
Kafkaクラスターの展開と開始
この記事では、Kafkaクラスターを構築する方法を示してから、Kafkaクラスターに関するいくつかの基本的な知識ポイントを簡単に紹介します。ただし、この記事ではクラスターの紹介にとどまり、カフカの基本的な考え方についてはあまり説明していません。読者はカフカの基本的な知識があることを前提としています。
まず、Kafkaクラスターのいくつかのメカニズムを理解する必要があります。
- Kafkaは当然クラスターをサポートしますが、実際には1つのノードでもクラスターモードです
- Kafkaクラスターは調整をZookeeperに依存しており、初期のKafkaバージョンの多くのデータはZookeeperに保存されます
- Kafkaノードが同じZookeeperに登録されている限り、それらは同じクラスター内にあることを意味します。
- KafkaはbrokerIdを使用して、クラスター内のさまざまなノードを区別します
Kafkaのクラスタートポロジは次のとおりです。
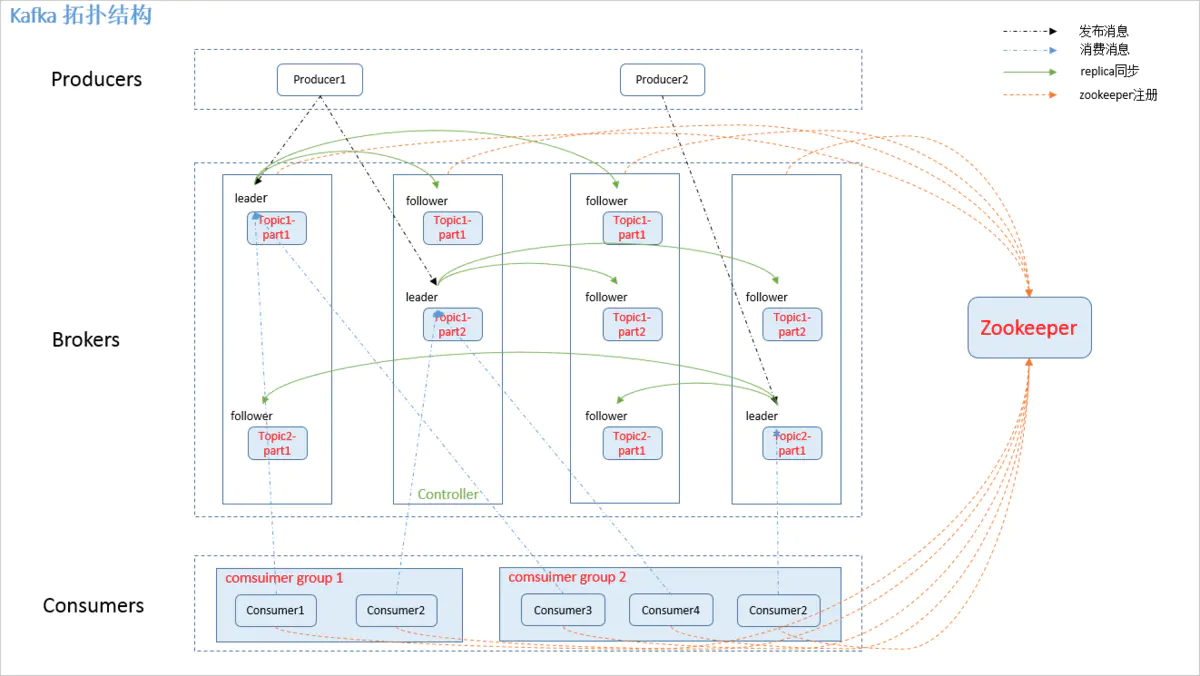
Kafkaクラスターでのいくつかの役割:
- ブローカー:通常、Kafkaのデプロイメントノードを指します
- リーダー:メッセージの受信と消費の要求を処理するために使用されます。つまり、プロデューサーはメッセージをリーダーにプッシュし、コンシューマーはリーダーからのメッセージをポーリングします。
- フォロワー:主にメッセージデータのバックアップに使用され、リーダーには複数のフォロワーがいます
この例では、実際の展開状況に近づくために、4つの仮想マシンをデモに使用しています。
| マシンIP | 効果 | 役割 | ブローカーID |
|---|---|---|---|
| 192.168.99.1 | Kafkaノードをデプロイします | ブローカーサーバー | 0 |
| 192.168.99.2 | Kafkaノードをデプロイします | ブローカーサーバー | 1 |
| 192.168.99.3 | Kafkaノードをデプロイします | ブローカーサーバー | 2 |
| 192.168.99.4 | Zookeeperノードをデプロイします | クラスターコーディネーター |
Zookeeperのインストール
Kafkaは分散調整を実現するためにZookeeperに基づいているため、Kafkaノードを構築する前にZookeeperノードを構築する必要があります。ZookeeperとKafkaはどちらもJDKに依存しています。私はすでにJDKをここにインストールしています。
[[email protected] ~]# java --version
java 11.0.5 2019-10-15 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.5+10-LTS)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.5+10-LTS, mixed mode)
[root@txy-server2 ~]#JDK環境を準備したら、Zookeeperの公式Webサイトのダウンロードアドレスにアクセスし、ダウンロードリンクをコピーします。
次に、次のように、wgetコマンドを使用してLinuxにダウンロードします。
[[email protected] ~]# cd /usr/local/src
[[email protected] /usr/local/src]# wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.6.1/apache-zookeeper-3.6.1-bin.tar.gzダウンロードした圧縮パッケージを解凍し、解凍したディレクトリを移動して名前を変更します。
[[email protected] /usr/local/src]# tar -zxvf apache-zookeeper-3.6.1-bin.tar.gz
[[email protected] /usr/local/src]# mv apache-zookeeper-3.6.1-bin ../zookeeperZookeeper構成ファイルディレクトリに移動し、サンプル構成ファイルzoo_sample.cfgをコピーして、zookeeperという名前を付けます。これはZookeeperのデフォルトの構成ファイル名です。
[[email protected] /usr/local/src]# cd ../zookeeper/conf/
[[email protected] /usr/local/zookeeper/conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[[email protected] /usr/local/zookeeper/conf]# cp zoo_sample.cfg zoo.cfg構成ファイルのdataDir構成項目を変更して、ディスク容量が大きいディレクトリを指定します。
[[email protected] /usr/local/zookeeper/conf]# vim zoo.cfg
# 指定Zookeeper的数据存储目录,类比于MySQL的dataDir
dataDir=/data/zookeeper
[[email protected] /usr/local/zookeeper/conf]# mkdir -p /data/zookeeper
次の例に示すように、使用方法を学習しているだけの場合、この手順は実際には無視できます。デフォルト構成でbinディレクトリに入り、起動スクリプトを使用してZookeeperを起動できます。
[[email protected] /usr/local/zookeeper/conf]# cd ../bin/
[[email protected] /usr/local/zookeeper/bin]# ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[[email protected] /usr/local/zookeeper/bin]#起動が完了したら、ポート番号が正常に監視されているかどうかを確認することで、起動が成功したかどうかを判断できます。起動は次のように成功します。
[[email protected] ~]# netstat -lntp |grep 2181
tcp6 0 0 :::2181 :::* LISTEN 7825/java
[[email protected] ~]#マシンでファイアウォールがオンになっている場合は、Zookeeperポートを開く必要があります。そうしないと、他のノードを登録できません。
[[email protected] ~]# firewall-cmd --zone=public --add-port=2181/tcp --permanent
[[email protected] ~]# firwall-cmd --reloadKafka安装
Zookeeperをインストールした後、Kafkaをインストールできます。同じ手順で、最初にKafkaの公式Webサイトにアクセスしてアドレスをダウンロードし、ダウンロードリンクをコピーします。
次に、次のように、wgetコマンドを使用してLinuxにダウンロードします。
[[email protected] ~]# cd /usr/local/src
[[email protected] /usr/local/src]# wget https://mirror.bit.edu.cn/apache/kafka/2.5.0/kafka_2.13-2.5.0.tgzダウンロードした圧縮パッケージを解凍し、解凍したディレクトリを移動して名前を変更します。
[[email protected] /usr/local/src]# tar -xvf kafka_2.13-2.5.0.tgz
[[email protected] /usr/local/src]# mv kafka_2.13-2.5.0 ../kafkaKafkaの構成ファイルディレクトリに入り、構成ファイルを変更します。
[[email protected] /usr/local/src]# cd ../kafka/config/
[[email protected] /usr/local/kafka/config]# vim server.properties
# 指定该节点的brokerId,同一集群中的brokerId需要唯一
broker.id=0
# 指定监听的地址及端口号,该配置项是指定内网ip
listeners=PLAINTEXT://192.168.99.1:9092
# 如果需要开放外网访问,则在该配置项指定外网ip
advertised.listeners=PLAINTEXT://192.168.99.1:9092
# 指定kafka日志文件的存储目录
log.dirs=/usr/local/kafka/kafka-logs
# 指定zookeeper的连接地址,若有多个地址则用逗号分隔
zookeeper.connect=192.168.99.4:2181
[[email protected] /usr/local/kafka/config]# mkdir /usr/local/kafka/kafka-logs構成ファイルの変更が完了したら、Kafkaコマンドスクリプトの使用を容易にするために、Kafkaのbinディレクトリを環境変数に構成できます。
[[email protected] ~]# vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[[email protected] ~]# source /etc/profile # 让配置生效したがって、次のコマンドでKafkaを起動できます。
[[email protected] ~]# kafka-server-start.sh /usr/local/kafka/config/server.properties &上記のコマンドを実行すると、起動ログがコンソールに出力されます。起動が成功したかどうかは、ログから判断できます。また、ポート9092が監視されているかどうかを確認することで、起動が成功したかどうかを判断できます。
[[email protected] ~]# netstat -lntp |grep 9092
tcp6 0 0 192.168.99.1:9092 :::* LISTEN 31943/java
[[email protected] ~]#同様に、ファイアウォールがオンになっている場合は、対応するポート番号も開く必要があります。
[[email protected] ~]# firewall-cmd --zone=public --add-port=9092/tcp --permanent
[[email protected] ~]# firwall-cmd --reloadこれまでに、最初のKafkaノードのインストールが完了しました。他の2つのノードのインストール手順も同じです。構成ファイルのbrokerIdとmonitoringipを変更するだけで済みます。そこで、ノード内のKafkaディレクトリを他の2台のマシンに直接コピーします。
[[email protected] ~]# rsync -av /usr/local/kafka 192.168.99.2:/usr/local/kafka
[[email protected] ~]# rsync -av /usr/local/kafka 192.168.99.3:/usr/local/kafka次に、次の2つのノードのbrokerIdとlisteningipを変更します。
[[email protected] /usr/local/kafka/config]# vim server.properties
# 修改brokerId
broker.id=1
# 指定监听的地址及端口号,该配置项是指定内网ip
listeners=PLAINTEXT://192.168.99.2:9092
# 如果需要开放外网访问,则在该配置项指定外网ip
advertised.listeners=PLAINTEXT://192.168.99.2:9092
[[email protected] /usr/local/kafka/config]#
[[email protected] /usr/local/kafka/config]# vim server.properties
# 修改brokerId
broker.id=2
# 指定监听的地址及端口号,该配置项是指定内网ip
listeners=PLAINTEXT://192.168.99.3:9092
# 如果需要开放外网访问,则在该配置项指定外网ip
advertised.listeners=PLAINTEXT://192.168.99.3:9092
[[email protected] /usr/local/kafka/config]# 構成の変更が完了したら、前述の手順に従って2つのノードを起動します。起動が成功したら、Zookeeperと入力します。/brokers/idsの下に対応するbrokerIdデータがあり、クラスターが正常に構築されたことを示します。
[[email protected] ~]# /usr/local/zookeeper/bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 4] ls /brokers/ids
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 5]Kafka副本集
カフカのレプリカセットについて:
- Kafkaレプリカセットとは、ログの複数のコピーをコピーすることを指します。Kafkaデータはログファイルに保存されます。これは、データのバックアップと冗長性に相当します。
- Kafkaは、構成を通じてレプリカセットのデフォルト数を設定できます
- Kafkaはトピックごとにレプリカセットを設定できるため、レプリカセットはトピックに関連しています。
- トピックのレプリカセットは複数のブローカーに分散できます。1つのブローカーに障害が発生しても、他のブローカーにデータが残っているため、データの信頼性が向上します。これは、レプリカセットの主な機能でもあります。
Kafkaのトピックは単なる論理的な概念であり、実際のストレージデータはパーティションであるため、実際にコピーされるのはパーティションです。以下に示すように:
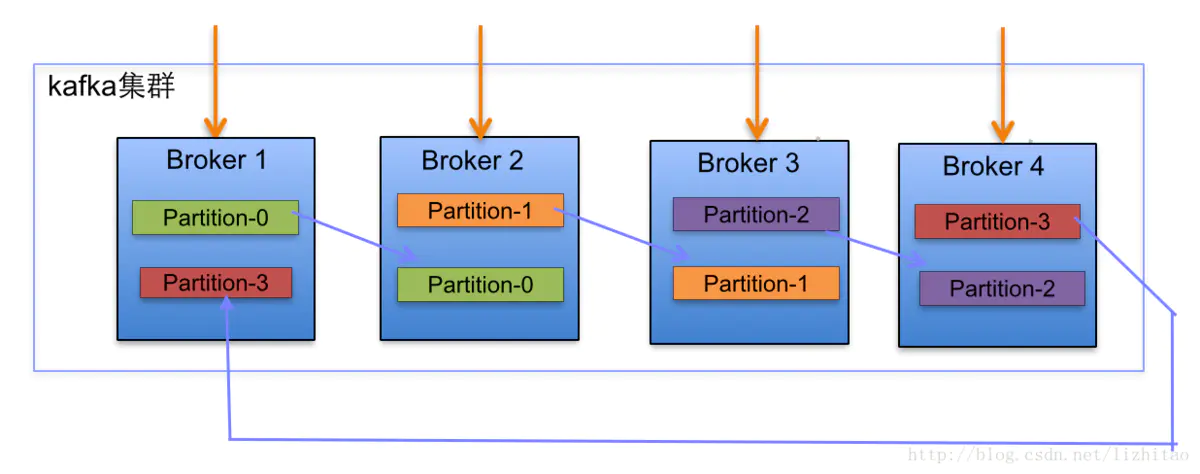
コピーファクターについて:
- コピー係数は、実際にはパーティションのコピー数を決定します。たとえば、コピー係数が1の場合、トピック内のすべてのパーティションがブローカーの数に従ってコピーされ、各ブローカーに配布されることを意味します。
コピー割り当てアルゴリズムは次のとおりです。
- 割り当てられるすべてのNブローカーとiパーティションを並べ替えます
- i番目のパーティションを(i mod n)ブローカーに割り当てます
- i番目のパーティションのj番目のコピーを((i + j)mod n)ブローカーに割り当てます
カフカノードの故障理由と治療方法
Kafkaノード(ブローカー)障害の2つの状況:
- KafkaノードとZookeeperのハートビートがノード障害として維持されない
- フォロワーのメッセージがリーダーよりもはるかに遅れている場合、ノード障害と見なされます
Kafkaによるノード障害の処理:
- Kafkaは障害が発生したノードを削除するため、ノードの障害によるデータの損失は基本的にありません。
- Kafkaのセマンティック保証は、データの損失も大幅に回避します
- Kafkaは、クラスター内のメッセージのバランスを取り、一部のノードでのメッセージの過熱を減らします
カフカリーダー選出メカニズムの紹介
カフカクラスターのリーダー選挙:
- 他の分散コンポーネントと接触したことがある場合は、多くのノードの中からリーダーを選出するために投票することでほとんどのコンポーネントが選出されることがわかりますが、カフカでは、リーダーの選出に投票は使用されません。
- Kafkaは、リーダーデータ(ISR)のコピーのセットを動的に維持します
- KafkaはISRでリーダーとしてより速いものを選択します
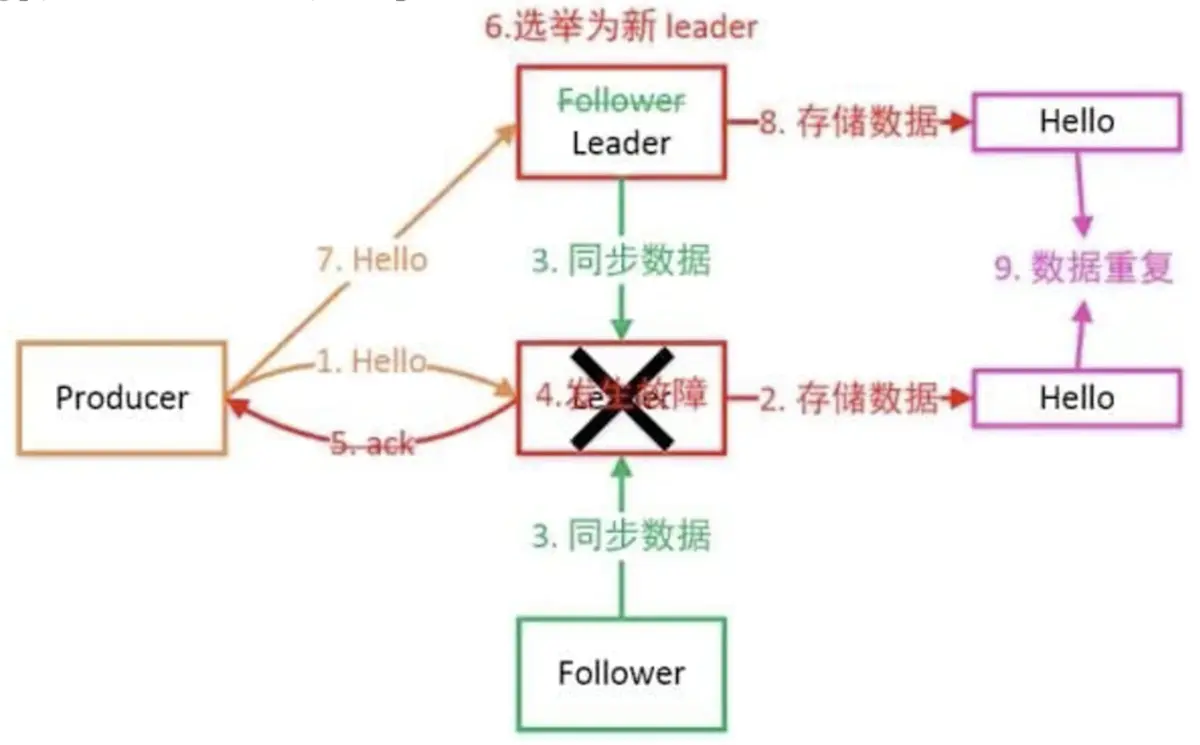
「賢い女性がご飯なしで料理するのは難しい」:カフカは無力な状況にあります。つまり、ISRのすべてのコピーがダウンしています。この場合、カフカはデフォルトで汚れたリーダー選挙を実施します。Kafkaは、2つの異なる処理方法を提供します。
-
ISR内のレプリカが回復するのを待ち、リーダーとして選択します
- 待機時間が長くなると可用性が低下するか、ISR内のすべてのレプリカを回復できないか、データが失われると、パーティションが使用できなくなります。
- ISRにあるかどうかに関係なく、最初に復元されたレプリカを新しいリーダーとして選択します
- リーダーによって以前にコミットされたすべてのメッセージが含まれているわけではないため、データが失われますが、可用性は高くなります。
リーダー選挙構成の推奨事項:
- 汚れたリーダーの選挙を無効にする
- 最小ISRを手動で設定する
ISRの詳細については、以下を参照してください。
元のリンク:https://www.jianshu.com/p/cc0b90636715作成者:Duanwan Chit-Chat