バックグラウンド
新規請負業者の信用格付けを予測するための5つの特徴的な指標は次の
とおりです。x1市場シェア
x2顧客苦情率
x3年間の粗利益率
x4売上高から払込資本
x5
上記の純利益利用次のように、マルチカテゴリの信用格付けモデルとクラスタリングモデルを開発するための5つの指標と過去の格付け結果の821サンプルデータ。
スムーズなネットワークを確保するために、R言語ローディングパッケージのネットワークリンクを国内ミラーに接続します。
ミラー設定をロードするには、次の2つの方法があります
。A。方法1:コードはミラーを指定します
local({r <-getOption( "repos")
r ["CRAN"] <-"http:// mirrors。 aliyun.com/CRAN / "
r [" CRANextra "] <-" http://mirrors.aliyun.com/CRAN/ "
options(repos = r)})
B。方法2:ミラーイメージを手動で変更する
(2) na.omit()コマンドを使用します。欠落しているデータ行を削除し
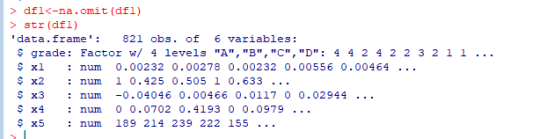
ます。データに欠落している値がないことがわかります。削除後、データと元のデータは同じままで、次の分析に進むことができます。
(3)R言語に読み込まれたAnnex 1データセットの場合、因子関数を使用して、評価結果のランク列を順序付き因子データ型に変換します。

データファクターを
並べ替えると、結果はA <B <C <Dになります。(4)変換されたdf1データフレームを開発サンプルdf1.trainと検証サンプルdf1.validateにランダムに分割します。

データ抽出率とデータサンプルには、それぞれ乱数が設定されています。

古典的な決定木モデル
(5)df1.trainを使用して古典的な決定木モデルをトレーニングし、df1.validateを使用してモデルの精度を検証します。
library(rpart)
set.seed(123456)
dtree <- rpart(grade~.,data = df1.train,method = 'class',
parms = list(split = 'information'))
dtree$cptable #不同大小的树对应的预测误差
plotcp(dtree) #交叉验证误差与复杂度参数的关系图
dtree.pruned <- prune(dtree,cp=0.015) #根据复杂度剪枝,控制树的大小
library(rpart.plot)
prp(dtree.pruned,type = 2, extra = 104,
fallen.leaves = TRUE, main = 'Decision Tree') #画出最终的决策树
dtree.pred <- predict(dtree.pruned,df1.validate,type = 'class')
str(dtree.pred)
dtree.pref <- table(df1.validate$grade,dtree.pred,
dnn = c('Actual','Predicted'))
print(dtree.pref)
結果を次のように示します。
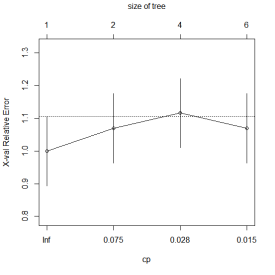
グラフの交差検定エラーと複雑度パラメーター
cp = 0.015の関係、複雑度に応じた枝刈り、ツリーのサイズの制御。決定ツリーグラフの描画は次のとおりです。
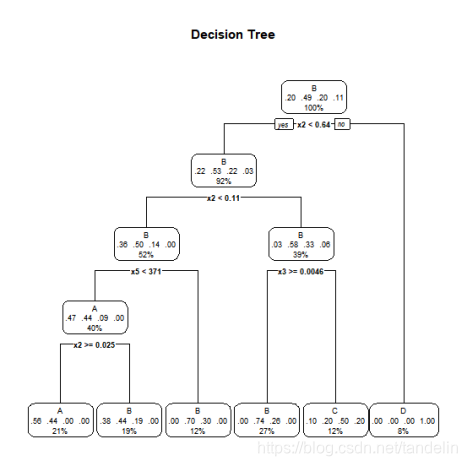
決定ツリーモデルは検証セットデータを使用して検証され、結果は次のとおりです

。計算によって検証できるデータの数は54 + 205 + 31 + 31 = 321であり、全体のデータは737です。最終的な正解率は、321/737 = 43.56%です。
推定決定木モデル
(6)df1.trainトレーニング条件を使用して決定木モデルを推測し、df1.validateを使用してモデルの精度を検証します。
#install.packages("party")
library(party) #加载必要包
fit.ctree <- ctree(grade~.,data = df1.train) #生成条件决策树
plot(fit.ctree,main = 'Conditional Inference Tree') #画出决策树
ctree.pred <- predict(fit.ctree,df1.validate,type = 'response') #对验证集分类
ctree.pref <- table(df1.validate$grade,ctree.pred,
dnn = c('Actual','"Predict')) #观察准确率
print(ctree.pref)
実行結果は以下のとおりです。
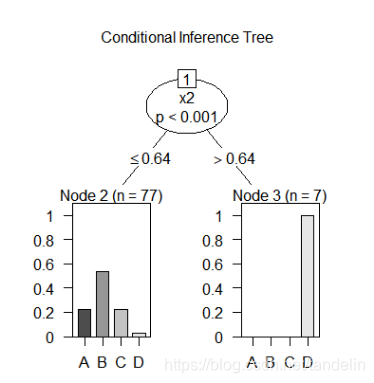
条件付き推論デシジョン
ツリーのグラフ化検証セットデータを使用してデシジョンツリーモデルを検証すると、最終的な予測データの結果は次のようになります。
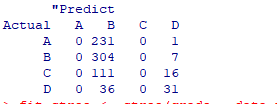
計算で検証できるデータ数は0+ 304 + 0 + 31 = 335、全体のデータ数は737です。最終的な正解率は次のとおりです。335/ 737 = 45.45%
ランダムフォレストモデル
(7)df1.trainを使用してランダムフォレストモデルをトレーニングし、df1.validateを使用してモデルの精度を検証します。
library(randomForest)
set.seed(123456)
ez.forest <- randomForest(grade~.,data = df1.train,
na.action = na.roughfix, #变量缺失值替换成对应列的中位数
importance = TRUE) #生成森林
print(ez.forest)
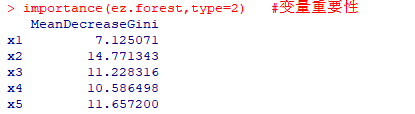
importance(ez.forest,type=2)
#type=2参数得到的某个变量的相对重要性就是分割该变量时节点不纯度的下降总量(所有决策树)取平均(/决策树的数量)
forest.pred <- predict(ez.forest,df1.validate)
forest.perf <- table(df1.validate$grade,forest.pred,
dnn = c('Actual','Predicted'))
print(forest.perf)
実行結果は次のとおりです。
決定木モデルは検証セットデータを使用して検証され、最終的な予測データの結果は次の
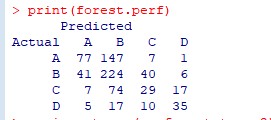
ようになります。計算によって検証できるデータの数は77 + 224 + 29 + 35 = 365であり、全体的なデータは737です。最終的な正解率は次のとおりです。365/ 737 = 49.53%
検証セットで上記の3つのモデルの予測精度を計算し、どのモデルが最も精度が高いかを評価します。
要約すると、古典的な決定木モデルの最終的な正解率は43.56%、条件付き推論の決定木モデルの最終的な正解率は45.45%、ランダムフォレストモデルの最終的な正解率は49.53%です。ランダムフォレストモデル高精度を選択します。
クラスター分析モデル
K-meansクラスタリングモデルを使用して、このデータのバッチに対してクラスター分析を実行します。
setwd("C:\\Users\\Administrator\\Desktop\\project")
df2<-read.csv("data2_cluster.csv")
str(df2)
library(factoextra)
df2<-df2[,-1]
b<-scale(df2)
#设置随机种子,保证试验客重复进行
set.seed(1234)
#确定最佳聚类个数,使用组内平方误差和法
fviz_nbclust(b,kmeans,method="wss")+geom_vline(xintercept=4,linetype=2)
#根据最佳聚类个数,进行kmeans聚类
res<-kmeans(b,4)
#将分类结果放入原数据集中
res1<-cbind(df2,res$cluster)
#导出最终结果
write.csv(res1,file='res1.csv')
#查看最终聚类图形
fviz_cluster(res,data=df2)
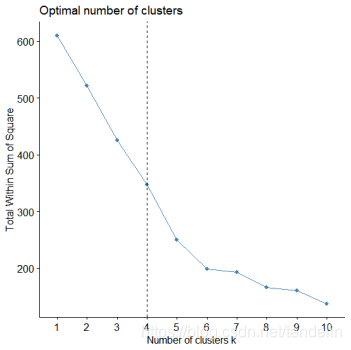
図:クラスターの最適数の判断
この関数は、カテゴリの最適数を直感的に示します:4。したがって、データは4つのカテゴリに分類されます。クラスタリング結果グラフは次のとおりです。
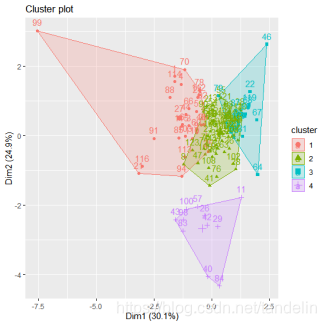
図:クラスタリング結果グラフ