医用画像における生成的敵対的ネットワーク:レビュー
医療画像における生成的敵対ネットワークの研究の進歩-レビュー
概要
生成的対立ネットワークは、データ分散のモデリングを暗黙的に完了することができるという事実のおかげで、コンピューターのビジョンの下で多くのタスクで輝いています。ジェネレーターは多数のサンプルを生成し、ディスクリミネーターは多数のラベルなしサンプルに対してカテゴリー予測を実行します。したがって、GANはドメイン移行、セグメンテーションタスク、分類タスク、およびクロスモーダル合成の分野で多くの調査を行ってきました。したがって、この記事では、医療画像の分野における生成的敵対ネットワークの関連する研究の進捗状況をレビューし、この分野に関心のある研究者にいくつかの利便性とアイデアを提供することを目的としています。
セクションIはじめに
2012年以降、ディープラーニングフレームワークはコンピュータービジョンの分野で活力を取り戻し、医療画像関連のジャーナルや会議でも多数の関連研究が行われています。ディープラーニングの強力な機能学習機能のおかげで、医療画像の機能表現を強化してさらに使用することができます。分類やセグメンテーションなどのタスク用。
GANは主にジェネレーターとディスクリミネーターの2つのネットワークで構成されています。ジェネレーターはサンプルの特定の分布を生成し、ディスクリミネーターはサンプルが実際の画像からのものか生成された画像からのものかを判断し、カテゴリ予測結果を提供します。2つのネットワークは同時にトレーニングされます。学習と戦う。
GANは、テキストから画像、超解像度、画像から画像への変換など、多くの分野でSOTAの結果を達成しています。
このレビューの主な検索ソースには、次の主流のジャーナル/会議が含まれます。医療画像コンピューティングおよびコンピューター支援介入に関する国際会議(MICCAI)、
SPIE医療画像、
IEEE International Symposium on Biomedical Imaging(
ISBI )、
国際会議ディープラーニングを使用した医療イメージング(MIDL)
期限:2019.1.1
記事の主な配置は次のとおりです。
セクションI:はじめに
セクションII:GANおよび関連するバリアントの基本知識セクションIII:
医療画像へのGANの適用、タスク:セグメンテーション、分類、検出、注釈など。
セクションIV
:全文を要約し、将来を楽しみにしています#セクションIIGANとそのバリアント
パートAGAN
元のGANには、生成ネットワークと識別ネットワークの2つのネットワークが含まれているため、画像/データの確率密度関数を学習する必要はありませんが、予想されるデータ分布から直接学習する必要がありますトレーニング用のサンプル。
Generaotrの入力は、特定の分布からサンプリングされたランダムノイズzであり、出力は、実際の画像と同様の生成された画像xrです。この非線形マッピング関数は、θgを使用して、Discriminatorが実際のサンプルまたは生成されたサンプルを入力として受け取り、出力が次のように入力サンプルであることを示します。真または偽の確率、いわゆる弁別子Dは、単純な2クラスネットワークにすることができます。
ジェネレーターは偽のサンプルでDを欺くことに専念し、ディスクリミネーターは入力サンプルが真か偽かを区別することに専念します。2つは学習とトレーニングを同時に行います。損失関数は次のように表されます。GANGANトレーニングの
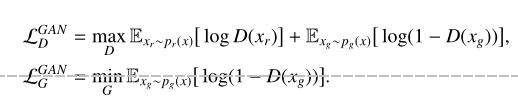
制限
は次の
ように見なされます。損失関数のサドルを探しますが、2つのネットワークトレーニングの収束問題を保証することは困難です。たとえば、弁別器Dは十分に強力であり、画像が本物であるか生成ネットワークからのものであるかを簡単に区別できます。このとき、Dは局所最適に達し、Gの最適化を継続することは困難です。 、この状況は、高解像度の画像を生成する場合に特に一般的です。別の問題は、GANトレーニングでもモード崩壊(モード崩壊)が発生することです。つまり、ジェネレーターは常に特定の分布でローカル出力を生成します。その結果、出力モードが制限されます。たとえば、犬の写真は生成できますが、猫やウサギの写真は生成できません。
弁別器、
GANの関連バリアント
:
Dの改善は、主に安定したトレーニングを行うか、モードの崩壊を防ぐことです。関連する改善は、f-GAN、LS-GAN、WGAN、EBGAN、BEGAN、ALI、BiGAN、InfoGAN、ACGAN
ジェネレーターです。
生成ネットワークは、ランダムノイズを出力の特定の分布にマッピングします。通常、VAEGANなどのデコーダーネットワークは、変分セルフエンコーダーによって学習された機能を使用して、ピクセルレベルの再構築を完了します。
GANネットワーク全体では、構築の開始時に生成されるモードに制限はありませんが、補助入力の追加情報がGANに特定のモードを生成するように導くことができる場合、これはcGANです。
画像変換では、再構成損失は、セグメンテーションタスクで補助監視情報としてよく使用されます。ダイスロスは上記のGANトレーニングで使用され、上記のGANトレーニングでは入力画像ペアが必要です。また、代表としてのCycle GANでは画像ペアの入力が不要であるため、ドメイン転送間の変形を制限するための周期的一貫性の存在が増加します。UNITもあります。イメージペアトレーニングなしで2つのVAEGANを組み合わせることができます。アーキテクチャ:
元のGANで使用されていたFCレイヤーは、DCGANのアップサンプリングまたはダウンサンプリングレイヤーに置き換えられ、完全に畳み込みのニューラルネットワークになります。BNとLeakyReLUは、トレーニングの安定性を高めることができます。一部の作業では、GANの残差を使用します。接続不良。
これにより、より深いネットワークを構築できます。
ノイズから高解像度の画像を直接生成することは非常に難しいため、LAPGANではスタック戦略を使用して画像の高周波の詳細を連続して追加します。SGANでは一連のGANカスケードも使用します。GANが異なれば生成も異なります。より浅いレベルの特徴表現; PGGANでは、G / Dネットワークのスケールを拡張するために新しいレイヤーを継続的に追加する段階的な成長方法です。styleGANの戦略は、入力としてノイズzを直接使用するのではなく、に変換することです。ある形。図3にGAN、CatGAN、EBGAN / BEGAN、ALI / BiGAN、InfoGAN、ACGAN、VAEGAN、CGAN、LAPGAN、SGANの具体的な構造を示し、図4にcGAN、CycleGAN、UNITの構造を示します。
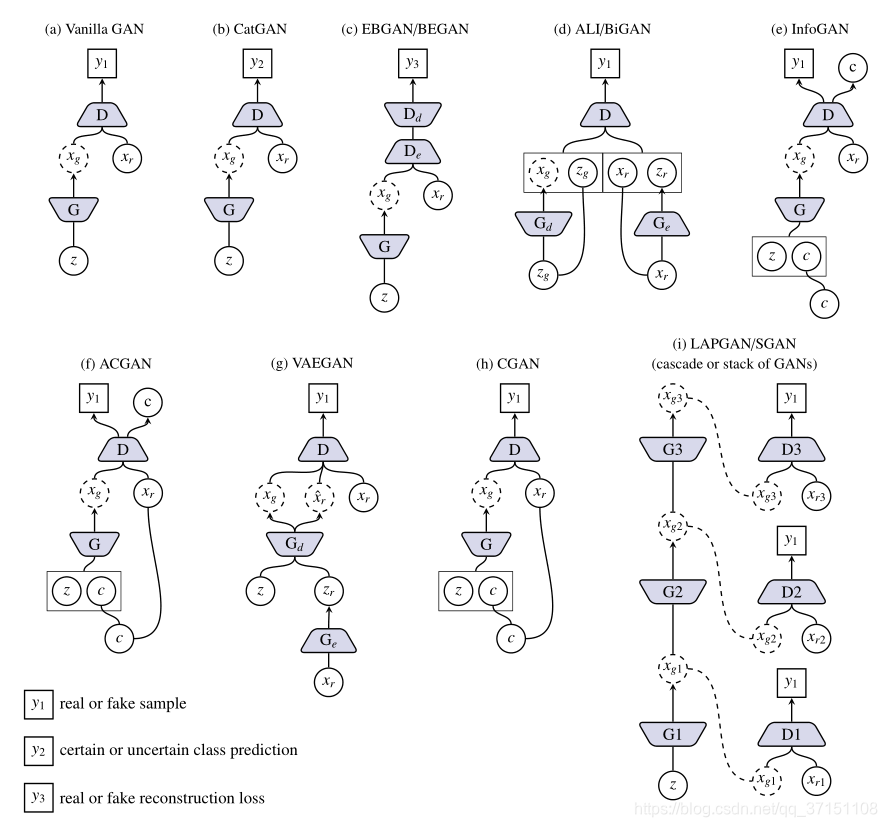

#セクションIII
医療画像へのGANの適用医療画像分析への生成的敵対ネットワークの適用は、主に2つの側面
から始まります。1つは、GAN生成の観点から、GANを使用してトレーニングデータの内部構造を学習し、医療問題を解決するための新しい画像を生成できます。画像が不足しているか、患者のプライバシーを保護する役割を果たしています。
次に、GAN識別の観点から、Discriminatorを使用して異常な画像を識別できます。

図5は、医療画像におけるGANの関連アプリケーションを示しています。afは画像の生成に焦点を当て、gは画像の識別に焦点を当てています。解決すべきさまざまなタスクに応じて、主に次のカテゴリに分類されます:画像再構成、画像合成、画像セグメンテーション、画像分類、臓器検出、画像登録など。
(A)CT画像のノイズ除去(b)MR生成CT(c)網膜血管セグメンテーションマップに基づく眼底画像の生成(d)ランダムノイズからの皮膚病変画像の生成(e)胸部X線に基づく心臓と肺のセグメント化(f)脳損傷のセグメンテーション(g)網膜のOCT異常検出
パートA再構成は
、イメージング機器自体の制限に基づいているため、医療画像には、観察と分析に影響を与えるノイズやアーティファクトが伴うことがよくあります。初期のデータ駆動型トレーニング方法では、通常、入力に基づいて直接再構成が生成されます。後続の出力は、画像処理のステップとして使用されます。画像の解像度が不十分であるか、ノイズ、サンプリングレートが不十分、またはエイリアスが含まれています。MR画像は例外です。元のK空間データは、フーリエ変換によって再構築された画像にマージできます。
現在、CT画像とPET画像のノイズ除去、およびMR再構築にpix2pixフレームワークを使用する研究があります。他の研究は、生成された画像知覚レベルの類似性を確保するための事前トレーニング済みVGGNetの使用、検出ネットワークの代替の使用など、フレームの最適化に専念しています。低解像度領域のノイズ除去、網膜画像の超解像度再構成を改善するためのローカル顕著性マップの使用、ネットワークがいくつかの重要な領域に焦点を合わせるようにするため、MR画像を処理する場合、画像処理にK空間データを正確に使用する方法を検討する必要があります。再建中。
データセットに関しても、一連の問題があります。たとえば、さまざまな医療画像再構成ネットワークの現在のパフォーマンス評価は、主に観察者の主観的評価に依存しており、客観的な比較が不足しています。現在のオープンソースの大規模画像再構成データセットは、医療画像には適していません。再構築分析、この側面は大規模なオープンソースデータセットに継続します。
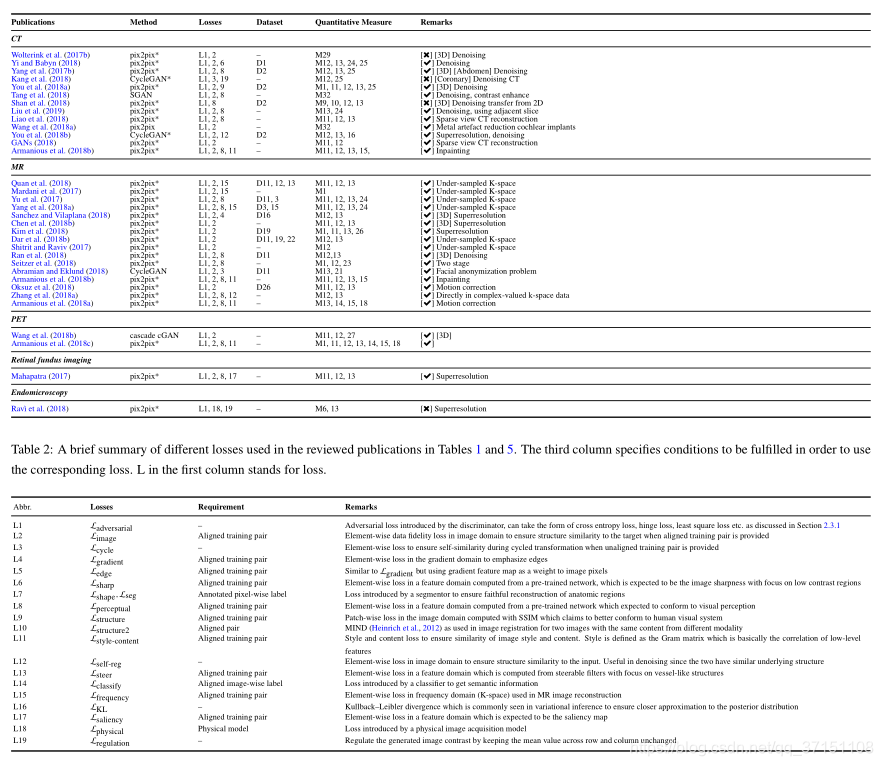
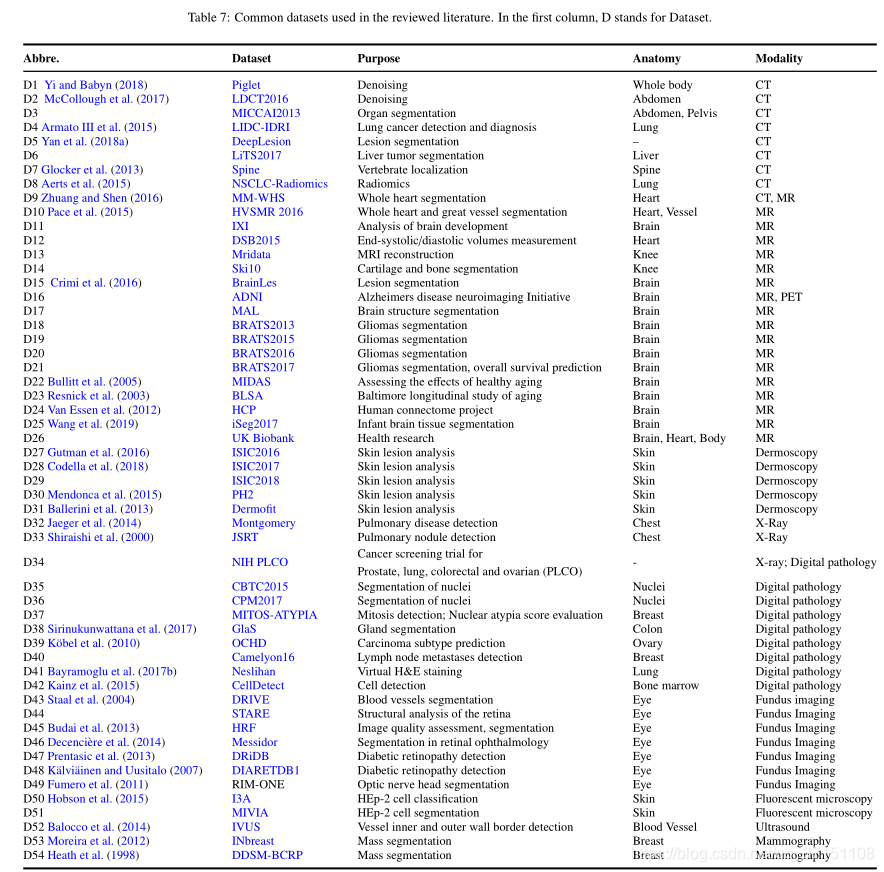
表Iに、医療画像再構成のためのGANの関連作業を示し、対応する損失、評価指標、および使用したデータセットをそれぞれ表2、3、および7に示します。表の正しい番号または間違った番号は、トレーニング中に画像ペアが使用されるかどうかを表しています。
CRやMRなどの医療画像再構成タスクのほとんどがpix2pixフレームワークを使用していることがわかります。ただし、MRデータはやや特殊であり、フーリエ変換が処理に関与しています。さらに、トレーニングデータが多いほど、カウンターロスが使用されます。一般に、ピクセルロスよりも視覚的な再構成効果は優れていますが、歪みが発生する可能性があります。ピクセル損失にはこの問題はありませんが、トレーニングデータとして画像ペアが必要であり、再構成効果はドメインの不一致には適していません。良い;既存の研究は、専門家によって厳密に実証される前に、GANに基づいて生成された再構築された画像は患者の診断に直接使用するのに適していないことを示しています。
表2-損失関数:損失関数
の最適化には、顕著性計算によるさまざまなピクセルへのさまざまな重みの割り当て、およびトレーニング画像の取得が困難な場合の心室CTの超分割再構成のためのCycleGANの使用が含まれます。低用量のCT画像のノイズ除去を実行するときに、pix2pixの忠実度の低下を取り除くこともできます。
表3
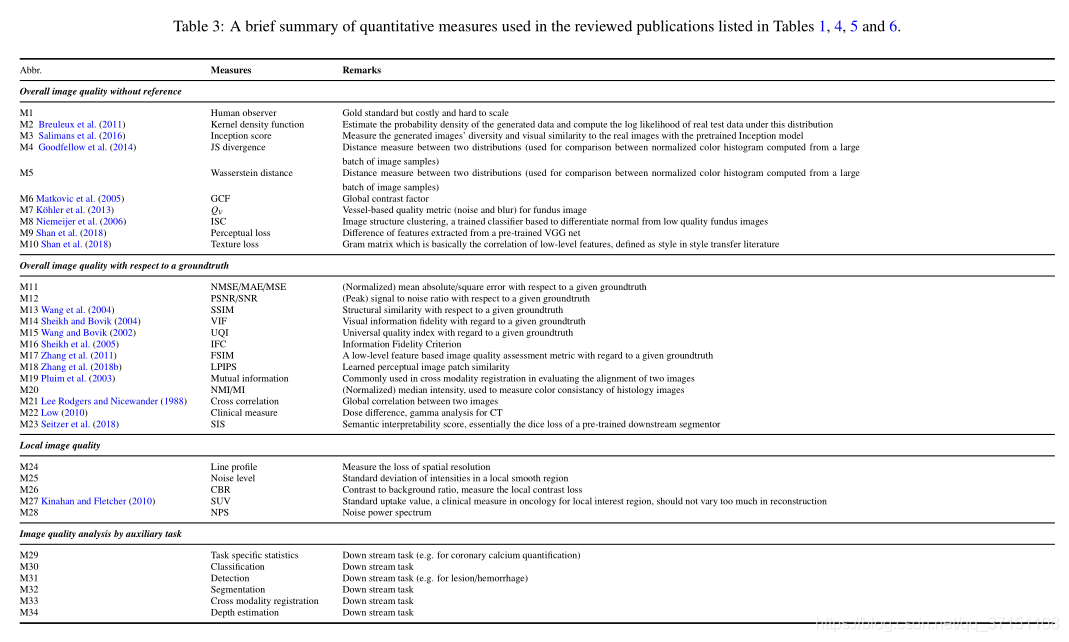 表7-データセット
表7-データセット
パートB医療画像の合成
は、関連機関の規制に従って、患者の医療画像が公開される場合、患者の希望を十分に考慮する必要があります。GANは、患者のプライバシー問題を効果的に回避し、不十分な病理学的画像の問題を解決する医療画像生成で広く使用されています。ただし、Biobank、National Biomedical Imaging Archive(NBIA)、The Cancer Imaging Archive(TCIA)など、このような大規模なデータセットの構築に専念する組織はすでに多数存在しますが、監視対象の学習フレームワークのトレーニング用の専門家による注釈付きの医療画像はまだ非常に不足しています。 、北米放射線技師協会(RSNA)など。
従来のデータ拡張には、スケーリング、回転、ミラーリング、アフィン変換、弾性変換などが含まれますが、特定のカテゴリのサンプルの豊富さは変更されておらず、サイズとサイズのみが変更され、GANによって生成される画像はより多様です。 、多くの作品でデータ拡張の手段として使用され、良好な結果を達成しています。
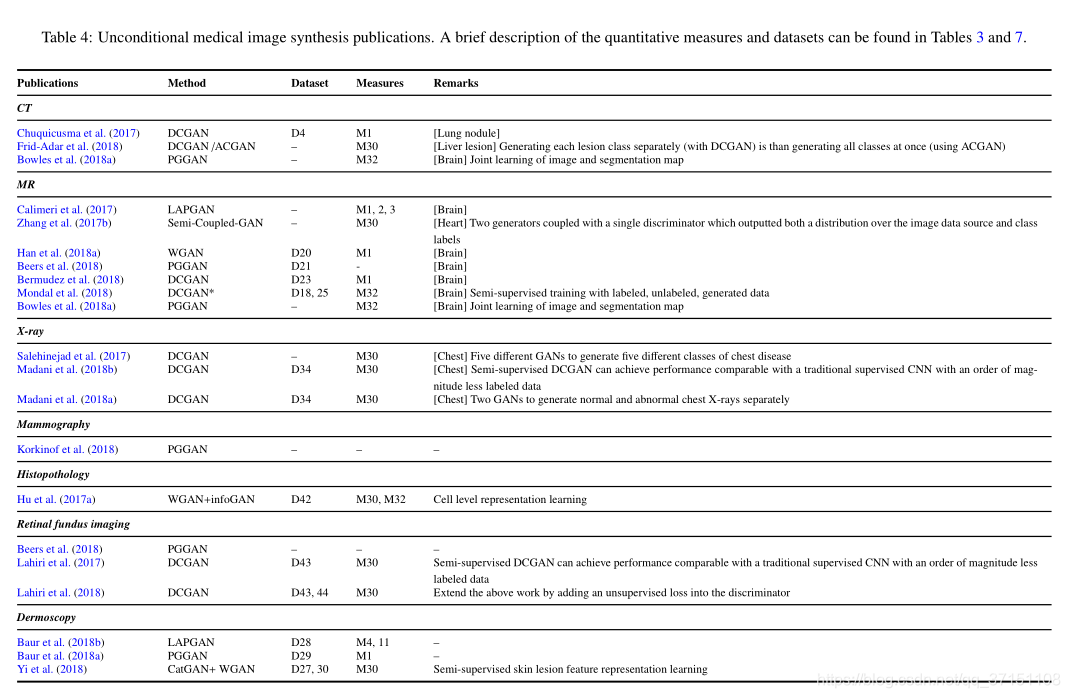
B-1制約のない画像の生成
無条件とは、制約のある情報を追加せずに画像を生成するための入力ランダムノイズを指します。医療画像の生成に一般的に使用されるフレームワークには、トレーニングがより安定しているDCGAN、WGAN、PGGANがあり、最初の2つは許容されます。解像度の上限は256x256で、高解像度では機能しません。肺結節や肝臓の損傷など、生成された画像が元の画像とあまり変わらない場合は、作成者のソースコードを直接移植してみることができます。ほとんどのダウンストリームタスク(事前トレーニング後の微調整に使用)では、データ不足の問題を解決するために、ほとんどのジェネレーターは、さまざまなタイプの肝障害画像など、特定のパターンの画像のみを生成します。生成された画像を使用してデータセットを拡張すると、ある程度改善できます。モデルのSpとSe。
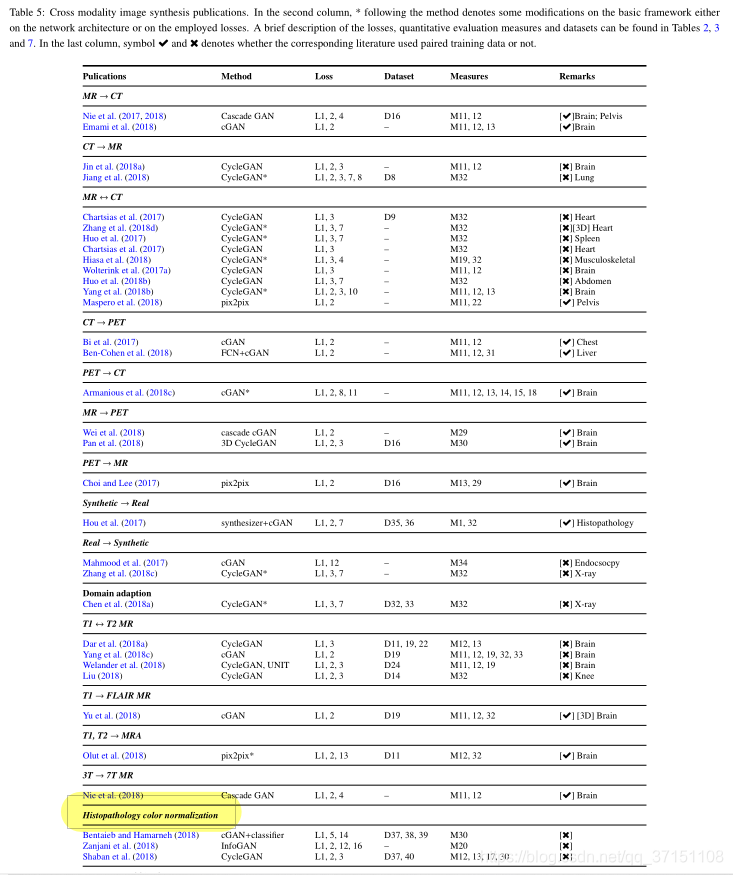
B-2クロスモダリティ画像の生成:
医療画像のクロスモダリティ生成は、MR画像に基づいてCT画像を生成するなど、非常に便利です。これにより、CT画像の取得にかかる時間とコストを効果的に削減できます。また、次のような検索サンプルを生成できるという利点もあります。ソースモーダルイメージのいくつかの構造的制約情報。一般に、2つのモードは高度な類似性を持っており、多くの場合pix2pixフレームワークに基づいています。モーダルの違いが大きい場合は、CycleGANフレームワークに基づいている可能性があります。図5に、クロスモーダル画像生成のためのGANの関連作業を示します。ほとんどのモードがCycleGANフレームワークに基づいていることがわかります。
たとえば、Zhang et al。の研究では、クロスモーダル生成でサイクル損失を使用するだけでは、生成された画像の幾何学的変形を抑制するのに十分ではないことがわかりました。したがって、形状の一貫性損失が追加され、形状の意味表現が2つのセグメンタによって取得されます。画像の歪みを抑えるために、損失の計算に制約が追加されます。さらに、CycleGANとUNITはどちらもクロスモーダル生成に適しています。
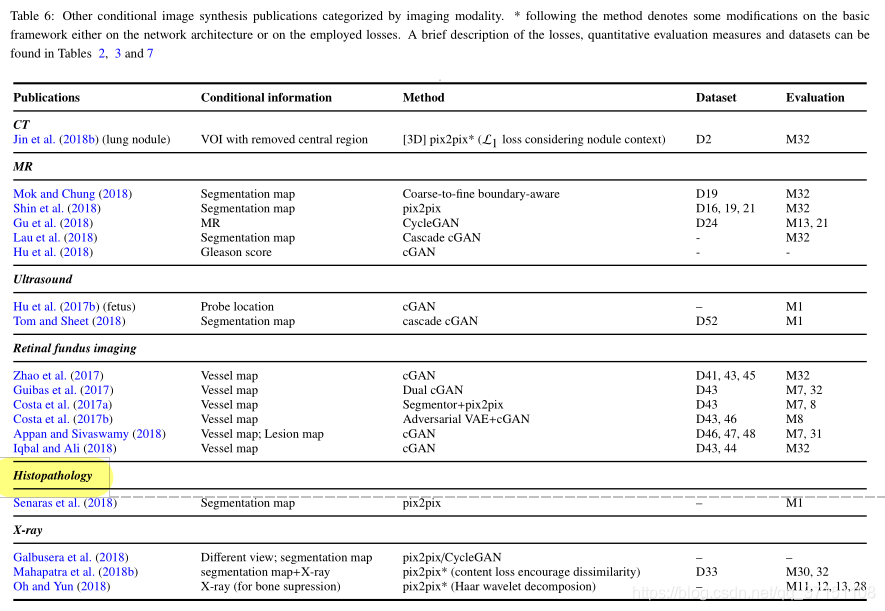
B-3条件付き生成
追加の条件付き情報は、セグメンテーションマップ、テキスト情報、ターゲットの場所、またはGANや事前にトレーニングされたセグメンテーションネットワークなどの生成された画像から取得して、制約付き条件付き情報を生成し、GAN生成ネットワークに送信できます。プロセス全体を2つの段階に分けます。
表6に、条件付き生成(cGAN)と制約情報のさまざまなソースを示します。
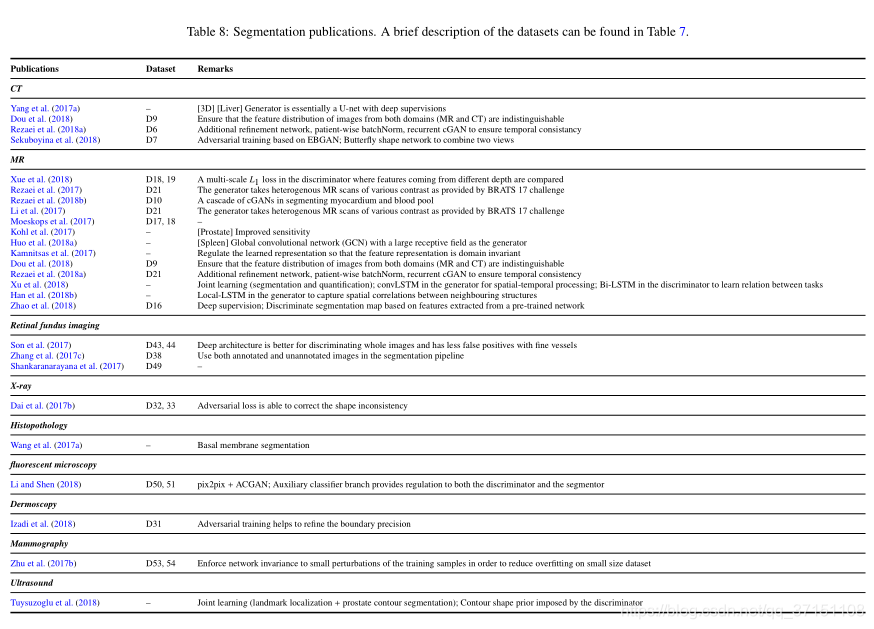
パートCセグメンテーション
セグメンテーションタスクは、クロスエントロピー損失関数の計算など、ピクセルレベルの損失関数を使用します。UNetの提案は、浅い特徴と深い特徴を効果的に組み合わせていますが、最終的なセグメンテーションマップスペースの一貫性を保証することはできません。通常、CRFまたは画像カットを使用して空間制約情報を増やしますが、コントラストが非常に低い一部の領域では、エッジセグメンテーション効果が不十分な場合があります。GANの逆の損失は、特に関心のある領域が比較的コンパクトな場合(心臓と肺のセグメンテーションなど)、形状レギュレーターと見なすことができますが、変形可能なカテーテル、血管などにはそれほど効果的ではありません中間のフィーチャレイヤーに適用すると、ドメインの不変性が保証されます。
損失防止の計算は、セグメンテーションマップとラベル付きGTの間の類似性の尺度ですが、ピクセル間の計算の代わりに、入力を低次元空間にマッピングして、2つの間の類似性を計算します。これは知覚損失と同じです。損失)は比較的近いですが、知覚損失は事前に訓練された分類ネットワークを介して計算され、弁別器はジェネレーターとの対決学習で徐々に進化します。XueはDでマルチスケールL1損失を使用するため、さまざまなスケールの情報を含めることができます。Zhangはラベル付きとラベルなしの両方の写真をDに送信して、Dを混乱させ、Dの識別能力を向上させます。上記の作業では対立を使用します。トレーニングのほとんどは、最終的なセグメント化された画像の構造情報を維持することであり、一部の研究では、GANを使用してモデルの堅牢性を強化し、小さなデータセットでのオーバーフィットの問題を軽減しています。
パートD分類
分類タスクは、間違いなく、深層学習が大きな成功を収めた領域です。ネットワークのさまざまなレベルを通じてさまざまなレベルの画像の特徴を抽出し、画像のカテゴリラベルを取得します。GANは、分類タスクでも広く使用されています。G/ Dの一部を特徴抽出器として使用するものもあれば、Dのみを分類子として使用して、条件情報を追加するものもあります。
現在、一部の学者はWGANとInfoGANを組み合わせて、監視されていない細胞病理学的画像を分類しています。半監視されたトレーニングは、胸部X線写真、網膜血管、心臓病の異常な診断に使用され、監視されたトレーニングCNNと同様の効果を達成できます。 、しかし、必要なトレーニングデータは1桁減少します。
データ拡張のためのGANの使用については、前の記事でも2つのステップを紹介します。フェーズ1は、データ拡張の機能を学習します。フェーズ2は、分類のための従来の分類ネットワークに基づいています。2つのフェーズは、干渉なしに互いに分離されます。利点は、パフォーマンスが向上する場合です。フレームワークは直接置き換えることができます。欠点は、特定のタイプの画像のみが毎回Gで展開できることです。NタイプはN回生成する必要があり、メモリと計算に非常にコストがかかるため、モデルに基づいてマルチモダリティを動的に生成する方法データは、より一般的な研究の方向性です。この点に関して、Frid-Adarの研究では、単一のACGANを使用するよりも、個別のDCGANを使用する方が皮膚の損傷の検出に効果的であることがわかりました。
パートE検出
GANの弁別器は、トレーニング画像データの分布確率を学習することで異常検出を実現します。画像がこの分布から外れると異常となる場合があります。
Schlegl et al。は、各章の画像のスコアを計算することによってOCT画像の異常を検出します。AlexはMR脳損傷の検出にGANを使用します。ここで、Gは入力パッチの分布を模倣するために使用され、Dは入力パッチの後方確率を計算するために使用されます。現在の検出のほとんどは異常な画像に対して実行されており、すべてをリストすることは困難であることがわかります。
画像再構成に関して、いくつかの研究では、症例分析からの画像の分布が研究されたことがなく、CycleGANを使用して画像ペアなしで移行すると、分布のマッチング効果により、生成された画像の病変が除去される可能性があることがわかっています。同じモーダルのデータですが、正常なカテゴリと異常なカテゴリが異なる場合、この副作用は異常検出によって取り除くことができます。
パートF登録
cGANは、マルチモーダルまたはシングルモーダルの画像登録タスクにも使用できます。Gは変換パラメーターを出力するか、変換された画像を直接出力し、Dはそれが整列画像か非整列画像かを判断します。通常、空間変形ネットワークまたは中間変換レイヤーは、エンドツーエンドのトレーニングを確実にするために、これら2つのネットワークの間に挿入されます。実施された関連研究から、それらのほとんどはCycleGANに基づいており、CT、MR、およびその他の異なるモードの画像の位置合わせを完了します。
パートGその他の作業
さらに、GANには、cGANを使用して患者の特定の術前画像を強調表示したり、最も可能性の高い患部を強調表示したり、内視鏡画像の色を変更したりするなど、その他の用途があります。
#セクションIVディスカッション
パートA要約
2017-2018は、GANのさまざまな研究アプリケーションの爆発的な時期を迎えました。関連する参考資料は、この記事のGitHubにあります。
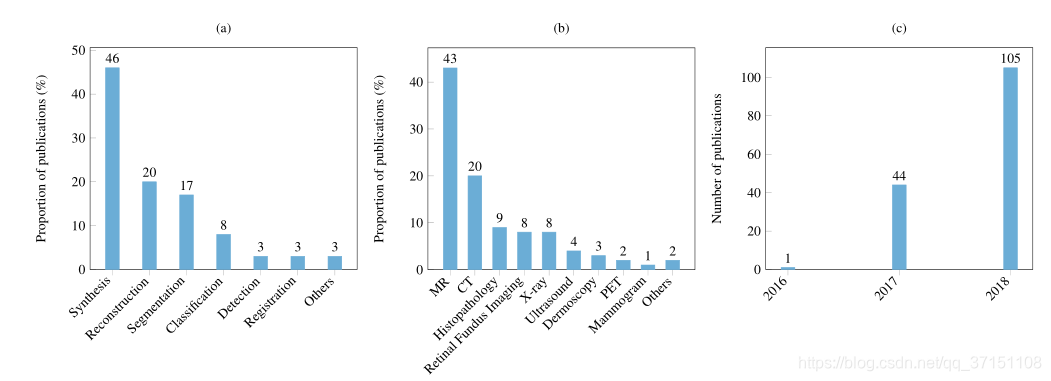
図1(a)は、さまざまなタスク(画像合成、再構成、セグメンテーション、分類、検出、注釈など)でのGANの公開ステータスを示しています。
(b)さまざまな医療画像形式(MR、CT、病理学的画像、光学ディスク画像、 X線、超音波、皮膚鏡検査、PET、マンモグラフィーなど)、
(c)異なる年の出版物では、2018年が大爆発を迎えたことがわかります。
研究の46%は、クロスモーダルデータのために医療画像の生成に焦点を当てていました。医療画像分析では生成が非常に重要です。たとえば、MRはシーケンス画像分析タスクであり、GANは既存のシーケンスに基づいて他のシーケンスを生成できるため、MRの生成時間が短縮されます。MR研究への熱意のもう1つの理由も大きい可能性があります。より多くのオープンソースデータセットがあります。
関連する研究の別の37%は、画像のセグメンテーションと再構築に焦点を当てています。その理由は、画像から画像への変換フレームワークの成熟度です。敵のトレーニングに形状やテクスチャの制約を追加することで、Gは3DCTなどの非常に理想的な画像を出力できます。画像のセグメンテーションは、カウンターロスを効果的に増加させ、コントラストの低い領域のセグメンテーション効果を改善します。
主にドメイン移行の問題を解決するために、約8%が分類タスクを研究しています。データエンハンスメントにGANを使用する場合、焦点のほとんどは、肺の小結節や細胞など、現在の最先端技術に基づいてより安定している可能性のある小さな前景オブジェクトを含む画像にあります。計算コストも考慮される場合があります。高解像度の画像は、コンピューティングリソースを大量に消費します。胸部X線の分類に成功した研究もありますが、タスクの規模は比較的小さく、数千枚の写真があり、タスクは比較的単純で、脳室の異常を検出します。
CheXpertなどの一部の大規模なデータセットのオープンソースでは、データ拡張のためのGANの需要が減少する可能性がありますが、それでも次の2つの側面で役立ちます。
まず、現在手動設計に限定されているデータ拡張戦略の多様性を高めます。さまざまなクロッピングローテーションアフィン変換などは、GANを使用して変換の多様性を高めることができます。
2つ目は、医療画像のトレーニングサンプルが非常に不均一で、サンプルのほとんどが一般的な疾患であり、関節リウマチや鎌型赤芽球血症などのいくつかの一般的でない疾患のトレーニングデータが非常に少ないため、cGANなどを使用できることです。専門家の説明または手描きの図面から、異常な疾患のトレーニングサンプルを生成します。
パートBの課題
GANは医療画像分析に多くの用途がありますが、それでも多くの課題があります。たとえば、画像再構成やクロスモーダル生成で使用される評価指標は、依然としてPSNR、SSIMなどであり、視覚的観察の品質に直接関係していません。たとえば、ピクセル損失に基づく最適化は、評価指標は良好に見えますが、最適化されていない結果になります。ただし、実際の観測にはまだあいまいさが多く、再構成・生成された画像に基づいてセグメンテーションや分類などのダウンストリームテストを行い、再構成の効果を測定することで解決できます。
最近、Zhangらは評価指標としてLPIPS(学習した知覚画像パスの類似性)を提案し、MedGANで使用しました。もう1つの問題は、ドメイン間の画像変換の問題です。画像ペアを使用する必要があるものと、画像ペアを必要としないものがあります。画像ペアが該当しない場合、画像の詳細の忠実度は保証されません。いくつかの研究では、画像変換にCycleGANを使用するとシステムバイアスが導入されることが示されています。このバイアスは、画像を使用してトレーニングされたcGANにも存在しますが、通常のデータのトレーニングや異常なテストなど、ドメインの移行中にほとんど発生します。例。
パートC興味深い将来のアプリケーション
GANの力は、監視されていない方法または監視されていない方法で学習できることです。これにより、画像分析プロセスが簡素化され、患者のケアが向上します。
たとえば、cGANは、MR画像の動きによって引き起こされるアーティファクトを除去するために使用されるため、繰り返しの撮影回数を減らすことができます。一部の研究では、GANを使用して医療分析レポートを半自動で生成でき、CycleGANを使用してメイクアップとメイクアップを削除したり、医療画像からアーティファクトを削除したりできます。異常な検出に加えて、ペースメーカーなどの埋め込みデバイスの検出をさらに拡張できます。そして人工弁など。
StyleGANの研究は、テキストから画像への実現の可能性を提供し、トレーニングデータの不足を補うために、希少疾患の専門家の説明に従って対応するトレーニングサンプルを生成できます。また、疾患の発症や薬剤の操作メカニズムを予測することもできます。
医療画像分析では、通常、同じ組織のさまざまな種類の医療画像が相互に補完する必要があります。包括的な分析では、監視付き学習では、一度に1つのモダリティしかトレーニングできません。使用するネットワークフレームワークは同じですが、繰り返す必要があります。 ;そしてGANはこの繰り返しのプロセスを回避し、人件費の無駄を減らします。
これまで、熱狂は医療画像分析の分野でGANの魅力的な応用の見通しをもたらしましたが、医療画像分析のためのGANの使用はまだ初期段階であり、実際の成熟した臨床応用結果はないことを認めなければなりません。