成矩阵
features = csr_matrix(paper_features_label[:,1:-1],dtype=np.float32)
print("字标签矩阵的形状:",np.shape(features)) # 字标签矩阵的形状
# 将数据的最后一项的文章分类属性取出,转化为分类的索引
labels = paper_features_label[:,-1]
lbl2idx = { k:v for v,k in enumerate(sorted(np.unique(labels)))}
labels = [lbl2idx[e] for e in labels]
print("论文类别的索引号:",lbl2idx,labels[:5])出力:

2.3紙のリレーショナルデータを読み取って解析する
論文の関係データを読み込み、データ内の論文IDで表される関係を番号を付け直した関係に変換し、各論文を頂点として扱い、論文間の引用関係をエッジとして扱い、論文の関係データでグラフ構造で表されます。

このグラフ構造の隣接行列を計算し、それを無向グラフ隣接行列に変換します。
2.3.1コードの実装:変換行列----Cora_GNN.py(パート3)
# 1.3 读取并解析论文关系数据
# 读取论文关系数据,并将其转化为数据
edges = np.genfromtxt(path/'cora.cites',dtype=np.int32) # 将数据集中论文的引用关系以数据的形式读入
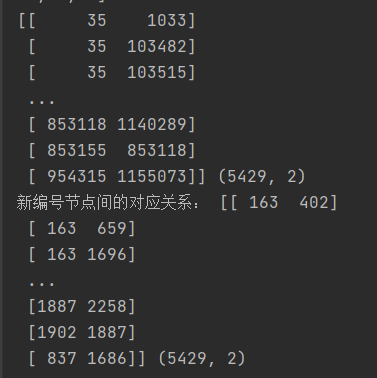
print(edges,np.shape(edges))
# 转化为新编号节点间的关系:将数据集中论文ID表示的关系转化为重新编号后的关系
edges = np.asarray([paper2idx[e] for e in edges.flatten()],np.int32).reshape(edges.shape)
print("新编号节点间的对应关系:",edges,edges.shape)
# 计算邻接矩阵,行与列都是论文个数:由论文引用关系所表示的图结构生成邻接矩阵。
adj = coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),shape=(len(labels), len(labels)), dtype=np.float32)
# 生成无向图对称矩阵:将有向图的邻接矩阵转化为无向图的邻接矩阵。Tip:转化为无向图的原因:主要用于对论文的分类,论文的引用关系主要提供单个特征之间的关联,故更看重是不是有关系,所以无向图即可。
adj_long = adj.multiply(adj.T < adj)
adj = adj_long + adj_long.T出力:
2.4処理グラフ構造のマトリックスデータ
グラフ構造の行列データは、グラフ構造の特徴をよりよく示すために処理され、ニューラルネットワークのモデル計算に関与します。
2.4.1グラフ構造のマトリックスデータを処理する手順
1.各ノードの特徴データを正規化します。
2.隣接行列の対角線に1を追加します:分類タスクでは、隣接行列の主な機能は、論文間の関連付けを通じてノードの分類を支援することであるためです。対角線上のノードの場合、表現の意味はそれ自体とそれ自体の間の関係です。対角ノードを1(自己ループグラフ)に設定すると、ノードが分類タスクにも役立つことを示します。
3. 1で補完した後、隣接行列を正規化します。

2.4.2コードの実装:処理グラフ構造のマトリックスデータ----Cora_GNN.py(パート4)
# 1.4 加工图结构的矩阵数据
def normalize(mx): # 定义函数,对矩阵的数据进行归一化处理
rowsum = np.array(mx.sum(1)) # 计算每一篇论文的字数==>02 对A中的边数求和,计算出矩阵A的度矩阵D^的特征向量
r_inv = (rowsum ** -1).flatten() # 取总字数的倒数==>03 对矩阵A的度矩阵D^的特征向量求逆,并得到D^逆的特征向量
r_inv[np.isinf(r_inv)] = 0.0 # 将NaN值取为0
r_mat_inv = diags(r_inv) # 将总字数的倒数变为对角矩阵===》对图结构的度矩阵求逆==>04 D^逆的特征向量转化为对角矩阵,得到D^逆
mx = r_mat_inv.dot(mx) # 左乘一个矩阵,相当于每个元素除以总数===》对每个论文顶点的边进行归一化处理==>05 计算D^逆与A加入自环(对角线为1)的邻接矩阵所得A^的点积,得到拉普拉斯矩阵。
return mx
# 对features矩阵进行归一化处理(每行总和为1)
features = normalize(features) #在函数normalize()中,分为两步对邻接矩阵进行处理。1、将每篇论文总字数的倒数变成对角矩阵。该操作相当于对图结构的度矩阵求逆。2、用度矩阵的逆左乘邻接矩阵,相当于对图中每个论文顶点的边进行归一化处理。
# 对邻接矩阵的对角线添1,将其变为自循环图,同时对其进行归一化处理
adj = normalize(adj + eye(adj.shape[0])) # 对角线补1==>01实现加入自环的邻接矩阵A2.5データをテンソルに変換し、コンピューティングリソースを割り当てます
処理されたグラフ構造行列データをPyTorchでサポートされているテンソル型に変換し、トレーニング、テスト、検証のために3つの部分に分割します。
2.5.1コードの実装:データをテンソルに変換し、コンピューティングリソースを割り当てる----Cora_GNN.py(パート5)
# 1.5 将数据转化为张量,并分配运算资源
adj = torch.FloatTensor(adj.todense()) # 节点间关系 todense()方法将其转换回稠密矩阵。
features = torch.FloatTensor(features.todense()) # 节点自身的特征
labels = torch.LongTensor(labels) # 对每个节点的分类标签
# 划分数据集
n_train = 200 # 训练数据集大小
n_val = 300 # 验证数据集大小
n_test = len(features) - n_train - n_val # 测试数据集大小
np.random.seed(34)
idxs = np.random.permutation(len(features)) # 将原有的索引打乱顺序
# 计算每个数据集的索引
idx_train = torch.LongTensor(idxs[:n_train]) # 根据指定训练数据集的大小并划分出其对应的训练数据集索引
idx_val = torch.LongTensor(idxs[n_train:n_train+n_val])# 根据指定验证数据集的大小并划分出其对应的验证数据集索引
idx_test = torch.LongTensor(idxs[n_train+n_val:])# 根据指定测试数据集的大小并划分出其对应的测试数据集索引
# 分配运算资源
adj = adj.to(device)
features = features.to(device)
labels = labels.to(device)
idx_train = idx_train.to(device)
idx_val = idx_val.to(device)
idx_test = idx_test.to(device)2.6グラフの畳み込み
グラフの畳み込みの本質は、次元変換です。つまり、次元内の各ノード特徴データを次元なしのノード特徴データに変換します。
グラフ畳み込みの操作は、入力ノードの特徴、重みパラメーター、および処理された隣接行列を組み合わせて、内積操作を実行します。
重みパラメータは、サイズin×outの行列です。ここで、inは入力ノードの特徴次元を表し、outは出力される最終的な特徴次元を表します。次元変換における重みパラメーターの関数は、完全に接続されたネットワークの重みとして理解されますが、グラフの畳み込みでは、完全に接続されたネットワークよりもノード関係情報の内積演算を実行します。
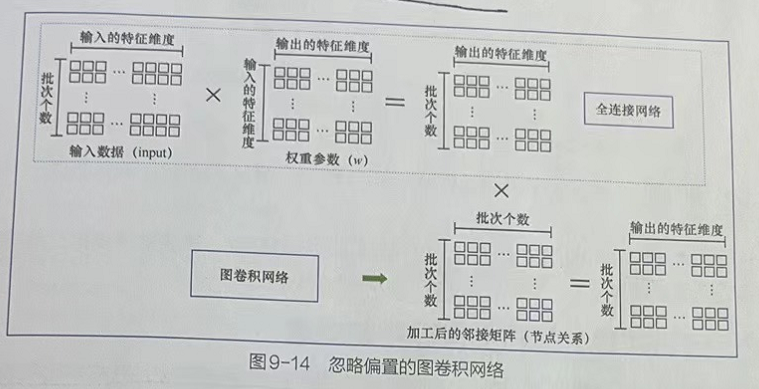
上図に示すように、バイアスを無視した後の完全接続ネットワークとグラフ畳み込みネットワークの関係を示します。このことから、グラフ畳み込みネットワークは、完全に接続されたネットワークに基づいてノード関係情報を実際に追加していることがはっきりとわかります。
2.6.1コードの実装:Mishの活性化関数とグラフの畳み込み演算クラスを定義する----Cora_GNN.py(パート6)
上の図に示されているアルゴリズムベースにバイアスを追加し、GraphConvolutionクラスを定義します
# 1.6 定义Mish激活函数与图卷积操作类
def mish(x): # 性能优于RElu函数
return x * (torch.tanh(F.softplus(x)))
# 图卷积类
class GraphConvolution(nn.Module):
def __init__(self,f_in,f_out,use_bias = True,activation=mish):
# super(GraphConvolution, self).__init__()
super().__init__()
self.f_in = f_in
self.f_out = f_out
self.use_bias = use_bias
self.activation = activation
self.weight = nn.Parameter(torch.FloatTensor(f_in, f_out))
self.bias = nn.Parameter(torch.FloatTensor(f_out)) if use_bias else None
self.initialize_weights()
def initialize_weights(self):# 对参数进行初始化
if self.activation is None: # 初始化权重
nn.init.xavier_uniform_(self.weight)
else:
nn.init.kaiming_uniform_(self.weight, nonlinearity='leaky_relu')
if self.use_bias:
nn.init.zeros_(self.bias)
def forward(self,input,adj): # 实现模型的正向处理流程
support = torch.mm(input,self.weight) # 节点特征与权重点积:torch.mm()实现矩阵的相乘,仅支持二位矩阵。若是多维矩则使用torch.matmul()
output = torch.mm(adj,support) # 将加工后的邻接矩阵放入点积运算
if self.use_bias:
output.add_(self.bias) # 加入偏置
if self.activation is not None:
output = self.activation(output) # 激活函数处理
return output2.7 Multi_SampleDropoutを使用した多層グラフ畳み込みネットワークモデルの構築---Cora_GNN_MUti-sample-Dropout.py(変更されたパート1)
# 1.7 搭建带有Multi_Sample Dropout的多层图卷积网络模型:根据GCN模型,
class GCNTD(nn.Module):
def __init__(self,f_in,n_classes,hidden=[16],dropout_num = 8,dropout_p=0.5 ): # 默认使用8组dropout,每组丢弃率为0.5
# super(GCNTD, self).__init__()
super().__init__()
layer = []
for f_in,f_out in zip([f_in]+hidden[:-1],hidden):
layer += [GraphConvolution(f_in,f_out)]
self.layers = nn.Sequential(*layer)
# 默认使用8个Dropout分支
self.dropouts = nn.ModuleList([nn.Dropout(dropout_p,inplace=False) for _ in range(dropout_num)] )
self.out_layer = GraphConvolution(f_out,n_classes,activation=None)
def forward(self,x,adj):
# Multi - sampleDropout结构默认使用了8个Dropout分支。在前向传播过程中,具体步骤如下。
# ①输入样本统一经过多层图卷积神经网络来到Dropout层。
# ②由每个分支的Dropout按照指定的丢弃率对多层图卷积的结果进行Dropout处理。
# ③将每个分支的Dropout数据传入到输出层,分别得到结果。
# ④将所有结果加起来,生成最终结果。
for layer,d in zip(self.layers,self.dropouts):
x = layer(x,adj)
if len(self.dropouts) == 0:
return self.out_layer(x,adj)
else:
for i, dropout in enumerate(self.dropouts): # 将每组的输出叠加
if i == 0 :
out = dropout(x)
out = self.out_layer(out,adj)
else:
temp_out = dropout(x)
out = out + self.out_layer(temp_out,adj)
return out # 返回结果
n_labels = labels.max().item() + 1 # 获取分类个数7
n_features = features.shape[1] # 获取节点特征维度 1433
print(n_labels,n_features) # 输出7与1433
def accuracy(output,y): # 定义函数计算准确率
return (output.argmax(1) == y).type(torch.float32).mean().item()
### 定义函数来实现模型的训练过程。与深度学习任务不同,图卷积在训练时需要传入样本间的关系数据。
# 因为该关系数据是与节点数相等的方阵,所以传入的样本数也要与节点数相同,在计算loss值时,可以通过索引从总的运算结果中取出训练集的结果。
# 在图卷积任务中,无论是用模型进行预测还是训练,都需要将全部的图结构方阵输入。
def step(): # 定义函数来训练模型
model.train()
optimizer.zero_grad()
output = model(features,adj) # 将全部数据载入模型,只用训练数据计算损失
loss = F.cross_entropy(output[idx_train],labels[idx_train])
acc = accuracy(output[idx_train],labels[idx_train]) # 计算准确率
loss.backward()
optimizer.step()
return loss.item(),acc
def evaluate(idx): # 定义函数来评估模型
model.eval()
output = model(features, adj) # 将全部数据载入模型
loss = F.cross_entropy(output[idx], labels[idx]).item() # 用指定索引评估模型结果
return loss, accuracy(output[idx], labels[idx])2.8コードの実装:トレーニングの視覚化--- Cora_GNN_MUti-sample-Dropout.py(変更されたパート2)
model = GCNTD(n_features,n_labels,hidden=[16,32,16]).to(device)
from ranger import *
from functools import partial # 引入偏函数对Ranger设置参数
opt_func = partial(Ranger,betas=(0.9,0.99),eps=1e-6)
optimizer = opt_func(model.parameters())
from tqdm import tqdm
# 训练模型
epochs = 400
print_steps = 50
train_loss, train_acc = [], []
val_loss, val_acc = [], []
for i in tqdm(range(epochs)):
tl,ta = step()
train_loss = train_loss + [tl]
train_acc = train_acc + [ta]
if (i+1) % print_steps == 0 or i == 0:
tl,ta = evaluate(idx_train)
vl,va = evaluate(idx_val)
val_loss = val_loss + [vl]
val_acc = val_acc + [va]
print(f'{i + 1:6d}/{epochs}: train_loss={tl:.4f}, train_acc={ta:.4f}' + f', val_loss={vl:.4f}, val_acc={va:.4f}')
# 输出最终结果
final_train, final_val, final_test = evaluate(idx_train), evaluate(idx_val), evaluate(idx_test)
print(f'Train : loss={final_train[0]:.4f}, accuracy={final_train[1]:.4f}')
print(f'Validation: loss={final_val[0]:.4f}, accuracy={final_val[1]:.4f}')
print(f'Test : loss={final_test[0]:.4f}, accuracy={final_test[1]:.4f}')
# 可视化训练过程
fig, axes = plt.subplots(1, 2, figsize=(15,5))
ax = axes[0]
axes[0].plot(train_loss[::print_steps] + [train_loss[-1]], label='Train')
axes[0].plot(val_loss, label='Validation')
axes[1].plot(train_acc[::print_steps] + [train_acc[-1]], label='Train')
axes[1].plot(val_acc, label='Validation')
for ax,t in zip(axes, ['Loss', 'Accuracy']): ax.legend(), ax.set_title(t, size=15)
# 输出模型的预测结果
output = model(features, adj)
samples = 10
idx_sample = idx_test[torch.randperm(len(idx_test))[:samples]]
# 将样本标签与预测结果进行比较
idx2lbl = {v:k for k,v in lbl2idx.items()}
df = pd.DataFrame({'Real': [idx2lbl[e] for e in labels[idx_sample].tolist()],'Pred': [idx2lbl[e] for e in output[idx_sample].argmax(1).tolist()]})
print(df)出力:
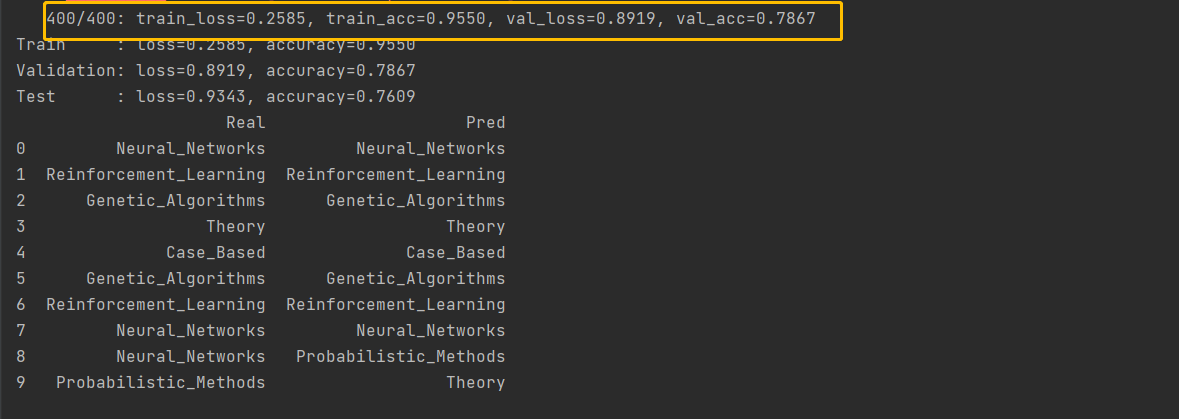
わずか400ラウンドでより良い結果が得られます
3コードの概要
Cora_GNN_MUti-sample-Dropout.py
from pathlib import Path # 引入提升路径的兼容性
# 引入矩阵运算的相关库
import numpy as np
import pandas as pd
from scipy.sparse import coo_matrix,csr_matrix,diags,eye
# 引入深度学习框架库
import torch
from torch import nn
import torch.nn.functional as F
# 引入绘图库
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
# 1.1 导入基础模块,并设置运行环境
# 输出计算资源情况
device = torch.device('cuda')if torch.cuda.is_available() else torch.device('cpu')
print(device) # 输出 cuda
# 输出样本路径
path = Path('./data/cora')
print(path) # 输出 cuda
# 1.2 读取并解析论文数据
# 读取论文内容数据,将其转化为数据
paper_features_label = np.genfromtxt(path/'cora.content',dtype=np.str_) # 使用Path对象的路径构造,实例化的内容为cora.content。path/'cora.content'表示路径为'data/cora/cora.content'的字符串
print(paper_features_label,np.shape(paper_features_label)) # 打印数据集内容与数据的形状
# 取出数据集中的第一列:论文ID
papers = paper_features_label[:,0].astype(np.int32)
print("论文ID序列:",papers) # 输出所有论文ID
# 论文重新编号,并将其映射到论文ID中,实现论文的统一管理
paper2idx = {k:v for v,k in enumerate(papers)}
# 将数据中间部分的字标签取出,转化成矩阵
features = csr_matrix(paper_features_label[:,1:-1],dtype=np.float32)
print("字标签矩阵的形状:",np.shape(features)) # 字标签矩阵的形状
# 将数据的最后一项的文章分类属性取出,转化为分类的索引
labels = paper_features_label[:,-1]
lbl2idx = { k:v for v,k in enumerate(sorted(np.unique(labels)))}
labels = [lbl2idx[e] for e in labels]
print("论文类别的索引号:",lbl2idx,labels[:5])
# 1.3 读取并解析论文关系数据
# 读取论文关系数据,并将其转化为数据
edges = np.genfromtxt(path/'cora.cites',dtype=np.int32) # 将数据集中论文的引用关系以数据的形式读入
print(edges,np.shape(edges))
# 转化为新编号节点间的关系:将数据集中论文ID表示的关系转化为重新编号后的关系
edges = np.asarray([paper2idx[e] for e in edges.flatten()],np.int32).reshape(edges.shape)
print("新编号节点间的对应关系:",edges,edges.shape)
# 计算邻接矩阵,行与列都是论文个数:由论文引用关系所表示的图结构生成邻接矩阵。
adj = coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),shape=(len(labels), len(labels)), dtype=np.float32)
# 生成无向图对称矩阵:将有向图的邻接矩阵转化为无向图的邻接矩阵。Tip:转化为无向图的原因:主要用于对论文的分类,论文的引用关系主要提供单个特征之间的关联,故更看重是不是有关系,所以无向图即可。
adj_long = adj.multiply(adj.T < adj)
adj = adj_long + adj_long.T
# 1.4 加工图结构的矩阵数据
def normalize(mx): # 定义函数,对矩阵的数据进行归一化处理
rowsum = np.array(mx.sum(1)) # 计算每一篇论文的字数==>02 对A中的边数求和,计算出矩阵A的度矩阵D^的特征向量
r_inv = (rowsum ** -1).flatten() # 取总字数的倒数==>03 对矩阵A的度矩阵D^的特征向量求逆,并得到D^逆的特征向量
r_inv[np.isinf(r_inv)] = 0.0 # 将NaN值取为0
r_mat_inv = diags(r_inv) # 将总字数的倒数变为对角矩阵===》对图结构的度矩阵求逆==>04 D^逆的特征向量转化为对角矩阵,得到D^逆
mx = r_mat_inv.dot(mx) # 左乘一个矩阵,相当于每个元素除以总数===》对每个论文顶点的边进行归一化处理==>05 计算D^逆与A加入自环(对角线为1)的邻接矩阵所得A^的点积,得到拉普拉斯矩阵。
return mx
# 对features矩阵进行归一化处理(每行总和为1)
features = normalize(features) #在函数normalize()中,分为两步对邻接矩阵进行处理。1、将每篇论文总字数的倒数变成对角矩阵。该操作相当于对图结构的度矩阵求逆。2、用度矩阵的逆左乘邻接矩阵,相当于对图中每个论文顶点的边进行归一化处理。
# 对邻接矩阵的对角线添1,将其变为自循环图,同时对其进行归一化处理
adj = normalize(adj + eye(adj.shape[0])) # 对角线补1==>01实现加入自环的邻接矩阵A
# 1.5 将数据转化为张量,并分配运算资源
adj = torch.FloatTensor(adj.todense()) # 节点间关系 todense()方法将其转换回稠密矩阵。
features = torch.FloatTensor(features.todense()) # 节点自身的特征
labels = torch.LongTensor(labels) # 对每个节点的分类标签
# 划分数据集
n_train = 200 # 训练数据集大小
n_val = 300 # 验证数据集大小
n_test = len(features) - n_train - n_val # 测试数据集大小
np.random.seed(34)
idxs = np.random.permutation(len(features)) # 将原有的索引打乱顺序
# 计算每个数据集的索引
idx_train = torch.LongTensor(idxs[:n_train]) # 根据指定训练数据集的大小并划分出其对应的训练数据集索引
idx_val = torch.LongTensor(idxs[n_train:n_train+n_val])# 根据指定验证数据集的大小并划分出其对应的验证数据集索引
idx_test = torch.LongTensor(idxs[n_train+n_val:])# 根据指定测试数据集的大小并划分出其对应的测试数据集索引
# 分配运算资源
adj = adj.to(device)
features = features.to(device)
labels = labels.to(device)
idx_train = idx_train.to(device)
idx_val = idx_val.to(device)
idx_test = idx_test.to(device)
# 1.6 定义Mish激活函数与图卷积操作类
def mish(x): # 性能优于RElu函数
return x * (torch.tanh(F.softplus(x)))
# 图卷积类
class GraphConvolution(nn.Module):
def __init__(self,f_in,f_out,use_bias = True,activation=mish):
# super(GraphConvolution, self).__init__()
super().__init__()
self.f_in = f_in
self.f_out = f_out
self.use_bias = use_bias
self.activation = activation
self.weight = nn.Parameter(torch.FloatTensor(f_in, f_out))
self.bias = nn.Parameter(torch.FloatTensor(f_out)) if use_bias else None
self.initialize_weights()
def initialize_weights(self):# 对参数进行初始化
if self.activation is None: # 初始化权重
nn.init.xavier_uniform_(self.weight)
else:
nn.init.kaiming_uniform_(self.weight, nonlinearity='leaky_relu')
if self.use_bias:
nn.init.zeros_(self.bias)
def forward(self,input,adj): # 实现模型的正向处理流程
support = torch.mm(input,self.weight) # 节点特征与权重点积:torch.mm()实现矩阵的相乘,仅支持二位矩阵。若是多维矩则使用torch.matmul()
output = torch.mm(adj,support) # 将加工后的邻接矩阵放入点积运算
if self.use_bias:
output.add_(self.bias) # 加入偏置
if self.activation is not None:
output = self.activation(output) # 激活函数处理
return output
# 1.7 搭建带有Multi_Sample Dropout的多层图卷积网络模型:根据GCN模型,
class GCNTD(nn.Module):
def __init__(self,f_in,n_classes,hidden=[16],dropout_num = 8,dropout_p=0.5 ): # 默认使用8组dropout,每组丢弃率为0.5
# super(GCNTD, self).__init__()
super().__init__()
layer = []
for f_in,f_out in zip([f_in]+hidden[:-1],hidden):
layer += [GraphConvolution(f_in,f_out)]
self.layers = nn.Sequential(*layer)
# 默认使用8个Dropout分支
self.dropouts = nn.ModuleList([nn.Dropout(dropout_p,inplace=False) for _ in range(dropout_num)] )
self.out_layer = GraphConvolution(f_out,n_classes,activation=None)
def forward(self,x,adj):
# Multi - sampleDropout结构默认使用了8个Dropout分支。在前向传播过程中,具体步骤如下。
# ①输入样本统一经过多层图卷积神经网络来到Dropout层。
# ②由每个分支的Dropout按照指定的丢弃率对多层图卷积的结果进行Dropout处理。
# ③将每个分支的Dropout数据传入到输出层,分别得到结果。
# ④将所有结果加起来,生成最终结果。
for layer,d in zip(self.layers,self.dropouts):
x = layer(x,adj)
if len(self.dropouts) == 0:
return self.out_layer(x,adj)
else:
for i, dropout in enumerate(self.dropouts): # 将每组的输出叠加
if i == 0 :
out = dropout(x)
out = self.out_layer(out,adj)
else:
temp_out = dropout(x)
out = out + self.out_layer(temp_out,adj)
return out # 返回结果
n_labels = labels.max().item() + 1 # 获取分类个数7
n_features = features.shape[1] # 获取节点特征维度 1433
print(n_labels,n_features) # 输出7与1433
def accuracy(output,y): # 定义函数计算准确率
return (output.argmax(1) == y).type(torch.float32).mean().item()
### 定义函数来实现模型的训练过程。与深度学习任务不同,图卷积在训练时需要传入样本间的关系数据。
# 因为该关系数据是与节点数相等的方阵,所以传入的样本数也要与节点数相同,在计算loss值时,可以通过索引从总的运算结果中取出训练集的结果。
# 在图卷积任务中,无论是用模型进行预测还是训练,都需要将全部的图结构方阵输入。
def step(): # 定义函数来训练模型
model.train()
optimizer.zero_grad()
output = model(features,adj) # 将全部数据载入模型,只用训练数据计算损失
loss = F.cross_entropy(output[idx_train],labels[idx_train])
acc = accuracy(output[idx_train],labels[idx_train]) # 计算准确率
loss.backward()
optimizer.step()
return loss.item(),acc
def evaluate(idx): # 定义函数来评估模型
model.eval()
output = model(features, adj) # 将全部数据载入模型
loss = F.cross_entropy(output[idx], labels[idx]).item() # 用指定索引评估模型结果
return loss, accuracy(output[idx], labels[idx])
model = GCNTD(n_features,n_labels,hidden=[16,32,16]).to(device)
from ranger import *
from functools import partial # 引入偏函数对Ranger设置参数
opt_func = partial(Ranger,betas=(0.9,0.99),eps=1e-6)
optimizer = opt_func(model.parameters())
from tqdm import tqdm
# 训练模型
epochs = 400
print_steps = 50
train_loss, train_acc = [], []
val_loss, val_acc = [], []
for i in tqdm(range(epochs)):
tl,ta = step()
train_loss = train_loss + [tl]
train_acc = train_acc + [ta]
if (i+1) % print_steps == 0 or i == 0:
tl,ta = evaluate(idx_train)
vl,va = evaluate(idx_val)
val_loss = val_loss + [vl]
val_acc = val_acc + [va]
print(f'{i + 1:6d}/{epochs}: train_loss={tl:.4f}, train_acc={ta:.4f}' + f', val_loss={vl:.4f}, val_acc={va:.4f}')
# 输出最终结果
final_train, final_val, final_test = evaluate(idx_train), evaluate(idx_val), evaluate(idx_test)
print(f'Train : loss={final_train[0]:.4f}, accuracy={final_train[1]:.4f}')
print(f'Validation: loss={final_val[0]:.4f}, accuracy={final_val[1]:.4f}')
print(f'Test : loss={final_test[0]:.4f}, accuracy={final_test[1]:.4f}')
# 可视化训练过程
fig, axes = plt.subplots(1, 2, figsize=(15,5))
ax = axes[0]
axes[0].plot(train_loss[::print_steps] + [train_loss[-1]], label='Train')
axes[0].plot(val_loss, label='Validation')
axes[1].plot(train_acc[::print_steps] + [train_acc[-1]], label='Train')
axes[1].plot(val_acc, label='Validation')
for ax,t in zip(axes, ['Loss', 'Accuracy']): ax.legend(), ax.set_title(t, size=15)
# 输出模型的预测结果
output = model(features, adj)
samples = 10
idx_sample = idx_test[torch.randperm(len(idx_test))[:samples]]
# 将样本标签与预测结果进行比较
idx2lbl = {v:k for k,v in lbl2idx.items()}
df = pd.DataFrame({'Real': [idx2lbl[e] for e in labels[idx_sample].tolist()],'Pred': [idx2lbl[e] for e in output[idx_sample].argmax(1).tolist()]})
print(df)