
この記事は、 DataFun「AI +」トークでChehaoduoのNLPディレクションを担当するWangWenbin氏が共有した「ThePracticeof Dialogue RobotsinGuazi」の編集に基づいています-「中古市場でのAIの応用」 。

本日は主に以下の側面を共有します。まず、対話ロボットとは何かを紹介し、次に技術選択のプロセス、どのアルゴリズムアーキテクチャとシステムアーキテクチャが設計されているか、最後にオフライン効果と直面しているいくつかの課題について説明します。グアジで。
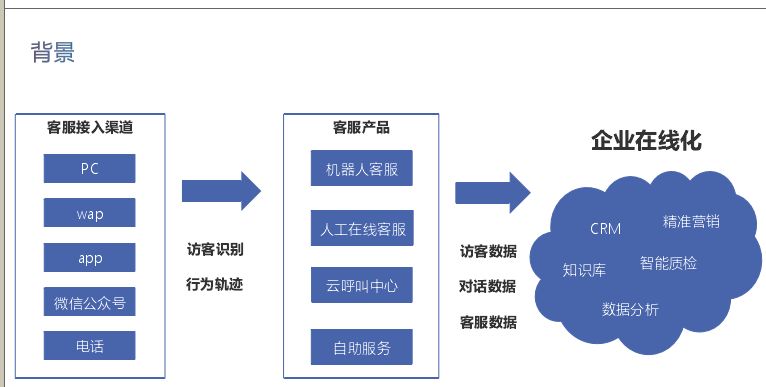
現在、対話ロボットは非常に人気があります。理由はたくさんあります。1つは、チューリングが知能を定義するときに人工知能のシンボルとして対話ロボットを使用したこと、2つ目は、深層学習技術がますます成熟し、対話ロボットがますます成熟していることです。業界ではより成熟しています。一定のレベルに到達します。第3に、インテリジェントなカスタマーサービスの蓄積により、これを行っている企業は数多くあります。上の図はスマートカスタマーサービスの設計図です。左側はアクセスチャネルです。ログインすると、ロボットカスタマーサービス、手動オンラインカスタマーサービス、クラウドコールセンターなどのカスタマーサービス製品が提供され、ユーザーはいくつかのことを行います。製品に基づくセルフサービス。チャット中、ユーザーは自分のデータ(フィードバックデータ、会話データ、手動カスタマーサービスデータ)を残し、これらのデータを分析に使用します。たとえば、カスタマーサービスデータは品質検査に使用でき、ユーザーデータはマーケティングに使用できます。動作し、 CRMに接続できます。
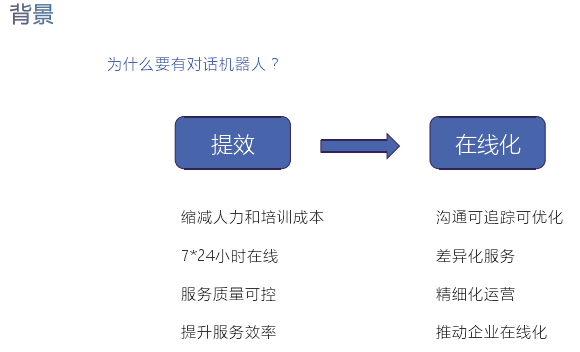
次に、対話型ロボットに必要なものについてお話します。最初に、Guaziの目標は、効率を改善し、人間を機械に置き換え、人件費とトレーニングコストの削減、 7 * 24時間のオンラインサービス、および制御可能という目標を達成することです。品質。開発の過程で、コンセプトは徐々にオンラインコンセプト、つまりデジタル化、データ化、インテリジェンスに昇華しました。デジタル化とは、ユーザーと企業間の相互作用のすべてのデータを記録し、データを構造化し、デジタル化と呼ばれるアルゴリズムでデータを利用できるようにすることです。デジタル化では、モデリングなどの一連のインテリジェントな方法を使用して、インテリジェントな改善を行うことができます。オンライン後、コミュニケーション全体を追跡し、最適化し、差別化されたサービスを提供し、洗練された操作を提供することができます。これにより、最終的に企業のオンラインビジネスが促進されます。
オンラインボットはオンラインチャットの一部であり、クローズドループサービス全体の入口と出口の両方です。ユーザーはチャットで対応する要求を表現して解決できますが、検索と推奨は受動的なプロセスのようなものです。IMは、要求を積極的に表現するためのポータルです。

対話ロボットの分類:オープンエンドのロボットにはMicrosoftXiaobingとDuMiが含まれ、タスク指向のロボットには航空券の予約と天気の問い合わせが含まれます。役割のポジショニングの観点から、 IMチャネルが提供されている場合、それは実際にはアーキテクチャです。対応するアプリケーションを作成できるのはスケルトンのみです。アルゴリズムはその中で重要な役割を果たします。後の段階では、実際にはより多くの製品になります。指向。対話ロボット技術は透過的です。違いは、誰が細部をより完璧にするかにあります。開発の角度は、3つのビュー、カスタマービュー:ダイアログコンテンツ、ダイアログボックス、およびダイアログボックス外の推奨情報を改善することです。カスタマーサービスビュー:ダイアログコンテキスト、カスタマーポートレート、背景情報、注文ポートレート、マネージャービュー:コンソール、ナレッジベース。
対話ロボットの古典的なプロセス:音声の目覚め、何をすべきかを教え、目覚めた後、音声認識によってテキストに変換されます。この時点で、意味の理解を行うことができます(知識ベースの相互作用が必要な場合があります)。意味理解の結果は、対話管理エンジンを介してユーザーに取得できます。対応する単語、対応する単語はテキストに変換され、最後に音声出力に変換されます。

「明日の朝10時に北京から上海へのフライトを予約するのを手伝ってください」などの対話ロボットのコアコンセプトを説明し、この文の意図は「フライトチケットを予約する」です。スロットは、文を完全に理解して結果情報を返すことができるようにするために必要な属性です。この文のスロット情報は、出発時刻=明日の朝10時、出発地=北京、目的地=上海です。 。
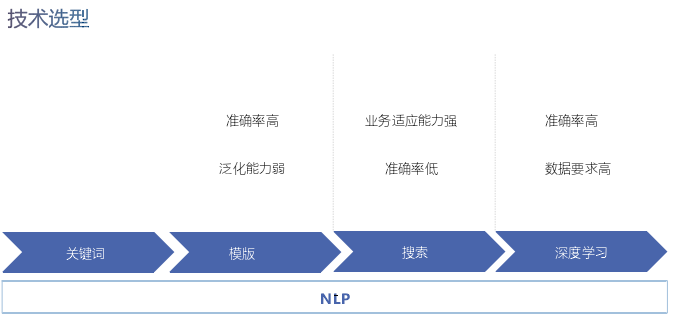
次に、対話ロボットの技術選択に関する研究の過程である技術選択についてお話しましょう。ダイアログボットは、最初はキーワード、次にテンプレートテクノロジーに基づいており、多くの企業が現在も使用しています。長所は制御可能な品質と高精度ですが、短所は一般化能力が比較的弱いことです。関数の継続的な反復により、テンプレートは手作業に大きく依存し、その一般化能力を独立して向上させることはできません。次に、ビジネスへの適応性が高い検索ベースの対話ロボットがありますが、その欠点は精度が低いことです。近年、ディープラーニングが普及した後、意図認識の元のモデルをディープラーニングに置き換え、従来の方法に比べて意図認識の精度は大幅に向上しますが、データ品質が高くなるというデメリットがあります。
模板可以部分自动生成,如果上线也需要应用方自己审核与补充,话术也需要应用方自己去配置。搜索技术更多的是先用意图识别做一个路由器的功能,然后路由到一些小的robot,每个robot做一类事情。深度学习与传统分类方法做的事情类似,也是在做多意图的意图分类,确定意图后会通过一对一或其他配置方式将其关联回答。
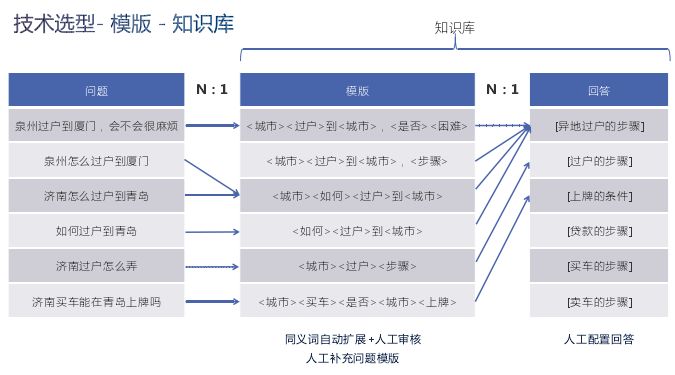
下面是一个模板算法,“泉州过户到厦门会不会很麻烦”,这个模板在前面没有出现过,就无法匹配,需要将模板提取出来,固化到知识库、模板库中。
对话机器人发展到后面越来越注重运营,有一个管理平台,就是知识库。固化知识,给运营提供管理入口。前面例子就是维护问题到模板以及模板到回答的映射关系,人工需要做很多审核以及一些校对的工作。而搜索方案,将query经过预处理打散成terms,进入搜索系统,如果按照原始结果会得到一个排序“泉州到厦门过户问题,泉州到厦门远吗,泉州到厦门怎么坐车,泉州到福州过户问题,泉州到厦门过户问题”,最后得出结果与查询一致,将最相近的query回答返回。而解决排序不正确的方法就是需要海量数据。
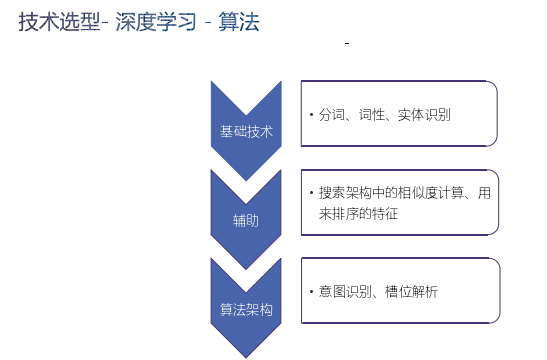
接下来讲一下深度学习的算法架构,深度学习应用很多,以对话机器人而言,基础技术如分词、词性、实体识别都可以用深度学习,数据好的话会比传统方法好。还有搜索架构中的相似度计算、用来排序的一些特征也可以用到深度学习的方法。我们是从整个结构来看就是一个深度学习的架构,这也是学术界研究的热点。
深度学习知识库我们解决就是意图与答案一对一的关系,回答对话术本身要求很严格,几乎是一个纯人工的过程,有很多人参与业务运营。如果是单轮就是一个多分类问题,更重要的是如何建立一种机制将问题积累过程与上线后模型的演进过程变得更加自动化、质量更可控。除了刚才它谈到的技术还有其他方法如生成模式,学术界较火,主要是应用于闲聊。我们最后选用深度学习模式,考虑的原因有以下几个方面,就是不再需要人去抽取大量的特征。
语义理解的流程,包括快速识别、模型识别、搜索识别、相似问题,在这个流程中应用了很多技术。我们采取的是一个漏斗方式,开始是快速识别(需要实时解决),在快速识别弄一个白名单用关键词或模版匹配立刻纠正,原则是必须准确率要高。90%的问题是依据模型框架,准确率也在90%以上,有了前面两步,后面是在补充召回的过程,通过搜索系统借助文本相似度的匹配将一部分数据召回,尽量让用户更多的问题被识别。

接下来介绍下多轮,我理解多轮是一个更偏工程的过程。里面更多的算法是在做槽位解析,需要做好三件事,第一个就是填槽,如果对话过程中槽位未补全,在下轮对话过程中引导用户补全槽位信息。再者就是场景管理,需要维护海量用户的聊天信息。第三点就是可配置,多轮最后面都是一个业务问题,开发一个可配置的界面,让运营自行配置其需要的对话。多轮的逻辑是在知识库里配置的,DM是和业务无关的,只需要按配置的解析结果执行即可。
按照上面设计还是会出现风险,常见的五个风险有:任何算法的选择都只是满足当前的需求,数据是历史数据,算法是当前反馈,业务演化过程不可知; 模型互搏,各种模型都要去做A/BTest确定哪种好那种坏,之前更多的判断是从原理上判断;意图爆炸,目前知识库是基于意图回答一对一关系,业务相对收敛,但是未来发展速度可能导致意图不可收敛; 主观标准的反复,很多过程都由人工参与,每个人评判标准不一;模型更新滞后于业务发展,技术发展较快。解决方案就是永远保持主动,提前应对。
系统架构:前端有一个对话框和消息服务器,类似于IM基本架构,消息服务器会将消息路由到对话管理模块(中控)。用户聊天文本会在中控识别意图和槽位,通过意图在知识库中获取对应的话术。知识库有一个控制台,与外部交互的界面,对话管理也会访问后端云服务,比如通过ip地址获取其属于哪个城市,除此外还有语义理解、CRM服务等。
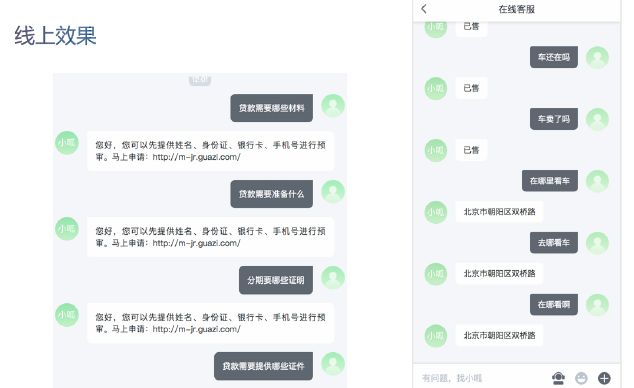
线上效果,左边是一个单轮对话能力,无论问如何贷款都能准确识别,右边是一个动态API,类似于知识图谱想要完成的工作。
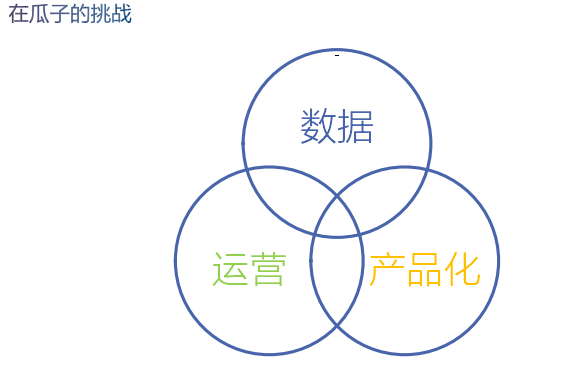
在瓜子遇到的挑战:首先是数据,不管做什么都需要数据。运营,这方面主要是对话机器人自学习的能力,如何设置一些机制使运营能够满足当前业务效果,跟上业务发展速度。最后是产品化,如何将产品细节做得足够好。
举例:第一个就是数据来源,以一定规则构造数据,或利用非结构化数据通过迁移学习训练embedding向量,将向量作为意图识别的原始输入,或模型产生数据反哺模型,不断迭代。第二个就是话术的确认流程,编辑发起修改,业务反馈,编辑确认,审核,法务,上线,这是一个理想的模式。人与人之间的平衡: 回答的标准,新增意图的标准,产品和算法的平衡: 意图预判、suggest、相似问题、下一个问题,业务和技术的平衡:卡片消息,就是在线化,后台服务如何让用户利用起来。


ユーザーがさまざまなビジネスポータルから見る質問のリストは異なり、ユーザーがさまざまなビジネスステージから見る質問のリストも異なります。将来的には、事業の状況だけでなく、過去のデータにもとづいて、いくつかの提言をしたいと思っています。ダイアログボットは、ユーザーの魅力を高め、より正確な推奨事項を提供するために、複数回のダイアログを通じて、現在行っているプレシジョンマーケティングなど、多くのことを実行できます。
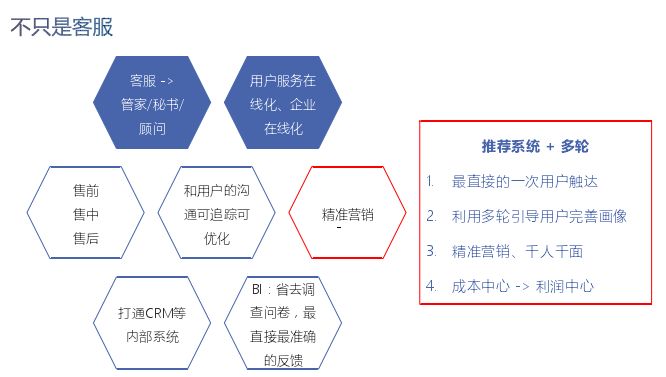
以下は、より概念的なものです。CRMなどの内部システムを通じて、データをビジネスインテリジェンスに使用し、すべてのプレセールス、インセールス、およびアフターセールスのシナリオをカバーし、ユーザーコミュニケーションを追跡および最適化できます。カスタマーサービスから専門コンサルタントまで、達成するためにオンラインユーザーサービスとオンライン企業は、最終的に企業全体のインテリジェンスを実現します。
著者について:
ChehaoduのNLPディレクションの責任者であるWangWenbin。北京大学を修士号で卒業し、Meituan、Baiduなどの企業で働いており、コンパイラ、ブラウザ、IM、ビッグデータなどの複雑なシステムの開発に実践的な経験があり、検索の推奨、知識の質疑応答、データマイニング、機械学習、NLP、その他のアルゴリズムの方向性は豊富に蓄積されています。たくさん車に乗り込んだ後、インテリジェントIMプロジェクトを開始し、対話ロボットの着陸に成功しました。
チーム紹介:
Guazi NLPチームは、チャットボットやその他の製品を使用して、人間の効率を高め、サービス品質を向上させ、オンラインサービスの割合を徐々に増やしています。チームは、将来のグアジの開発のための重要な基本機能の1つであるグアジのオンラインサービスを担当しています。
- 終わり -
他の記事を見ますか?
レビュー・知識グラフ:シェルハウス検索で0から1まで練習する
レビュー・ロボット・ヒューマンコンピュータインタラクション・テクノロジーの紹介
レビュー・深層学習の解釈可能性と金融分野における低頻度イベント学習の研究と応用
レビュー・5月8日市のスマートカスタマーサービスシステムの「バンバン」技術が明らかに

