Apache Kafkaは、マイクロサービス間の非同期通信の主流プラットフォームになりました。堅牢で柔軟な非同期アーキテクチャを構築できるようにする多くの強力な機能があります。
同時に、それを使用する過程で多くの潜在的な落とし穴に注意する必要もあります。起こりうる問題を事前に(つまり遅かれ早かれ)検出できないと、エラーやデータの破損が発生しやすいシステムに直面します。
この記事では、落とし穴の1つであるメッセージを処理しようとしたときの失敗に焦点を当てます。まず、メッセージの消費は遅かれ早かれ失敗する可能性があり、失敗することを認識する必要があります。次に、このような障害に対処するときに問題が発生しないようにする必要があります。
カフカ入門
この記事を読む読者は全員、Kafkaを理解している必要があります。Kafkaとその使用方法を紹介する詳細な記事もインターネット上にいくつかあります。そうは言っても、私たちの議論にとって重要ないくつかの概念を簡単に復習しましょう。
イベントログ、発行者、消費者
Kafkaは、データストリームを処理するために使用されるシステムです。概念的には、Kafkaは次の3つの基本コンポーネントを含むと考えることができます。
- イベントログ(イベントログ) 、ニュースはそこに掲載されます
- パブリッシャー(パブリッシャー)、メッセージをイベントログに公開します
- コンシューマー(コンシューマー)、イベントログ内のメッセージを消費(つまり使用)
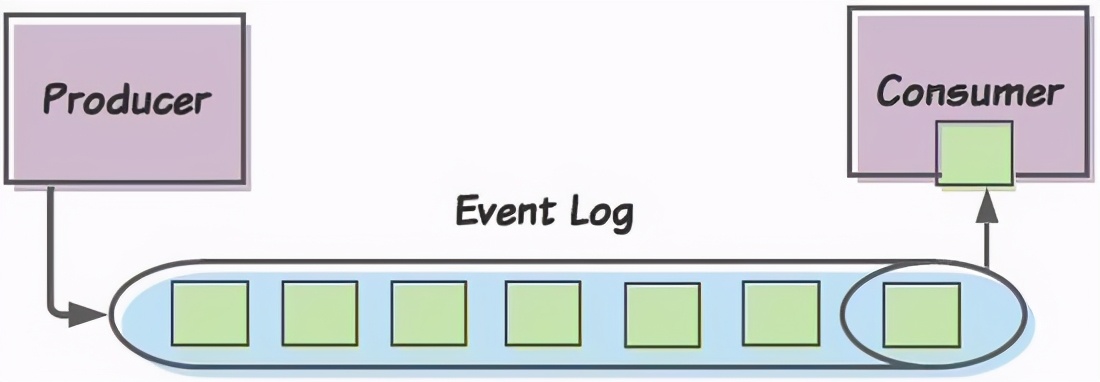
RabbitMQなどの従来のメッセージキューとは異なり、Kafkaを使用すると、コンシューマーはメッセージを読み取るタイミングを決定できます(つまり、Kafkaはプッシュモードではなくプルモードを使用します)。各メッセージには オフセット(オフセット) があり、各コンシューマーは最新の消費メッセージのオフセットを追跡(または送信)します。このようにして、消費者はこのメッセージのオフセットを介して次のメッセージを要求できます。
テーマ
イベントログはいくつかのトピック に分割されて おり、各トピックで公開されるメッセージのタイプが定義されています。件名の定義はエンジニアの責任であるため、いくつかの経験則を覚えておく必要があります。
- 各トピックでは、他のサービスが知っておく必要のあるイベントについて説明する必要があります。
- 各トピックは、各メッセージが従う一意のスキーマを定義する必要があります。
パーティションとパーティションキー
トピックはさらに複数のパーティションに分割されます 。パーティショニングにより、メッセージを並行して消費できます。Kafkaを使用すると、 パーティションキーで 各パーティションにメッセージを決定論的に配布できます。パーティションキーはデータの一部(通常、IDなどのメッセージ自体の一部の属性)であり、その上にアルゴリズムが適用されてパーティションが決定されます。
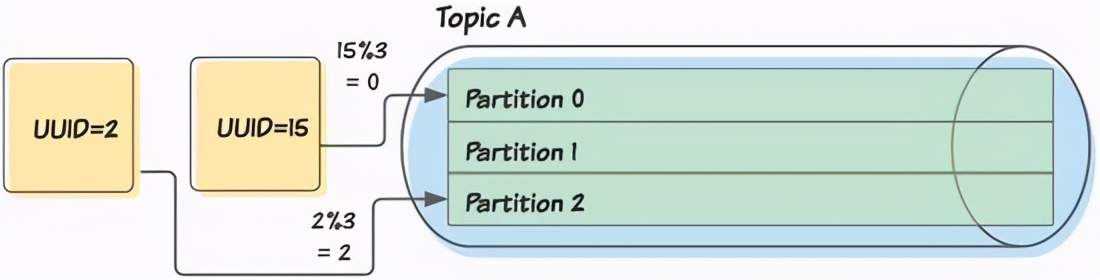
ここでは、メッセージのUUIDフィールドをパーティションキーとして割り当てます。プロデューサーは、アルゴリズム(パーティションの数に応じて各UUID値を変更するなど)を適用して、各メッセージをパーティションに割り当てます。
このようにパーティションキーを使用すると、特定のIDに関連付けられたすべてのメッセージが単一のパーティションに確実に公開されるようになります。
コンシューマーの複数のインスタンスをコンシューマーグループとしてデプロイできることにも注意してください。Kafkaは、特定のパーティション内のすべてのメッセージが、グループ内の同じコンシューマーインスタンスによって常に読み取られるようにします。
マイクロサービスでKafkaを使用する
カフカは非常に強力です。そのため、さまざまなユースケースをカバーするさまざまな環境で使用できます。ここでは、マイクロサービスアーキテクチャの最も一般的な使用法に焦点を当てます。
制限されたコンテキスト間でメッセージを渡す
私たちが最初にマイクロサービスの構築を開始したとき、私たちの多くは最初に集中型モデルを採用しました。各データには、主流の単一のマイクロサービス(つまり、信頼できる唯一の情報源)があります。他のマイクロサービスがこのデータにアクセスする必要がある場合、同期呼び出しを開始してデータを取得します。
このアプローチは、長い同期コールチェーン、単一障害点、チームの自律性の低下など、多くの問題を引き起こしました。
最後に、より良い方法を見つけました。今日の成熟したアーキテクチャでは、通信をコマンド処理とイベント処理に分割します。
コマンド処理は通常、単一の制限されたコンテキストで実行され、同期通信が含まれることがよくあります。
一方、イベントは通常、制限されたコンテキストのサービスによって発行され、他の制限されたコンテキストのサービスで使用するために非同期でKafkaに公開されます。
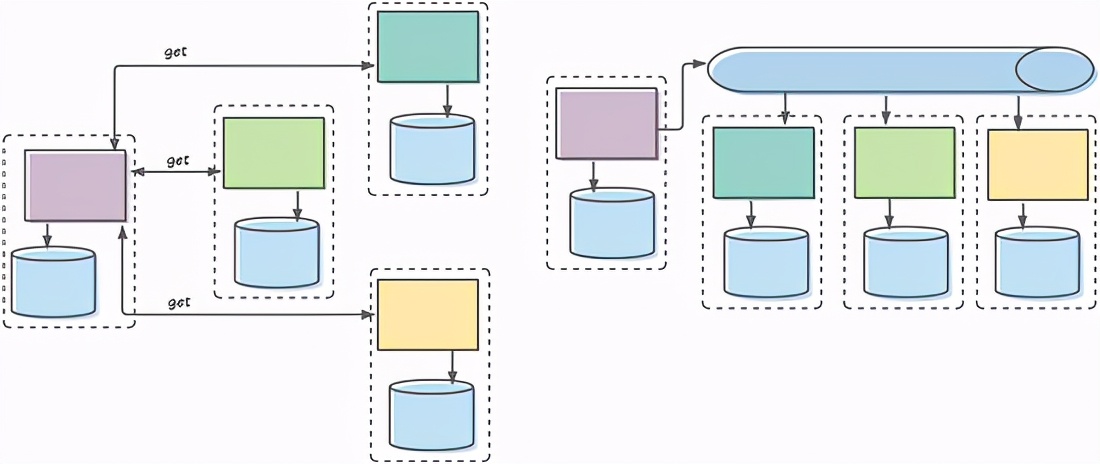
左側は、以前にマイクロサービス通信を設計した方法です。制限されたコンテキストのサービス(破線のボックスで表されます)は、他の制限されたコンテキストのサービスから同期呼び出しを受信します。右側は、今日私たちが行っていることです。制限されたコンテキストのサービスはイベントを公開し、他の制限されたコンテキストのサービスは、アイドル状態のときにイベントを消費します。
たとえば、例としてユーザー制限コンテキストを取り上げます。ユーザーチームは、新しいユーザーの有効化や既存のユーザーアカウントの更新などのタスクを担当するアプリケーションとサービスを構築します。
ユーザーアカウントを作成または変更した後、UserAccountサービスは対応するイベントをKafkaに公開します。関心のある他の制限されたコンテキストは、イベントを消費し、ローカルに保存し、他のデータで拡張することができます。たとえば、ログイン制限コンテキストは、ログイン時にユーザーに挨拶するために、ユーザーの現在の名前を知りたい場合があります。
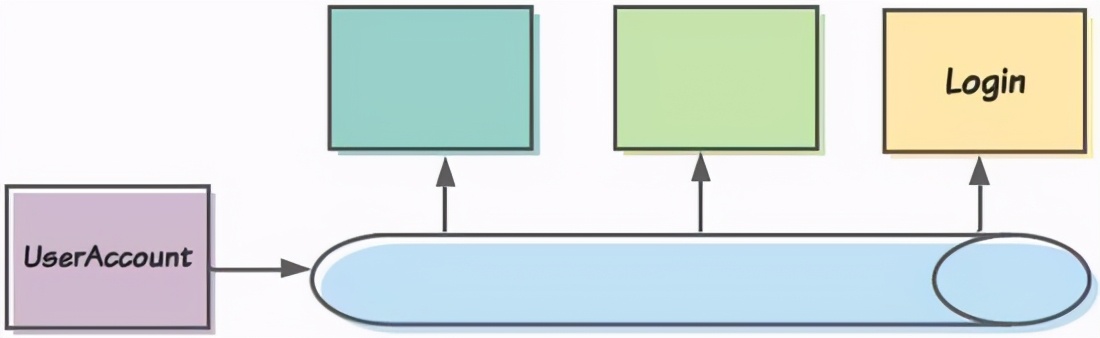
このユースケースを境界を越えたイベント公開と呼びます。
国境を越えたイベントの公開を実行するときは、Aggregateを公開する必要があります。集約はエンティティの自己完結型グループであり、各エンティティは個別のアトミックエンティティとして扱われます。すべての集計には「ルート」エンティティと、追加データを提供するいくつかの従属エンティティがあります。
アグリゲーションを管理するサービスがメッセージを公開する場合、メッセージのペイロードはアグリゲーションの表現(JSONやAvroなど)になります。重要なことは、サービスがアグリゲートの一意の識別子をパーティションキーとして指定することです。これにより、特定の集約エンティティへの変更が同じパーティションに公開されるようになります。
何か問題が発生した場合はどうすればよいですか?
Kafkaの国境を越えたイベント公開メカニズムは非常に洗練されていますが、結局のところ分散システムであるため、システムに多くのエラーが発生する可能性があります。おそらく最も一般的な厄介な問題に焦点を当てます。消費者は、消費するメッセージを正常に処理できない可能性があります。
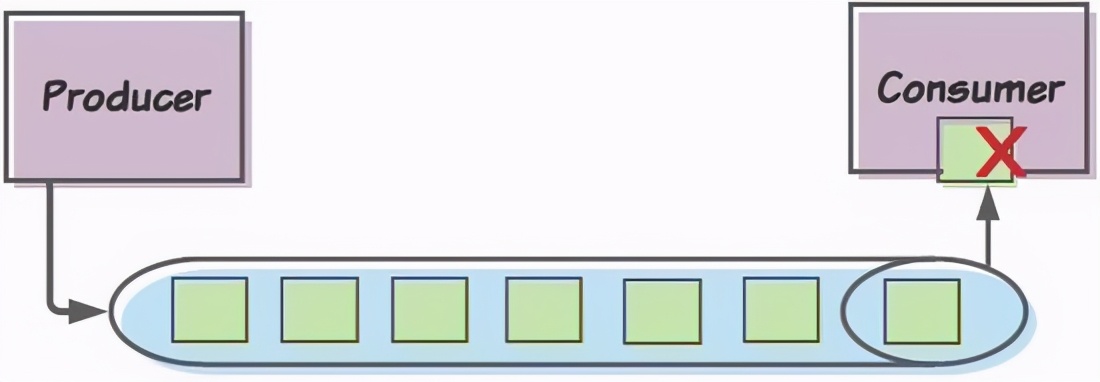
何をするべきだろう?
確かにこれは問題です
チームが最初に間違えたのは、それが潜在的な問題であることに気づかなかったことです。ニュースの失敗は時々起こります、そして私達はそれに対処するための戦略を開発する必要があります...それを修正するのではなく、前もって計画するために。
したがって、これを理解することは遅かれ早かれ起こる問題であり、ターゲットを絞ったソリューションを設計することが私たちが行う必要のある最初のステップです。これを達成した場合は、少しおめでとうございます。最大の問題はまだ残っています:この状況にどのように対処するのですか?
そのメッセージを再試行し続けることはできませんか?
デフォルトでは、コンシューマーがメッセージを正常に消費しない場合(つまり、コンシューマーが現在のオフセットを送信できない場合)、同じメッセージを再試行します。したがって、このデフォルトの動作にすべてを引き継いで、成功するまでメッセージを再試行させることはできませんか?
問題は、このメッセージが成功しない可能性があることです。少なくとも、何らかの形の手動介入なしでは成功しません。その結果、消費者は後続のメッセージを処理し続けることができなくなり、メッセージ処理に問題が発生します。
さて、そのメッセージを単にスキップすることはできませんか?
通常、同期要求は失敗します。たとえば、UserAccountサービスへの「create-user」POSTには、誤ったデータや欠落しているデータが含まれている可能性があります。この場合、エラーコード(HTTP 400など)を返し、呼び出し元に再試行するように依頼するだけです。
このアプローチは理想的ではありませんが、データの整合性に長期的な問題を引き起こすことはありません。そのPOSTは、まだ実行されていないコマンドを表します。失敗させても、データは一貫した状態に保たれます。
これは、メッセージを破棄する場合には当てはまりません。メッセージは、発生したイベントを示します。これらのイベントを無視するコンシューマーは、イベントを生成したアップストリームサービスと同期しなくなります。
これはすべて、メッセージを破棄したくないことを示しています。
では、この問題をどのように解決するのでしょうか。
これは私たちにとって簡単な問題ではありません。したがって、解決する必要があることに気づいたら、インターネットで解決策を探すことができます。しかし、これは私たちの2番目の質問につながります:私たちが従わないかもしれないいくつかの提案がインターネット上にあります。
再試行トピック:人気のあるソリューション
最も人気のある解決策の1つは、再試行トピックの概念であることがわかります。具体的な詳細は実装ごとに異なりますが、全体的な概念は次のとおりです。
- 消費者は、主要な件名でメッセージを消費しようとします。
- メッセージが正しく消費されない場合、コンシューマーはメッセージを最初の再試行トピックに投稿し、次のメッセージの処理を続行するためにメッセージのオフセットを送信します。
- 再試行トピックにサブスクライブするのは再試行コンシューマーであり、メインコンシューマーと同じロジックが含まれています。コンシューマーは、メッセージの消費試行の間に短い遅延を導入しました。コンシューマーがメッセージを消費できない場合、メッセージは別の再試行トピックに公開され、メッセージのオフセットが送信されます。
- このプロセスは続行され、いくつかの再試行トピックと再試行コンシューマーが追加され、各再試行遅延が増加します(バックオフ戦略として使用されます)。最後に、消費者が特定のメッセージを処理できないことを最終的に再試行した後、メッセージはDead Letter Queue(DLQ)に投稿され、エンジニアリングチームが手動で分類します。
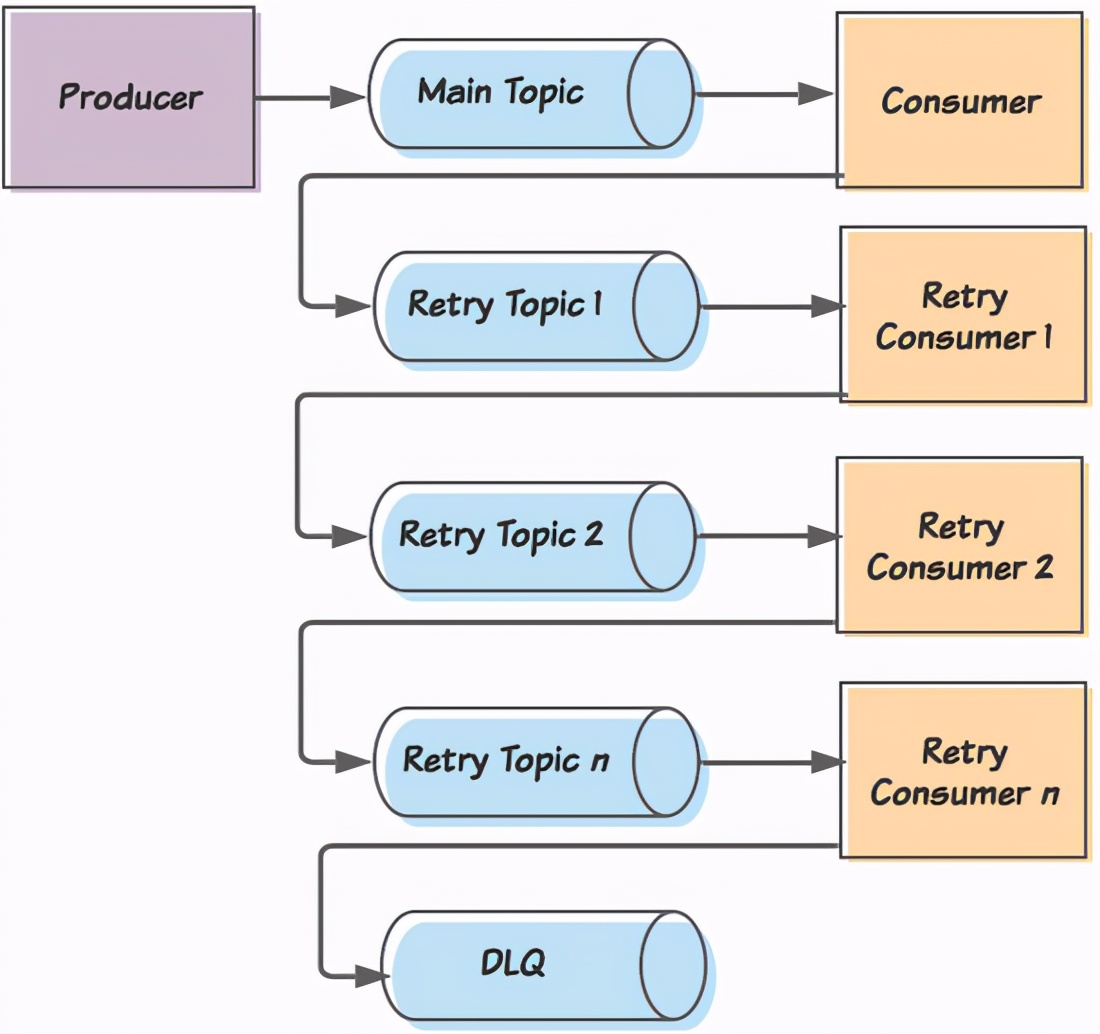
概念的には、トピックの再試行モードは、失敗したメッセージが転送される複数のトピックを定義します。メイントピックのコンシューマーが処理できないメッセージを消費した場合、メッセージを公開してトピック1を再試行し、現在のオフセットを送信して、次のメッセージに解放します。再試行トピックのコンシューマーはメインコンシューマーのコピーになりますが、メッセージを処理できない場合は、新しい再試行トピックに投稿されます。最終的に、最後の再試行コンシューマーがメッセージを処理できない場合、メッセージはデッドレターキュー(DLQ)に送信されます。
問題はどこだ?
この方法は合理的なようです。実際、多くのユースケースで正常に機能します。問題は、それが一般的な解決策として役立つことができないということです。実際には、いくつかの特別なユースケース(国境を越えたイベントの公開など)があります。これらのユースケースでは、この方法は実際には危険です。
さまざまなタイプのエラーを無視します
最初の問題は、イベント消費の失敗の2つの主な原因である回復可能なエラーと回復不可能なエラーが考慮されていないことです。
回復可能なエラーとは、複数回再試行した場合、これらのエラーが最終的に解決されることを意味します。簡単な例は、データをデータベースに保存するコンシューマーです。データベースが一時的に利用できない場合、次のメッセージが通過したときにコンシューマーは失敗します。データベースが再び利用可能になると、コンシューマーはメッセージを再度処理できます。
別の観点から:回復可能なエラーとは、メッセージとコンシューマーの外部に根ざしたエラーを指します。このエラーを解決した後、消費者は何も起こらなかったかのように進みます。(ここでは多くの人が混乱しています。「回復可能」という用語は、アプリケーション自体(この例ではコンシューマー)を回復できることを意味するのではなく、外部リソースを指します。この例では、データベースです。失敗し、最終的には回復します。)
回復可能なエラーについて注意することは、それらが主題に関するほとんどすべてのメッセージを悩ますことです。トピック内のすべてのメッセージは同じ構造に従い、同じタイプのデータを表す必要があることを思い出してください。同様に、私たちの消費者は、主題に関するすべてのイベントに対して同じアクションを実行します。したがって、データベースの中断が原因でメッセージAが失敗した場合、メッセージB、メッセージCなども失敗します。
回復不能なエラーとは、何度再試行しても失敗するエラーです。たとえば、メッセージにフィールドがない場合、NullPointerExceptionが発生したり、特殊文字を含むフィールドによってメッセージが解析できなくなったりする場合があります。
回復可能なエラーとは異なり、回復不可能なエラーは通常、単一の孤立したメッセージに影響します。たとえば、メッセージAのみに解析できない特殊文字が含まれている場合、メッセージBは成功し、メッセージCなども成功します。
回復可能なエラーとは異なり、回復不可能なエラーを解決するには、コンシューマー自体を修正する必要があります(メッセージ自体を「修正」しないでください。これらは不変のレコードです!)。たとえば、null値を適切に処理するためにコンシューマーを修正してから、再デプロイします。
では、これは再試行テーマソリューションと何の関係があるのでしょうか?
手始めに、回復可能なエラーには特に役立ちません。外部の問題が解決されるまで、回復可能なエラーは現在のメッセージだけでなく、すべてのメッセージに影響することを忘れないでください。したがって、失敗したメッセージを再試行トピックに転送すると、次のメッセージのチャネルがクリアされることは確実です。ただし、次のメッセージも失敗し、次のメッセージと次のメッセージも失敗します。問題が解決するまで、消費者に再試行させたほうがよいでしょう。
回復不能なエラーはどうですか?再試行キューは、これらの状況で役立ちます。厄介なメッセージが後続のすべてのメッセージの消費を妨げる場合、メッセージを迂回させることでユーザー消費の障壁が確実にクリアされることは間違いありません(もちろん、複数の再試行トピックは不要です)。
ただし、再試行キューは、回復不能なエラーに苦しんでいるメッセージコンシューマーが前進し続けるのに役立ちますが、さらに隠れた危険をもたらす可能性もあります。以下では、背後にある理由をさらに分析します。
並べ替えを無視します
国境を越えたイベントの発表にあるいくつかの重要なリンクを簡単に確認しましょう。制限されたコンテキストでコマンドを処理した後、対応するイベントをKafkaトピックに公開します。アグリゲートのIDをパーティションキーとして指定することが重要です。
何でこれが大切ですか?これにより、特定のアグリゲートへの変更が同じパーティションに公開されることが保証されます。
さて、なぜこれがそれほど重要なのですか?イベントが同じパーティションに投稿されると、イベントが発生した順序で処理されることが保証されます。同じ集計に継続的な変更が加えられ、結果のイベントが異なるパーティションに公開されると、競合状態が発生する可能性があります。つまり、コンシューマーは最初の変更の前に2番目の変更を消費します。これにより、データの不整合が発生する可能性があります。
簡単な例を見てみましょう。User Bounded Contextは、ユーザーが名前を変更できるようにするアプリケーションを提供します。ユーザーは自分の名前をZoeyからZoëに変更し、すぐにZoeeeに変更しました。順序を気にしない場合、ダウンストリームのコンシューマー(ログイン制限コンテキストなど)が最初にZoieeの変更を処理し、すぐにZoëで上書きする場合があります。
現在、ログインデータはユーザーデータと同期していません。さらに厄介なのは、Zoeeeが当社のWebサイトにログオンするたびに、「Welcome、Zoë!」というログインプロンプトが表示されることです。
これは、再試行テーマが実際に失敗した場所です。これらにより、消費者はイベントの処理順序を簡単に混乱させることができます。Zoëの変更の処理中にコンシューマーが一時的なデータベースの停止の影響を受けた場合、メッセージは再試行トピックに転送され、後で再試行されます。Zoieの変更が到着したときにデータベースの停止が修正された場合、メッセージはZoëの変更によって上書きされる前に正常に処理されます。
問題を説明するために、ここではZoiee /Zoëなどの簡単な例を使用します。実際、イベントを順不同で処理すると、さまざまなデータ破損の問題が発生する可能性があります。さらに悪いことに、これらの問題はそもそもほとんど気づかれません。それどころか、それらが引き起こすデータの破損は、しばらくの間気付かれないことがよくありますが、損傷の程度は時間とともに増加します。一般的に言って、何が起こったのかを理解すると、多くのデータが影響を受けています。
いつサブジェクトを再試行できますか?
明確にするために、再試行テーマは必ずしも間違ったパターンではありません。もちろん、いくつかの適切なユースケースもあります。具体的には、このモデルは、消費者の仕事が変更不可能なレコードを収集することである場合にうまく機能します。この例には、次のものが含まれます。
- ウェブサイトの活動の流れを処理してレポートを生成する消費者
- 元帳にトランザクションを追加する消費者(これらのトランザクションを特定の順序で追跡する必要がない場合)
- 別のデータソースからのETLデータである消費者
このような消費者は、データ破損のリスクなしにテーマモードを再試行することで恩恵を受ける可能性があります。
ただし、ご注意ください
そのようなユースケースが存在する場合でも、注意して進める必要があります。このようなソリューションの構築は複雑で時間がかかります。したがって、組織として、新しい消費者ごとに新しいソリューションを作成することは望んでいません。代わりに、さまざまなサービス間で再利用できる、ライブラリやコンテナなどの統合ソリューションを作成したいと考えています。
別の問題があります。関連する消費者向けに再試行テーマソリューションを構築する場合があります。残念ながら、このソリューションはまもなく国境を越えて消費者を公開する分野に参入します。これらの消費者を所有するチームは、リスクを認識していない可能性があります。前に説明したように、大規模なデータ破損が発生する前に、問題を認識していない可能性があります。
したがって、再試行テーマソリューションを実装する前に、次のことを100%確認する必要があります。
- 私たちのビジネスには、既存のデータを更新する消費者は決していないでしょう。
- 再試行テーマソリューションがそのような消費者に実装されないように、厳格な管理措置を講じています
このモデルをどのように改善できますか?
テーマパターンの再試行は、国境を越えて消費者を公開するための許容可能なソリューションではない可能性があることを考えると、それを改善するためにいくつかの調整を行うことができますか?
当初、この記事は完全なソリューションを提供したいと考えていました。しかし、私は、万能の道はないことに気づきました。したがって、適切なソリューションを開発する際に考慮する必要があるいくつかの事項についてのみ説明します。
エラータイプを排除する
回復可能なエラーと回復不可能なエラーの間のあいまいさを排除できれば、作業ははるかに簡単になります。たとえば、消費者が回復可能なエラーを経験し始めた場合、サブジェクトの再試行は冗長になります。
したがって、発生したエラーのタイプを判別することができます。
void processMessage(KafkaMessage km) {
try {
Message m = km.getMessage();
transformAndSave(m);
} catch (Throwable t) {
if (isRecoverable(t)) {
// ...
} else {
// ...
}
}
}コードをコピーする
上記のJava擬似コードの例では、isRecoverable()はホワイトリストメソッドを使用して、tが回復可能なエラーを表すかどうかを判断します。つまり、tをチェックして、既知の回復可能なエラー(SQL接続エラーやReSTクライアントタイムアウトなど)と一致するかどうかを判断し、一致する場合はtrueを返し、一致しない場合はfalseを返します。これにより、回復不能なエラーによって消費者がブロックされるのを防ぐことができます。
もちろん、回復可能なエラーと回復不可能なエラーを明確にすることは難しい場合があります。たとえば、SQLExceptionは、データベース障害(回復可能)または制約違反(回復不能)を参照する場合があります。疑わしい場合は、おそらくエラーが回復不能であると想定する必要があります-これのリスクは、隠されたトピックに他の良いメッセージを送信し、それによってそれらの処理を遅らせることです...しかし、それは私たちが誤って泥沼に入るのを防ぐこともできます、無限に試してください回復不能なエラーに対処するため。
コンシューマー内で回復可能なエラーを再試行します
すでに説明したように、回復可能なエラーがある場合、再試行トピックにメッセージを投稿しても意味がありません。次のメッセージの失敗への道を明らかにするだけです。代わりに、コンシューマーは状態が復元されるまで単に再試行できます。
もちろん、回復可能なエラーは、外部リソースに問題があることを意味します。このリソースのリクエストは無駄に送信し続けます。したがって、再試行にはバックオフ戦略を適用する必要があります。胃のJavaコードは次のようになります。
void processMessage(KafkaMessage km) {
try {
Message m = km.getMessage();
transformAndSave(m);
} catch (Throwable t) {
if (isRecoverable(t)) {
doWithRetry(m, Backoff.EXPONENTIAL, this::transformAndSave);
} else {
// ...
}
}
}コードをコピーする
(注:使用するバックオフメカニズムは、特定のしきい値に達したときにアラートを出し、重大なエラーの可能性があることを通知するように構成する必要があります)
回復不能なエラーが発生した場合は、メッセージを最後のトピックに直接送信してください
一方、コンシューマーが回復不能なエラーに遭遇した場合は、メッセージをすぐに隠して、後続のメッセージを解放したい場合があります。しかし、ここで複数の再試行トピックを使用すると便利ですか?答えは否定的です。DLQに移る前に、メッセージで発生するのはn回の消費エラーのみです。では、最初からメッセージを貼り付けてみませんか?
再試行テーマと同様に、このテーマ(ここでは非表示テーマと呼びます)には独自のコンシューマーがあり、メインコンシューマーと一致しています。ただし、DLQと同様に、このコンシューマーは常にメッセージを消費しているわけではありません。明らかに必要な場合にのみメッセージを消費します。
並べ替えを検討する
ソートの状況を見てみましょう。ここでは、前の「ユーザー/ログイン」の例を再利用します。Zoë名のë文字を処理しようとすると、Loginコンシューマーでエラーが発生する場合があります。コンシューマーはそれを回復不能なエラーとして認識し、メッセージを脇に置き、後続のメッセージの処理を続行します。その後すぐに、消費者はZoieeメッセージを受け取り、それを正常に処理します。
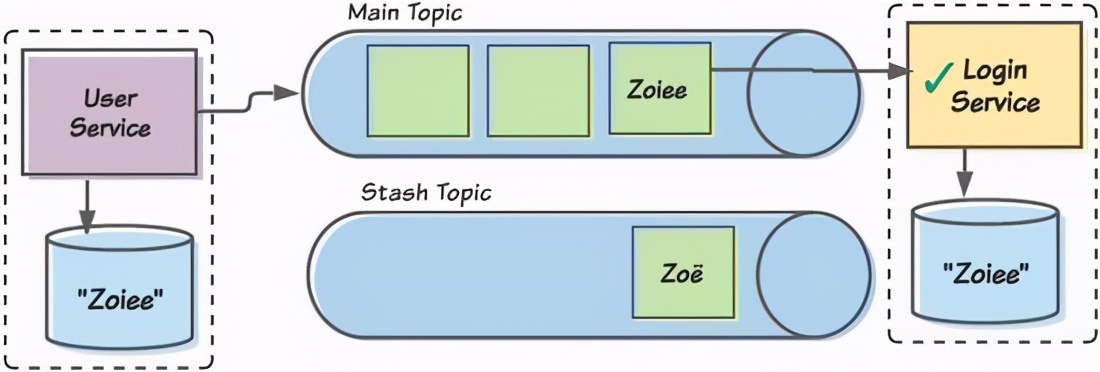
Zoëメッセージは非表示になり、Zoieeメッセージは正常に処理されました。現在、2つの境界のあるコンテキスト間のデータは一貫しています。
後で、私たちのチームは、特殊文字を正しく処理して再デプロイできるように、コンシューマーを修正します。次に、Zoëメッセージをコンシューマーに再投稿すると、コンシューマーはメッセージを正しく処理できるようになります。
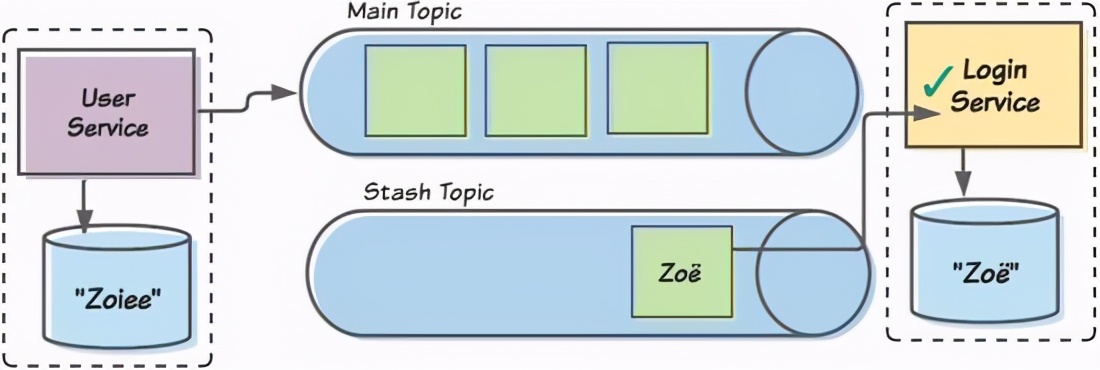
その後、更新されたコンシューマーが非表示のZoëメッセージを処理すると、2つの境界のあるコンテキスト間のデータに一貫性がなくなります。したがって、ユーザー制限コンテキストがユーザーをZoeeeと見なすと、ログイン制限コンテキストはユーザーをZoëと呼びます。
明らかに、順序を維持しませんでした。ZoëはZoeeeの前にLoginコンシューマーによって処理されましたが、正しい順序が逆になっています。メッセージを非表示にした後、すべてのメッセージの非表示を開始できますが、その場合、実際にはスタックします。幸い、すべてのメッセージの順序を維持する必要はありません。単一の集計に関連付けられているメッセージを検討するだけです。したがって、コンシューマーが非表示になっている特定のアグリゲーションを追跡できる場合、同じアグリゲーションに属する後続のメッセージも非表示にすることができます。
トピック内のメッセージを非表示にするアラートを受信した後、コンシューマーをアンデプロイしてコードを修正できます(注意:メッセージ自体は変更しないでください。メッセージは不変のイベントを表します!)コンシューマーを修正してテストした後、次のことができます。再デプロイされます。もちろん、メインテーマを使い続ける前に、まず非表示のテーマのすべてのレコードを処理することに特別な注意を払う必要があります。このようにして、正しいソート状態を維持し続けます。このため、最初に非表示のコンシューマーをデプロイし、それが完了したとき(つまり、複数のコンシューマーを使用する場合、コンシューマーグループ内のすべてのインスタンスが完了したとき)にのみ、デプロイを解除してメインコンシューマーをデプロイします。
また、固定コンシューマーが非表示のメッセージを処理した後でも、他のエラーが発生する可能性があるという事実も考慮する必要があります。この場合、そのエラー処理動作は前に説明したとおりである必要があります。
- エラーが回復可能な場合は、バックオフ戦略を使用して再試行してください。
- エラーが回復不能な場合は、メッセージが非表示になり、次のメッセージに進みます。
このために、2番目の隠しテーマの使用を検討できます。
一部のデータに一貫性がない可能性はありますか?
このようなシステムは、構築が非常に複雑になる可能性があります。それらは、構築、テスト、および保守が難しい場合があります。したがって、一部の組織は、データの不整合の可能性を判断し、このリスクを許容できるかどうかを判断したい場合があります。
多くの場合、これらの組織はデータ調整メカニズムを採用して、最終的に(比較的長い「最終」)データの一貫性を保つことができます。これには多くの戦略があります(この記事の範囲外)。
総括する
再試行の処理は複雑に思えますが、それは非常に面倒なためです。特に、すべてが正常な場合のKafkaの比較的エレガントなスタイルと比較した場合はそうです。私たちが構築する適切なソリューション(再試行テーマ、非表示のテーマ、またはその他のソリューション)は、必要以上に複雑になります。
残念ながら、マイクロサービス間で柔軟な非同期通信フローを確立したい場合、それを無視することはできません。
この記事では、一般的なソリューション、その欠点、および代替ソリューションを設計する際に考慮すべきいくつかの事項について説明します。最終的に、適切なソリューションを構築するには、次のようないくつかの点に留意する必要があります。
- トピック、パーティション、およびパーティションキーを通じて、Kafkaが提供する機能について学習します。
- 回復可能なエラーと回復不可能なエラーの違いを考慮してください。
- 制限付きコンテキストや集約などのデザインパターンの使用。
- 現在または将来に関係なく、組織のユースケースの特性を把握する必要があります。独立したレコードを移動するだけですか?…この場合、並べ替えは気にしないかもしれません。それとも、データの変更を示すイベントを伝播していますか?…この場合、ソートは非常に重要です。
- あらゆるレベルのデータの不整合を許容できるかどうかを慎重に検討してください。
元のリンク:https://www.infoq.cn/article/51XSHW2opSmakhHmtth8
この記事がお役に立てば幸いです。私の公式アカウントに注意を払い、キーワード[インタビュー]に返信して、Javaコアナレッジポイントとインタビューギフトパッケージをまとめてください。共有する技術的な乾物記事と関連資料がもっとあります。一緒に学び、進歩しましょう!
